mRNAutilus: Multi-Objective-Guided Discrete Generation of mRNA with Optimized Therapeutic Properties
Abstract: Therapeutic mRNA design requires coordinating multiple interacting sequence features across the full transcript, where codon usage, untranslated regions (UTRs), and their coupling jointly determine stability, translation efficiency, and protein expression. Here, we present mRNA generation via unrolled trajectories and informed latent updates (mRNAutilus), a framework for simultaneous codon optimization and de novo UTR design directly from sequence. mRNAutilus combines a masked discrete diffusion model trained on millions of full-length mRNAs with Monte Carlo Tree Guidance to generate Pareto-efficient sequences under multiple functional objectives, using lightweight regressors over model embeddings to predict half-life, translation efficiency, and protein abundance. Unlike recent methods that design coding sequences and UTRs separately or rely on post hoc assembly and screening, mRNAutilus generates complete transcripts in a single process optimized across properties. Across diverse targets, zero-shot mRNAs encoding P. pyralis luciferase achieve over 400-fold higher expression than wild-type and outperform commercial and machine learning-designed baselines, including zero-shot generative approaches. Zero-shot SARS-CoV-2 Spike mRNAs exceed clinically used and commercial constructs and match or surpass lab-optimized designs with improved durability. We further demonstrate generality in therapeutic settings, including prime editing (PEMax) and programmable proteome modulation, where mRNAutilus-designed constructs enhance expression of peptide-guided E3 ligases (uAbs) for beta-catenin degradation. These results establish a sequence-based, multi-objective framework for generating functional mRNAs tailored to diverse biological applications.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces mRNAutilus, a new AI tool that designs full-length mRNA “recipes” for cells. The goal is to create mRNAs that last longer, are read more efficiently by the cell’s protein-making machines, and produce more of the desired protein. Instead of designing different parts of an mRNA separately, mRNAutilus builds the entire message at once and balances several goals at the same time. The team shows that its designs work well in lab experiments for different medical uses, like vaccines, gene editing, and targeted protein degradation.
What questions did the researchers ask?
They focused on three simple but important questions:
- Can we automatically design complete mRNA sequences that make lots of protein and last long enough in cells?
- Can we optimize all the key parts of an mRNA together at once (the 5'UTR “front”, the coding region made of codons, and the 3'UTR “back”), instead of separately?
- Will these AI-designed mRNAs actually work better than standard or commercial designs in real cell experiments?
How did they do it?
To explain their approach, think of an mRNA as a recipe card:
- The coding region (CDS) is the recipe’s steps written in “codons” (three-letter words). Different codons can mean the same amino acid, like synonyms.
- The untranslated regions (UTRs) are notes around the recipe (the margins) that control how the recipe gets used—how quickly the cell starts reading it and how long the message sticks around.
Here’s how mRNAutilus designs better “recipe cards”:
- Learned from millions of real mRNAs They trained a large AI model on millions of natural mRNA sequences so it could understand what real, effective mRNAs look like.
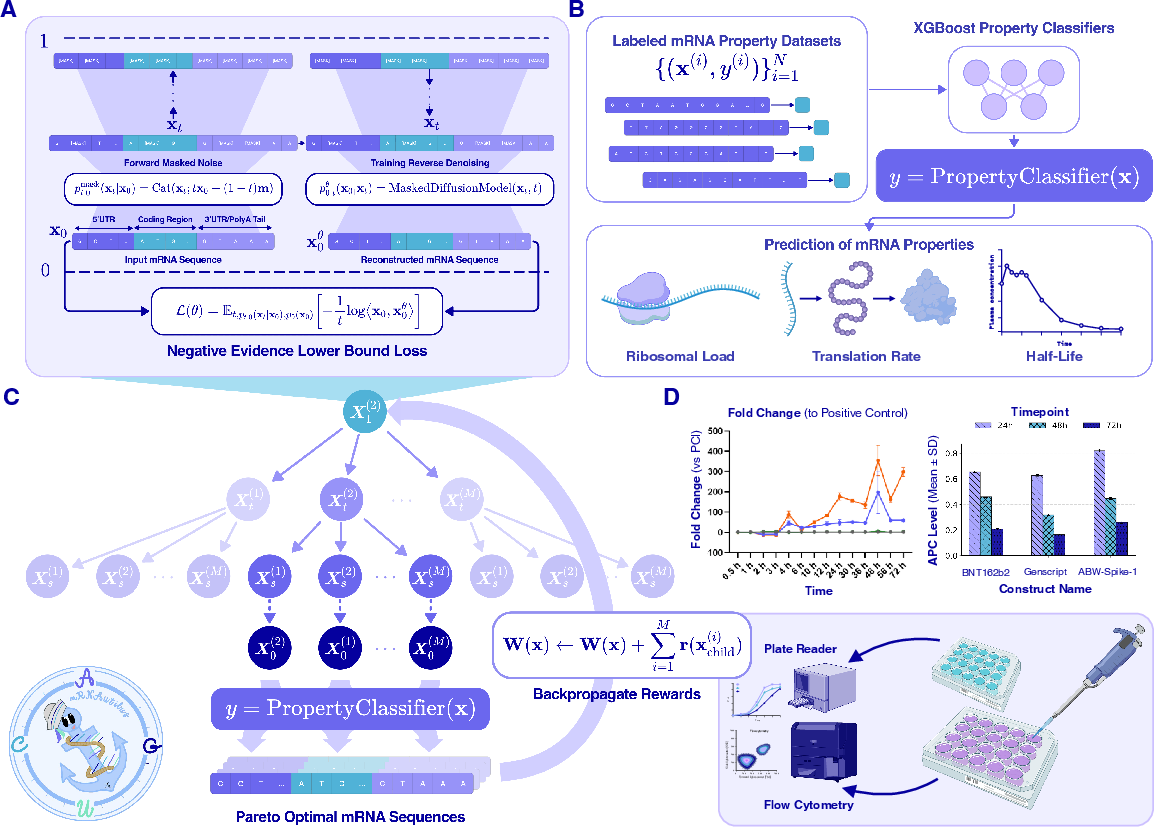
- A “fill-in-the-blanks” generator They used a method called a masked discrete diffusion model. Imagine a crossword where most letters are covered; the AI gradually reveals and fills in the blanks in a smart order. This lets it design entire mRNAs, not just one part at a time.
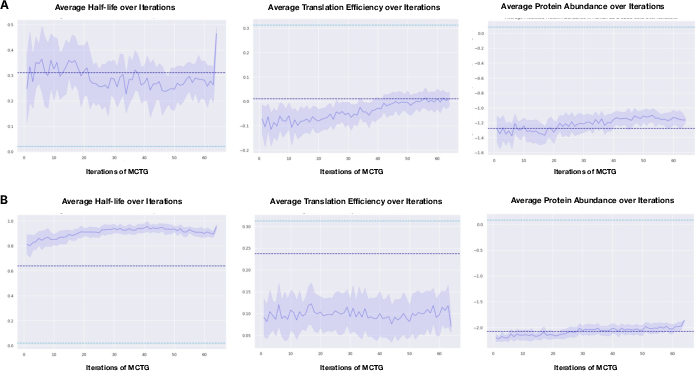
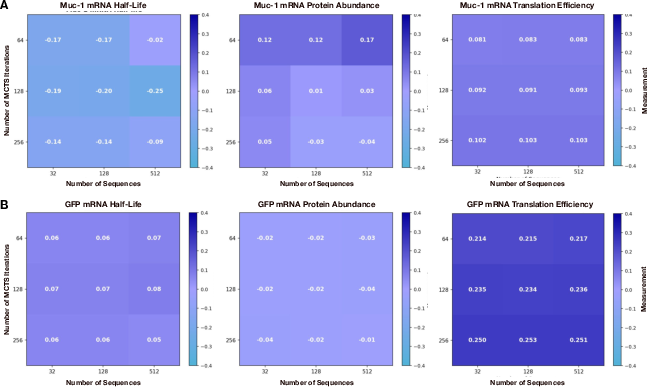
- Smart guidance during generation Just filling in blanks isn’t enough—you want the best outcome. The team used Monte Carlo Tree Guidance, which is like exploring many choose-your-own-adventure paths at once and keeping the paths that score best. Scores are based on:
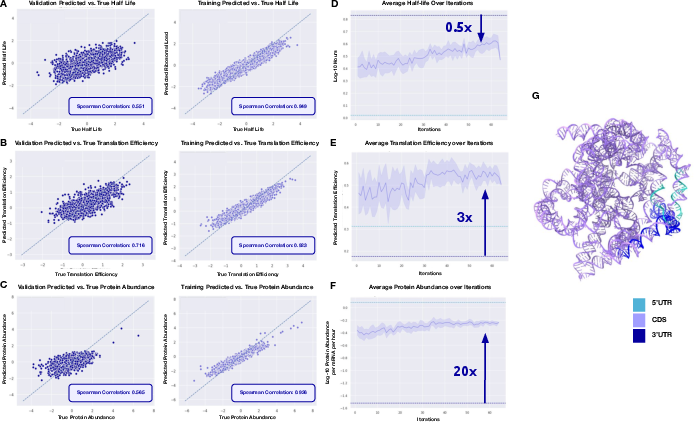
- Half-life: how long the mRNA lasts before it breaks down.
- Translation efficiency: how easily the cell’s “chefs” (ribosomes) pick up and read the recipe.
- Protein abundance: how much final protein is made.
- Quick “judges” to score sequences To score each candidate mRNA, they used small, fast prediction models (regressors) that read the AI’s internal “fingerprints” of the sequence (embeddings) and estimate half-life, translation efficiency, and protein output. These judges help steer the generator toward strong designs. The method aims for Pareto-optimal results—solutions that balance trade-offs so you can’t improve one goal without hurting another.
In short: the model proposes many full mRNA sequences, predicts how good each one looks for several goals, and keeps improving the best ones until it finds a set of top trade-offs.
What did they find, and why is it important?
Across several real tests, the AI-designed mRNAs performed impressively—without extra “trial-and-error” lab tuning.
Key results included:
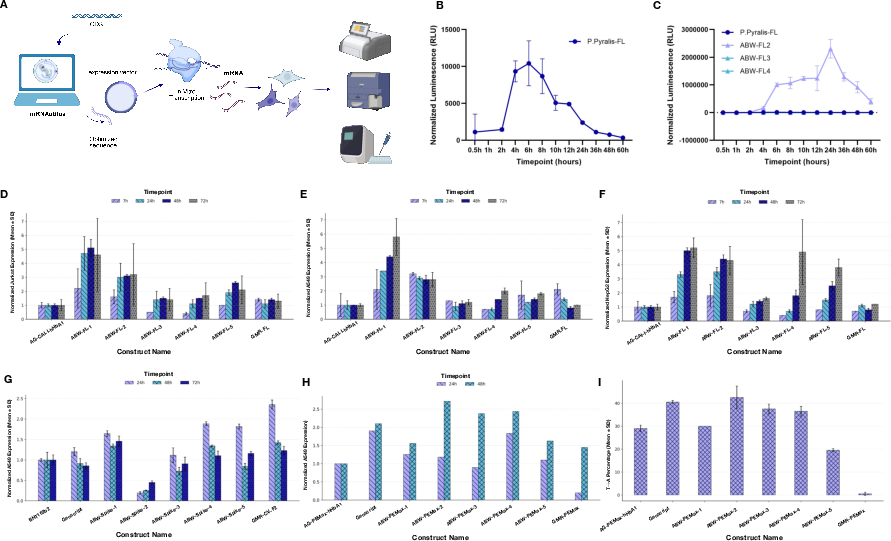
- Stronger luciferase reporter mRNAs Luciferase is a common “glow” protein used to measure expression. Some AI-designed luciferase mRNAs produced about 400 times more signal than the natural (wild-type) version and beat both a commercial design and another machine-learning method across multiple human cell lines. This shows the approach can create very high-expression mRNAs in a single shot.
- Better SARS-CoV-2 Spike mRNAs When they designed mRNAs encoding the Spike protein (used in COVID-19 vaccines), several AI designs outperformed a commercial Spike construct and matched or surpassed a lab-optimized design, with signs of better durability over time. That’s encouraging for vaccine design.
- Improved prime editing mRNAs (PEMax) Prime editing is a precise gene-editing method. The team’s AI-designed mRNAs for a large editor called PEMax showed higher expression and, importantly, higher editing efficiency at a test site in cells than a commercial PEMax mRNA. That means better real-world gene editing performance.
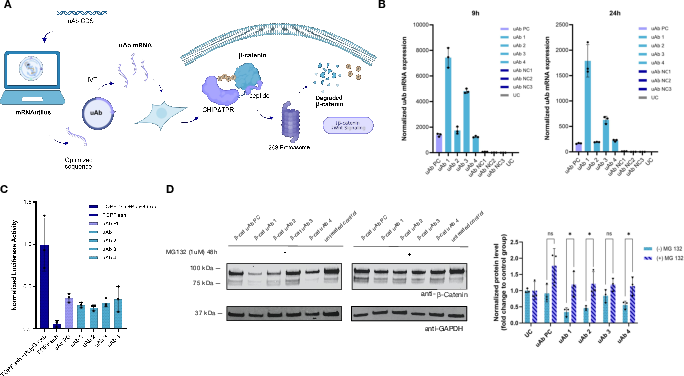
- Functional protein degradation (uAbs) They also designed mRNAs for “ubiquibodies” (uAbs), engineered proteins that tag harmful targets inside cells for destruction. The AI-designed uAb mRNAs were expressed more strongly and successfully knocked down a cancer-related protein, beta-catenin, in cells. When they blocked the cell’s trash-disposal system (the proteasome), the effect went away—confirming the degrader worked as intended.
Why this matters:
- It’s the first system that simultaneously designs the entire mRNA with multiple goals in mind, rather than sticking pieces together later.
- It works “zero-shot,” meaning it can design strong sequences for new targets it wasn’t trained on.
- It shows benefits across very different applications: vaccines, reporters, gene editors, and targeted protein degradation.
What does this mean for the future?
This work suggests a faster, smarter way to create mRNA medicines:
- Speed: Instead of months of trial-and-error on different parts, this tool can propose strong full-length mRNAs in one pass.
- Versatility: It can be used for vaccines, protein therapies, genome editing tools, and designer degraders.
- Better performance: By balancing half-life, translation efficiency, and protein output, it can achieve higher expression and longer-lasting effects.
What’s next:
- Even better data: The guidance relies on predictors trained on existing datasets. Larger, cleaner, and more diverse lab datasets will make the tool even more accurate.
- Broader testing: These results are from cell experiments. Moving toward animal studies and then clinical use will be important to confirm safety, dosing, and effectiveness in the body.
- Tailoring to tissues: Different tissues and diseases may need different balances (for example, very high expression vs. very long half-life). This multi-goal system can be tuned for those needs.
Bottom line: mRNAutilus is a promising step toward “programming” medicine at the sequence level—designing custom mRNAs that are more stable, more efficient, and more powerful for many medical applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain or unexplored in the paper, framed as concrete, actionable items for future work:
- Data and predictors
- Property predictors are trained on sparse, heterogeneous, and cell-type–mixed datasets (half-life, ribosome profiling, protein abundance), with no explicit batch-effect correction, domain adaptation, or uncertainty calibration; how robust are rewards to dataset shift across cell types, species, or assay conditions?
- Guidance relies on three proxy objectives (half-life, translation efficiency, protein abundance); key therapeutic attributes such as immunogenicity (innate/adaptive), tissue specificity, secretion/processing efficiency, and toxicity are not modeled or predicted.
- No evaluation of predictor generalization/calibration on independent held-out labs/datasets or quantification of prediction uncertainty (e.g., conformal prediction) to avoid overconfident guidance.
- Lack of direct experimental measurements of half-life and translation efficiency (e.g., metabolic labeling, decay kinetics, polysome profiling) for designed constructs to validate embedding-based regressors.
- Sequence design space and constraints
- UTR design does not explicitly constrain deleterious motifs (e.g., upstream AUGs/uORFs, cryptic splice sites, strong RNAse sites, AU-rich elements, G-quadruplexes) or enforce avoidance of harmful dinucleotide patterns (CpG/UpA) and long homopolymers; risk of generating translation-impeding or unstable UTRs remains unassessed.
- No explicit modeling of miRNA/RBP binding site landscapes or cell-type–specific post-transcriptional regulation in UTRs; generated UTRs may have unintended regulatory interactions.
- Chemical modifications (e.g., m1Ψ, Ψ, m6A) are not represented in training or generation; consequences for immunogenicity, stability, translation, and structure are unmodeled and untested.
- Poly(A) tail length/composition, 5′ cap chemistry, and IVT/capping parameters, which critically affect stability and expression, are excluded from design and optimization.
- Tokenization and training include IUPAC ambiguous bases; safeguards to prevent ambiguous/invalid tokens in generated therapeutic sequences are not described.
- A fixed Kozak fragment (“GCCACC”) is appended rather than learned/optimized; the impact of this heuristic versus data-driven Kozak optimization across contexts is not evaluated.
- Codon optimization is restricted to synonymous substitutions; the framework does not explore amino-acid–level engineering objectives (e.g., secretion signals, glycosylation sites, signal peptides) when such changes are permissible or desired.
- Guidance and optimization methodology
- Multi-objective performance is assessed mainly via proxy regressors; no evaluation of Pareto-front quality using standard multi-objective indicators (e.g., hypervolume, coverage) or baselines (evolutionary/MOEA methods).
- No head-to-head comparison of MCTG with alternative discrete guidance algorithms (e.g., TR2-D2, MOG-DFM, AReUReDI) within the mRNA setting to quantify benefits/costs.
- Reward scaling/normalization, trade-off handling, and sensitivity to objective weighting are not systematically analyzed; stability of solutions under different reward formulations remains unclear.
- Limited ablations on the contributions of CDS optimization versus UTR design to observed gains; the extent to which cross-component coupling drives improvements is not isolated experimentally.
- Biological validation and safety
- In vitro only: no in vivo validation (e.g., pharmacokinetics, biodistribution, immunogenicity, durability, efficacy) to confirm translation of gains beyond cell lines.
- Immunogenicity and innate immune activation (e.g., IFN responses, ISG induction, TLR/RIG-I/MDA5 activation) are not measured for designed mRNAs; dsRNA byproducts and cytokine profiles are not profiled.
- Functional assessment of Spike is limited to expression; antigen processing/presentation, glycosylation fidelity, and neutralizing antibody elicitation are untested.
- For PEMax, only a single locus edit (HEK3, T→A) is measured; editing breadth (insertions/deletions), efficiency across loci/cell types, off-target edits, and cytotoxicity are not characterized.
- For uAbs, off-target proteome effects, global pathway perturbations, and long-term cellular consequences (viability, stress responses) are not assayed; proteome-wide degradation specificity is untested.
- No assessment of translational fidelity (frameshifting/readthrough), unintended peptide products, or cryptic ORFs arising from designed UTRs.
- Manufacturability and deployment
- IVT manufacturability constraints (template GC extremes, repeat-rich regions), capping/clean-up efficiency, dsRNA burden, and lot-to-lot consistency are not incorporated into objectives or evaluated empirically.
- Delivery/formulation context (e.g., LNP chemistry, dose, administration route) is absent; interactions between sequence features and delivery parameters affecting in vivo performance are unexplored.
- Sequence-level IP/freedom-to-operate and regulatory considerations (e.g., known clinically used UTRs/motifs) are not discussed; practical deployment constraints remain unspecified.
- Generalization and scope
- Generalization is demonstrated on a limited set of targets; performance on diverse protein classes (membrane, secreted, multi-pass, very long ORFs) and across primary cells or clinically relevant tissues remains unknown.
- Cross-species training data (broad vertebrate Ensembl) may encode regulatory patterns not optimal for human cells; the benefits and risks of training on mixed-species UTRs are not dissected.
- No exploration of tissue- or cell-type–specific optimization (e.g., hepatocytes vs dendritic cells), despite known context dependence of UTR-mediated regulation.
- Reproducibility and transparency
- Detailed release of code, model weights, and training/validation splits for regressors is not provided; independent replication and benchmarking may be impeded.
- Limited statistical power in some assays and incomplete reporting of replicate numbers/variance across all experiments; comprehensive statistical analyses are lacking for several comparisons.
These gaps suggest a roadmap: develop richer, cell-type–aware and immunogenicity-aware objectives with calibrated uncertainty; integrate biochemical/manufacturing constraints and RNA modifications into the design loop; benchmark guidance algorithms with standard multi-objective metrics; and validate in vivo across diverse payloads and delivery contexts with comprehensive safety and functional profiling.
Practical Applications
Overview
Based on the paper’s findings, methods, and innovations—namely a masked discrete diffusion generator coupled with Monte Carlo Tree Guidance (MCTG) and embedding-based regressors for half-life, translation efficiency, and protein abundance—mRNAutilus enables practical applications that span R&D, bioprocess, clinical translation, and regulatory practice. Below are actionable use cases, categorized as deployable now or requiring further development. Each item notes relevant sectors, potential tools/products/workflows, and key dependencies or assumptions that affect feasibility.
Immediate Applications
- High-expression research reagents (reporters) for cell-based assays
- Sectors: Academia, diagnostics, biotech R&D, CROs
- What: Rapid, zero-shot design of luciferase and other reporters with markedly higher expression versus wild-type and commercial baselines for assay readouts, transfection QC, and platform benchmarking.
- Tools/workflows: Use the mRNAutilus interface/API to generate CDS+UTR designs; integrate with in vitro transcription, standard capping/poly(A) workflows, and cell-line transfection assay pipelines.
- Dependencies/assumptions: In vitro gains may vary by cell line; manufacturing details (capping chemistry, nucleoside modifications, poly(A) tailing) and delivery modality (e.g., LNPs) materially impact outcomes; current regressors do not model immunogenicity.
- Antigen mRNA optimization for vaccine discovery and preclinical screening
- Sectors: Healthcare (vaccines), biopharma, CDMOs
- What: Generate Spike or other antigen mRNAs that exhibit improved expression and durability to accelerate hit-identification and down-selecting in preclinical programs.
- Tools/workflows: Design CDS+UTRs jointly; produce small panels optimized for half-life/translation; test in cell lines, then in small animal immunogenicity screens; integrate with existing LNP formulations.
- Dependencies/assumptions: Optimized expression does not guarantee optimal immunogenicity; antigen conformation/glycosylation must be conserved; regulatory comparability protocols needed for AI-designed sequences.
- Enhanced mRNA payloads for gene editing (e.g., prime editing with PEMax)
- Sectors: Gene therapy, cell therapy, genome engineering
- What: Improve expression and editing efficiency for editors (prime/base editors, Cas9 variants) in ex vivo or in vitro contexts by co-optimizing CDS and UTRs.
- Tools/workflows: Design editor mRNA panels; deliver with pegRNA/sgRNA complexes; evaluate editing rates and off-targets; use for ex vivo editing or tool benchmarking.
- Dependencies/assumptions: Editing outcomes depend on guide design and delivery; immunogenicity and stress responses not yet modeled; larger ORFs may require additional sequence constraints.
- Transient, mRNA-encoded protein degraders (uAbs) for target validation
- Sectors: Pharma target validation, oncology, functional genomics
- What: Rapidly express peptide-guided E3 ligases to degrade endogenous targets (e.g., β-catenin) to probe pathway dependence and validate targets in disease-relevant lines.
- Tools/workflows: Optimize uAb mRNAs; transfect and measure protein knockdown (WB, proteomics); read out pathway activity (e.g., TOPFlash); use MG132 controls to confirm mechanism.
- Dependencies/assumptions: Degrader efficacy depends on binder quality and subcellular routing; proteasome dependence may vary across cell types; off-target degradation assessments required.
- In silico triage to reduce wet-lab screening burden
- Sectors: Biotech R&D, CROs/CDMOs, platform biotech
- What: Pre-filter mRNA designs using multi-objective regressors to prioritize compact “best-of” libraries for synthesis/testing, reducing iteration cycles and costs.
- Tools/workflows: Embed → predict → MCTG-guided generation → rank by Pareto efficiency → synthesize top-N; integrate with LIMS and bench automation.
- Dependencies/assumptions: Predictor generalization varies by cell type and payload; regular calibration with in-house data is advisable.
- SaaS/API for CDS+UTR co-design integrated into sequence design workflows
- Sectors: Software for biotech, CROs, computational biology groups
- What: Offer mRNAutilus as a cloud/API tool (e.g., integration with Benchling, DNA software, or internal LIMS) to standardize mRNA design workflows.
- Tools/products: “mRNAutilus Designer” SaaS/CLI; property predictor SDK; automated sequence QC; one-click synthesis order handoff.
- Dependencies/assumptions: Data security/IP controls; audit trails for regulatory review; service-level reliability.
- UTR and CDS library generation for mechanistic studies
- Sectors: Academia, platform biotech
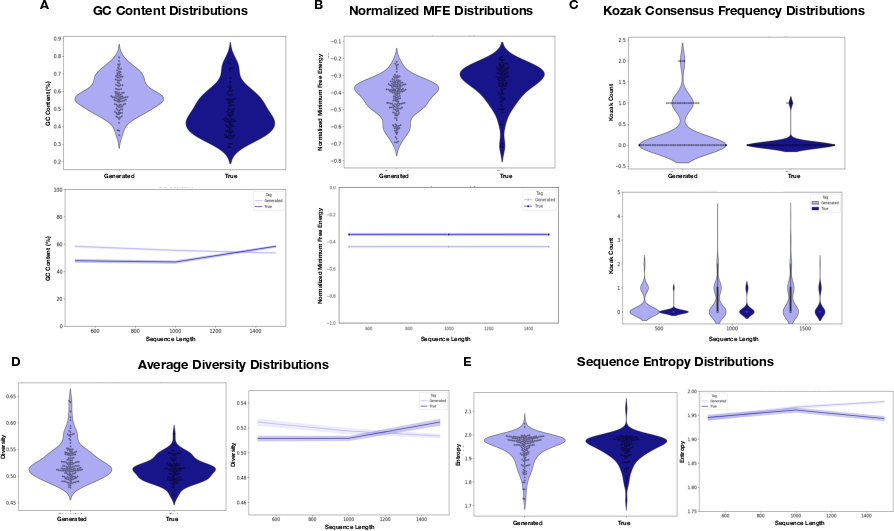
- What: Produce diverse UTR/CDS libraries with controlled GC/MFE distributions to interrogate motifs, structure, and translation initiation, feeding back to improved predictors.
- Tools/workflows: Library design → high-throughput transfection → RNA-seq/proteomics → active learning updates to regressors.
- Dependencies/assumptions: Requires scalable screening and standardized assays; cell-type specificity must be captured in data.
- Educational resources for sequence design and multi-objective optimization
- Sectors: Education, training programs
- What: Use the public interface to teach mRNA design principles, multi-objective trade-offs, and evaluation metrics in computational biology courses/labs.
- Tools/workflows: Classroom modules; hands-on labs designing reporter constructs; simple in vitro validation.
- Dependencies/assumptions: Access to basic molecular biology infrastructure; safety oversight for any wet-lab use.
- Regulatory/biosecurity testbeds for AI-sequence pipelines
- Sectors: Regulators, policy groups, biosecurity organizations
- What: Pilot audit procedures, metadata minimums, and validation templates for AI-generated therapeutic sequences using a controllable, generative system.
- Tools/workflows: Sandbox environments; provenance logs; performance benchmarking against reference constructs.
- Dependencies/assumptions: Cross-institutional collaboration; governance for model access and use; defined risk frameworks.
Long-Term Applications
- Rapid outbreak response platform for vaccine candidates
- Sectors: Public health, vaccines, biodefense
- What: End-to-end pipeline from pathogen sequence to optimized mRNA antigens within days, feeding into preclinical immunogenicity workflows.
- Tools/workflows: Automated antigen selection/epitope design → mRNAutilus optimization → LNP formulation → small-animal challenge studies.
- Dependencies/assumptions: Need validated immunogenicity and safety models; scalable manufacturing; regulatory fast-track mechanisms.
- Personalized cancer vaccines with co-optimized expression
- Sectors: Oncology, precision medicine
- What: Patient-specific neoantigen mRNAs designed to maximize translation and persistence, packaged as multi-epitope constructs.
- Tools/workflows: Neoantigen calling → construct assembly → CDS+UTR co-design → GMP production → adaptive dosing.
- Dependencies/assumptions: Accurate neoantigen prediction; individualized QA/QC; immune tolerance management; payer/regulatory alignment.
- Tissue- and cell-type–specific mRNA design
- Sectors: Gene therapy, regenerative medicine
- What: Train cell/tissue-specific property regressors and incorporate sequence motifs (e.g., miRNA target sites) to restrict or enhance expression in target tissues.
- Tools/workflows: Curate tissue-resolved datasets; add motif-aware constraints; validate in organoids/animal models.
- Dependencies/assumptions: Large, standardized, tissue-specific datasets; delivery that targets desired tissues; off-target expression risk mitigation.
- Co-optimization of sequence and delivery (LNP, polymers) in closed-loop DBTL
- Sectors: Drug delivery, CDMOs, pharma R&D
- What: Jointly optimize mRNA sequence features and nanoparticle chemistry for biodistribution, potency, and durability in vivo.
- Tools/workflows: Multi-modal models (sequence+formulation) → co-guided generation → automated in vivo screens → iterative model updates.
- Dependencies/assumptions: Integrated datasets across chemistry and biology; robust animal models; scalable automation.
- Low-immunogenicity mRNA design (nucleoside modifications, innate sensing)
- Sectors: Therapeutics, vaccines
- What: Extend objectives to penalize innate immune activation (e.g., TLR/RIG-I signatures) and incorporate modified nucleoside usage patterns to minimize reactogenicity.
- Tools/workflows: Train immunogenicity predictors; add constraints for modified nucleosides; standardized cytokine/ISG panels for validation.
- Dependencies/assumptions: High-quality immunogenicity datasets; manufacturing compatibility with modifications; regulatory acceptance.
- mRNA-encoded therapeutic protein replacement with dose-tailored kinetics
- Sectors: Rare disease, metabolic disorders
- What: Design mRNAs for protein replacement with tunable half-life and translation to meet dosing windows and PK/PD constraints.
- Tools/workflows: Objective weighting for durability vs. peak expression; in vivo PK/PD modeling; patient-specific titration.
- Dependencies/assumptions: Longitudinal in vivo data; chronic dosing safety; delivery to target organs.
- Programmable proteome modulation platforms (degraders, stabilizers, synthetic circuits)
- Sectors: Oncology, neuroscience, autoimmune diseases
- What: Scale uAb-like modalities and related proteome editors (e.g., deubiquitinase fusions) as mRNA therapies to dial protein levels transiently.
- Tools/workflows: Co-design binders and mRNAs; multiplexed target panels; proteome-wide off-target profiling.
- Dependencies/assumptions: Binder discovery pipelines; safety and specificity; regulatory path for novel modalities.
- Standardization and governance for AI-generated therapeutic sequences
- Sectors: Policy/regulatory, standards bodies
- What: Establish audit trails, explainability artifacts, and validation protocols specific to AI-generated mRNA (e.g., provenance of objectives, versioned models, and seeds).
- Tools/workflows: Model governance frameworks; submission-ready documentation templates; third-party certification ecosystems.
- Dependencies/assumptions: Consensus across agencies; interoperability standards; mechanisms for post-market surveillance.
- Autonomous mRNA foundries (design–build–test–learn)
- Sectors: Pharma, biofoundries, large research institutes
- What: Full-stack automation that feeds experimental data back into mRNAutilus regressors and guidance to continuously improve platform performance.
- Tools/workflows: Robotics for synthesis/formulation; high-throughput assay suites (expression, stability, immunogenicity); active learning loops.
- Dependencies/assumptions: Capital investment; robust QC; cross-disciplinary teams.
- Public health impact via faster access to updated vaccines and therapeutics
- Sectors: Daily life/public health
- What: Shorter timelines from variant detection to deployment-ready mRNA formulations, improving responsiveness to seasonal and emerging pathogens.
- Tools/workflows: Integrated surveillance-to-design pipelines; manufacturing flexibility; equitable distribution strategies.
- Dependencies/assumptions: Regulatory pathways for rapid iteration; global supply chains; pharmacovigilance infrastructure.
Notes on Cross-Cutting Assumptions and Dependencies
- Data limitations: Current regressors are trained on heterogeneous public datasets with limited cell-type coverage; performance can improve with new, standardized measurements (half-life, translation efficiency, protein abundance, immunogenicity).
- Generalization: In vitro gains may not fully translate to in vivo efficacy; delivery, dosing, and host factors are critical.
- Manufacturing specifics: Capping, poly(A) length, nucleoside modifications, and purification influence expression and immunogenicity; these are not explicitly modeled yet.
- Safety and ethics: AI-generated sequences must undergo standard safety, biosecurity, and regulatory review; guardrails for dual-use risk are essential.
- IP and compliance: Freedom-to-operate and documentation requirements (traceability, version control) are necessary for clinical translation.
- Infrastructure: Realizing closed-loop and co-optimization workflows requires automation, LIMS integration, and scalable screening capabilities.
These applications leverage the paper’s core innovation—multi-objective, full-transcript mRNA design via discrete diffusion with MCTG—to shorten design cycles, improve candidate quality, and broaden the utility of mRNA across vaccines, gene editing, and programmable proteome modulation.
Glossary
- 3'UTR (3-prime untranslated region): The non-coding region downstream of the coding sequence that influences stability and translation. "stability-guided 3'UTRs"
- 5'UTR (5-prime untranslated region): The non-coding region upstream of the coding sequence that regulates translation initiation and stability. "the Kozak motif ('GCCACC') is appended to the 5'UTR before token unmasking."
- Absorbing mask token: A special token in masked diffusion where once unmasked, tokens remain fixed, enabling an absorbing-state corruption process. "the forward noising process applies an absorbing mask token via:"
- AReUReDI: A multi-objective guidance method for discrete flow matching used to steer generative models toward desired properties. "multi-objective guidance for discrete flow matching (MOG-DFM, AReUReDI \citep{chen2025mogdfm, chen2025areuredi})"
- Bayes' rule: A probability theorem used to invert conditional probabilities; here, to derive the reverse posterior in diffusion. "Applying Bayes' rule yields the conditional reverse posterior:"
- BERT-style MDM: A masked-diffusion generative model with a BERT-like architecture for bidirectional context modeling. "Because mRNAutilus is a BERT-style MDM,"
- β-catenin: A protein central to Wnt signaling and oncogenesis; degradation target for therapeutic constructs. "for -catenin degradation."
- Categorical noise: Noise applied to discrete variables by sampling from a categorical distribution during the forward diffusion process. "applies categorical noise to "
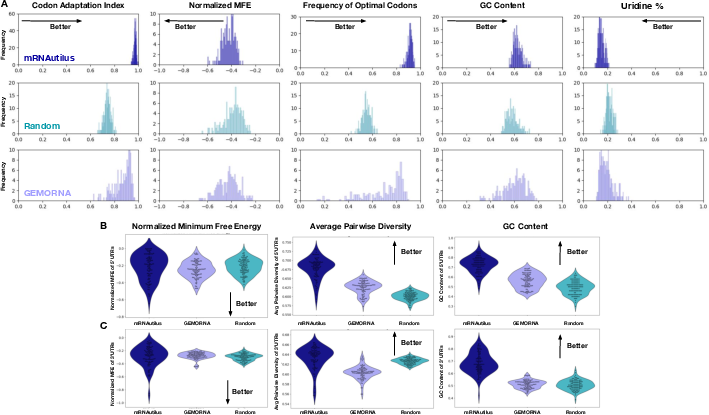
- Codon adaptation index (CAI): A metric quantifying how well a coding sequence’s codon usage matches preferred codons of a species. "maximize the codon adaptation index via species-specific codon-usage tables"
- Coding sequence (CDS): The nucleotide sequence that encodes a protein. "coding sequence (CDS)"
- Continuous-time negative evidence lower bound (NELBO): A training objective derived from the ELBO for continuous-time diffusion models. "continuous-time negative evidence lower bound (NELBO)"
- Denoiser: The neural network component that predicts clean tokens from noisy inputs in diffusion models. "parameterizes a denoiser over the joint UTR--CDS--UTR vocabulary"
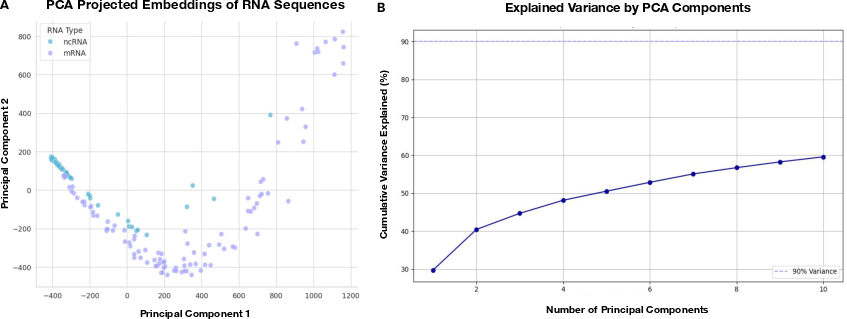
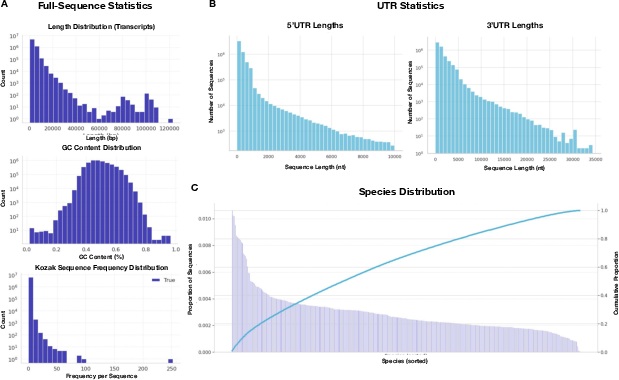
- Ensembl corpus: A large, curated genome and transcript database used for model pretraining. "from the Ensembl corpus"
- FlashAttention-2: An optimized attention algorithm for efficient Transformer inference and training. "we also utilize FlashAttention-2"
- Gumbel noise: Noise used with the Gumbel-Max trick to sample from categorical distributions. "we apply Gumbel noise"
- Immunogenicity: The ability of a molecule (e.g., an mRNA or its protein product) to provoke an immune response. "immunogenicity, and tissue-specific expression"
- IUPAC degenerate nucleotide codes: Standard symbols representing ambiguous nucleotides in sequences. "IUPAC degenerate nucleotide codes"
- Kozak consensus motif: A conserved sequence around the start codon that enhances translation initiation in eukaryotes. "Kozak consensus motifs"
- Lipid nanoparticle (LNP) delivery: A method to encapsulate and deliver mRNA therapeutics into cells. "Coupled with lipid nanoparticle delivery"
- Masked discrete diffusion models (MDMs): Discrete generative models that corrupt with masks and iteratively denoise to sample sequences. "Masked discrete diffusion models (MDMs) provide a natural architecture"
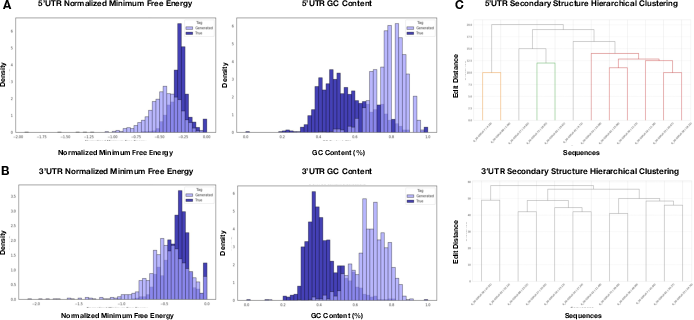
- Minimum free energy (MFE): A thermodynamic measure predicting the stability of RNA secondary structures. "minimum free energies (MFEs)"
- Monte Carlo Tree Guidance (MCTG): A tree-guided sampling strategy to steer discrete diffusion toward multi-objective optima. "Monte Carlo Tree Guidance (MCTG)"
- Nuclear localization signals (NLS): Short peptide motifs that direct proteins to the nucleus. "multiple nuclear localization signals"
- Pareto-optimal: A solution state where no objective can be improved without worsening another in multi-objective optimization. "Pareto-optimal sequences"
- Polysome profiling: An experimental method that measures ribosome loading on mRNAs to infer translation efficiency. "polysome profiling"
- Prime editing (PEMax): A genome editing approach using a Cas9 nickase fused to a reverse transcriptase; PEMax is an optimized variant. "prime editing (PEMax)"
- Probability simplex: The space of all nonnegative probability vectors that sum to one. "denotes the probability simplex over states."
- Proteasome inhibitor MG132: A small molecule that blocks proteasomal protein degradation. "proteasome inhibitor MG132"
- qPCR (quantitative PCR): A technique to quantify nucleic acid abundance via polymerase chain reactions. "by qPCR"
- Ribosome profiling: A sequencing technique that captures ribosome-protected mRNA fragments to assess translation. "ribosome profiling data"
- Rotary Positional Embeddings (RoPE): A positional encoding method that injects relative phase information into attention. "Rotary Positional Embeddings (RoPE)"
- SwiGLU: A gated activation function used in Transformer feed-forward networks for improved performance. "SwiGLU activation function"
- TR2-D2: A trajectory-aware tree search method for guiding discrete diffusion processes. "trajectory-aware tree search for discrete diffusion (TR2-D2"
- Ubiquibodies (uAbs): Engineered E3 ubiquitin ligases that redirect degradation to chosen targets via designed binders. "ubiquibodies (uAbs)"
- Ubiquitin–proteasome pathway: The cellular system that tags proteins with ubiquitin and degrades them via the proteasome. "ubiquitin--proteasome pathway"
- ViennaRNA: A software suite for RNA secondary structure prediction and free energy calculations. "as predicted by ViennaRNA"
- XGBoost: A gradient-boosted decision tree framework used here for property prediction from embeddings. "XGBoost regressors"
- Zero-shot: Using a model to generate or evaluate on new tasks/targets without task-specific training. "zero-shot mRNAs"
Collections
Sign up for free to add this paper to one or more collections.

