- The paper presents a two-stage framework that separates semantic expansion from online retrieval, enabling high recall and low latency news search.
- It employs a dynamic retrieval tree built from collaborative agents—Planning, Retrieval, Augmented, and Reflection—to efficiently manage temporal drift and redundancy.
- Empirical results on proprietary and BEIR benchmarks demonstrate that dynamic subtree selection yields up to 1.5x performance gains in live deployment.
DynaTree: A Dynamic Agentic Retrieval Tree for High-Recall, Low-Latency News Retrieval
Motivation and Problem Context
High-recall news retrieval in temporally dynamic corpora presents persistent challenges for IR systems: queries are frequently abstract and under-specified, episodic events shift topical distributions, and demands for content freshness and subtopic diversity outpace the adaptation speed of standard RAG and agentic RAG. Classical relevance feedback, query expansion, and freshness-aware ranking offer improvements but lack persistent, structured mechanisms to mitigate temporal drift and redundancy in expansion. Most current agentic RAG methods tightly couple semantic exploration and retrieval in short-horizon inference cycles, incurring prohibitive online costs and limiting systemic reuse. This architectural deficiency is especially acute in production news systems, where recall and freshness directly drive user utility and engagement.
DynaTree Framework
DynaTree addresses these deficiencies via a two-stage framework that explicitly decouples semantic expansion from online retrieval, materializing agentic reasoning as a reusable retrieval tree structure. This design enables amortized, role-specialized agentic exploration offline (Stage I), and dynamic, lightweight subtree selection online (Stage II), permitting rapid adaptation to temporal distribution shift without incurring the high inference costs associated with repeated expansion or agentic reasoning.
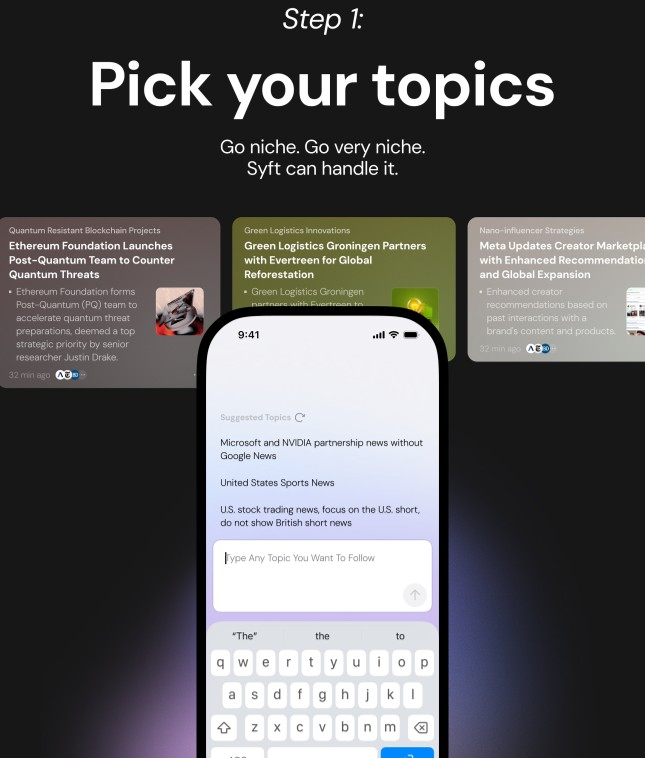
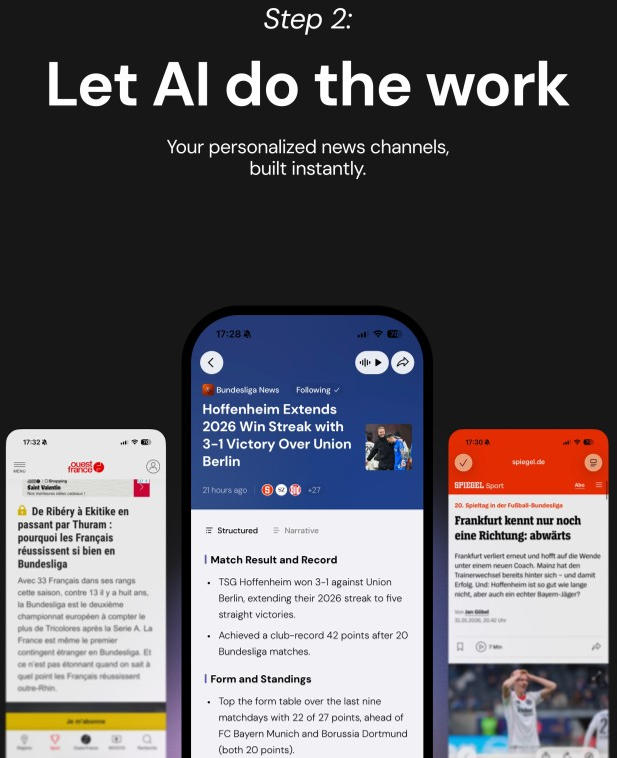
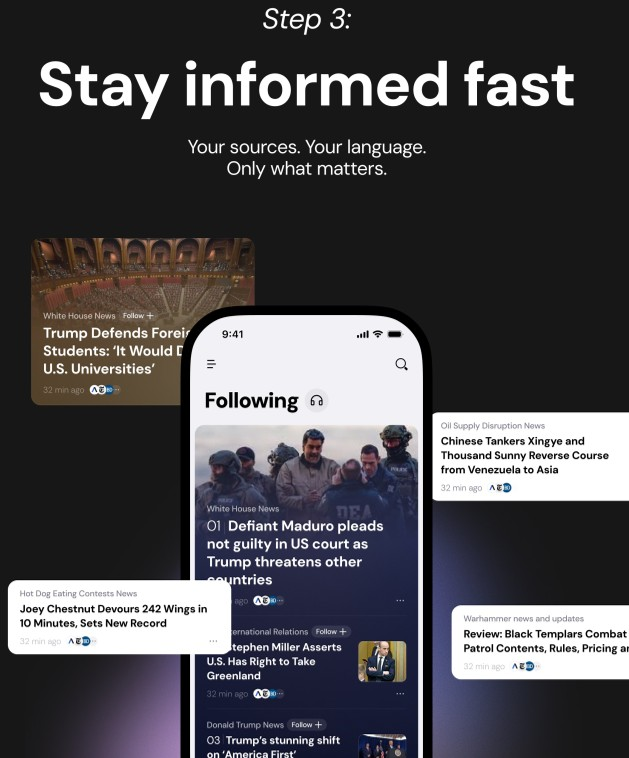
Figure 1: Syft deployment pipeline; DynaTree powers live adaptive news retrieval for improved user experience.
Stage I: Agentic Retrieval Tree Construction
Semantic exploration is cast as a recursive, path-conditioned process. A set of collaborative agents (Planning, Retrieval, Augmented, Reflection) work together to construct a retrieval tree T rooted at the original query q. Each node represents a semantic refinement, with edges encoding the recursion trajectory. For each path, the Planning Agent generates a context-aware expansion, the Retrieval Agent selects and executes an appropriate retrieval operator, the Augmented Agent normalizes and compresses retrieved evidence within fixed budgets, and the Reflection Agent performs structural self-correction using retrieval feedback. This yields a persistent structure encoding a rich ensemble of semantic trajectories (root-to-leaf paths) capturing both stable topical intent and evolving subtopic structure.
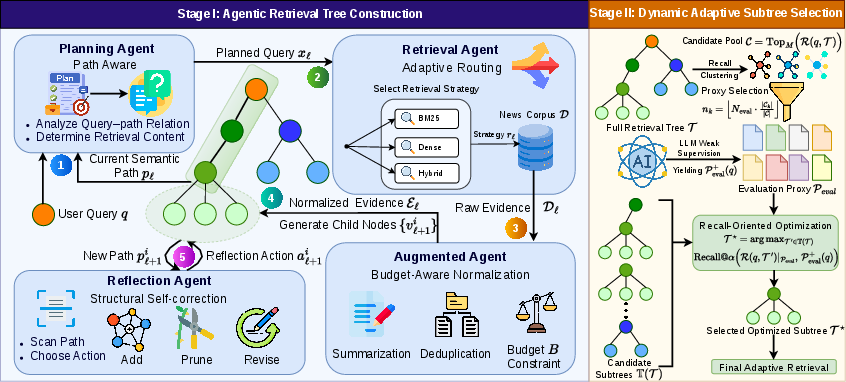
Figure 2: DynaTree architecture with agentic tree construction (Stage I) and proxy-driven online subtree selection (Stage II).
Stage II: Dynamic Subtree Selection
Rather than using the entire tree for each retrieval, Stage II introduces a lightweight but effective subtree selection process. Each day, an evaluation proxy is built by retrieving the M top-ranked documents (with diversity-preserving embedding-based stratification), and an LLM provides relevance annotations on this compact set. For each candidate subtree, recall relative to the LLM-proxied relevance set is estimated, and the system adopts the subtree maximizing recall@α. The online retrieval pipeline thus operates purely as a structure-aware, path-ensemble semantic matcher, with no further agentic inference or retraining. This approach retains high adaptability in the face of shifting news distributions while amortizing complex agentic reasoning.
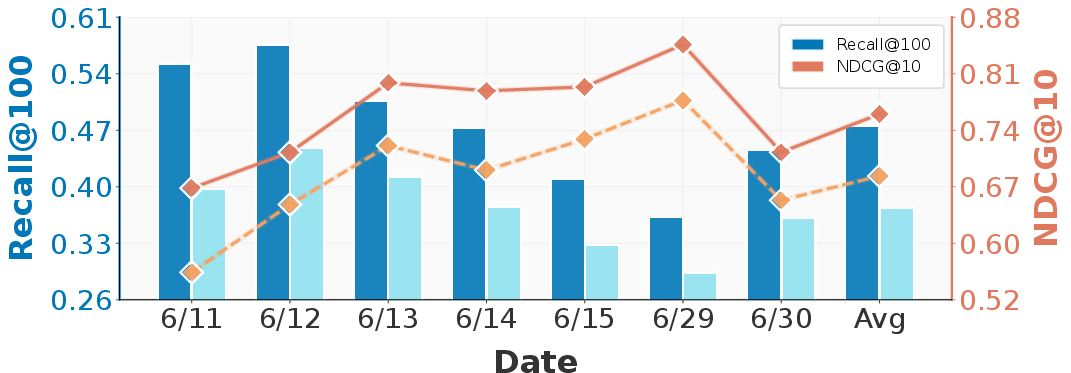
Figure 3: Subtree selection yields consistent performance gains; ablation (full tree vs. best subtree) highlights structural adaptivity benefits.
Empirical Validation
DynaTree is evaluated on both the proprietary Syft News benchmark (seven daily corpora) and five BEIR public datasets. On the Syft benchmark, DynaTree consistently outperforms all baselines, with Recall@100 ranging from 0.36–0.58 and NDCG@10 from 0.66–0.84, while second-best baselines typically plateau at 0.30–0.41 recall and 0.67–0.73 NDCG. These results are robust to significant temporal shifts in the underlying news distribution.
Ablation and Sensitivity Studies
Comprehensive ablations show that every agentic component (Planning, Retrieval, Augmented, Reflection) provides positive but non-additive contributions to recall and ranking quality (analyzed using Shapley value decomposition). Stage II subtree selection, rather than simple full-tree usage, confers stable 8–12% gains in both recall and NDCG. Proxy size studies demonstrate that 100–200 LLM-annotated samples suffice for stable, reliable subtree selection. Trees of depth 3 consistently outperform shallower variants, providing richer paths for semantic coverage.
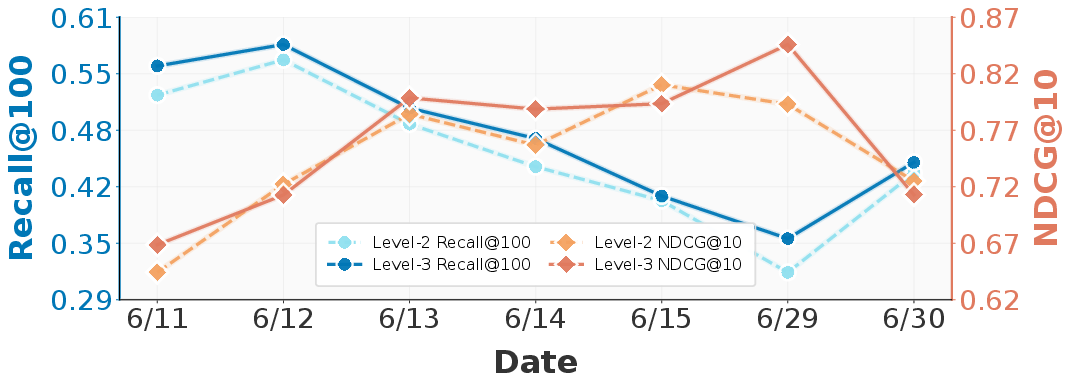
Figure 4: Level-3 retrieval trees (deeper semantic trajectories) dominate Level-2 on both recall and NDCG during temporal shifts.
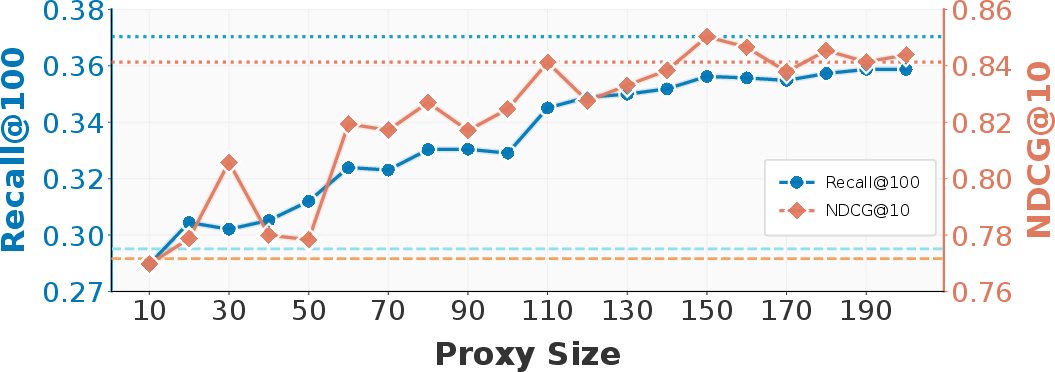
Figure 5: Stage-II proxy size vs. performance; ~200 proxy samples yield upper-bound recall, validating data-efficiency and practicality.
Online Deployment
DynaTree was deployed in a production pipeline serving millions of live retrievals on the Syft news platform. An A/B test compared daily dynamic subtree selection against static, offline-selected subtrees and all incumbent recallers. Across ten days, DynaTree with daily adaptation lifts survival rate from 0.32–0.53 (static) to 0.59–0.73 (dynamic), consistently outperforming all previously deployed recaller strategies—achieving up to 1.5x absolute improvement in survival under live user traffic.
Theoretical and Practical Implications
By divorcing semantic expansion from per-query inference, DynaTree demonstrates that high-recall, latency-constrained retrieval over evolving corpora can be realized with only amortized agentic cost. Structured, path-based expansions enable expressive coverage while explicit structural selection manages temporal drift and redundancy without heavy online inference. This design principle directly challenges the previously dominant paradigm of per-inference query expansion, establishing structured persistence and dynamic adaptation as new foundational capabilities for production RAG and agentic IR systems.
DynaTree’s methodology extends beyond news: any domain requiring temporally adaptive, high-coverage document recall—such as entity-aware search, event monitoring, or emerging topic exploration—will benefit from its staged, structure-aware approach. The demonstrated gains under strong real-world constraints (corporate-scale user traffic, strict latency, dynamically shifting corpora) underscore its practical viability.
Future Directions
Potential future extensions include graph-based generalization for non-tree expansion, finer-grained control over adaptive operations (online branching, path revisiting), and integration of real-time user feedback as additional weak supervision for subtree selection. Techniques for automated subtopic detection and entity tracking within trees may further enhance adaptation under rapid concept drift. Finally, formal analysis of structure selection stability and robustness under high label noise remains an open theoretical direction.
Conclusion
DynaTree constitutes a decisive advance in structured agentic retrieval for temporally dynamic news systems (2605.31377). By introducing a persistent, agentically constructed retrieval tree decoupled from online inference and enabling dynamic subtree adaptation through compact evaluation proxies, DynaTree achieves superior recall and ranking quality both offline and in live deployment settings. This framework reifies structured, adaptive semantic expansion as a practical, high-utility solution for real-world, high-recall document retrieval under nonstationary data distributions.