- The paper presents a unified model that reduces medical ASR WER and EWER by integrating audio and text through cross-modal attention.
- The methodology uses a Whisper-based audio encoder and LLaMA-3.1-8B decoder, achieving a 56% WER reduction and efficient real-time inference.
- The design streamlines clinical transcription workflows by lowering latency and optimizing semantic alignment for robust entity recognition.
Au-M-ol: A Unified Model for Medical Audio and Language Understanding
Introduction
Au-M-ol introduces an integrated multimodal architecture targeting clinically relevant Automatic Speech Recognition (ASR) and medical language understanding tasks. Existing models, including Whisper, Qwen2-Audio, and Whispering-LLaMA, either operate through cascaded pipelines or lack domain-specific audio-language fusion critical for medical applications. Au-M-ol consolidates speech and text processing into a streamlined encoder-decoder system, reducing latency, computational footprint, and points of failure common in cascaded architectures.
Model Architecture
Au-M-ol is comprised of a Whisper-based audio encoder, an adaptation layer, and a decoder-only LLM (LLaMA-3.1-8B). The Whisper encoder generates contextualized audio features from log-Mel spectrograms. The adaptation layer projects audio representations into the LLM space using linear mappings, ReLU, and layer normalization. Cross-modal attention mechanisms facilitate explicit correspondence between modalities and support semantic alignment. The LLM decoder processes concatenated adapted audio embeddings and text tokens for unified multimodal reasoning. Alignment loss and supervised cross-entropy loss jointly optimize transcription accuracy and cross-modal integration.
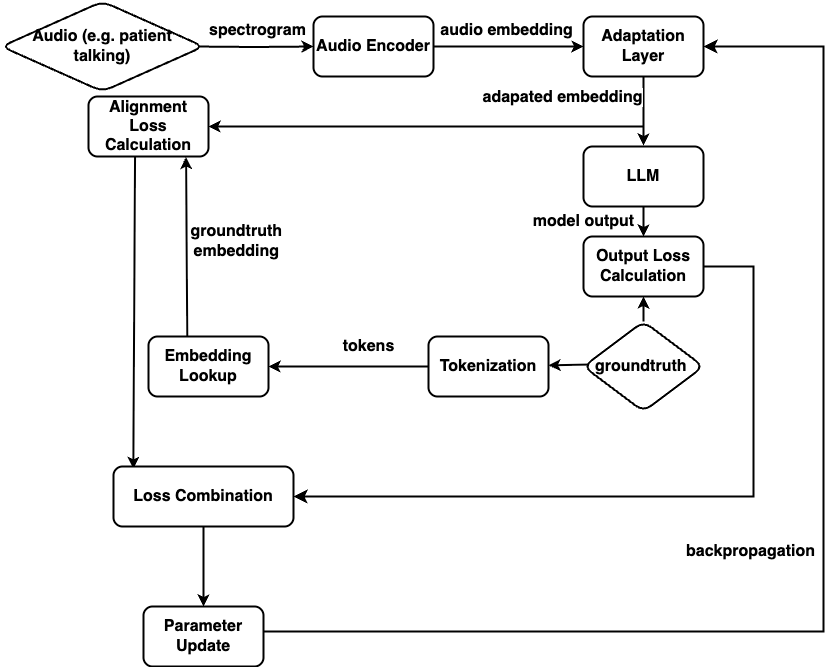
Figure 1: The overview of the Au-M-ol model architecture.
Experimental Evaluation
Evaluation was conducted over LibriSpeech, FLEURS, and a proprietary medical corpus with over 1.3 million de-identified clinical audio recordings. The primary metrics were Word Error Rate (WER) and Entity Word Error Rate (EWER), the latter reflecting entity-level transcription accuracy—a critical metric for medical ASR. Au-M-ol achieved a 56% WER reduction compared to SOTA baselines across medical transcription tasks. On LibriSpeech and FLEURS, Au-M-ol consistently outperformed Whisper, United-MedASR, Qwen2-Audio, and Whispering-LLaMA, with final WERs of 0.42 and 0.18 respectively. In medical ASR, Au-M-ol reduced EWER from ≥38% (SOTA baselines) to 15.23%, demonstrating robust domain-specific entity recognition.
Inference speed was competitive with existing baselines (12.7 seconds per minute of audio), validating the design's practical deployability for real-time clinical workflows. Fine-tuning and ablation studies confirmed that the adaptation layer and alignment loss were essential to optimal performance. Removing these components or substituting encoder/decoder variants resulted in significant transcription degradation, confirming that modality projection and semantic alignment are foundational for medical audio-language processing.
Model Implications and Future Directions
Au-M-ol's unified encoder-decoder design addresses practical deployment issues in the clinical domain by reducing latency and computational multiplicity. This enables scalable, real-time clinical transcription, ambient documentation, and audio-based retrieval-augmented generation (Audio-RAG). The architecture's multimodal joint optimization can be further leveraged for clinical intent recognition, emotion analysis, and diagnostic support.
Theoretical implications include the emergence of shared embedding spaces for heterogeneous modalities and the utility of cross-modal alignment losses for semantic integration. Future work will explore multilingual and multidialect extensions to increase global healthcare applicability, incorporation of structured medical knowledge (e.g., UMLS, RxNorm) for improved entity linking and reasoning, and enhancements in interpretability to meet clinical transparency requirements. End-to-end integration in live clinical workflows and robust handling of noisy or imbalanced modalities remain important research directions.
Limitations
The requirement for large-scale, high-quality multimodal clinical data limits generalizability across diverse patient populations and rare conditions. Modal imbalance—where audio and text inputs have disparate information density or quality—remains a challenge, especially under noisy or incomplete contexts. The tight integration, while efficient, reduces interpretability and explainability, complicating validation in high-stakes clinical environments.
Conclusion
Au-M-ol establishes a robust, efficient, and scalable framework for medical audio-language fusion, overcoming the key limitations of previous cascaded and modality-alignment approaches. With demonstrated gains in transcription and entity recognition accuracy, reduced latency, and validated efficiency, Au-M-ol is a strong candidate for deployment in real-world clinical ASR and multimodal medical reasoning. Its architecture lays the foundation for future advances in context-rich, real-time healthcare AI applications.
Reference: "Au-M-ol: A Unified Model for Medical Audio and Language Understanding" (2604.23284)