MOSS-Audio Technical Report
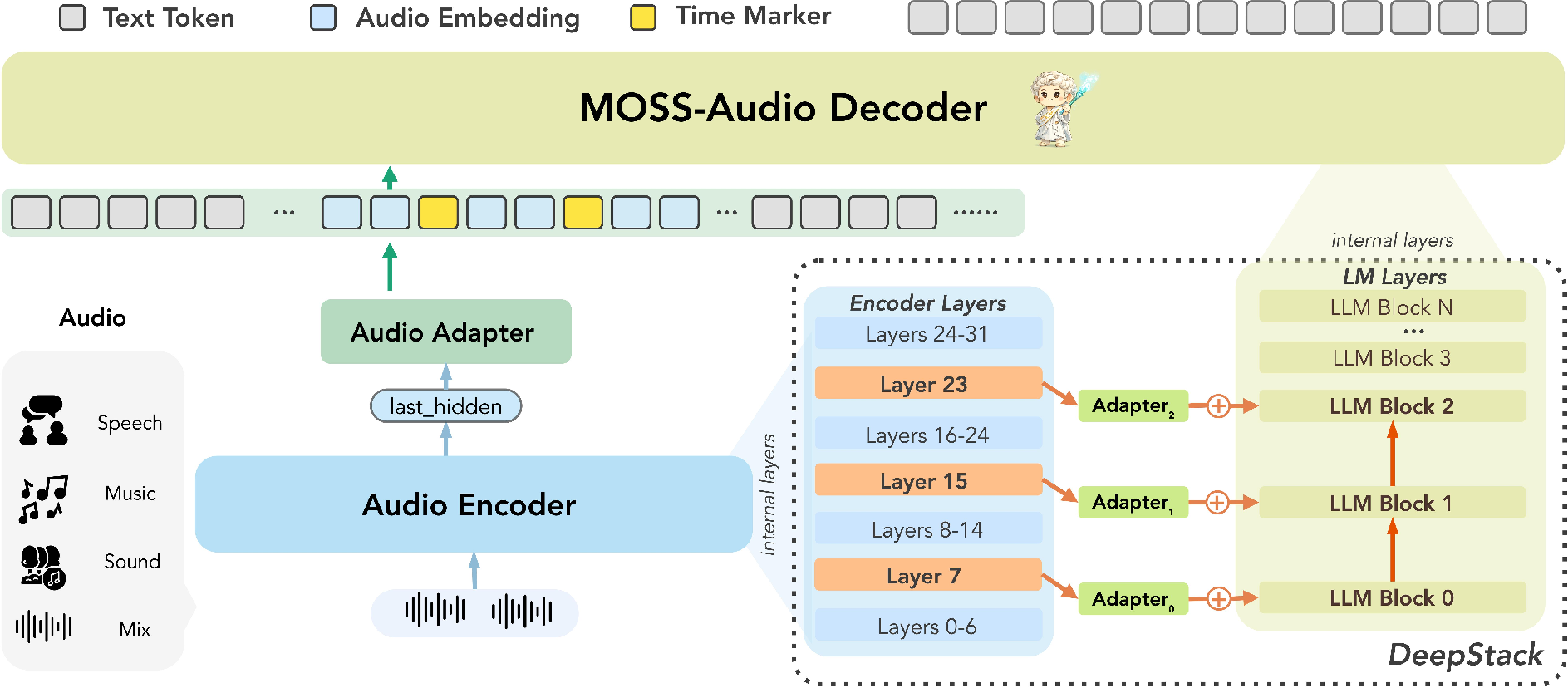
Abstract: MOSS-Audio is a unified audio-LLM for speech, environmental sound, and music understanding, supporting audio captioning, time-aware question answering, timestamped transcription, and audio-grounded reasoning. MOSS-Audio couples a dedicated audio encoder with a modality adapter and a LLM: the encoder produces 12.5 Hz temporal representations, the adapter projects them into the decoder space, and the decoder generates autoregressive text outputs. Two design choices are central to the system: \textbf{DeepStack cross-layer feature injection}, which exposes the decoder to acoustic information from multiple encoder depths, and \textbf{time markers}, which provide explicit temporal cues by inserting timestamp markers into the audio-token stream. At the data level, we design an event-preserving audio annotation pipeline that segments raw audio at coherent event boundaries, applies branch-specific annotation to speech, music, and general audio, and merges the results into unified captions for pretraining. The intermediate branch-specific captions are further retained to support the construction of task-oriented SFT data. The model is pretrained on large-scale audio-language data, with time-aware objectives incorporated to support temporal grounding, and then undergoes multi-stage post-training to enhance instruction following and audio-grounded reasoning. We release 4B and 8B variants in both Instruct and Thinking configurations. MOSS-Audio achieves strong performance across general audio understanding, speech captioning, ASR, and timestamped ASR, positioning it as a promising understanding foundation for future voice agents.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MOSS-Audio, a smart system that can listen to all kinds of sounds—speech, everyday noises, and music—and then explain what it hears in words. It can write captions for audio, answer questions about what’s happening and when, transcribe speech with timestamps, and reason about complicated sound scenes. The team built one unified model so you don’t need different tools for each audio task.
What questions did the researchers ask?
In simple terms, the team asked:
- Can we build one audio “brain” that understands many types of sounds (speech, environment, music) instead of separate tools for each?
- Can this model not only recognize “what” is happening but also “when” it happens?
- Can it follow instructions, give clear answers, and reason about complex audio situations like overlapping sounds or long recordings?
How did they build the system?
The model’s parts (think: ears, translator, storyteller)
- Audio encoder (the “ears”): Listens to the sound and turns it into a stream of small summaries about 12 times per second. This keeps track of details over time.
- Modality adapter (the “translator”): Converts those audio summaries into a form a LLM can understand.
- LLM decoder (the “storyteller”): Uses the translated audio plus your instruction to write text—like captions, answers, or transcripts.
This setup is called encoder–adapter–decoder. It lets the model combine strong listening skills with strong language skills.
Two key ideas that make it better
- DeepStack cross-layer injection: Instead of only using the encoder’s final output (which can lose fine details), the model also taps into earlier layers. Imagine writing a report and keeping notes from every draft, not just the final one. This preserves tiny sound cues (like tone, rhythm, brief beeps) and big-picture meaning at the same time.
- Time markers: The model inserts little “time stamps” throughout the audio features, like mile markers on a road or time codes on a video timeline. This teaches the model to talk about when events happen, which helps with timestamped transcripts and time-aware questions.
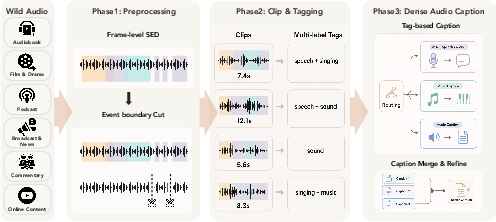
How they prepared the data (like editing a movie at scene changes)
- Event-preserving segmentation: Instead of cutting audio every fixed number of seconds, they split it at natural “event boundaries” (for example, when a speaker finishes a sentence or a sound effect ends). That keeps complete moments together.
- Branch-specific labeling:
- Speech branch: Transcribes words, aligns them to time, and describes speakers (emotion, speed, accent, etc.).
- General-audio branch: Describes environmental sounds, scenes, and how events change over time.
- Music branch: Captures musical details like genre, instruments, beat, chords, sections (intro, verse, chorus), and lyrics timing if present.
- Caption merge: These different pieces are combined into one clear caption per clip, so the model learns a unified picture.
- Some data is synthetic: They also create controlled audio examples (like mixing known sounds with exact timestamps) to teach precise timing and rare cases.
How they trained the model
- Pretraining: The model learns three things together:
- Transcribing speech (with and without timestamps)
- Writing captions about audio scenes
- Regular text learning (to keep language skills sharp)
- Post-training in stages:
- Supervised fine-tuning: Teaches the model to follow instructions and output in the right format.
- Reasoning “cold start”: Trains it to explain its thinking and connect answers to audio evidence.
- Reinforcement learning: Improves correctness, stability, and avoids overly long or messy answers by rewarding better responses.
They release two sizes (about 4B and 8B parameters) and two styles:
- Instruct: Best for straightforward tasks like transcription and captioning.
- Thinking: Better at multi-step reasoning about audio.
What did they find?
Here are the main results and why they matter:
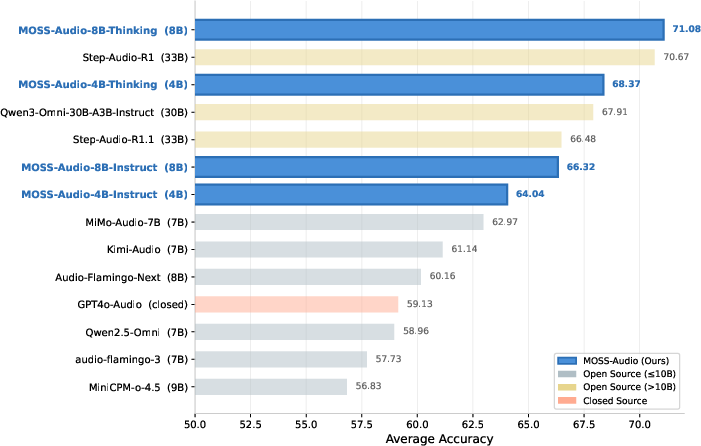
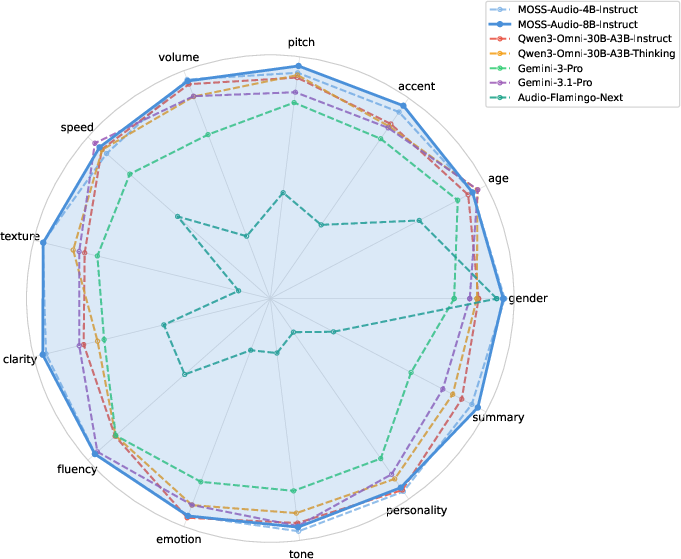
- The model performs strongly across many tasks: general audio understanding, speech captioning, regular ASR (speech-to-text), and ASR with timestamps. This shows one model can handle many audio jobs well.
- The “Thinking” versions do better on reasoning-heavy tests (for example, answering complex questions about overlapping events or long recordings), which is important for real-world voice assistants.
- The “Instruct” versions are more stable for direct tasks like transcription and captioning.
- Despite being compact (4B and 8B), MOSS-Audio matches or beats many larger open-source models on several benchmark suites. That means it’s efficient and powerful.
Why does this matter?
- Better voice assistants: A single model that understands speech, sounds, and music—and knows when things happen—can power smarter assistants that do more than just transcribe.
- Time-aware understanding: Adding time markers helps the system say not only “what” happened but also “when,” which is crucial for real recordings, meetings, podcasts, and videos.
- One model for many jobs: Instead of stitching together multiple tools, developers can use one foundation that handles transcription, captioning, Q&A, and reasoning.
- Stronger, fairer training: Cutting audio at natural boundaries and merging specialized annotations gives the model clearer, more accurate lessons, which improves real-world behavior.
- Open releases: With 4B and 8B “Instruct” and “Thinking” variants, the community can build on this work for education, accessibility, media tools, and safer voice tech.
In short, MOSS-Audio shows that a unified, time-aware audio–LLM can both recognize fine details (like exact words and timestamps) and reason about complex sound scenes. That makes it a promising foundation for the next generation of voice-based applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address to strengthen the claims and broaden the applicability of MOSS-Audio.
- Lack of ablation studies isolating contributions of DeepStack cross-layer injection and explicit time markers (e.g., remove each, vary injection layers/aggregation, compare GatedMLP vs linear/cross-attention adapters).
- Unexplored design space for time markers: frequency (2 s vs finer/coarser), absolute vs relative markers, learned vs numeric tokens, and their impact on timestamp accuracy and sequence length.
- Potential ambiguity between numeric time-marker tokens and numeric transcripts (e.g., digits in speech); no disambiguation strategy or tokenization scheme is described.
- Fixed 12.5 Hz encoder token rate may be too coarse for fine-grained phonetic/prosodic tasks and tight timestamps; no experiments with multi-scale or adaptive token rates.
- Encoder sliding-window attention limited to 100 frames (~8 s) delegates long-range audio dependencies to the LLM without analysis of effects on tasks needing minute-scale temporal structure (e.g., music form, long scenes).
- No quantitative evaluation of long-context audio (tens of minutes) or memory/latency trade-offs when interleaving time markers across long sequences.
- Injection strategy is under-specified experimentally: which decoder layers receive cross-layer features, how many, and the performance vs compute/latency trade-off of different injection patterns.
- Adapter choice not compared to alternative conditioning mechanisms (e.g., cross-attention, Perceiver-style latent adapters, FiLM, prefix tuning).
- Training from-scratch encoder vs initializing from strong ASR/self-supervised encoders (wav2vec 2.0, w2v-BERT, HuBERT, WavLM) is not benchmarked for quality/compute trade-offs.
- No systematic study of pretraining mixture ratios (30% ASR, 40% captioning, 30% text-only): sensitivity, interference across tasks, and catastrophic forgetting of language ability.
- Reward design for DAPO RL is under-specified: how “correctness” is scored for audio QA, reliability of automatic graders, and safeguards against reward hacking.
- Missing quantitative grounding metrics for hallucination reduction (e.g., audio-grounded factuality, evidence attribution, counterfactual audio tests).
- Limited robustness analysis: performance under noise, reverberation, far-field microphones, codec distortions, adversarial perturbations, and overlapping speech is not reported.
- Multilingual coverage is unclear: language distribution, code-switch handling, low-resource languages, tonal languages, and non-Latin scripts; no multilingual ASR/captioning benchmarks are provided.
- Bias and fairness risks are unmeasured: accent, gender/age emotion inference bias, and cross-lingual fairness in ASR, captioning, and QA.
- Event-preserving segmentation relies on SED quality; no error analysis of boundary errors, their propagation to captions/QA, or mitigation strategies.
- Router-R1 thresholding and entropy-based routing are not validated for failure modes (e.g., suppressing weak-but-important signals, retaining spurious ones); no calibration or QoE metrics.
- Heavy reliance on pseudo-labels (ASR ensemble, SED, MIR tools) risks propagating upstream model biases; no comparison to human-verified subsets or confidence-weighted training.
- Filtering high-disagreement ASR segments may remove hard but important examples; no study on robustness cost vs noise reduction or on curriculum strategies.
- Diarization errors (speaker ID merges/splits) and their impact on speech captions and QA are not quantified.
- Music branch lacks task-specific evaluation: accuracy of key/chords/tempo/structure vs MIR ground truth (e.g., Billboard, SALAMI, Isophonics); no A/B of “holistic ALM caption” trust heuristic.
- Timestamped reasoning/QA is asserted but not rigorously evaluated on public temporal grounding benchmarks with standard metrics (e.g., event F1, tIoU, NER-level alignment).
- ASR and timestamped ASR results are summarized without detailed breakdowns by domain, noise condition, speaker demographics, language, and utterance length.
- General audio understanding benchmarks risk data leakage; no train–test deduplication, contamination checks, or per-benchmark overlap analysis with the massive pretraining corpus.
- Synthetic TAC data benefits and risks are unquantified: transfer to real audio, overfitting to synthetic compositional patterns, and robustness to timestamp jitter.
- Streaming capability is claimed (KV caching) but lacks end-to-end latency/throughput benchmarks (CPU/GPU/edge), chunking strategies, and real-time timestamp stability.
- Memory/compute footprint and scalability are not reported (encoder 0.6B + 4B/8B LLM): throughput per second of audio, inference cost vs baseline models, and on-device feasibility.
- Modality over-reliance: text-only reasoning may overshadow audio cues; no diagnostics for “text-only surrogate reasoning” or training controls (e.g., audio-muting counterfactuals).
- Uncertainty estimation is absent: no confidence calibration for transcripts, timestamps, or QA answers; no abstention or defer-to-human mechanisms.
- Multi-channel/spatial audio and array processing are unsupported; no exploration of binaural/ambisonics or spatial reasoning tasks.
- Sample-rate and music-fidelity concerns are unaddressed (e.g., 16 kHz vs 44.1 kHz); impact on music timbre/prosody and downstream caption quality is unknown.
- Safety, privacy, and licensing gaps: handling PII in speech, diarization ethics, copyrighted music in training/outputs, and dataset/tool licenses are not discussed.
- Reproducibility is limited: the “millions of hours” corpus, routing policies, and annotation prompts/tools are not fully released; compute budgets and hyperparameters are insufficiently detailed.
- Scalability/open questions: do larger LLM backbones vs stronger encoders yield better returns; can smaller LLMs with richer encoders match 8B variants; what are scaling laws for audio–language fusion.
These gaps suggest prioritized future work on targeted ablations, long-context and multilingual robustness, rigorous temporal grounding metrics, fairness/safety audits, efficiency profiling, and transparent data/reward pipelines.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by leveraging MOSS-Audio’s released 4B/8B Instruct and Thinking variants, its timestamp-aware generation, and its unified handling of speech, environmental sounds, and music. Each item includes sector links, likely tools/workflows, and feasibility notes.
- Unified front-end for voice agents and chatbots (software, consumer devices)
- What: Replace separate ASR, sound-event detectors, and captioners with a single model that follows instructions, answers audio-grounded questions, and returns timestamped transcripts.
- Tools/workflows: “Audio QA” endpoint; Instruct variant for steady execution (transcription/caption), Thinking for complex reasoning; time-synced answers via built-in timestamp markers.
- Assumptions/dependencies: Latency depends on hardware, quantization, and streaming support; multilingual coverage varies with pretraining data; privacy and on-device constraints may apply.
- Meeting/lecture assistants with chapters and time-coded action items (enterprise software, education)
- What: Generate timestamped transcripts, segment into chapters, and answer queries like “When did the speaker discuss budget risks?” with time anchors.
- Tools/workflows: Plug-ins for Zoom/Teams/Meet; automatic chaptering from event/timestamp cues; retrieval over captions/transcripts.
- Assumptions/dependencies: Speaker attribution/diarization may require an external diarizer; quality depends on mic/signal quality and domain language.
- Media indexing and search for podcasts, broadcasts, and video (media, search)
- What: Produce dense audio captions and time markers to power content-based search, auto-chaptering, highlights, and cross-episode topic discovery.
- Tools/workflows: Timeline markers from model’s time-aware outputs; indexing pipeline that stores captions + timestamps; search over caption embeddings.
- Assumptions/dependencies: Domain shift for highly produced audio and heavy background music; scale-out storage and retrieval needed for large catalogs.
- Contact-center QA and compliance summaries (finance, telecom, enterprise ops)
- What: Time-coded transcripts with speech-captioned paralinguistic cues (e.g., speaking rate, tone) for coaching, script adherence, and dispute analysis.
- Tools/workflows: Dashboards showing clips with timestamps, prosody/emotion descriptors in text; rule checks (e.g., mandatory disclosures) with time references.
- Assumptions/dependencies: Emotion/prosody inference is probabilistic and requires calibration; fairness and bias audits; multilingual performance may vary.
- Accessibility overlays for Deaf/Hard-of-Hearing users (health/accessibility, consumer)
- What: Real-time captions plus concise descriptions of environmental sounds (e.g., “Doorbell rings at 00:12”).
- Tools/workflows: Mobile app with streaming audio input, on-screen time-synced captions; optional haptics for salient events (alarms, glass break).
- Assumptions/dependencies: On-device or low-latency edge inference needed; battery/performance tradeoffs; error rates must be communicated to users.
- Safety and security event logs (smart home, industrial safety)
- What: Detect and describe key non-speech events (alarms, impacts) with time anchors and concise captions for audit trails.
- Tools/workflows: IoT pipeline that records timestamped events; alerting rules (e.g., “if alarm sound at t ∈ [..] then notify”).
- Assumptions/dependencies: False positives/negatives require thresholds and human-in-the-loop review; microphone placement and acoustic variability matter.
- Content moderation with explainability (platform policy, trust & safety)
- What: Flag and justify time-localized content (e.g., gunshots, screams) with natural-language rationales grounded in timestamps.
- Tools/workflows: Moderation queue entries include time-linked snippets, captions, and model rationale; human reviewer tools.
- Assumptions/dependencies: Requires calibrated thresholds and escalation policies; potential for hallucinations mitigated by conservative routing and human review.
- Music metadata enrichment and discovery (music tech, streaming)
- What: Generate listener-facing descriptions (genre, mood, instrumentation, sections) and time-coded segment notes to improve recommendations and search.
- Tools/workflows: Batch processing of catalogs using Instruct variant; track-level and section-level metadata stored alongside audio.
- Assumptions/dependencies: Genre/instrument inference can be noisy; rights management and licensing for audio ingestion; not a substitute for musicological ground truth.
- Language learning and pronunciation feedback (education)
- What: Timestamped transcripts and speech-captioned feedback on rate/clarity/tone; “repeat after me” exercises with time-coded comparisons.
- Tools/workflows: Student recordings analyzed by Instruct model; dashboards showing time-aligned feedback.
- Assumptions/dependencies: Accent diversity and fairness considerations; per-language phonetic granularity varies.
- Academic dataset bootstrapping and labeling (academia, AI research)
- What: Use the event-preserving segmentation and branch-specific annotation pipeline to curate high-quality, heterogeneous audio-language corpora.
- Tools/workflows: Reuse segmentation + unified-caption merge to create SFT and evaluation sets; ablate DeepStack/time-marker settings in experiments.
- Assumptions/dependencies: Availability of annotation tools and rights to process audio; compute for large-scale preprocessing.
- Timeline automation in video/audio editors (creative tools, post-production)
- What: Auto-insert timeline markers at salient acoustic events (laughs, applause, beats) and generate clip summaries for editing.
- Tools/workflows: NLE plug-ins using timestamped captions; “jump-to-event” editing workflows; auto-chaptering for exports.
- Assumptions/dependencies: Integration with popular NLEs (Premiere, Resolve, FCP); accuracy varies by content type and mic setup.
- Developer-facing Audio QA API with time-cited answers (software)
- What: Ask questions like “When does the interviewee disclose the price?” and get an answer with a time range (e.g., “02:34–02:41”).
- Tools/workflows: REST/gRPC API exposing Thinking model; optional chain-of-thought disabled for production, enabled for troubleshooting.
- Assumptions/dependencies: Throughput and cost control for long audio; caching and chunking strategies; privacy and retention policies.
- Multilingual timestamped ASR for compliance and search (enterprise, media)
- What: Produce accurate, time-synced transcripts across common languages for indexing and legal review.
- Tools/workflows: Batch jobs over archives; validators and LID checks; subtitle generation (.srt/.vtt).
- Assumptions/dependencies: Language coverage depends on pretraining mixture; may require domain adaptation for low-resource languages or specialized jargon.
Long-Term Applications
These uses require additional research, domain validation, scaling, or ecosystem integration beyond today’s release, but are directly motivated by MOSS-Audio’s methods (DeepStack multi-granularity features, explicit time markers, unified data pipeline, and audio-grounded reasoning).
- Autonomous, audio-situated agents for smart environments (consumer IoT, robotics)
- What: Agents that monitor and reason over complex soundscapes (e.g., crying baby vs. appliance beep) and trigger context-aware actions.
- Dependencies: Reliable open-set sound reasoning, robust low-latency on-device inference, safety assurances, interop with home/robot control stacks.
- Clinical-grade acoustic monitoring (healthcare)
- What: Detect respiratory distress, cough types, pain cries, or seizure-associated sounds with time-coded evidence.
- Dependencies: Clinical validation, FDA/CE approvals, strong privacy guarantees, bias and reliability studies across populations and devices.
- Human–robot collaboration via audio-grounded planning (robotics, manufacturing)
- What: Robots interpret verbal instructions and ambient cues (alarms, tool sounds) with temporal grounding to adjust tasks in real time.
- Dependencies: Tight control-loop latencies, multimodal fusion with vision/tactile, robustness in loud or echoic environments.
- Evidence-grade forensic audio pipelines (public safety, legal)
- What: Time-aligned transcripts/captions with explainable reasoning trails and chain-of-custody for bodycam/911 audio.
- Dependencies: Standardization of reporting, tamper-evidence requirements, auditor tooling, legal admissibility, bias and error transparency.
- Personalized hearing augmentation and AR audio UX (health/accessibility, consumer)
- What: Real-time prioritization and captioning of salient sounds with user-specific preferences (e.g., amplify speech, summarize background events).
- Dependencies: Aggressive on-device optimization (quantization/distillation), low power consumption, stable UX under noise, user safety.
- Music production co-pilots (creative tools)
- What: DAW-integrated assistants suggesting structure edits, instrument balances, and lyric alignment, using time-aware captions and music understanding.
- Dependencies: Precise alignment with project timelines, music-domain adaptation, human-in-the-loop workflows acceptable to professionals.
- City-scale acoustic intelligence for policy (government, urban planning)
- What: Aggregate time-stamped sound-event statistics for noise mapping, public safety insights, and urban design.
- Dependencies: Privacy-preserving data collection (federated/edge), governance and consent frameworks, bias mitigation, public transparency.
- Endangered and low-resource language documentation (academia, cultural heritage)
- What: Bootstrap aligned transcripts/captions with timestamps to aid linguistic analysis and archival search.
- Dependencies: Community consent and co-ownership, language-specific adaptation, expert validation, ethical data handling.
- Multimodal (audio+video+text) temporal reasoning for broadcast and sports (media, analytics)
- What: Fuse audio time markers with video detections to produce event logs (e.g., “whistle + crowd spike → foul at 12:34”).
- Dependencies: Joint training/inference stacks, precise cross-modal synchronization, scalable indexing.
- On-device edge deployments at scale (IoT, automotive, wearables)
- What: Deploy quantized 4B variants for real-time inference in cars, cameras, and wearables to interpret scenes and events.
- Dependencies: Model compression and hardware acceleration, thermal/power budgets, continuous update pipelines, privacy-by-design.
- Large-scale social science and behavioral studies (academia)
- What: Analyze prosody, turn-taking, and emotion trends across corpora with time-aligned outputs.
- Dependencies: Strong privacy/consent frameworks, bias-aware analyses, reproducibility protocols and baseline benchmarks.
- Method transfer: DeepStack and time-marker design patterns in other models (AI R&D)
- What: Apply cross-layer feature injection and explicit temporal tokens to improve temporal grounding in speech/music/env-sound models or other modalities.
- Dependencies: Engineering integration into existing LLM/encoder stacks, ablation-driven validation, training compute and data.
Notes on feasibility across applications:
- Model choice: Use Instruct variants for stable formatting (ASR/caption/timestamps), Thinking variants for complex, multi-step audio QA and reasoning.
- Data/domain shift: Accuracy degrades under heavy noise, far-field mics, rare events, or low-resource languages; consider fine-tuning.
- Governance: Many applications (moderation, monitoring, healthcare) require human review, bias audits, and clear user consent mechanisms.
- Performance: Streaming and real-time use cases depend on KV-caching, chunked processing, and hardware acceleration; battery and thermal limits apply for mobile/edge.
- Explainability: Timestamped outputs can anchor explanations, but hallucinations remain possible; design for verifiability with time-cited evidence and user controls.
Glossary
- acoustic events: Discrete occurrences of sound sources or actions in audio. "Audio is a primary modality for perceiving language, acoustic events, environments, music, and social context."
- ASR: Automatic Speech Recognition; converting spoken audio into text. "Different tasks depend on different levels of acoustic abstraction: ASR requires fine-grained phonetic and lexical information"
- audio captioning: Generating natural-language descriptions of audio content. "supporting audio captioning, time-aware question answering, timestamped transcription, and audio-grounded reasoning."
- audio-conditioned LLM: A LLM that conditions generation on audio representations. "We therefore design MOSS-Audio as an end-to-end audio-conditioned LLM whose audio encoder is trained from scratch for this purpose."
- audio-grounded reasoning: Reasoning that explicitly uses evidence from the audio signal. "MOSS-Audio achieves strong performance across general audio understanding, speech captioning, ASR, and timestamped ASR, positioning it as a promising understanding foundation for future voice agents."
- audio-LLMs: Models jointly handling audio inputs and language outputs. "As audio-LLMs move beyond automatic speech recognition"
- AudioSet ontology: A hierarchical organization of audio event categories used for labeling. "We map these fine-grained AudioSet labels into nine coarse-grained categories based on the AudioSet ontology"
- AudioSet taxonomy: The set of labeled audio event classes used for detection and annotation. "to obtain timestamped event labels under the AudioSet taxonomy"
- autoregressive generation: Producing outputs token by token, each conditioned on previous outputs. "the decoder then performs autoregressive generation for transcription, captioning, audio question answering, temporal localization, and reasoning-oriented audio understanding."
- BEATs backbone: A pretrained audio representation model used as a feature extractor. "using a BEATs backbone trained within the PretrainedSED framework"
- branch-specific annotation: Separate annotation procedures tailored to content types (e.g., speech, music). "applies branch-specific annotation to speech, music, and general audio"
- Canonical normalization: A standardization step that converts diverse annotations into a common format. "Canonical normalization."
- classification-guided annotation: Using classifier predictions to guide what and how to annotate. "the data engine is centered on classification-guided annotation."
- DAPO: A reinforcement learning objective for policy optimization in generation. "we adopt a clipped DAPO objective."
- DeepStack cross-layer feature injection: Feeding representations from multiple encoder layers into the decoder. "DeepStack cross-layer feature injection"
- dense captions: Detailed, information-rich descriptions capturing events, attributes, and timelines. "produce natural-language dense captions with acoustic attributes, foreground-background relations, source interactions, and temporal context."
- diarized speaker regions: Time segments labeled by speaker identity for multi-speaker audio. "These diarized speaker regions serve as the basic units for speech-caption annotation"
- dynamic filtering: Dropping uninformative samples during RL training based on reward variance. "we apply dynamic filtering to discard rollout groups whose reward standard deviation is (near) zero."
- elapsed-time markers: Explicit tokens indicating absolute time positions within audio-token sequences. "explicit elapsed-time markers"
- entropy of the class distribution: A measure of uncertainty used in routing decisions. "residual uncertainty is measured using the entropy of the class distribution"
- event-preserving segmentation: Cutting audio at natural event boundaries to keep events intact. "event-preserving segmentation"
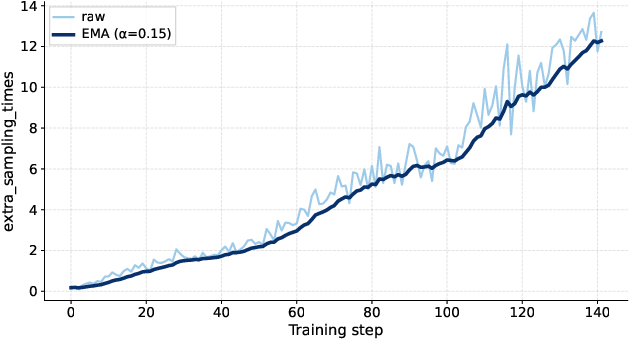
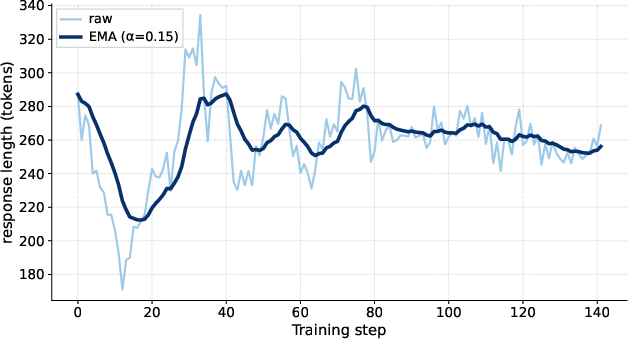
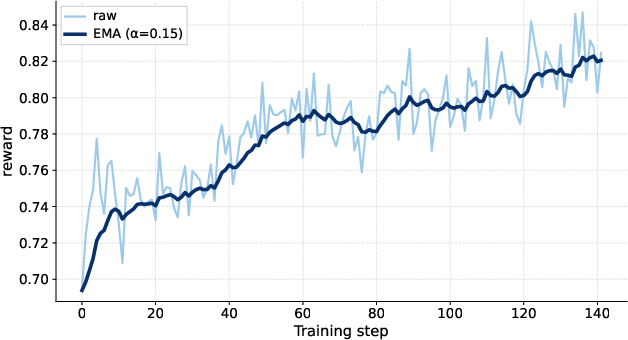
- exponential moving average (EMA): A smoothed statistic tracking trends over training steps. "the dark curve its exponential moving average ()."
- forced alignment: Aligning recognized text to audio timestamps at word or phoneme level. "we employ the TorchAudio MMS_FA forced-alignment model"
- GatedMLP: A gated multilayer perceptron used for cross-modal projection. "two GatedMLP cross-modal adapters"
- global self-attention: Attention over all positions in a sequence (contrasted with local windows). "the encoder eschews global self-attention in favor of sliding window attention"
- group-relative objective: An RL objective comparing samples within the same prompt group. "within-group advantage signal under the group-relative objective."
- hard-cut fallback: A forced segmentation when audio exceeds limits or lacks clear boundaries. "A maximum segment length cap and a hard-cut fallback for very long recordings ensure training compatibility."
- instrument-recognition: Detecting which musical instruments are active over time. "An instrument-recognition branch records time-varying active instruments"
- KV-caching: Caching key/value attention states to speed up inference on long sequences. "enabling real-time KV-caching"
- language identification (LID): Determining the language present in audio or text. "language identification (LID) is cross-validated"
- log-mel spectrograms: Time–frequency representations using log-scaled Mel filterbanks. "128-channel log-mel spectrograms"
- merge adapter: A module that aggregates intermediate encoder features for injection into the decoder. "aggregates them through a merge adapter"
- MIR pipeline: A Music Information Retrieval toolkit chain for musical structure and attribute extraction. "A MIR pipeline based on Chordino"
- modality adapter: A projection module aligning audio features to the LLM’s space. "a modality adapter projects audio features into the language-model space"
- modality dominance: An estimate of which content type (e.g., speech, music) leads in a clip. "The routing policy estimates modality dominance"
- overlap-merged: Combining event intervals that overlap to form continuous segments. "The remaining events are overlap-merged"
- paralinguistic: Non-lexical aspects of speech such as emotion, tone, and style. "paralinguistic characteristics"
- PretrainedSED: A framework for pretraining sound event detection models. "within the PretrainedSED framework"
- prior-driven routing: Using prior modality scores to decide which annotations to include and order. "Prior-driven routing."
- prosody: Rhythm and intonation patterns in speech. "speaker traits, prosody, emotion, turn-taking cues"
- reinforcement learning: Optimizing a policy via rewards from sampled outputs. "We use a DAPO-based reinforcement learning stage"
- rollout: A batch of sampled model responses used for RL updates. "For rollout generation, we sample responses"
- Router-R1: A lightweight policy for selecting and ordering evidence branches. "Router-R1"
- sliding window attention: Limiting attention to local windows to scale with sequence length. "sliding window attention"
- square-root mixing strategy: Sampling datasets with probability proportional to the square root of size. "square-root mixing strategy."
- supervised fine-tuning: Post-pretraining adaptation using labeled instruction data. "The first post-training stage is supervised fine-tuning"
- temporal anchors: Explicit timing cues that help align generated text with audio events. "providing explicit temporal anchors"
- temporal downsampling: Reducing time resolution of features to fewer frames per second. "achieving an 8× temporal downsampling"
- temporal grounding: Associating recognized content with when it occurs in time. "Temporal grounding is essential"
- temporal localization: Identifying the time spans where events occur. "temporal localization"
- time markers: Special tokens inserted to encode elapsed time in the sequence. "explicit time markers"
- time-aware question answering: QA that requires reasoning about when events occur in audio. "time-aware question answering"
- timestamped ASR: Speech recognition that includes timestamps for words or sentences. "timestamped ASR"
- timestamped transcription: Transcripts annotated with time information for segments or words. "timestamped transcription"
- token-level importance sampling correction: A stabilization technique adjusting gradient estimates per token in RL. "token-level importance sampling correction"
- tool_results interface: A unified schema organizing heterogeneous annotation outputs. "tool_results interface"
- Transformer backbone: A stack of Transformer layers serving as the core network. "a 32-layer Transformer backbone"
- TIS: Token-level Importance Sampling; a correction method in RL training. "the TIS clipping threshold"
- word error rate (WER): A metric for ASR accuracy based on edit distance between hypotheses and references. "word error rate (WER)"
- word-level timestamps: Per-word timing alignments linking text to audio. "This procedure generates precise word-level timestamps"
Collections
Sign up for free to add this paper to one or more collections.