- The paper introduces Ψ-RAG, a novel method that uses hierarchical abstract tree indexing with agent-driven retrieval to overcome multi-hop reasoning challenges in large document corpora.
- It employs a dynamic agglomerative 'merging and collapse' strategy, integrating dense tree-based, sparse keyword, and query reorganization techniques for robust performance.
- Empirical results show significant F1 score improvements over existing models, demonstrating practical efficiency and theoretical insights for scalable retrieval-augmented generation.
Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation
Introduction and Motivation
The paper "Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation" (2605.00529) addresses core challenges in retrieval-augmented generation (RAG) for LLMs when integrating external document collections. Traditional dense and sparse retrieval strategies, as well as Tree-RAG approaches, exhibit fundamental limitations in corpus-scale, cross-document, and multi-hop reasoning scenarios. Tree-RAG methods, exemplified by frameworks like RAPTOR, break down when the scale increases: they are strongly affected by inflexible structural assumptions from k-means-type clustering, suffer from structural isolation that impairs multi-hop reasoning across documents, and exhibit abstraction granularity that is often too coarse for token-level fact retrieval.
The paper introduces Ψ-RAG, a new agentic Tree-RAG framework that overcomes these deficiencies through a novel hierarchical abstract tree indexing scheme and a multi-granular, agent-driven retrieval paradigm. Ψ-RAG diverges from the k-means lineage and instead employs an agglomerative clustering style "merging and collapse" strategy. Retrieval is delegated to an intelligent agent that dynamically mixes dense tree-based retrieval, sparse keyword-based retrieval, and sophisticated query reorganization as necessitated by the task. This approach affords robust support for both single- and multi-hop, single- and cross-document, token-, passage-, and document-level tasks, without requiring data-dependent parameter tuning or retraining.
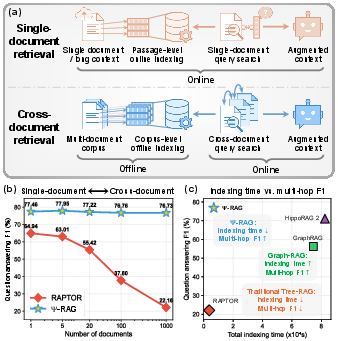
Figure 1: Two major RAG scenarios—single-document and cross-document retrieval—and the comparative multi-hop QA performance versus document number, highlighting the efficiency and accuracy of Ψ-RAG.
Framework: Ψ-RAG Pipeline
Ψ-RAG separates into two principal modules: Abstract Tree Indexing and Multi-granular Agentic Retrieval.
Abstract Tree Indexing
Rather than enforcing a top-down k-ary or binary split, Ψ-RAG operates by hierarchical agglomeration of semantically similar chunks, ranked according to learned encoder similarity, to form multi-level, dynamically structured abstract nodes. Merging and collapse operations recursively bind chunks and subtrees based on data-dependent proximity, accommodating arbitrary corpus size and distributional characteristics. For each abstract node, an LLM-powered abstraction agent generates either a summative or keyword abstract. Tree rebalancing mitigates context-window issues by capping child node counts and distributing branches evenly, with node splits as required.
This process enables encoding of semantically coherent, non-uniform subtrees, facilitating both fine- and coarse-grained retrieval while circumventing the uniformity biases and lossy abstraction issues prevalent in previous approaches.
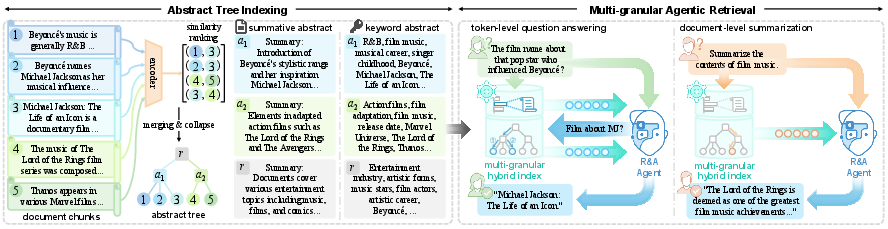
Figure 2: Ψ-RAG architecture—abstract tree indexing and agentic retrieval, with the knowledge base structured by both a tree index and a sparse keyword index.
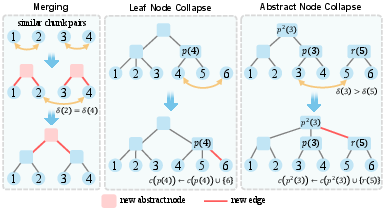
Figure 3: Merging and node collapse operations in abstract tree construction, depicting the flexible assembly process.
Multi-granular Agentic Retrieval
Ψ-RAG builds retrieval around an LLM-based agent that enacts a multi-hop, iterative process: upon receiving a query, the agent determines whether to answer or to generate a reformulated query for further retrieval. For each retrieval step, it combines:
- Top-down dense retrieval over the hierarchical tree index, prioritizing high-relevance abstract nodes and their descendants,
- Sparse BM25 retrieval against a separate keyword index,
- Reranking of results (e.g., via large-scale reranker models or reciprocal rank fusion),
- Query reorganization—context-aware query expansion with additional appositions/descriptions.
This orchestrated retrieval continues up to a maximal attempt budget, avoiding spurious over-retrieval chains, and ultimately returns a chain-of-thought-augmented answer or an explicit declaration of insufficient evidence.
Distribution Adaptability Analysis
The study provides thorough theoretical and empirical analysis demonstrating the uniformity pathologies of k-means trees and the adaptivity of Ψ-RAG's agglomerative tree. For k-means, the objective's symmetric treatment of clusters encourages equalized cluster size, regardless of the true data distribution, which leads to major-to-minor cluster assignment errors and substantial semantic confusion in retrieval—validated both analytically and via visualizations.
Conversely, hierarchical abstract trees constructed with Ψ-RAG preserve minor-class structure and selectively assign nodes to subtrees in accordance with natural semantic divisions, as formalized using Dasgupta's cost measure.
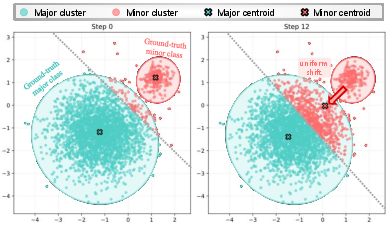
Figure 4: Demonstration of the "uniform effect" of k-means: mode collapse as nodes are misassigned from major to minor clusters through iterative updates.
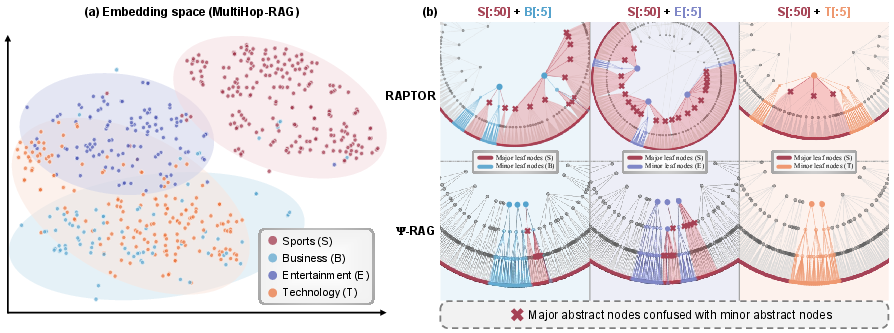
Figure 5: RAPTOR versus Ψ-RAG on MultiHop-RAG with skewed distributions; Ψ-RAG presents minor class regions with far less confusion and less intermingling between major and minor classes.
Empirical Results
Ψ-RAG was evaluated on comprehensive cross-document, single- and multi-hop QA, narrative QA, and summarization benchmarks, using open-source LLMs for all components. Key findings:
- On cross-document multi-hop QA, Ψ-RAG achieves an average F1 score improvement of 25.9% over RAPTOR and 7.4% over HippoRAG 2—outperforming even advanced Graph-RAG methods.
- In document-level summarization, Ψ-RAG matches or exceeds the performance of community graph-based and TF-IDF/BM25 approaches with much higher retrieval and generation accuracy.
- Ablations highlight the synergistic necessity of the agentic retriever, the sparse index, and reranking; agentic retrieval alone yields gains of ~20% F1 for multi-hop QA, with additional substantial benefit from hybrid retrieval.
- Ψ-RAG's efficiency is strong: despite the O(n2) time/space for explicit similarity ranking, judicious use of bucketing and ANN search (HNSW) enables construction and search on million-scale corpora within practical computational resource constraints.
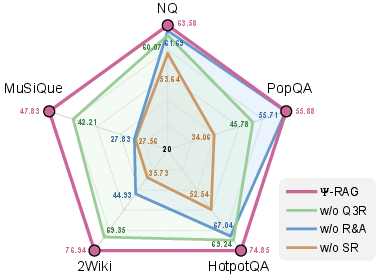
Figure 6: F1 ablation—performance rapidly deteriorates when the sparse retriever, reranker, or agent are disabled, demonstrating their necessity.
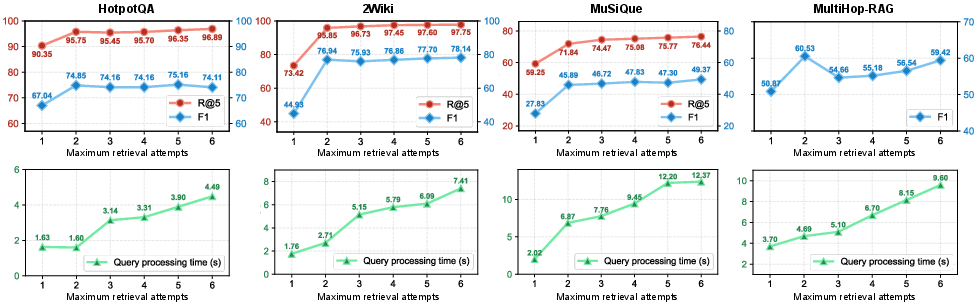
Figure 7: Recall@5, F1, and query processing time curves for increasing retrieval steps, showing the cost-utility tradeoff of additional agentic retrieval iterations.
Theoretical and Practical Implications
This work establishes that hierarchical agglomerative abstract tree indexing can overcome the structural and distributional bottlenecks inherent to prior Tree-RAG systems. By decoupling the tree structure from rigid clustering assumptions and leveraging a dynamic, agent-controlled retrieval regime, Ψ-RAG demonstrates stable, robust performance across task granularities and data scales.
Practically, this architecture allows for open-source, modular deployment atop evolving LLM platforms and is compatible with continual index updates and heterogeneous corpus composition—enabling practical cross-document RAG in industrial information retrieval, QA, and summarization settings. The inclusion of multi-granular and agentic mechanisms positions Ψ-RAG as a canonical baseline for research on scalable reasoning across large, unstructured knowledge bases.
Theoretically, the analysis of Dasgupta cost and uniformity bias clarifies fundamental principles for RAG index design, and the workflow provides a template for combining hierarchical and agentic retrieval in future architectures.
Conclusion
Ψ-RAG delivers a flexible, generalizable Tree-RAG framework that efficiently supports corpus-scale indexing and augments retrieval-augmented LLMs with robust cross-document multi-hop reasoning. The shift toward hierarchical abstract trees and agent-driven, multi-granular retrieval advances the state of the art in both theoretical understanding and empirical performance for structured RAG. Future research will likely extend these approaches by developing more efficient LLM-based abstractors, integrating reinforcement learning for task-adaptive agent optimization, and scaling indexing strategies to truly web-scale corpora.