- The paper introduces a novel audio language model that leverages acoustically grounded chain-of-thought reasoning to overcome modality misalignment.
- It employs the Modality-Grounded Reasoning Distillation (MGRD) framework to iteratively align reasoning trajectories with acoustic features.
- Empirical evaluations demonstrate significant gains in speech-to-text and speech-to-speech tasks, achieving near state-of-the-art scores.
Step-Audio-R1: Enabling Acoustically Grounded Reasoning in Audio LLMs
Introduction
The development of explicit reasoning capabilities such as chain-of-thought (CoT) has yielded considerable advances in natural language and vision-LLMs, especially when inference-time compute is scaled via extended deliberation. However, models in the audio domain have historically failed to benefit from long reasoning traces; performance typically declines as reasoning length increases. This paper, "Step-Audio-R1 Technical Report" (2511.15848), addresses this anomaly by introducing Step-Audio-R1, the first model to demonstrate that audio intelligence can indeed exploit chain-of-thought reasoning—if grounded in acoustic perception rather than textual surrogates. The work centers on the Modality-Grounded Reasoning Distillation (MGRD) framework, which iteratively aligns reasoning trajectories with acoustic properties, successfully counteracting the tendency to hallucinate or default to purely text-based explanations.
Motivation and Analysis of Failure Modes
Despite the advances in multimodal reasoning, prior audio LLMs systematically exhibit performance regressions when forced to elaborate via CoT. Empirical and ablation studies identify the root cause as modality misalignment: existing models, initialized via supervised fine-tuning on textual CoT corpora, default to reasoning from transcript/caption content rather than directly from the audio signal. This "textual surrogate reasoning" manifests both in output content and in suboptimal task accuracy, particularly when acoustic analysis is mandatory. The Step-Audio-R1 project isolates this as a primary failure mode, reframing the central question away from inherent modality incompatibility and towards a problem of reasoning substrate alignment.
Model Architecture
Step-Audio-R1 is based on a modular design that integrates:
- Audio Encoder: Frozen Qwen2 audio encoder pre-trained on diverse audio and speech understanding tasks; outputs at 25 Hz.
- Audio Adaptor: A fixed downsampling module mapping encoder outputs to match the LLM's temporal granularity (yielding 12.5 Hz).
- LLM Decoder: Qwen2.5 32B, taking latent audio features and producing textual reasoning augmented with a standardized reasoning tag sequence.
The architectural pipeline ensures that the LLM is directly conditioned on subsampled acoustic features, which is critical for enforcing acoustic grounding in downstream reasoning.
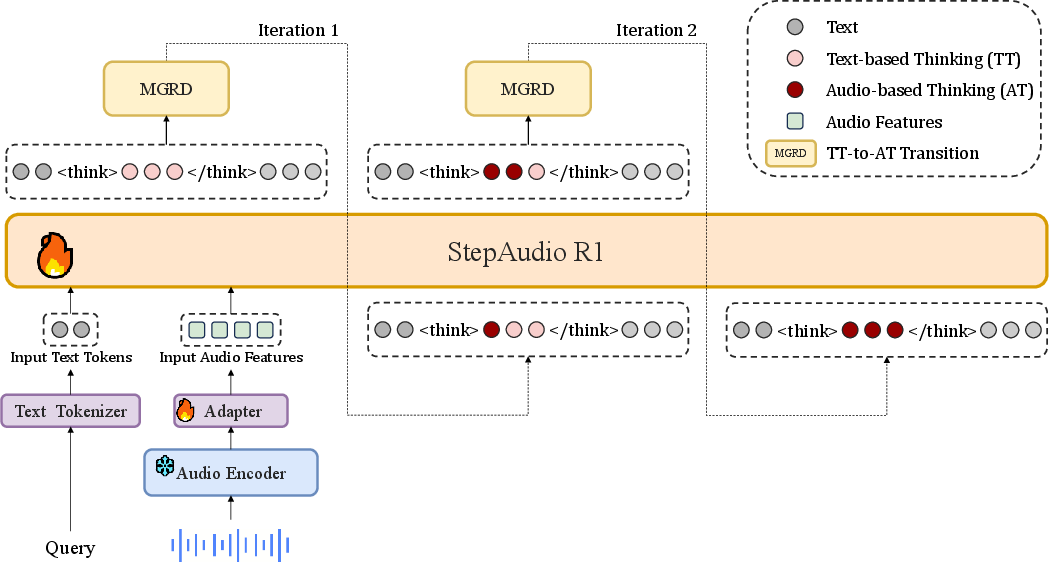
Figure 2: Schematic architecture of Step-Audio-R1, illustrating the pathway from audio input through the Qwen2 encoder and adaptor to the LLM decoder.
Modality-Grounded Reasoning Distillation (MGRD)
MGRD is a cyclical distillation and optimization framework designed to shift the model’s deliberation process from text-based surrogacy towards explicit acoustic analysis:
- Foundation Phase: Supervised fine-tuning (SFT) on multi-domain data, mixing text-only (math/code), audio QA, and audio-based CoT (self-distilled). RL with verified rewards (RLVR) further tunes task-oriented accuracy.
- Iterative Refinement: Alternating cycles in which model generations are filtered for acoustic relevance, logical consistency, and accuracy. High-quality, perceptually grounded reasoning traces—even when relatively rare—are used for further SFT.
- Multimodal RL: Joint reward signals for answer accuracy (dominant) and explicit reasoning format (minor), ensuring that chain-of-thought persists through optimization and does not collapse to direct answers.
- Self-Cognition Correction: Models are additionally subjected to preference optimization to counteract learned text-only biases, practically eradicating "I cannot process audio" style errors in responses.
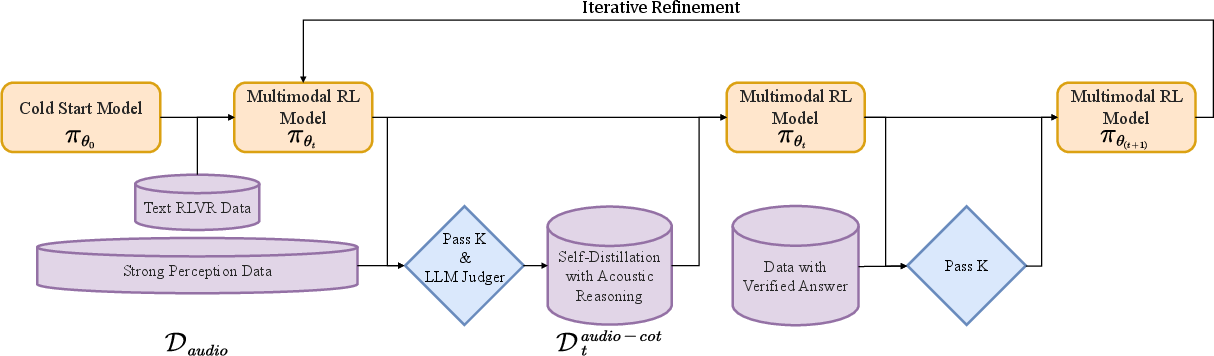
Figure 1: The MGRD process: iterative self-distillation aligns model reasoning to explicitly reference acoustic features, while reinforced with multimodal supervised and RL objectives.
Empirical Evaluation
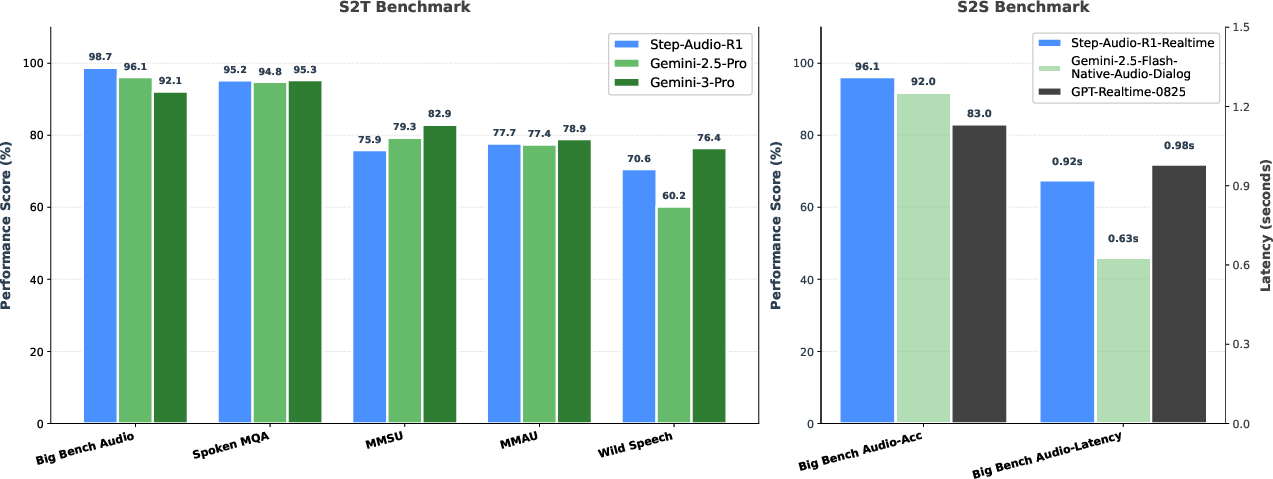
Step-Audio-R1 was benchmarked across an extensive suite of speech-to-text and speech-to-speech tasks, including highly challenging datasets such as Big Bench Audio, Spoken MQA, MMSU, MMAU, and Wild Speech. Results indicate:
Training Dynamics and Ablations
The work features ablation studies that interrogate the effects of reward structure and data curation:
- Format Reward: Introducing a reward component for the presence of explicit reasoning prevents the collapse of chain-of-thought generation typical in vanilla RL. Without format reward, output reasoning tokens decay by over 50% during training, directly correlating with decreased performance (MMAU: from 77.7% to 76.5%, see Section 5.1).
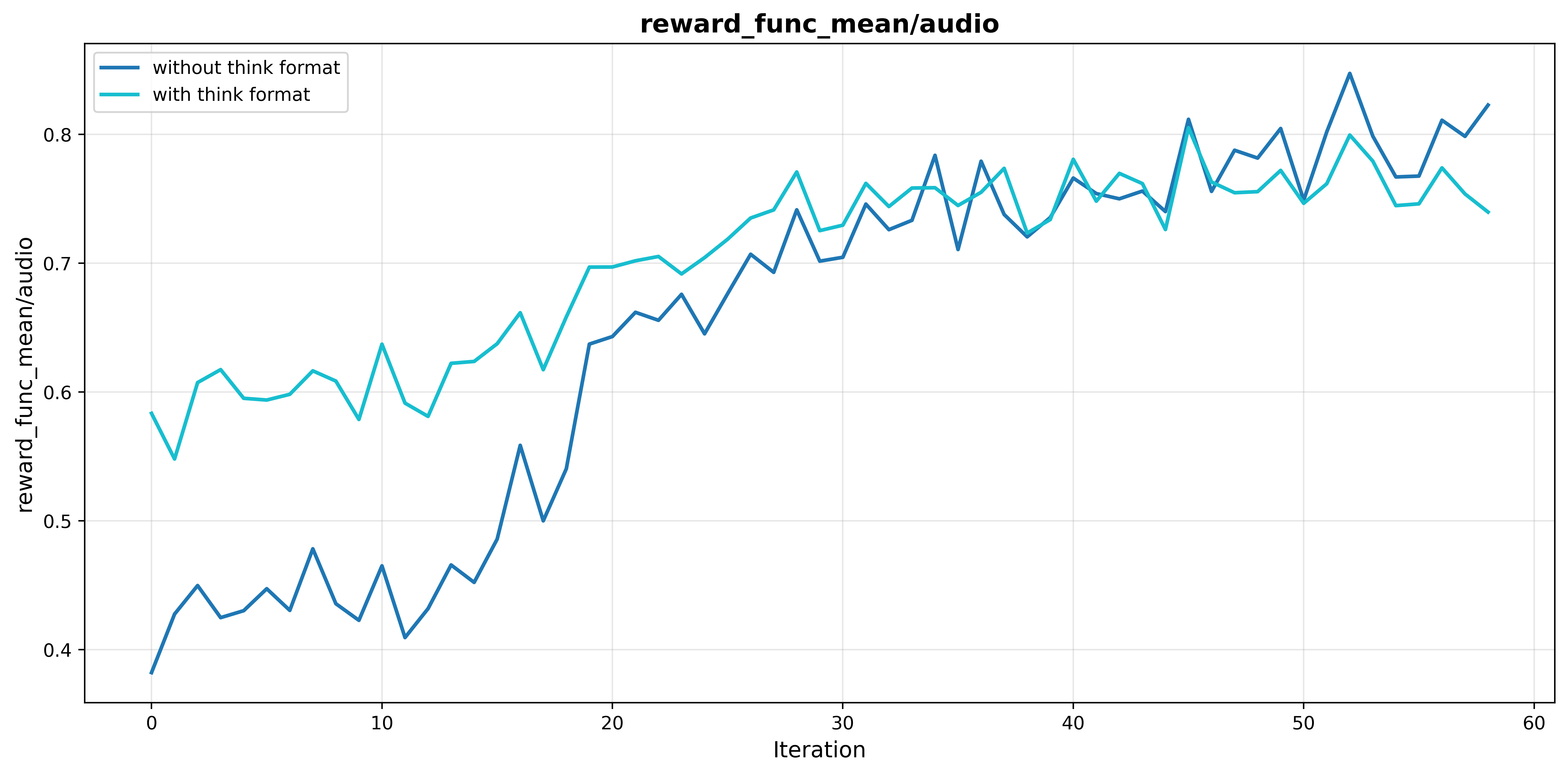
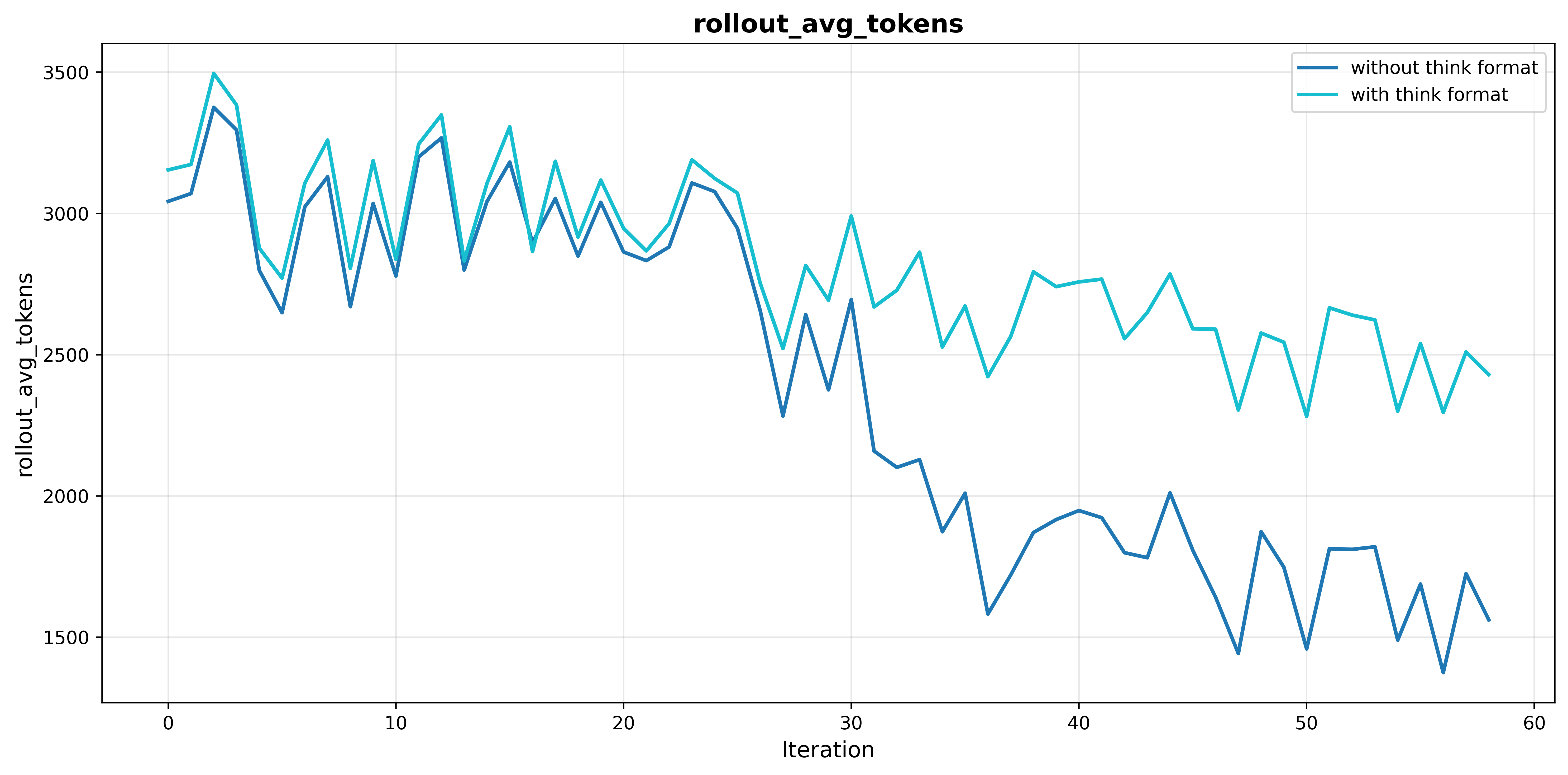
Figure 4: Format rewards stabilize mean reward progression and ensure sustained reasoning output during training.
- Data Curation: Models trained on moderately difficult examples (i.e., those solvable but challenging) reliably learn effective reasoning strategies, while those trained on consistently failed or overscaled (unfiltered) datasets suffer from unstable convergence and shorter reasoning traces. Quality of samples outweighs raw dataset size in determining generalizable reasoning performance.
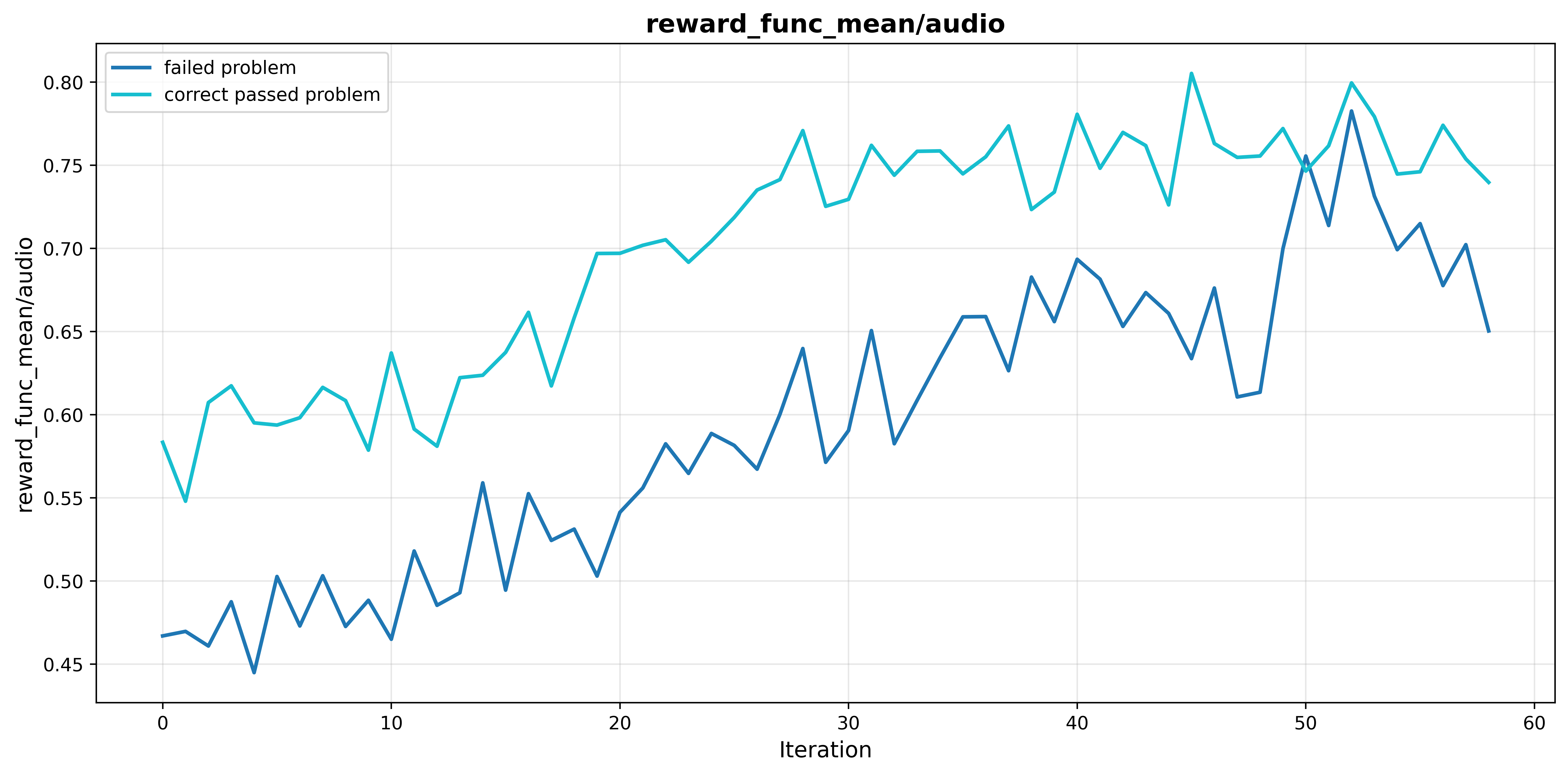
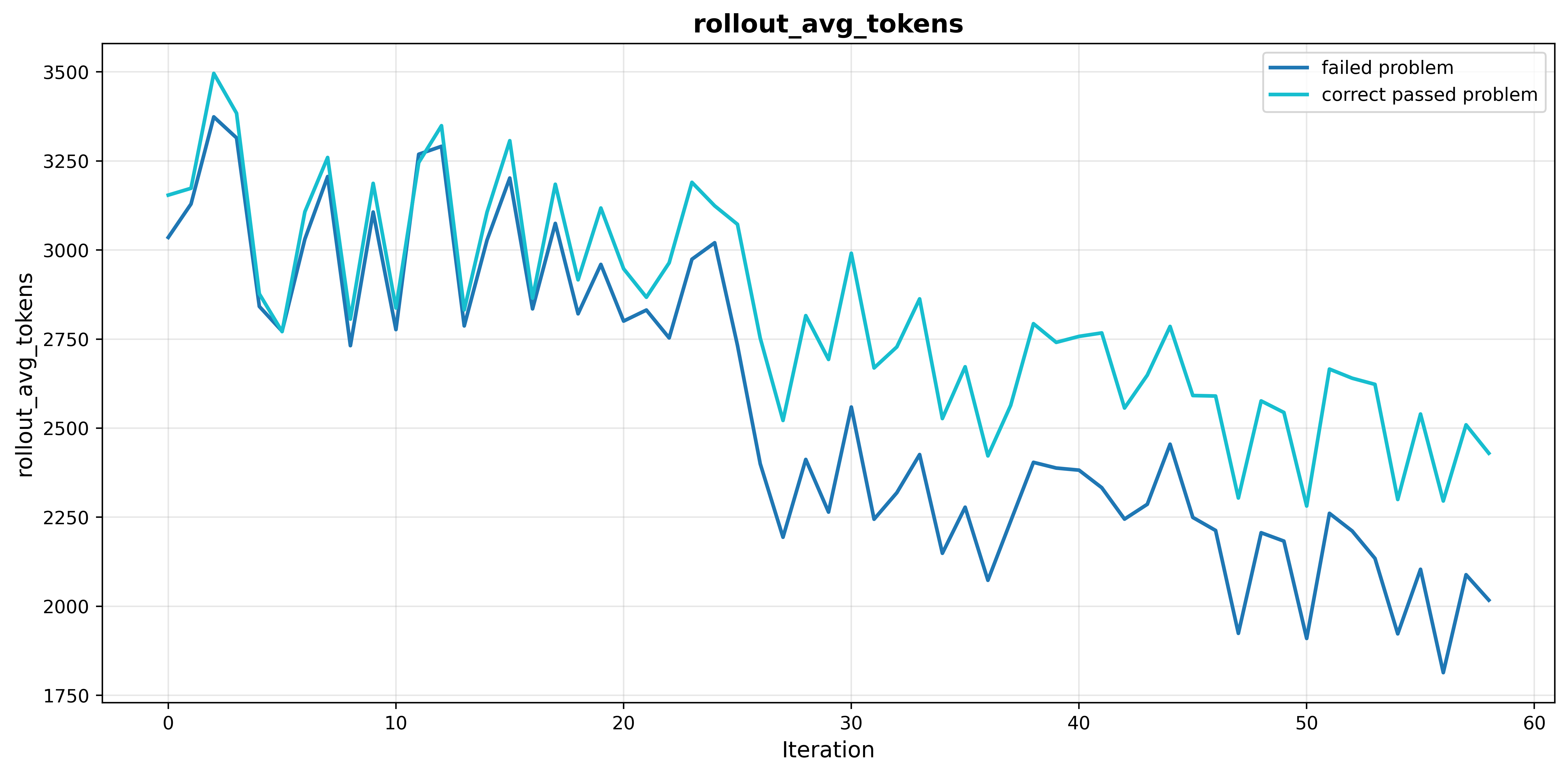
Figure 5: Selective training on moderately difficult problems maintains longer, meaningful reasoning chains and avoids the reasoning decay observed with consistently failed problems or unfiltered scaling.
- Self-Cognition Correction: Iterative filtering plus preference optimization (DPO) reduces the error rate in self-cognition from 6.76% to essentially zero, indicating that misalignment is not an intrinsic limitation but a learned artifact.
Implications and Future Perspectives
Step-Audio-R1 repudiates the previously observed "inverted scaling" in audio reasoning models. When reasoning is grounded in the relevant modality—i.e., the physical audio signal—longer chains of thought not only cease to impair performance, but actually yield improved accuracy and more robust inference. This has direct ramifications for the design of general-purpose multimodal systems, indicating that compute scaling principles and structured deliberation should remain viable tools—provided that explicit modality anchoring is enforced during optimization.
The MGRD framework is generically applicable; its utility likely extends to other under-explored modalities or cross-modal transfer learning scenarios plagued by domain-misaligned reasoning. The approach systematically addresses modality-specific failure modes, suggests curriculum-based RL for data curation, and highlights the value of detailed preference optimization in correcting learned behavioral biases.
Conclusion
Step-Audio-R1 establishes that deliberate, acoustically grounded reasoning is not just possible, but beneficial in complex audio language modeling. The MGRD methodology fundamentally transforms both the process and output of model reasoning in the audio domain. These findings redefine the design space for audio LLMs, integrating them more deeply into the trajectory of universal, chain-of-thought-driven, multimodal agents and laying groundwork for future work in deep multimodal reasoning.