Cosmos 3: Omnimodal World Models for Physical AI
Abstract: We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-LLMs, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
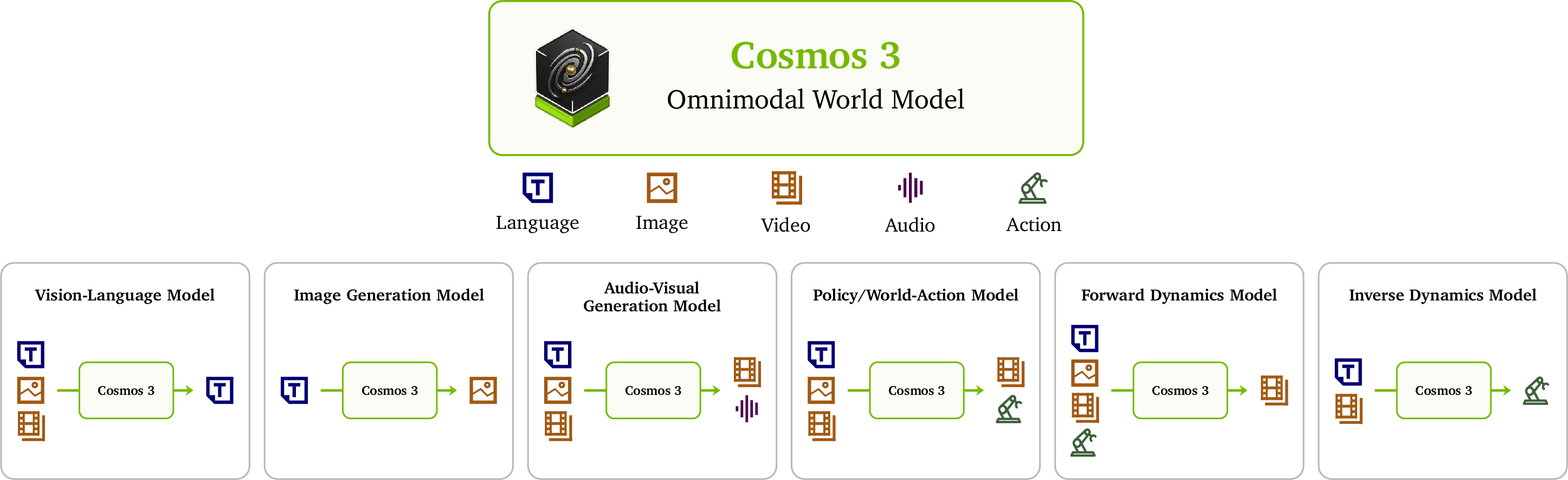
This paper introduces Cosmos 3, a single AI system that can understand and create many kinds of things at once: text, images, videos, sounds, and even action steps for robots. Instead of using separate models for each job (like one for reading images, another for making videos, and another for controlling a robot), Cosmos 3 combines them into one “omnimodal” model. The goal is to build a strong, general “world model” that can power Physical AI—agents that see, think, and act safely and effectively in the real world.
The main questions the paper asks
- Can we build one model that both understands the world and also generates (creates or predicts) what happens next—across text, images, video, audio, and actions?
- Can this single model replace many separate, specialized systems (like vision-LLMs, video generators, and robot policy models)?
- Will this unified approach help train smarter, safer Physical AI agents, especially by learning in simulation before trying things in real life?
How the system works (in everyday terms)
Think of Cosmos 3 as a single “brain” with two tightly connected halves that share what they learn:
One brain for many skills
- Cosmos 3 accepts different kinds of inputs: words, pictures, video clips, audio, and even robot movements.
- It turns everything into “tokens,” which you can imagine as small puzzle pieces that carry meaning. Different encoders turn each input type into a shared internal language so the brain can work on all of them together.
Understanding and making: two teamwork modes inside one model
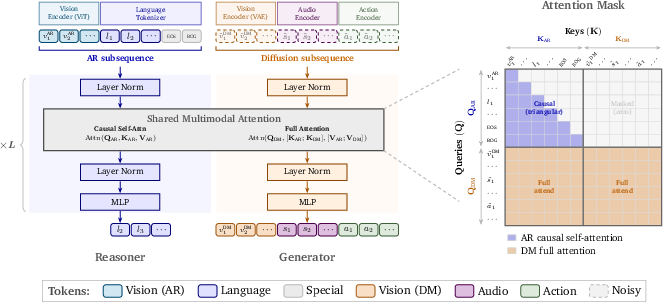
- Autoregressive (AR) mode = understanding and reasoning. Picture writing a sentence one word at a time, using what came before to decide the next word. Cosmos 3 uses this for reading text, looking at images/videos, and answering questions.
- Diffusion (DM) mode = generation. Imagine starting with a very noisy, blurry canvas and slowly cleaning it up until a clear image or video appears. Cosmos 3 uses this to generate images, videos, audio, and actions.
Both modes run inside a Mixture-of-Transformers (MoT) design—think of it like a two-lane highway inside the same brain:
- The “reasoning lane” handles AR tokens (words and vision tokens for understanding).
- The “generation lane” handles the diffusion tokens (for making images, video, audio, and actions).
- The generation lane can look at what the reasoning lane produced (so it follows instructions), but the reasoning lane doesn’t depend on the generation lane. This keeps instructions stable while creation happens.
Action tokens: teaching the model how to act
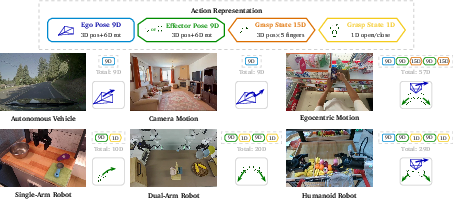
- “Action” is treated as a first-class citizen, just like text or images. An action token sits between two video frames and represents “what changed” to get from the last frame to the next, like a tiny motion step.
- Different robots or bodies have different controls (car steering, robot arm movement, hand grasps). Cosmos 3 converts them into a shared, compact “action vector” so it can learn consistent patterns across many types of movement.
- This lets the model do:
- Forward dynamics: if I take these actions, what will I see next?
- Inverse dynamics: given what changed in the video, what actions caused it?
- Policy mode: predict actions and the future video together, like planning moves and imagining the outcome at the same time.
Keeping time in sync across video, audio, and actions
- Different data run at different speeds: video might be 24 or 60 frames per second; audio is sampled thousands of times per second; actions might be logged at yet another rate.
- Cosmos 3 uses a shared “time map” so all tokens line up on the same timeline. Think of it as a common rhythm or beat so the model knows which sound, picture, and action belong together at each moment.
Flexible input/output modes
Cosmos 3 can switch jobs without changing its architecture. Here are common modes:
- Text-to-Image: write a caption, get a picture.
- Text-to-Video (optionally with audio): write a script, get a video (and matching sound).
- Image-to-Video or Video-to-Video: start from one image or a few frames, continue the motion.
- Video transfer: give a control video (like an edge map or depth map) and text, get a stylized RGB video.
- Action modes:
- Forward dynamics: clean actions in, predict future visuals.
- Inverse dynamics: clean visuals in, infer the actions that caused them.
- Policy: predict actions and their visual results together.
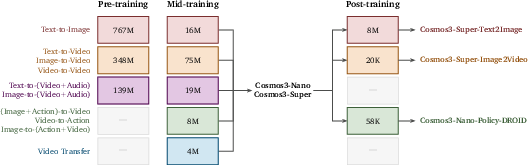
Different sizes for different needs
- Edge (small), Nano (medium), and Super (large) versions balance speed and power. All share the same design but vary in scale.
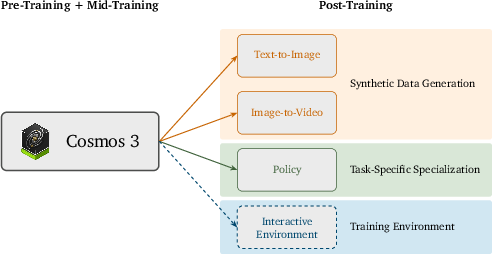
How it’s trained
- Reasoner pathway: trained on vision-language tasks (like image+text, video+text) to learn to understand and reason.
- Generator pathway: trained on lots of images, videos, audio, and action data to learn to create and simulate.
- The model is then “post-trained” (further tuned) for specific tasks, like better text-to-image, better image-to-video, or better robot policies.
What the researchers found and why it matters
According to the paper’s benchmarks and rankings:
- Cosmos 3 reaches or sets state-of-the-art results across many understanding and generation tasks.
- The post-trained Cosmos 3 models were ranked:
- Best open-source Text-to-Image and Image-to-Video by Artificial Analysis at the time of writing.
- Best policy model by RoboArena at the time of writing.
- It performs competitively even against specialized models built for single tasks, while Cosmos 3 handles many tasks in one framework.
- It can be adapted (“post-trained”) for particular needs—like creating higher-quality synthetic data or learning strong robot policies—without changing the architecture.
Why this is important:
- Training robots directly in the real world is slow, expensive, and sometimes unsafe. Cosmos 3 can learn in simulation, generate realistic data, and predict outcomes, making training cheaper and safer.
- Unifying understanding and generation helps the model plan better: it can reason about what will happen next and create those futures in its “mind,” then choose actions accordingly.
- Because it’s open-weight and comes with code, datasets, and benchmarks, other researchers can build on it.
What this could change in the future
- Smarter, safer Physical AI: A home robot, for example, could read instructions, look around, plan its moves, predict the results, and act—using one brain instead of stitching together separate tools.
- Faster progress through synthetic worlds: Cosmos 3 can generate high-quality images, videos, and environments for training, speeding up research without risking real-world harm.
- Easier specialization: The same base model can be tuned for different jobs—robotics, driving, digital humans, warehouse tasks—while sharing a common understanding of the world.
In short, Cosmos 3 is like a Swiss Army knife for AI that sees, thinks, makes, and acts. By combining many abilities into one model, it aims to become a strong backbone for the next generation of real-world AI agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research.
- Quantify the sensitivity of the fixed temporal gap (15,000) between AR and diffusion subsequences: ablations on image/video quality, artifact suppression, and any side-effects on AR reasoning.
- Systematically evaluate the absolute temporal modulation (base TPS=6) across diverse frame rates and sampling rates: robustness to variable-FPS inputs, dropped frames, clock drift, and mixed-modality resampling.
- Provide ablations comparing alternative positional-encoding schemes (e.g., different RoPE variants, learned embeddings, segment-aware encodings) and their effects on long-horizon temporal coherence and cross-modal alignment.
- Investigate whether the AR-not-conditioned-on-DM constraint limits iterative reasoning, e.g., text updates informed by partially denoised visuals or actions; explore controlled bidirectional coupling or multi-round conditioning.
- Characterize the impact of token ordering within the unified format (vision → audio → action in DM) on conditioning strength, modality bias, and generation fidelity; test alternative orderings and interleavings.
- Detail and compare generator objectives (flow matching vs. DDPM/EDM/consistency models), noise schedules, and training dynamics; report how each objective trades off sharpness, temporal consistency, and conditioning faithfulness.
- Assess whether freezing the video/audio VAEs creates a fidelity bottleneck; evaluate end-to-end finetuning or tokenizer adaptation and its cost/benefit on realism and dynamics fidelity.
- Examine limits of the unified action interface: coverage gaps for legged locomotion, drones, deformable manipulation, multi-contact tasks, and complex gripper/hand synergies not captured by pose deltas + simple grasp states.
- Quantify the loss from discarding embodiment-specific low-level actuation/controller parameters; evaluate feasibility constraints and control stability when converting pose deltas back to executable controls.
- Analyze numerical stability of the 6D rotation representation + SVD inversion for action decoding in long sequences; report failure modes and regularization needed to avoid discontinuities.
- Measure cross-domain transfer and negative transfer with domain-aware input/output projections: when do shared MoT parameters help vs. hurt new embodiments, and what isolation or adapters minimize interference?
- Provide a recipe for rapidly adding a new embodiment domain (data requirements, initialization of domain-specific projections, few-shot adaptation) and quantify sample efficiency.
- Clarify synchronization assumptions between video, audio, and action streams; evaluate robustness to latency, jitter, and sensor desynchronization common in real data.
- Report memory/latency/computation scaling for the dual-tower MoT at different sequence lengths and modes; quantify the cost-benefit of dual towers vs. single-tower baselines.
- Provide long-horizon evaluations (minutes-scale) to probe temporal drift, identity/scene consistency, and physics plausibility given the VAE’s 4× temporal compression and transformer context limits.
- Investigate uncertainty calibration and multi-future modeling: how many diverse samples are needed for planning; metrics for diversity vs. realism under action-conditioned generation.
- Specify the generator data composition (scale, domains, real vs. synthetic ratios, action-video pair coverage), curation/filtering procedures, and their impact on downstream capabilities and biases.
- Evaluate sim-to-real transfer and closed-loop control on real robots/vehicles beyond DROID post-training: robustness to sensor noise, occlusions, lighting changes, and embodiment mismatch.
- Analyze catastrophic forgetting risks when post-training for different targets (T2I, I2V, policy): what freezes/regularizers or multi-task schedules preserve reasoning while improving generation/policy.
- Provide audio–video synchronization metrics and results; characterize failure modes (lip-sync drift, onset misalignment) and training interventions to fix them.
- Test multi-video/multi-scene conditioning and segment stitching: does resetting spatial/temporal indices per segment cause ambiguities or context leakage; propose disambiguation mechanisms.
- Clarify how action feasibility is enforced in policy mode: do predicted pose deltas respect dynamics/kinematics constraints; propose training-time penalties or post-hoc projection onto feasible sets.
- Benchmark the world-model’s physics fidelity (contact, momentum, friction) with standardized diagnostics; identify gaps where the model breaks physical invariants.
- Evaluate planning usefulness: does forward dynamics accuracy translate into better control when used in MPC/planning loops; quantify end-to-end task improvements over baselines.
- Study robustness under distribution shift and adversarial prompts across modalities (text, images, audio); propose guardrails for unsafe content or unsafe policies.
- Provide detailed training schedules (which layers updated per mode, learning-rate strategies, curriculum timing) to improve reproducibility and illuminate key design choices.
- Compare MoT to alternatives (e.g., cross-attention conditioning, mixture-of-experts, adapters) with controlled compute to isolate where dual towers most help.
- Quantify effects of the DeepStack aggregation and text-based video timestamps on temporal reasoning vs. generation fidelity; ablate or replace with alternatives.
- Describe evaluation protocols and metrics behind the headline scores (human preference criteria, inter-rater reliability, dataset coverage), including energy/latency footprints for fair comparisons.
- Explore interactive/online learning: integrating RL, environment rollouts, and self-play with the unified model; report stability and sample efficiency in on-policy updates.
- Address ethical risks of open synthetic data and omnimodal generation (video/audio deepfakes, action misuse); document bias audits, content filtering, and policy safeguards.
- Specify interoperability with simulators and control stacks: APIs and data exchange formats to plug Cosmos 3 into standard RL/planning pipelines.
- Clarify the status and roadmap for the unreleased Edge model and its on-device constraints; provide mobile/edge benchmarks and compression/distillation strategies.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released code, open-weight checkpoints, and datasets, or with modest post-training/fine-tuning. Each item includes suggested sectors and possible tools/workflows, plus key assumptions/dependencies.
- Synthetic data engine for vision and robotics
- Sectors: robotics, autonomous driving, smart infrastructure, media
- What: Use Cosmos3-Super/Nano (and post-trained Text2Image/Image2Video) to generate high-diversity images/videos for perception model pretraining, rare-event augmentation, and domain balancing; leverage open SDG datasets (e.g., SDG-DriveSim, SDG-Warehouse, SDG-RobotSim) to bootstrap domain-specific corpora.
- Tools/workflows: “Data factory” pipelines that script prompts + control-video (depth/edges) for targeted data; automatic curriculum generation via Image-to-Video and Video transfer; integrate with MLOps data versioning and evaluation via Cosmos-HUE.
- Assumptions/dependencies: GPU capacity for diffusion inference; prompt and control-signal engineering; data governance (copyright/consent) and content provenance; sim-to-real validation.
- Unified multimodal evaluation and benchmarking
- Sectors: academia, industry R&D, public sector labs
- What: Use Cosmos-HUE and the MoT-based reasoner for standardized assessment across understanding, generation, and action; compare ablations and fine-tuned variants in a single protocol.
- Tools/workflows: Continuous evaluation in CI; regression dashboards for multimodal KPIs (reasoning, T2I/T2V quality, policy success).
- Assumptions/dependencies: Agreement on metrics for cross-modality evaluation; reproducible evaluation harnesses.
- Robotics policy prototyping and imitation learning
- Sectors: robotics (R&D labs, warehouse automation), education
- What: Post-train Cosmos3-Nano on task data (e.g., DROID) to obtain world-action models and policies; use forward/inverse dynamics for rollouts and action inference from demonstrations.
- Tools/workflows: “Policy studio” for dataset ingestion, embodiment adapters (domain-aware action projections), closed-loop sim evaluation, and real-robot pilots; RoboArena-style benchmarks for quick iteration.
- Assumptions/dependencies: High-quality demonstrations with calibrated action/state logs; safety guardrails; sim-to-real transfer plan; latency budget for control loops.
- Previsualization and virtual production (text-to-video/image-to-video with audio)
- Sectors: media/entertainment, advertising, education
- What: Rapidly iterate storyboards, motion studies, and animatics from prompts or single images; generate synchronous audio for scenes.
- Tools/workflows: NLE/DCC plugins that drive Cosmos3 generation modes (T2V, I2V, AV sync); control-video (depth/edge) guided transfers to preserve motion/layout.
- Assumptions/dependencies: Alignment to studio style guides; IP clearance; compute provisioning and caching; watermarking/content provenance.
- Smart-infrastructure and AV research sandboxes
- Sectors: transportation, city planning, AV startups
- What: Use video-to-video/transfer to synthesize traffic scenes, weather, lighting, and sensor variations for perception/regression testing; employ reasoner for spatiotemporal QA and incident annotation.
- Tools/workflows: “Scenario bank” generation on SDG-DriveSim; automatic labeling and question-answering for corner-case triage; evaluation against downstream detectors/trackers.
- Assumptions/dependencies: Coverage of local traffic rules and assets; realism thresholds for downstream models; governance for synthetic images in safety pipelines.
- Interactive multimodal assistants for labs and classrooms
- Sectors: education, research
- What: VLM-style understanding (language+image/video) for lab demonstrations, procedural guidance, and video explanation; generate short illustrative clips for concepts.
- Tools/workflows: Lightweight front-ends that invoke AR reasoning for step-by-step instructions and DM generation for illustrative sequences.
- Assumptions/dependencies: Domain alignment (terminology, safety); content filters for classroom use.
- Teleoperation preview and human-in-the-loop robotics
- Sectors: field robotics, logistics
- What: Use forward dynamics to visualize predicted near-term consequences of candidate actions, aiding remote operators in delicate tasks.
- Tools/workflows: Operator console overlays showing rollout videos conditioned on action tokens; adjustable horizon/uncertainty bands.
- Assumptions/dependencies: Accurate camera/pose calibration for action tokens; latency management; uncertainty communication to the operator.
- Multimodal documentation and training content authoring
- Sectors: software/devtools, enterprise L&D
- What: Auto-generate short tutorial videos from textual procedures or screenshots (I2V/T2V), with synchronized narration.
- Tools/workflows: CMS integration to draft trainings; batch generation with human review; A/B testing on learner outcomes.
- Assumptions/dependencies: Corporate brand/safety policies; accessibility standards; compute cost controls.
- Egocentric analytics and AR prototyping
- Sectors: wearables, AR/VR
- What: Use egocentric action tokens for wrist/head motion analysis, imitation learning, or predictive overlays in AR prototypes.
- Tools/workflows: Embodiment adapters for head/wrist pose; inverse dynamics to infer actions from video for coaching/feedback.
- Assumptions/dependencies: Accurate inertial/vision sensor fusion; privacy/consent; power/latency limits on device (Edge model pending release).
- Open research on world models and MoT architectures
- Sectors: academia, open-source community
- What: Experiment with dual-tower MoT, absolute-temporal MRoPE, and mixed AR+diffusion training strategies using open weights and code.
- Tools/workflows: Reproducible training curricula for reasoner/generator; ablation suites; dataset contribution via SDG schema.
- Assumptions/dependencies: Compute access; alignment with OpenMDW-1.1 licensing.
Long-Term Applications
These applications are feasible with further research, scaling, safety validation, or systems integration. They indicate where Cosmos 3’s unified, omnimodal design can evolve into end-to-end solutions.
- General-purpose home and service robots
- Sectors: consumer robotics, hospitality, eldercare
- What: Single backbone for perception, planning via forward simulation, and action generation across diverse household tasks (e.g., table clearing, tidying).
- Tools/workflows: Continual post-training per home/venue; joint video-action policy learning; on-device Edge deployment for privacy/latency.
- Assumptions/dependencies: Robust sim-to-real transfer, safety and reliability certification, long-horizon memory, task generalization, cost-effective sensors/actuators.
- Closed-loop autonomous driving with world-model-based planning
- Sectors: automotive, mobility services
- What: Use joint video-action modeling for prediction and policy rollouts, integrating multiple sensors and control stacks under a unified world model.
- Tools/workflows: Scenario-driven self-play and rare-event synthesis; uncertainty-aware planning on top of DM predictions; hybrid optimization with rule-based constraints.
- Assumptions/dependencies: Multi-sensor fusion extensions, stringent safety validation, regulatory approval, robust OOD handling.
- City-scale digital twins and policy stress testing
- Sectors: public policy, smart cities, insurance
- What: Generate and simulate complex urban scenes (traffic flows, events, infrastructure changes) to test interventions (signal timing, zoning, emergency response).
- Tools/workflows: Scenario authoring with control-video inputs; synthetic longitudinal datasets for impact analysis; benchmarking pipelines for KPIs.
- Assumptions/dependencies: High-fidelity asset libraries and behavioral priors; governance frameworks for synthetic evidence; integration with GIS and real telemetry.
- Industrial and energy inspection robotics with predictive simulation
- Sectors: energy, manufacturing, utilities
- What: Robots that plan and execute inspection/maintenance, leveraging forward dynamics to predict effects of manipulations in constrained environments.
- Tools/workflows: Task libraries (valve turning, gauge reading, thermal inspections); policy rollouts under safety envelopes; digital twin synchronization.
- Assumptions/dependencies: Specialized sensors (thermal, depth), hazardous-environment certification, domain adaptation to materials/lighting.
- Synthetic training environments as a service (EaaS) for Physical AI
- Sectors: robotics platforms, AV, defense research
- What: Programmatically generate complex, curriculum-aligned 3D environments and tasks, co-evolving with agent capabilities to minimize real-world risk.
- Tools/workflows: “Environment compiler” that uses text prompts + control signals to produce interactive scenes and tasks; automated difficulty scaling.
- Assumptions/dependencies: Interactive physics integration with the generator; scalable evaluation harnesses; guardrails to avoid overfitting to synthetic artifacts.
- Multimodal AR/VR agents and embodied tutoring
- Sectors: education, healthcare training, enterprise
- What: Agents that perceive user actions/scene context and generate real-time guidance, demonstrations, or corrective feedback via video/audio overlays.
- Tools/workflows: Real-time MoT inference pipelines; egocentric action adapters; curriculum personalization via reasoner.
- Assumptions/dependencies: Edge-grade models for on-device operation, low-latency streaming, bias mitigation, user safety and privacy controls.
- Assistive technologies and rehabilitation robots
- Sectors: healthcare, home care
- What: Personalized, safe action policies for mobility/rehab support, with video-action rollouts to anticipate and avoid risk.
- Tools/workflows: Clinician-in-the-loop training; safety-case documentation using synthetic stress tests; explainable action rationales via reasoner.
- Assumptions/dependencies: Medical-grade data, regulatory clearance, rigorous human-subject trials, specialized hardware and fail-safes.
- Content authenticity, governance, and forensic tools for generative media
- Sectors: policy/regulation, media platforms
- What: Detection/traceability layered onto Cosmos 3 outputs (e.g., watermarking, provenance metadata), plus explainable generation settings for audits.
- Tools/workflows: Platform-side filters; provenance pipelines embedded in Cosmos-Framework; third-party audit APIs.
- Assumptions/dependencies: Standardized provenance frameworks, cross-platform adoption, adversarial robustness.
- Cross-embodiment transfer and fleet learning
- Sectors: robotics platforms, logistics networks
- What: Share a common backbone with embodiment-specific action adapters to propagate skills across robot types and sites; centralize learning while respecting local constraints.
- Tools/workflows: Domain-aware projection libraries; federated post-training; capability discovery and routing.
- Assumptions/dependencies: Consistent action semantics across fleets, privacy-preserving training, robust adapter calibration.
- On-device, privacy-preserving multimodal agents
- Sectors: consumer devices, wearables, automotive
- What: Edge-scale Cosmos 3 variants for real-time perception, short-horizon prediction, and local action, minimizing cloud dependency.
- Tools/workflows: Quantization/distillation; hardware-aware scheduling; hybrid on-device/cloud fallback.
- Assumptions/dependencies: Release and maturation of Cosmos3-Edge; memory and power constraints; thermal design; model safety on-device.
Notes on common dependencies and risks across applications:
- Compute and latency: Diffusion-based generation and joint attention are compute-intensive; production use may require model scaling strategies (distillation, caching, progressive inference).
- Data and calibration: Accurate time-aligned video/action/audio streams, correct FPS/sampling metadata (required by the absolute-temporal MRoPE), and reliable camera/pose calibration are critical.
- Safety and sim-to-real: Policies derived from synthetic or simulated data require staged validation and conservative deployment; uncertainty estimation is essential.
- Licensing and governance: Compliance with OpenMDW-1.1, asset/IP policies for synthetic media, and platform rules for generated content distribution.
- Security and misuse: Powerful text-to-video/image capabilities necessitate watermarking/provenance and moderation pipelines to mitigate deepfake or deceptive content risks.
Glossary
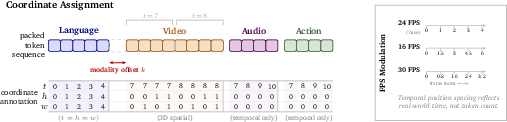
- 3D MRoPE: A 3D multimodal rotary positional embedding that splits positional encoding across temporal and spatial dimensions to align tokens across modalities. "we design a 3D MRoPE with absolute temporal indexing to align video, audio, and action tokens along the same physical temporal axis."
- 6D rotation representation: An over-parameterized representation of 3D rotations that improves continuity and learning stability compared to Euler angles or quaternions. "We use the 6D representation following~\citet{zhou2019continuity} and the OpenCV convention for rotations where the z-axis is along the fingers/grippers and x-axis is to the right."
- Action tokens: Learned tokens representing actions as a core modality, used to connect control signals with multimodal reasoning and generation. "Cosmos 3 treats action as a core modality, introducing a dedicated class of action tokens."
- Autoregressive (AR) subsequence: The front segment of the packed token sequence used for reasoning with causal attention (e.g., language and ViT-encoded vision). "The AR subsequence is responsible for reasoning and understanding."
- Begin-of-generation (BOG) token: A special token marking the transition point where generation begins in the packed sequence. "ending with <EOS> and a begin-of-generation token <BOG>,"
- Bidirectional attention: Attention that allows tokens to attend to both past and future positions (used for diffusion tokens). "Tokens in the DM subsequence use full bidirectional attention, with the union of AR and DM tokens serving as the keys and values."
- Causal self-attention: Attention constrained to past tokens only, preserving the autoregressive property for language/understanding. "Tokens in the AR subsequence attend only to tokens within the AR subsequence using causal self-attention;"
- DeepStack: A technique for aggregating multi-level vision features to enhance understanding. "we also aggregate visual features from ViT via DeepStack~\citep{meng2024deepstack}"
- Diffusion (DM) subsequence: The back segment of the packed token sequence containing noisy continuous tokens to be iteratively denoised for generation. "The diffusion subsequence follows the AR subsequence and contains video and image tokens from the VAE encoder, as well as audio and action tokens."
- Domain-aware input and output projection layers: Per-domain linear projections that map heterogeneous action vectors into and out of a shared latent action space. "We therefore use domain-aware input and output projection layers with separate weight matrices for each embodiment domain~\citep{zheng2026xvla}, while sharing the MoT backbone."
- Dual-stream joint attention: An attention mechanism where diffusion tokens attend to both AR and DM tokens, while AR tokens attend only within AR. "tokens from the diffusion subsequence interact with the AR subsequence through a dual-stream joint attention operation."
- Ego poses: The poses of the agent’s main observation frame (e.g., camera or body), used as part of the unified action representation. "actions can include up to three components: ego poses for the agent's main observation frame, effector poses for the agent's effectors, and grasp states for the manipulation state."
- Effector poses: The poses of the agent’s effectors (e.g., robot grippers or wrists) included in the action representation. "actions can include up to three components: ego poses for the agent's main observation frame, effector poses for the agent's effectors, and grasp states for the manipulation state."
- Flow-matching objective: A generative training objective that predicts a velocity field consistent with probability flow, used for diffusion-style generation. "trained in practice with a flow-matching objective predicting velocity; we show the clean target here for clarity"
- FPS modulation: A positional-embedding adjustment that aligns tokens from different sampling rates (e.g., video, audio, actions) onto a shared physical timeline. "FPS modulation is designed to align tokens with different temporal resolutions onto a shared physical temporal axis by modulating the effective size of each temporal increment."
- Forward dynamics: Predicting future states given current observations and actions, used for simulating world evolution. "Forward dynamics predicts future visual states conditioned on observed context and clean action tokens"
- Hop size: The number of audio samples between successive encoded frames, determining tokens-per-second for audio. "The raw stereo audio sampled at 48\,kHz is encoded with a hop size of 1920 samples, resulting in 25 tokens per second of audio."
- Inverse dynamics: Inferring the actions that caused an observed transition between states. "inverse dynamics infers the action tokens that explain an observed visual transition."
- Mixture-of-Transformers (MoT) architecture: A dual-tower transformer design with separate parameter sets for reasoning (AR) and generation (DM) that share attention. "Cosmos 3 adopts a Mixture-of-Transformers (MoT) architecture that processes a unified sequence of tokens from different modalities."
- Proportional–Integral–Derivative (PID): A classical control scheme characterized by proportional, integral, and derivative terms, often used in low-level actuation. "To avoid embodiment-specific controller details such as ProportionalâIntegralâDerivative (PID) parameters or low-level actuation interfaces,"
- Pseudo-actions: Action representations derived from state differences (e.g., relative pose changes) rather than direct controller commands. "ego and effector poses are represented as pseudo-actions derived from state differences."
- SE(3): The Lie group of 3D rigid body transformations (rotations and translations). "For consecutive poses and , we represent motion as the relative transform ."
- SO(3): The Lie group of 3D rotations represented by orthogonal matrices with determinant one. "We convert the predicted 6D rotation back to a rotation matrix using singular value decomposition (SVD)."
- Singular value decomposition (SVD): A matrix factorization used here to project 6D rotation predictions back onto a valid rotation matrix in SO(3). "We convert the predicted 6D rotation back to a rotation matrix using singular value decomposition (SVD)."
- Temporal steps per second (TPS): A rate defining how many positional steps correspond to one second of physical time for a token stream. "We first define the temporal steps per second (TPS) to characterize the physical temporal resolution."
- VAE: A variational autoencoder used to tokenize images/videos (and audio) into continuous latent tokens for diffusion-based generation. "The VAE compresses the input video temporally by and spatially by "
- ViT encoder: A Vision Transformer encoder used for visual understanding and alignment with language. "For visual understanding, we use a ViT encoder pre-trained with vision-language alignment."
- Video transfer: A conditional generation task that maps control videos (e.g., edges, depth) and text to RGB videos. "Video transfer. In this task, the input consists of a control video (\eg, edge, or depth) together with a text description, and the model generates the corresponding RGB video."
- Vision-Language-Action Model (VLA): A model class that predicts actions from vision and language inputs. "such as Vision-Language-Action Models (VLAs) and World-Action Models (WAMs)."
- Vision-LLM (VLM): A model class that jointly processes images/videos and text for understanding and reasoning. "initialized from the weights of a pre-trained Vision-LLM (VLM), allowing Cosmos 3 to inherit strong language and visual reasoning capabilities"
- World-Action Model (WAM): A model that predicts actions (and possibly state evolution) grounded in world observations. "such as Vision-Language-Action Models (VLAs) and World-Action Models (WAMs)."
Collections
Sign up for free to add this paper to one or more collections.