- The paper introduces an artifact-based build process that uses dependency graphs and caching to convert ROS bag files into ML datasets.
- The paper demonstrates significant runtime reductions, achieving a 386x speedup in warm builds and near-constant scaling with increased dataset size.
- The paper presents a practical implementation with Bagzel/Bazel that supports reproducible, incremental dataset builds through server-side digest management.
Artifact-Based Build Systems for Robotics Dataset Construction
Motivation and Context
The complexity of modern robotics workflows, especially those employing machine learning paradigms, demands robust and efficient dataset generation pipelines. Robotic platforms typically record multimodal sensor data using the ROS ecosystem, generating large volumes of raw data in bag file formats. Converting these recordings into ML-compatible datasets has conventionally relied on sequence-based, procedural scripts, introducing considerable engineering overhead, technical debt, and non-reproducibility. Additionally, the repetitiveness of active learning cycles and iterative dataset updates leads to slow iteration and high data management costs.
This paper introduces a formalism and open-source implementation—Bagzel—which conceptualizes robotics dataset construction as an artifact-based build problem, akin to software compilation processes managed by build systems such as Bazel. The adoption of artifact-based dependency graphs, deterministic actions, and content-addressable artifact caching aims to provide reproducible, incremental, and efficient dataset generation, decoupled from rigid benchmark schemas and legacy pipelines.
The authors formalize the dataset build process as a bipartite Directed Acyclic Graph (DAG), where artifact nodes represent data objects (both source and derived), and operation nodes encode data transformations. Each transformation (operation) declares explicit input dependencies and outputs, enabling precise invalidation and recomputation only along modified subgraphs. The approach supports deterministic digest computation over both data and executable dependencies, enforcing reproducibility.
A significant challenge arises in scaling such systems to the robotics domain: source artifacts (bag files) are often large (tens to hundreds of gigabytes), making repeated digest computations expensive. To address this, the system optionally uses server-side extended attribute-based digest management, whereby content hashes are computed server-side and reused across builds, reducing client-side digest load and incremental update latency.
Implementation: Bagzel and Bagzel-xattr
Bagzel, implemented as a Bazel rule extension, operationalizes this formalism for practical robotics dataset workflows. It supports the transformation of ROS 1 and ROS 2 bag files into structured datasets, including direct export to standard schemas such as nuScenes. Each step—decoding, synchronization, metadata processing—is expressed as an explicit target in the build graph. Artifact caching and dependency declaration allow for selective recomputation and high concurrency when running on suitable hardware or clusters.
The Bagzel-xattr variant incorporates server-side digest management for large source files. This further optimizes runtime for incremental rebuilds in high-throughput environments by avoiding redundant whole-file hash computations for immutable or unchanged data. Both variants maintain deterministic outputs, facilitating reproducible and auditable ML datasets.
Empirical Results
The paper presents a comprehensive empirical evaluation targeting execution efficiency, scalability, and the impact of both input granularity and digest management on incremental build performance.
Runtime Reduction and Execution Modes
Across 20.4 GB datasets, Bagzel yields a 386.26x reduction in warm build runtime and a 7.21x speedup in incremental mode compared to conventional sequential processing. Even in cold builds, Bagzel achieves more than 2x runtime reduction. Bagzel-xattr achieves additional runtime savings of around 5.9% relative to Bagzel in incremental workflows.
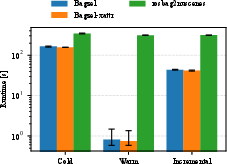
Figure 2: Runtime comparison across cold, warm, and incremental builds for the 20.4 GB dataset, demonstrating Bagzel's orders-of-magnitude speedup over sequential baselines, especially in iterative use cases.
Scalability with Dataset Size
Bagzel's warm and incremental build runtimes exhibit near-constant behavior as dataset size increases from 5.1 GB to 20.4 GB, with scaling slopes close to zero. The sequential baseline's runtime, in contrast, grows linearly with data volume (15.50 s/GB for cold; 15.25 s/GB for incremental builds). This validates that the artifact-based approach provides markedly superior scaling behavior in both batch and incremental scenarios.
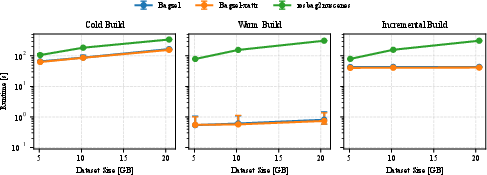
Figure 4: Runtime scaling with dataset size, highlighting the weak dependence of Bagzel's warm and incremental builds on total data volume as compared to the linear scaling of sequential pipelines.
Incremental runtime sensitivity to input artifact granularity was evaluated by varying the number of source bag files under a constant total data volume. Both Bagzel variants show only minor increases in runtime as granularity increases, reaffirming the robustness of the approach. Bagzel-xattr's runtime benefit remains consistent, with the percentage gain increasing slightly with finer partitioning.
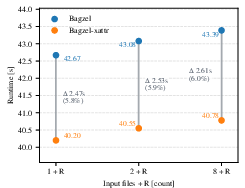
Figure 6: Incremental runtime for a fixed target with varying input file granularities, demonstrating the modest effect of granularity and the stable advantage of server-side digest management.
Implications and Outlook
Modeling data transformation as an artifact-based dependency graph introduces determinism, modularity, and efficiency into robotics dataset preparation pipelines. The direct benefits are significant runtime improvements for iterative development (active learning, continual integration, etc.) and strong guarantees of reproducibility—a core requirement for academic and industrial ML research. Artifact-level caching and selective recomputation are especially impactful where dataset sizes and update frequency are high.
Practical implications extend to automated dataset auditing, provenance tracking, and fast feedback cycles in model retraining and deployment pipelines. The compatibility with Bazel and Slurm infrastructure suggests seamless integration into large-scale or distributed environments. Further, the explicit treatment of digest management for large files addresses a central scaling bottleneck, suggesting suitability for expansion to multimodal and cross-organizational workflows.
Theoretically, this work bridges principles of software systems engineering (artifact-based builds, hermeticity, DAG execution models) with the needs of ML data management in robotics. Such formalization prompts further research into optimally partitioning data artifacts, integrating upstream annotation/labeling pipelines, and optimizing for distributed and federated contexts.
As AI systems increasingly rely on continual data collection and retraining, artifact-based data management is well-positioned to become foundational not only in robotics but also in broader domains requiring dynamic, reproducible, and scalable data engineering.
Conclusion
This study rigorously demonstrates that conceptualizing dataset construction for robotics as an artifact-based build process—implemented through Bazel and Bagzel—leads to strong gains in efficiency and reproducibility. Major experimental findings include extreme runtime reductions for iterative dataset updates and near-elimination of scaling penalties with increasing dataset size for artifact-based approaches. The introduction of server-side digest management provides further runtime benefits in incremental workflows.
The approach outlined in "Modeling Robotics Dataset Construction as an Artifact-Based Build Process" (2606.00162) lays a structured foundation for future high-throughput, reproducible, and scalable data engineering in robotics and related AI domains, with clear paths for further scalability, distributed deployment, and principled data lifecycle management.