- The paper introduces a ROS2-based perception system integrating synthetic data generation, transformation-equivariant 3D detection, and center-pose tracking for dynamic industrial environments.
- It achieves significant performance gains, with improvements in IoU, RMSE, and HOTA metrics, demonstrating robust 6D pose estimation and tracking in real-world scenarios.
- The study validates efficient real-time object association on mobile robots by reducing yaw errors and minimizing false positives under challenging conditions.
ROS 2-Based LiDAR Perception Framework for Mobile Robots in Dynamic Production Environments
Overview of Objectives and Framework Architecture
This paper introduces a comprehensive LiDAR-based perception framework tailored for mobile robots operating in dynamic industrial environments, underpinned by ROS 2 as its middleware. The framework integrates synthetic data-driven, transformation-equivariant 3D object detection with a lightweight, center-pose-based multi-object tracking (MOT) module. The principal objectives include reducing dependence on labor-intensive, real-world annotated LiDAR datasets; improving robustness to sensor noise and occlusions; and maintaining spatiotemporal consistency in object tracking for mobile robots amid dynamic changes and occlusions.

Figure 1: High-level depiction of the overall perception framework, highlighting the data flow, modular structure, and ROS 2 network integration.
The system is engineered for deployment in industrial scenarios characterized by frequent workspace reconfiguration, requiring mobile manipulators to dock, align, and interact with mobile resources such as workstations and storage units. Through a rigorous evaluation protocol spanning 72 distinct scenarios, the framework advances both theoretical and practical aspects of LiDAR-based 6D pose estimation and multi-object tracking.
Synthetic Data Generation for Sim-to-Real Transfer
To mitigate the limitations of real-world dataset availability, the framework employs a sophisticated synthetic data generation pipeline utilizing NVIDIA Isaac Sim’s physically-based Omniverse Replicator. The pipeline performs extensive domain randomization—including object layouts, environmental factors, LiDAR parameters, scaling, and rotation—while modeling sensor-specific noise profiles for the Ouster OS1-128, thus fostering robust model generalization.

Figure 2: Visualization of the synthetic data generation process, detailing diverse object placement, sensor positions, and augmentation strategies.
Synthetic datasets adhere to OpenPCDet conventions and are filtered for LiDAR visibility to ensure training-targeted annotations. Models are trained per object category with a balanced train-test split. This approach decisively addresses the sim-to-real gap by enriching training with physically plausible, annotation-rich data, enabling subsequent modules to operate without the constraints of costly real-world labeling campaigns.
The 3D object detection module builds upon the Transformation-Equivariant Detection (TED) architecture, leveraging the synthetically generated dataset. The original TED model components—including TeSpConv, TeBEV pooling, and TiVoxel pooling—are preserved to provide invariant feature extraction under arbitrary spatial transformations.
The isolated impact of synthetic data augmentation on TED enables a direct analysis of sim-to-real generalization, as no other architecture or training hyperparameters are altered.
Lightweight Multi-Object Tracking via Center Pose Integration
The multi-object tracking subsystem adopts a modular design inspired by AB3DMOT, but prioritizes computational efficiency via a center-based data association strategy. A greedy nearest-neighbor algorithm assigns detections to existing tracklets based on Euclidean distance in object center space, constrained by size-aware thresholds. This obviates the computational expense of appearance descriptors or complex affinity graphs.

Figure 3: Schematic depiction of the MOT module architecture, highlighting data association, prediction, management, and storage components.
Tracklet prediction employs historical smoothing for stationary assets, robust outlier rejection via orientation consistency checks, and symmetry-aware orientation hypothesis selection for ambiguous, symmetric geometries. Dynamic transitions are handled through threshold-based criteria for position and angle deviations. The management subsystem prunes unreliable associations based on temporal stability checks, while storage ensures seamless integration with ROS 2-based data broadcasting and visualization.
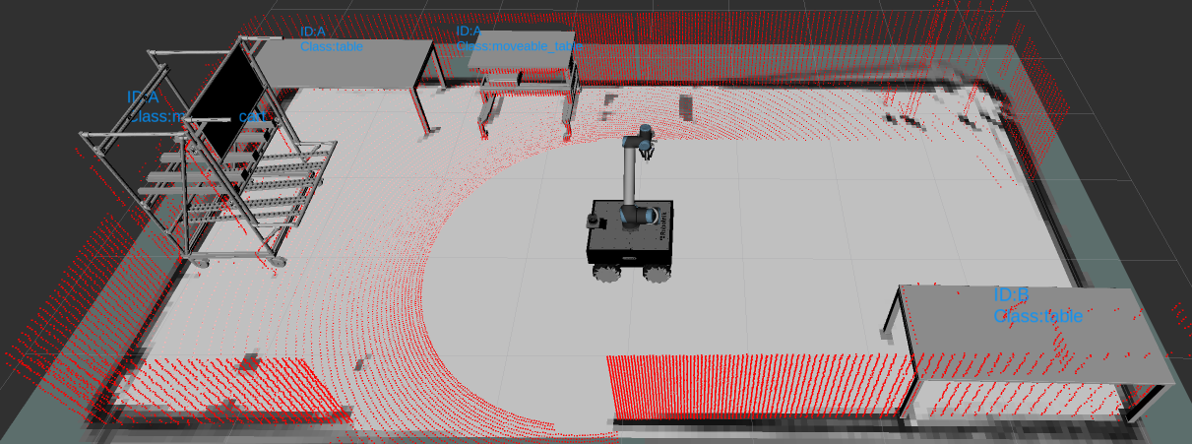
Figure 4: Real-time RViz-based visualization of active tracklets and trajectories, reflecting spatiotemporal continuity and association fidelity.
Experimental Setup and Evaluation Protocol
The experimental platform leverages a state-of-the-art RB-Kairos mobile manipulator, equipped with an Ouster OS1-128 LiDAR and ground-truth motion capture via OptiTrack. The experimental scenarios are systematically structured using a mixed-level orthogonal array, encompassing variations in object number, robot linear/angular velocity, occlusion, and initial distances.

Figure 5: Industrial lab layout at WZL-IQS, encapsulating robot platform, assets, occluders, and motion capture infrastructure.
Metrics include spatial localization (IoU, RMSE), detection accuracy (DetA), and higher-order tracking accuracy (HOTA), enabling a comprehensive assessment of system robustness across varying operational conditions.
Quantitative and Qualitative Results
Integrated pose estimation and tracking yield significant performance gains. With standalone TED-based detection, mean IoU reaches 62.67%; MOT integration furthers this to 83.12%, corresponding to a 20.45% improvement. Directional RMSE drops from 1.21 m (detection-only) to 0.05 m (MOT), and yaw RMSE decreases from 67° to 10.99°. The tracking system attains 91.12% HOTA on average, with highest class-specific performance observed for mobile storage units (93.92% HOTA, 88.04% IoU in MOT mode).
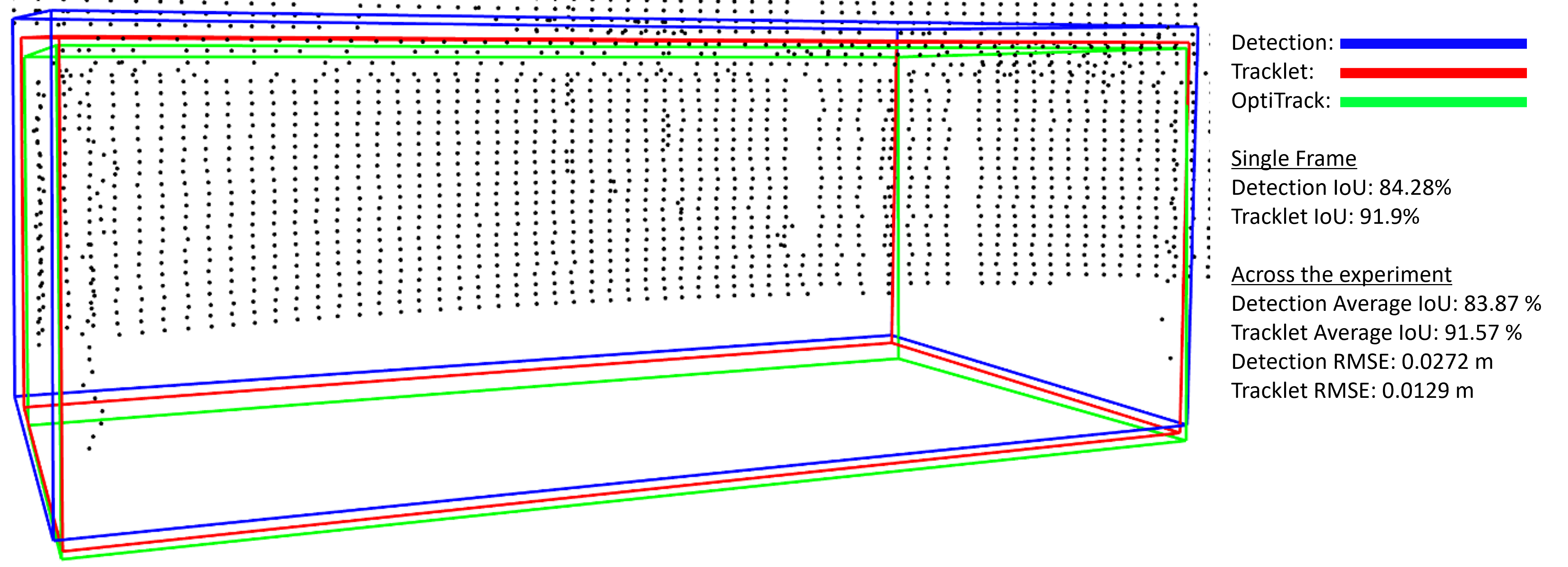
Figure 6: Visualization of bounding box alignment in a representative SW experiment, depicting enhanced overlap post-tracking.
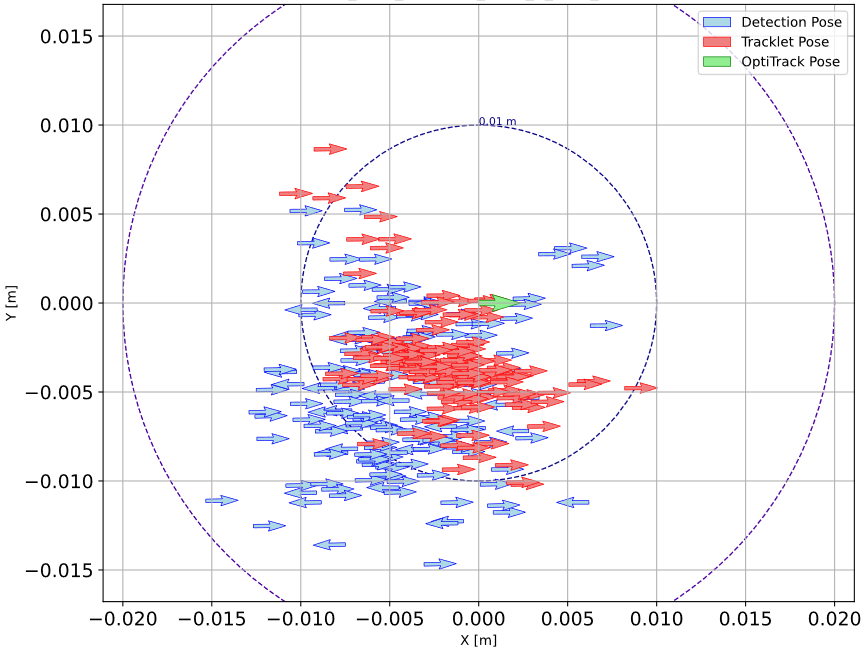
Figure 7: Plots of directional and rotational error evolution in a SW (stationary workstation) sequence, indicating pronounced error attenuation via MOT.
A salient result is the MOT module’s capability to resolve yaw ambiguities in symmetric objects, reducing worst-case flipping errors by 98.8% (from 102.5° to 1.23° RMSE). The initialization requirement of multiple consecutive detections introduces minor latency, but decisively minimizes false positives and improves aggregate localization precision.
Performance degrades under high-speed robot rotation, attributed to point cloud-server transfer latency and misaligned timestamping, which induce error modes scaling quadratically with angular velocity. Despite this, the MOT-enhanced architecture maintains stable object association under challenging occlusion and velocity conditions, subject to the underlying accuracy of the pose estimation backbone.
Implications and Prospective Directions
Practically, the proposed system promotes reliable closed-loop task execution for industrial mobile manipulators—such as docking and precision material handling—without manual data annotation. Theoretically, it demonstrates the scalable efficacy of synthetic data and transformation-equivariant priors in bridging sim-to-real for 3D perception tasks. The lightweight, modular MOT implementation offers a deployable trade-off between real-time efficiency and association accuracy, directly benefiting industrial automation applications where safety and adaptability are paramount.
Future research directions include system latency minimization, multi-modal sensor fusion with RGB-D for fine-grained perception, integration with digital twins for persistent asset tracking, and adaptation for broader industrial subdomains (such as automotive), where dynamic asset perception and spatiotemporal tracking are critical.
Conclusion
This work establishes a robust, modular perception system built upon synthetic data generation, transformation-equivariant detection, and efficient multi-object tracking within a ROS 2 framework. The system achieves substantial accuracy and reliability advances in 6D pose estimation and object association under dynamically challenging industrial conditions, with proven applicability for real-world mobile manipulation scenarios. The research substantiates the efficacy of synthetic learning pipelines and lightweight tracking paradigms as scalable solutions for next-generation adaptive robotics in production environments.

