OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Abstract: World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper explains what “world models” in AI really are and introduces OpenWorldLib, a shared toolbox that helps different AI models work together like parts of the same system. Think of a world model as an AI “brain” that can:
- see and hear the world (perception),
- think about what it means (reasoning),
- remember what happened before (memory),
- and decide what to do next (actions), so it can predict and interact with the real world over time.
OpenWorldLib gives researchers one common way to plug in different skills—like making videos, building 3D scenes, or controlling robots—so they can reuse parts and compare methods fairly.
The main questions the paper asks
- What is a clear, simple definition of a “world model”?
- Which tasks truly count as world-model abilities, and which are often confused with them?
- How can we build one practical, unified framework where many different AI skills work together?
- How do 3D tools and simulators help world models understand and test the physical world?
- What directions should future world model research take?
How the researchers approached it (methods made simple)
First, the authors reviewed the history of world models and wrote a clear definition: a world model is a model or framework that uses perception, interaction (actions), and long-term memory to understand and predict how the world changes.
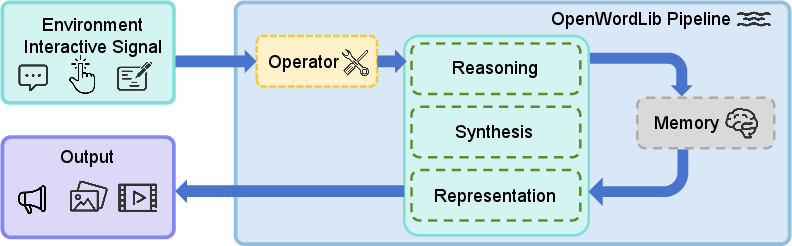
Then they designed OpenWorldLib—a “universal remote” or “operating system” for world-model parts. It standardizes how different models connect and talk to each other. You can imagine it like a robot student with organs:
- Operator: the “senses filter.” It checks and cleans up inputs (like resizing images or turning text into tokens) so the rest of the system understands them.
- Reasoning: the “thinking” part. It answers questions about what’s happening in images, videos, sounds, and space (like where objects are or what will happen next).
- Synthesis: the “imagination and expression” part. It creates images, videos, sounds, or even robot actions based on what the system has understood. For example, a “diffusion model” here is like starting with static noise and gradually “drawing” a clear picture or video.
- Representation: the “map builder.” It creates explicit 3D models of the world—like a digital diorama—so the AI can test ideas in a structured space, not just in pixels.
- Memory: the “long-term memory.” It stores important observations, plans, and results from earlier steps so the system stays consistent over time.
- Pipeline: the “conductor.” It coordinates the whole process from input to output and keeps the memory updated.
They also explain where simulators fit in. A simulator is like a sandbox video game world where the AI can practice safely and follow exact physics. The framework supports both local models and online services, and the team tested it on powerful GPUs across tasks like interactive video generation, 3D scene building, and robot-like action planning.
Technical terms in everyday language:
- Diffusion model: a method that turns random noise into a clear image or video step by step.
- 3D reconstruction: turning photos or videos into a 3D scene you can move around in.
- Simulator: a fake but realistic world where AI can test ideas without breaking real things.
- Vision-Language-Action (VLA): an AI that sees (vision), understands instructions (language), and does something (action).
What they found and why it matters
- A clear definition and scope for world models:
- True world-model abilities include:
- Interactive video prediction (e.g., guessing future frames based on actions)
- Multimodal reasoning (understanding and explaining across images, text, audio, time, and space)
- Vision-Language-Action (using perception and instructions to perform actions)
- 3D understanding and use of simulators (to keep a stable, testable world state)
- What is not a world model by itself:
- Plain text-to-video from a prompt (it can show physics-like effects but doesn’t “perceive” real inputs or interact over time)
- Code generation or web search-only systems (they don’t understand the physical world)
- Entertainment-only avatar video tasks (they don’t focus on real-world understanding)
- A unified framework (OpenWorldLib) that actually works:
- It connects many different models in one place, so researchers can reuse parts and run “collaborative inference” (models helping each other).
- It handles the whole loop: take in real-world signals, reason, imagine/generate results, store memory, and act.
- It standardizes how models plug in (shared templates and APIs), which makes it easier to test, compare, and build bigger systems.
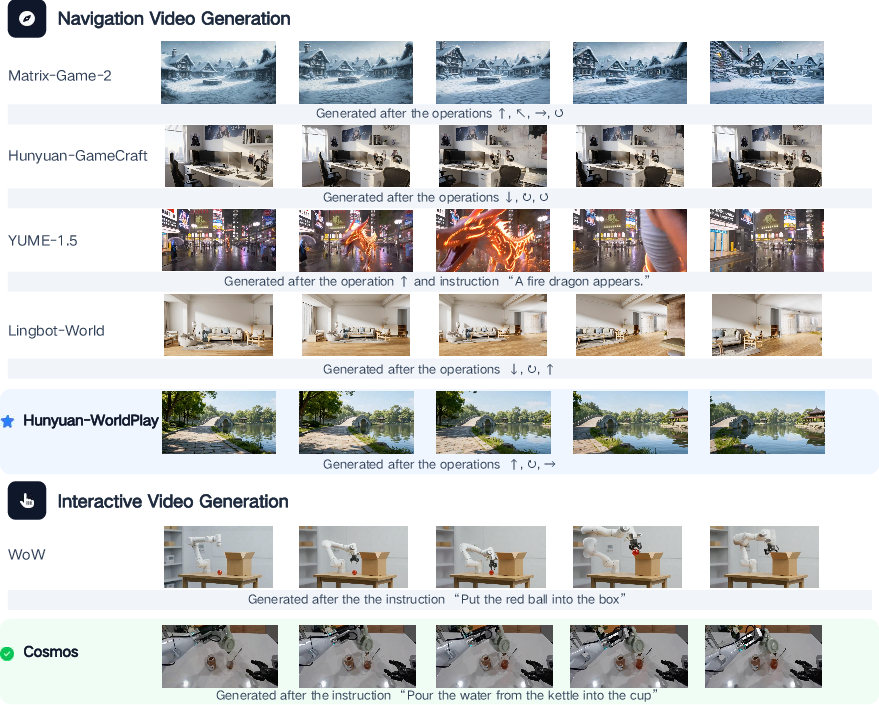
- Practical tests across important tasks:
- Interactive video generation: the framework runs multiple methods and shows how quality varies over long sequences (some models drift in color or consistency; newer ones keep scenes more stable during navigation).
- 3D generation and reconstruction: some systems build scenes quickly but struggle with sharp details or consistent geometry when the camera moves a lot; still, 3D remains essential for accurate physics and long-term consistency.
- Vision-Language-Action (in simulators like AI2-THOR and LIBERO): the system evaluates action models that combine vision and language to perform tasks, and also models that predict future visuals to guide actions. This helps test whether the AI can not just “talk about” the world but also do things in it.
Why this matters:
- The field has lacked a common definition and common tools. This paper gives both, which speeds up progress and helps everyone compare fairly.
What this could change in the future (impact)
- Standardization: With OpenWorldLib, researchers can build more complex, real-world-capable AI faster because parts fit together more easily.
- Better real-world agents: The focus on memory, interaction, and 3D/simulators brings AI closer to being useful in robotics, AR/VR, assistive devices, and driving.
- Data and hardware shifts: The authors suggest that while predicting future video frames carries lots of useful information, it’s heavier than predicting text tokens. So we’ll need better hardware and possibly new model designs to make this efficient. They also highlight the growing importance of high-quality, well-prepared multimodal data to train these systems.
- LLMs as a backbone: LLMs can be extended to also “see” and “act.” Combining their reasoning skills with strong perception and memory may be a practical path to full world models.
In short, the paper gives the field a common language and a practical toolbox. It sets clear goals for what world models should do, filters out what they’re not, and offers a framework to build and test them—bringing AI a step closer to understanding and acting in our complex, physical world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes a unifying definition and a modular inference framework (OpenWorldLib) for world models, but several aspects remain underspecified or unevaluated. Below is a concise, actionable list of gaps to guide future work:
- Lack of formal, testable criteria for “what counts” as a world model
- No measurable definition or pass/fail protocol for the proposed capability set (perception, interaction, long-term memory). Define task-agnostic diagnostics, unit tests, and threshold metrics.
- Missing standardized benchmarks and metrics
- No quantitative evaluation suite for interactive video, VLA, 3D reconstruction, multimodal reasoning, or memory. Specify datasets, metrics (e.g., action-conditioned prediction error, long-horizon consistency, spatial/temporal grounding accuracy, uncertainty calibration, latency), and protocols.
- Insufficient empirical evaluation
- Results are qualitative and comparative by name; no ablations, baselines, or statistical analyses. Provide reproducible experiments with metrics, seeds, and confidence intervals.
- Unclear interoperability across modules
- The framework outlines modules (Operator/Reasoning/Synthesis/Representation/Memory/Pipeline) but lacks concrete interface contracts (schemas, tensor shapes, timing alignment) and error-handling across modules. Publish strict interface specs and validation tests.
- Memory module design is under-specified
- No concrete algorithms for retrieval, indexing, compression, forgetting, cross-session isolation, and consistency maintenance. Evaluate retrieval efficacy (precision/recall), staleness detection, and catastrophic interference.
- No uncertainty handling or state estimation protocol
- The framework does not define probabilistic state representations, confidence estimates, or uncertainty propagation from perception to action. Integrate Bayesian/ensembles and evaluate calibration.
- Missing criteria for choosing implicit vs explicit representations
- No guidance on when to rely on next-frame prediction vs explicit 3D state, or how to fuse them. Define decision policies, switching costs, and performance trade-off evaluations.
- Action space standardization is not operationalized
- The text promises unified mapping from discrete/continuous actions to simulators/robots, but no canonical action schema, units, constraints, or safety envelopes are specified. Provide an extensible action ontology and validation toolkit.
- Real-time and systems constraints unaddressed
- No latency, throughput, scheduling, or memory-footprint profiling for multi-module pipelines; no deadlines or QoS policies for real-time control. Benchmark end-to-end latency and propose schedulers.
- Simulator-to-real transfer
- The framework evaluates in simulators but does not address sim-to-real gaps, domain randomization, sensor noise, or hardware calibration. Include real-robot trials and transfer metrics.
- Safety, robustness, and failure modes
- No discussion of safe action constraints, out-of-distribution detection, adversarial robustness, or rollback mechanisms. Define safety layers, guardrails, and failure taxonomies with tests.
- Data governance and ethics
- No treatment of data provenance, privacy in long-term memory, bias/imbalance in training/evaluation data, or compliance. Introduce data cards, access control for memory, and fairness audits.
- Training integration and continual learning
- The library targets inference; no end-to-end training or continual adaptation pipeline is provided (fine-tuning, RL, online learning, replay buffers). Add training hooks and protocols for safe continual updates.
- Cross-modality time synchronization
- Procedures for synchronizing audio, video, proprioception, and actions are unspecified. Define clock models, buffering, and alignment validation.
- Evaluation of multimodal reasoning is incomplete
- Spatial/temporal/causal reasoning capabilities lack formal tasks (e.g., scene graphs, temporal ordering, counterfactuals) and ground-truth annotations. Curate labeled benchmarks and scoring methods.
- World-state persistence and identity tracking
- No mechanisms or metrics for object permanence, identity tracking across views/time, or long-horizon world consistency. Propose persistent state models and consistency checks.
- Resource efficiency and scalability
- No analysis of GPU/CPU usage, model parallelism, caching, or incremental computation. Provide profiling tools and recipes for low-resource and large-scale deployments.
- Integration with 3D engines and physics
- Representation module mentions export to engines but lacks reference adapters, coordinate conventions, unit standards, or differentiable physics integration. Publish adapters and conformance tests.
- API-based model reliance risks
- Cloud API integration is planned but versioning, rate limits, fallbacks, and reproducibility (determinism across providers) are not addressed. Define API contracts, pinning/version tests, and local fallbacks.
- Benchmarking long-horizon interaction
- No standardized tasks for multi-episode, goal-conditioned interaction with memory carry-over and evaluation of cumulative error. Create multi-episode suites with success, regret, and recovery metrics.
- Hardware–algorithm co-design left conceptual
- The need for hardware suited to next-frame prediction is noted, but no concrete co-design proposals or simulated performance studies are provided. Prototype token-free pipelines or frame-native accelerators in emulation.
- Model coverage and plug-in ecosystem
- The paper claims unified integration but does not enumerate supported models, adapters, or contribution standards. Provide a registry, adapter templates, CI tests, and minimal working examples.
- Reproducibility and environment management
- No pinned dependencies, container images, or deterministic settings across A800/H200 and other hardware. Release reproducible environments (containers), seed control, and cross-hardware validation reports.
- Multi-agent and collaborative settings
- The framework focuses on a single agent; coordination, communication protocols, and shared memory for multi-agent world models remain unexplored. Define APIs and benchmarks for multi-agent interaction.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging OpenWorldLib’s unified inference framework, standardized module interfaces (Operator, Synthesis, Reasoning, Representation, Memory, Pipeline), and simulator integrations (AI2-THOR, LIBERO).
- Unified multimodal inference SDK for rapid prototyping (Software, Academia, Robotics)
- Summary: Use OpenWorldLib’s Base* templates and Pipeline to quickly stitch together perception, reasoning, and generation across image/video/audio/VLA backends under one API.
- Tools/products/workflows: “World Model SDK” for Python; plug-in backends for diffusion video generators, MLLMs, 3D reconstruction; local vs cloud endpoints via api_init().
- Assumptions/dependencies: Availability of compatible pretrained checkpoints; GPU access (A800/H200 or cloud); licensing for third-party models; developer expertise in Python/ML.
- Standardized evaluation harness for world-model capabilities (Academia, Policy, Software)
- Summary: Benchmark interactive video generation, multimodal reasoning, 3D reconstruction, and VLA using a single orchestration layer for fair comparison and reproducibility.
- Tools/products/workflows: Reproducible scripts driving AI2-THOR and LIBERO; shared logging and Memory module for run traces; evaluation dashboards.
- Assumptions/dependencies: Stable simulator versions; consistent seeds and model versions; agreed metrics.
- Robot policy prototyping with VLA signal synthesis and simulators (Robotics)
- Summary: Rapidly test action-conditioned policies via the “Other Signal Synthesis” branch to translate multimodal context into actions for manipulation or navigation in LIBERO/AI2-THOR.
- Tools/products/workflows: ROS2 bridge adapters; action space alignment utilities; closed-loop evaluation in sim; export of executable sequences to hardware-in-the-loop rigs.
- Assumptions/dependencies: Accurate action-space mapping; safety interlocks for hardware; sim-to-real gap awareness.
- Synthetic data generation for perception pipelines (Automotive, Robotics, Media/Entertainment)
- Summary: Use interactive video generation and 3D reconstruction to create task-targeted synthetic datasets for detection, tracking, and scene understanding.
- Tools/products/workflows: Scenario scripts that drive camera paths and control inputs; batch generation; paired labels from 3D representations (depth, poses).
- Assumptions/dependencies: Domain gap calibration; quality controls on physics and visual consistency; storage/throughput for large video assets.
- AR/VR scene capture and reconstruction pipeline (AR/VR, Real Estate, Education)
- Summary: Convert single/multi-view images into 3D scene proxies, enabling rapid environment bootstrapping for XR applications or instructional content.
- Tools/products/workflows: Representation module for depth/point clouds/camera poses; export to Unity/Unreal; viewpoint scripting for walkthroughs.
- Assumptions/dependencies: Robustness to challenging lighting/texture; downstream engine import compatibility; user calibration for scale/metric accuracy.
- Multimodal reasoning assistant for physical-world QA (Education, Software, Customer Support)
- Summary: Deploy MLLMs within the Reasoning module to answer spatial/temporal/causal questions about images/videos or annotated scenes.
- Tools/products/workflows: Structured prompts plus perceptual inputs; memory-backed context retrieval; explainability logs (rationales, bounding info).
- Assumptions/dependencies: Model coverage of domain-specific knowledge; limits of current spatial reasoning accuracy; privacy/PII in uploaded media.
- Content creation workflows with synchronized video and audio generation (Media/Entertainment, Marketing)
- Summary: Combine visual and audio synthesis branches for storyboards, ads, or tutorial videos with better physical continuity and timing controls.
- Tools/products/workflows: Text/image conditioning; frame-budget and timing control; audio guidance settings; batch render pipelines.
- Assumptions/dependencies: Rights for training data; approval for generative outputs; brand safety and QC.
- Curriculum and lab adoption for “world model” teaching (Academia)
- Summary: Use OpenWorldLib as a teaching scaffold for courses on multimodal AI, robotics, and simulation by exposing consistent base classes and end-to-end pipelines.
- Tools/products/workflows: Classroom labs on video prediction, spatial reasoning, VLA; standard assignments and rubrics.
- Assumptions/dependencies: GPU quotas in teaching labs; curated pretrained checkpoints; simplified install docs.
- MLOps-friendly multimodal service adapters (Software)
- Summary: Operate local or cloud synthesis/reasoning/representation services behind the same API for cost-performance flex.
- Tools/products/workflows: api_init() connectors; telemetry hooks; autoscaling policies for batch inference.
- Assumptions/dependencies: Stable vendor APIs; cost controls; data governance for uploaded content.
- Terminology and taxonomy alignment for proposals and reviews (Policy, Funding, Standards)
- Summary: Adopt the paper’s stricter definition of “world models” (perception-centered + interaction + long-term memory) to prevent mislabeling (e.g., pure text-to-video).
- Tools/products/workflows: Checklists for grant solicitations; procurement criteria; peer review guidelines using capability categories (perception, interaction, memory, multimodal output).
- Assumptions/dependencies: Willingness of agencies and venues to adopt shared terminology; consensus-building in the community.
Long-Term Applications
These applications are enabled by OpenWorldLib’s architectural unification and by the paper’s future directions (latent reasoning, LLM/VLM backbones, hardware co-design for next-frame prediction), but require further research, scaling, or integration.
- Embodied household assistants with persistent memory and predictive control (Robotics, Consumer)
- Summary: Robots that perceive, reason, predict, and act over long horizons in homes, leveraging unified perception–action–memory loops.
- Tools/products/workflows: VLA policies + visual prediction synthesis; Memory for routines and layouts; 3D representations for stable world state.
- Assumptions/dependencies: Robust navigation/manipulation; on-device inference; safety and failover policies; durable hardware; privacy-preserving memory.
- Autonomous driving with explicit representations and future-frame prediction (Automotive)
- Summary: Closed-loop stacks that couple multimodal reasoning, next-frame predictions, and long-term memory for planning and uncertainty-aware control.
- Tools/products/workflows: BEV/3D state maintenance; camera-controlled video prediction for “what-if” planning; scenario simulators fused with real data.
- Assumptions/dependencies: Regulatory approval; certifiable reliability; real-time constraints; robust sensor fusion; adversarial resilience.
- Enterprise digital twins and decision rehearsal with dynamic scene generation (Manufacturing, Energy, Logistics)
- Summary: Forecasting and optimization in plants/sites using explicit 3D states and implicit predictive generators to simulate interventions at scale.
- Tools/products/workflows: Rapid 3D scene bootstrapping (FlashWorld-class); action-conditioned simulations; RL-in-the-loop for policy improvement.
- Assumptions/dependencies: Accurate physical models; integration with industrial control systems; data security; operator trust.
- Simulation-based safety certification frameworks for embodied AI (Policy, RegTech, Insurance)
- Summary: Regulatory testbeds that measure perception, interaction, and memory criteria with standardized tasks and logs prior to real-world deployment.
- Tools/products/workflows: Conformance test suites built on OpenWorldLib pipelines; traceable Memory logs; red-teaming libraries.
- Assumptions/dependencies: Standards adoption by regulators; harmonized metrics across sectors; transparent reporting.
- Latent-reasoning world models for high-dimensional continuous data (Academia, Software)
- Summary: Models that reason in latent spaces beyond text tokens for more efficient and physically faithful inference over video/audio/3D streams.
- Tools/products/workflows: Training recipes for latent planners; integration into Reasoning module; evaluation against spatial/causal tasks.
- Assumptions/dependencies: New training corpora; scalable compute; benchmarks for latent reasoning; interpretability methods.
- Hardware–algorithm co-design for frame-centric world modeling (Semiconductors, Cloud)
- Summary: Accelerator architectures and kernels optimized for next-frame prediction and spatiotemporal reasoning rather than token-centric throughput.
- Tools/products/workflows: Custom schedulers/solvers for diffusion/flow; memory hierarchies tuned for video tensors; compiler support.
- Assumptions/dependencies: Vendor roadmaps; ecosystem support (PyTorch/TVM); sufficient demand from robotics/AV.
- Privacy-preserving multimodal memory for real-world agents (Security/Privacy, Healthcare, Finance)
- Summary: On-device or encrypted Memory designs that retain long-term context without exposing sensitive audio/video or action histories.
- Tools/products/workflows: Federated logging; differential privacy; secure enclaves; retention policies and user controls.
- Assumptions/dependencies: Legal compliance (GDPR/CCPA/HIPAA); performance overheads; user trust and UX.
- Cross-domain XR copilots with spatially-grounded assistance (Education, Field Services, Retail)
- Summary: Wearable/AR assistants that recognize spaces, reason about layouts, and provide step-by-step guidance with predictive visuals and audio.
- Tools/products/workflows: On-device 3D reconstruction; spatial reasoning; synchronized audio-visual prompts; session memory for continuity.
- Assumptions/dependencies: Battery and compute constraints; robust tracking in the wild; content safety; network availability.
- Standardization of world-model APIs and benchmarks (Policy, Standards Bodies, Open Source)
- Summary: Industry-wide adoption of OpenWorldLib-like module contracts and capability taxonomies to enable interoperability and fair benchmarking.
- Tools/products/workflows: Reference APIs (BaseOperator/BaseSynthesis/BaseReasoning/BaseRepresentation/BaseMemory); shared leaderboards.
- Assumptions/dependencies: Community consensus; maintenance funding; neutral governance.
- RL-enhanced 3D asset and scene generation for interactive media (Gaming, Metaverse, Media)
- Summary: Use reinforcement learning with explicit simulators and world-model feedback to generate assets that meet gameplay and physical criteria.
- Tools/products/workflows: Action-conditioned 3D generation loops; physics-consistency rewards; creator toolchains that auto-test assets in sandboxes.
- Assumptions/dependencies: Fast, high-fidelity simulators; stable 3D generative backbones; IP/licensing frameworks.
- Healthcare training and teleoperation with physically consistent simulators (Healthcare, EdTech)
- Summary: Surgical or rehabilitation training environments that combine predictive video, 3D representations, and action synthesis for skill transfer.
- Tools/products/workflows: Haptic-feedback integration; scenario libraries; assessment via reasoning and memory logs.
- Assumptions/dependencies: Clinical validation; device regulation; high-fidelity biomechanics; secure data handling.
- City-scale planning assistants integrating causal/temporal reasoning (Public Policy, Urban Planning)
- Summary: Tools that simulate interventions (traffic, zoning, emergency response) using multimodal evidence and long-horizon predictive models.
- Tools/products/workflows: Data fusion from sensors/videos/maps; scenario scripting; stakeholder dashboards with explainable outputs.
- Assumptions/dependencies: Data access agreements; governance and transparency; robustness to uncertainty and confounders.
Glossary
- 3D reconstruction: Recovering explicit 3D structure from images or videos (e.g., point clouds, depth, poses). "3D Reconstruction: It transforms input data into explicit 3D outputs"
- Action space: The set of all possible actions an agent can execute in an environment. "drawn from an action space that has been broadened to encompass diverse operations and task-specific outputs such as generation and manipulation"
- Action-conditioned simulation: Simulation whose predictions depend on chosen actions, enabling planning and control. "equipped with action-conditioned simulation and long-term memory capabilities"
- AI2-THOR: A photorealistic interactive simulator for embodied AI research and evaluation. "AI2-THOR~\cite{kolve2017ai2} for embodied video generation"
- Audio reasoning: Inferring semantic or structural information from audio signals. "Audio Reasoning: Models that interpret and reason over auditory signals."
- Camera poses: The position and orientation of a camera in 3D space. "point clouds, depth maps, and camera poses."
- Closed-loop interaction: Continuous perception–action cycles where outputs affect subsequent inputs. "advancing the closed-loop interactive capabilities of models in the real world."
- Conditional probability distributions: Probabilistic formulations defining dynamics, observations, and rewards given states and actions. "defined by three core conditional probability distributions:"
- Depth estimation: Predicting scene depth from visual inputs. "depth estimation~\cite{lin2025depth}"
- Diffusion models: Generative models that iteratively denoise data to synthesize images or videos. "leveraging diffusion models~\cite{ho2022imagen, huang2026vidworld} to achieve higher-quality interactive video generation"
- Flow-based cores: Generative components based on invertible flows for tractable likelihood and synthesis. "diffusion- or flow-based cores"
- Guidance strength: A control parameter that adjusts conditioning influence in guided generation (e.g., diffusion). "guidance strength"
- Hybrid memory: A memory mechanism combining multiple storage types or modalities for long-context tasks. "utilize hybrid memory for long-context reconstruction"
- Large view synthesis: Generating novel views across wide baselines or extreme camera motions. "large view synthesis~\cite{jin2024lvsm}"
- Latent decoders: Generative decoders operating in compressed latent spaces rather than pixel space. "text encoders, latent decoders, and diffusion- or flow-based cores"
- Latent reasoning: Implicit, non-textual reasoning over learned representations to model complex dynamics. "utilizing latent reasoning~\cite{assran2025v,Monet} to analyze complex dynamics"
- Latent state: A compact internal representation capturing relevant information for prediction and control. " denotes the latent state"
- LIBERO: A benchmark/simulator suite for evaluating vision-language-action manipulation. "and LIBERO~\cite{liu2023libero} for Vision-Language-Action (VLA) evaluation"
- Long-horizon dependencies: Dependencies spanning many time steps that require memory to handle effectively. "long-horizon dependencies"
- Metric 3D reconstruction: 3D recovery with real-world scale and geometry consistency. "metric 3D reconstruction~\cite{keetha2025mapanything}"
- Mixture-of-Experts (MoE): An architecture with multiple expert submodels gated per input for improved capacity and specialization. "mixture-of-experts (MoE) action heads"
- Multimodal LLMs (MLLMs): LLMs extended to process and reason over multiple modalities. "utilizing Multimodal LLMs (MLLMs) to directly predict actions"
- Next-frame prediction: Predicting future video frames conditioned on past frames (and possibly actions). "Next-frame prediction is widely regarded the most recognized paradigm by world model researchers~\cite{ha2018world}"
- Next-token prediction: Autoregressive prediction of the next discrete token in a sequence. "next-token prediction"
- Observation model: The probabilistic mapping from latent states to observed sensory data. "Observation model:"
- Omni reasoning: General-purpose multimodal reasoning across diverse inputs and tasks. "omni reasoning"
- Permutation-equivariant visual geometry: Representations whose outputs are invariant to permutations of input elements, aiding geometric understanding. "permutation-equivariant visual geometry~\cite{wang2025pi}"
- Persistent 3D state: A long-lived 3D representation maintained across time for consistent scene understanding. "maintain a persistent 3D state"
- Proprioception: Internal sensing of an agent’s own configuration (e.g., joint angles, velocities). "proprioception"
- Proprioceptive histories: Time series of internal body-state measurements used for action synthesis and control. "proprioceptive histories"
- Reward model: The probabilistic mapping from states and actions to rewards. "Reward model:"
- Schedulers or solvers: Numerical procedures controlling the sampling or denoising steps in generative pipelines. "with schedulers or solvers appropriate to each task"
- State transition model: The probabilistic dynamics mapping current state and action to next state. "State transition model:"
- Token-based Transformers: Transformer architectures operating over discrete token sequences. "token-based Transformers may need to evolve"
- Vision-Language-Action (VLA): Models integrating perception, language, and action for embodied control. "Vision-Language-Action (VLA)"
- Visual geometry grounded transformers: Transformer models that fuse vision with geometric priors for 3D understanding. "use visual geometry grounded transformers to link image inputs with real geometric structures."
Collections
Sign up for free to add this paper to one or more collections.