A Predictive Law for On-Policy Self-Distillation From World Feedback
Abstract: Moving beyond simple scalar rewards toward richer world feedback is a natural path to more scalable RL post-training. On-policy self-distillation (OPSD) is a promising recent approach that uses arbitrary feedback as learning signal, yet its reliability compared to established methods, such as GRPO, remains unclear. We identify a strikingly consistent linear correlation between the initial student-self-teacher performance gap and the final performance improvement in OPSD. This relationship holds across context types and model families, providing a powerful predictive law for anticipating the outcome of an OPSD configuration without running the full training procedure. Interestingly, we show that this linear predictability holds with model scale, suggesting a potential basis for new empirical scaling laws on larger models with stronger in-context learning capabilities. In essence, our findings show that OPSD performance can be predicted and tuned before training, offering a principled way to incorporate world feedback as a first-class component of the post-training pipeline.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Predictive Law for On-Policy Self-Distillation From World Feedback — Explained Simply
What is this paper about?
This paper studies a way to help AI models get better by learning from their own experiences and the “world” around them. Instead of only rewarding a model for getting an answer right or wrong, the authors use richer feedback, like error messages or test results from coding tasks. They then show a simple rule: if you measure how much better a model with extra hints is compared to the same model without those hints before training, you can predict how much the model will improve after training.
What questions are the researchers asking?
The authors focus on three big questions:
- If we give the “teacher” version of a model extra information (like hints or feedback) and compare it to the regular “student” model, does the size of that initial gap predict how much the student will improve after training?
- Does this rule work for different kinds of extra information and different model families?
- Does it still work for both small and larger models?
How did they study this?
Think of one model as two versions of the same student:
- The “student” sees only the original problem.
- The “self-teacher” is the same model, but it gets extra clues called “privileged context” (like a helpful checklist, a peer’s solution, or feedback from failed tests). Because of those clues, the self-teacher usually performs better right away.
They train the student to imitate the self-teacher on the student’s own attempts. This is called “on-policy self-distillation”:
- “On-policy” means the model practices on its own choices, not examples picked by another model.
- “Self-distillation” means the model learns from a stronger version of itself that has extra hints.
What they did, in everyday terms:
- Task: Coding problems from a benchmark called LiveCodeBench (it automatically runs code and gives pass/fail test results and error messages—i.e., “world feedback”).
- Setup: They tried six kinds of extra information for the self-teacher, such as:
- No extra info (control)
- An expert-style preamble (like a problem-solving checklist)
- Feedback from previous failed attempts (e.g., error messages)
- Hints or solutions from peers
- The model’s own earlier solution plus feedback
- Peer solution plus feedback
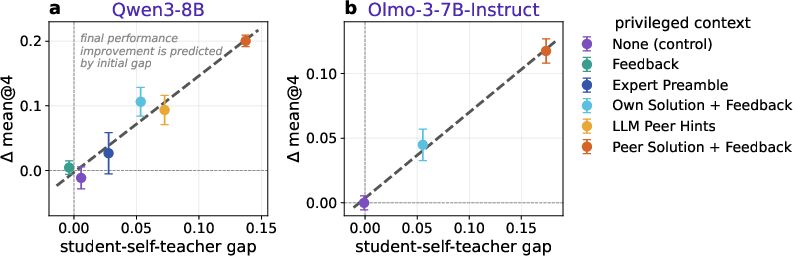
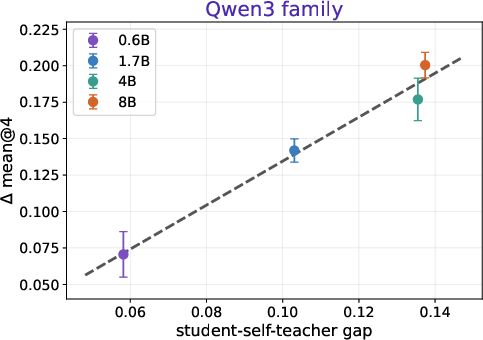
- Models: They tested two model families (Qwen3 and Olmo 3), and also tested multiple sizes of Qwen3 (from smaller to bigger).
- Simple measurement: Before any training, they measured the “initial gap” = (self-teacher accuracy) − (student accuracy). Then they trained for a short time and measured how much the student improved in the end.
What did they find, and why does it matter?
The main discovery is a simple, strong, and consistent pattern:
- The bigger the initial gap between the self-teacher and the student, the more the student ends up improving after training.
- This relationship is basically a straight line: double the gap, roughly double the improvement.
- It works across different types of extra information and different model families.
- It also holds across different model sizes, from small to larger.
Why this is important:
- You can predict training outcomes early. Instead of running many long training jobs, you can quickly test several “hint setups,” measure the initial gap once, and pick the best setup to train.
- It makes using rich “world feedback” (like test failures, error messages, or peer hints) practical and reliable in post-training.
- It suggests a path to new “scaling laws,” where we can forecast improvements for bigger models using the same simple rule.
What could this change in the future?
- Faster tuning: Teams can try different ways of giving extra context, measure the initial gap, and choose the most promising approach before spending lots of compute on training.
- Better use of feedback: Because the rule works with many types of hints and feedback, developers can comfortably include real-world signals (like test results) in training.
- More predictable improvements: Since the rule also holds as models get bigger, it could guide how we plan improvements for future, larger systems.
In short: The paper shows a clear, practical shortcut—measure the performance gap between a normal model and the same model with helpful hints, and you can reliably predict how much training will improve the model. This makes training smarter, cheaper, and more dependable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates what remains missing, uncertain, or unexplored in the paper, expressed as concrete, actionable directions for future research.
- Generalization beyond coding: evaluate whether the predictive law holds on non-coding tasks (e.g., math reasoning, multi-hop QA, instruction following, tool-use) using diverse benchmarks (GSM8K/MATH, HotpotQA, BBH, WebArena).
- Richer environments: test OPSD with interactive or multi-turn environments (e.g., program repair loops, web navigation, API/tool orchestration) and non-verifiable feedback (human critiques), assessing whether the law persists.
- Out-of-distribution robustness: measure if the linear relation holds under domain shift (new time slices of LiveCodeBench, novel problem distributions, unseen libraries/APIs).
- Scaling to larger models: validate the law for models >8B (including 14B, 70B) with appropriate hyperparameter tuning; report where scaling breaks, and whether slopes/intercepts change with scale.
- Chain-of-thought/thinking mode: determine whether enabling deliberate reasoning (chain-of-thought, scratchpad) affects the student–self-teacher gap, training dynamics, and the linearity of the predictive law.
- Training horizon sensitivity: test the law across substantially different training lengths (e.g., 10, 200, 1000 steps) to check for saturation, nonlinearity, or late-stage divergence from the teacher.
- Hyperparameter invariance: systematically ablate EMA rate, batch size, rollouts per prompt, learning rate, gradient clipping, and distillation top-k to assess how sensitive the law is to training settings.
- Objective choice: compare reverse-KL with alternative divergences (forward-KL, JS, cross-entropy, relaxed objectives) to determine whether the predictive law is objective-dependent.
- Decoding hyperparameters: quantify how differences between train-time and validation-time decoding (temperature/top-p/pass@k) affect the initial gap and the reliability of predictions.
- Measurement protocol for “cheap” gap estimation: determine the minimum number of prompts needed to estimate the initial gap with usable confidence; provide sample-size guidelines and computation-time trade-offs.
- Slope/intercept calibration: propose and validate a practical procedure (small pilot runs or bootstrapping) to estimate model- and context-specific slopes/intercepts before full training; report confidence intervals.
- Negative or near-zero gap regimes: test contexts where the self-teacher underperforms the student (negative gap) or matches it (zero gap) to see if the law predicts no improvement or degradation.
- Robustness to noisy/misleading privileged context: introduce controlled noise, contradictory feedback, partial/incorrect peer solutions, and hallucinated hints to stress-test the law’s stability.
- Privileged context design space: perform fine-grained ablations on context length, source (retrieval vs generated), hint granularity, reference quality, and feedback structure to map how these factors translate into initial gap changes.
- Group/peer configuration: vary group size, diversity of peer rollouts, and selection criteria (best, median, random peer) to measure effects on the gap and final improvement.
- Teacher drift dynamics: study how self-teacher improvements over training (as EMA tracks the student) interact with the initial-gap predictor and whether a time-varying gap better explains outcomes.
- Model-family diversity: replicate results across more families (e.g., Llama, Mistral, Phi, Gemma) and instruction vs base variants to test portability of the law.
- Baseline comparisons: benchmark OPSD against OPD, GRPO/RLVR, and PRM-based methods under matched compute to contextualize the predictive law’s practical utility and trade-offs.
- Metric sensitivity: check whether the law holds for pass@1, pass@k, and exact match/functional correctness variants; report differences across metrics.
- Data contamination and evaluation integrity: audit whether “peer solutions” or context materials risk leakage or trivialization; formalize safeguards ensuring correctness without shortcutting the task.
- Clarity and reproducibility of context templates: resolve the “LLM Peer Hints” template that appears to include a full correct solution; provide unambiguous definitions for each context type and release exact prompts.
- Formalization of the OPSD objective: present a clean, unambiguous mathematical specification (and reference implementation) of the per-token reverse-KL objective to avoid ambiguity in reproductions.
- Confidence and statistical power: increase seed counts (especially for Olmo-3 and omitted contexts) and report confidence intervals for slopes/intercepts to strengthen claims of linearity and generality.
- Extrapolation limits: test whether the law remains linear for very large gaps (strong privileged contexts) or very small gaps, identifying saturation points or nonlinear regimes.
- Cost–benefit analysis: quantify compute/time savings of using the predictive law for configuration screening versus running full OPSD, including the cost of initial-gap estimation.
Practical Applications
Overview
Below are practical, real-world applications enabled by the paper’s core finding: a robust, linear, and scale-invariant relationship between the initial student–self-teacher performance gap and the final performance improvement in on-policy self-distillation (OPSD) with world feedback. This “predictive law” lets practitioners cheaply forecast OPSD outcomes before training, select effective privileged contexts, and allocate compute more efficiently.
Immediate Applications
- Bold: OPSD configuration screening for post-training pipelines
- Sectors: software, AI/ML platforms, academia
- Tools/Products/Workflows: “OPSD GapMeter” that computes the initial student–self-teacher gap for each candidate privileged context and predicts final gains via a calibrated linear model; a lightweight pre-training evaluation stage that runs only inference on a validation set to rank context templates (e.g., expert preambles, feedback, peer solutions)
- Assumptions/Dependencies: access to a validation set and the privileged context variants; the linear fit should be calibrated per base model/domain; world feedback must be tokenizable and reliably improves the self-teacher’s in-context behavior
- Bold: Compute and budget planning for RL post-training (ROI gating)
- Sectors: industry (LLMOps), finance (FP&A for AI orgs), policy (sustainability reporting)
- Tools/Products/Workflows: dashboards that convert predicted accuracy gains into cost/benefit projections and “go/no-go” decisions; batch schedulers that allocate GPUs only to high-ROI OPSD runs
- Assumptions/Dependencies: organization-specific cost models; stable mapping from predicted task metrics (e.g., mean@4) to business value; the predictive law calibrated on the org’s data/model family
- Bold: Early stopping and run gating in RLVR/OPSD training
- Sectors: software, AI/ML platforms
- Tools/Products/Workflows: training controllers that set target improvement bands based on the initial gap and terminate runs that underperform predicted trajectories; alerts when live student performance deviates significantly from the expected convergence to the self-teacher
- Assumptions/Dependencies: reliable online evaluation; OPSD training recipe similar to the paper’s (reverse-KL, EMA teacher) or re-calibrated otherwise
- Bold: Context/template A/B testing for world-feedback ingestion
- Sectors: software engineering (code assistants), customer support, education technology
- Tools/Products/Workflows: a “Context Designer” library that iterates over prompt/feedback templates (e.g., Expert Preamble, Feedback, Peer Solution + Feedback), measures the gap, and auto-selects top candidates before any training
- Assumptions/Dependencies: verifiable or high-quality feedback sources (unit tests, rubric scores, runtime errors, verdicts) and consistent tokenization
- Bold: LLMOps observability: add “gap” to evaluation dashboards
- Sectors: industry (MLOps/LLMOps), academia
- Tools/Products/Workflows: integrations with experiment trackers (e.g., W&B, MLflow) to log the initial gap, predicted improvement, and realized gain; regression-fit artifacts versioned alongside runs
- Assumptions/Dependencies: evaluation harness alignment with train-time decoding parameters; standardized protocol for computing the gap on a fixed validation split
- Bold: CI/CD-driven code assistant fine-tuning from world feedback
- Sectors: software engineering
- Tools/Products/Workflows: GitHub/GitLab Actions that package failing tests, stack traces, and peer solutions into privileged contexts; nightly OPSD jobs are launched only when predicted gains exceed a threshold
- Assumptions/Dependencies: robust test suites, clean feedback extraction, and data governance for code/logs; the law demonstrated on LiveCodeBench suggests strong immediate transfer to similar coding setups
- Bold: Academic experimental design and sample-efficiency
- Sectors: academia
- Tools/Products/Workflows: plan OPSD studies by pre-computing gaps to prune weak context conditions; use the predictive law to reduce the number of expensive full training runs while still exploring a broad design space
- Assumptions/Dependencies: domain-specific calibration; controlled reporting of decoding settings and validation splits to ensure reproducibility
- Bold: Benchmarking and reporting standards for OPSD
- Sectors: academia, policy, standards bodies
- Tools/Products/Workflows: require publications and model cards to report the initial gap and the fitted slope/intercept used for predictions; add “gap-aware” leaderboards for OPSD
- Assumptions/Dependencies: community agreement on protocol (e.g., fixed validation tasks, decoding parameters); acceptance by venues and benchmark maintainers
- Bold: Lightweight personalization of small local models via world feedback
- Sectors: daily life (developers, data analysts), SMBs
- Tools/Products/Workflows: short OPSD sessions on-device or on a small server using user logs as privileged context (e.g., common errors, preferred patterns), only when predicted improvements justify the compute
- Assumptions/Dependencies: adequate local compute; privacy-compliant logging; limited to domains where feedback is informative (coding, data wrangling, templated writing)
Long-Term Applications
- Bold: Self-improving production agents with predictive monitors
- Sectors: software, customer support, operations
- Tools/Products/Workflows: autonomous agents that continuously harvest rich world feedback (tickets, error traces, user critiques), compute gaps for candidate contexts, and schedule OPSD updates when predicted ROI is high; guardrails prevent drift by enforcing predicted convergence bands
- Assumptions/Dependencies: robust safety, rollback, and evaluation infrastructure; high-quality, verifiable feedback streams; long-horizon stability of the predictive law under changing data
- Bold: Cross-domain OPSD in robotics using environment/sensor feedback
- Sectors: robotics, manufacturing, logistics
- Tools/Products/Workflows: privileged contexts built from execution traces, failure modes, and controller diagnostics; planners estimate gains from short OPSD sessions before deploying updated policies
- Assumptions/Dependencies: transformation of multimodal signals into tokenized feedback; safety validation; likely re-calibration of the predictive law beyond code
- Bold: Clinical and biomedical assistants that learn from clinician feedback
- Sectors: healthcare
- Tools/Products/Workflows: systems ingest structured clinician corrections, guideline citations, and adjudicated errors as privileged context; hospitals predict whether fine-tuning rounds are worth the compute and risk
- Assumptions/Dependencies: strong privacy/compliance (HIPAA/GDPR), high-quality adjudication, clear verifiability proxies (gold standard references), domain calibration and guardrails to prevent unsafe drift
- Bold: Educational tutors that distill rubric-based world feedback
- Sectors: education
- Tools/Products/Workflows: tutors use instructor rubrics, solution exemplars, and programmatic graders as privileged contexts; institutions use predicted gains to schedule model updates between terms/courses
- Assumptions/Dependencies: reliable programmatic grading or curated rubrics; mitigation of model overfitting to narrow rubrics; fairness audits
- Bold: Finance and compliance automation with verifiable rule feedback
- Sectors: finance, legal/compliance
- Tools/Products/Workflows: reconciliation errors, policy violations, and audit findings supply privileged context; teams prioritize fine-tuning windows based on predicted improvements
- Assumptions/Dependencies: strict data governance; high-precision feedback labels; conservative safety thresholds due to regulatory risk
- Bold: Auto-curriculum and context evolution policies that target “optimal gaps”
- Sectors: AI/ML platforms, research
- Tools/Products/Workflows: controllers that select or synthesize privileged contexts to keep the student–self-teacher gap within a band that maximizes stable learning; integration with retrieval-augmented generation and prompt/context evolution
- Assumptions/Dependencies: reliable online estimation of the gap; causal understanding of when larger gaps destabilize training; advanced context-engineering toolchains
- Bold: Scaling planners for 70B+ models and multi-domain OPSD
- Sectors: foundation model providers
- Tools/Products/Workflows: “Scaling Planner” that extrapolates predicted gains across model sizes and domains to stage expensive runs; combined with cost/carbon calculators for executive decisions
- Assumptions/Dependencies: law’s validity at larger scales and across domains; separate hyperparameter tuning may be required as models scale
- Bold: Safety, governance, and audit frameworks using gap-based guarantees
- Sectors: policy, standards, safety engineering
- Tools/Products/Workflows: certification checklists that require initial-gap reporting, predicted improvement ranges, and drift bounds before deployment; auditors verify realized gains match predicted bands
- Assumptions/Dependencies: community and regulator adoption; standardized measurement protocols and disclosures
- Bold: Consumer-facing “world-feedback” SDKs for personal agents
- Sectors: daily life, productivity apps
- Tools/Products/Workflows: SDKs that capture user corrections, error logs, and preferences to form privileged contexts; the app predicts when a quick adaptation session will materially improve the agent
- Assumptions/Dependencies: consented data collection, privacy-preserving on-device or federated fine-tuning, alignment to avoid undesirable behavioral drift
- Bold: Carbon-aware training schedulers informed by predicted ROI
- Sectors: energy, sustainability, policy
- Tools/Products/Workflows: schedulers that trigger OPSD only when the predicted improvement per kWh meets a threshold and low-carbon energy is available; reporting for ESG disclosures
- Assumptions/Dependencies: accurate energy metering; credible mapping from predicted gains to societal value; policy and market incentives to adopt carbon-aware practices
Cross-cutting dependencies and assumptions
- The predictive law was validated on coding tasks (LiveCodeBench v6) and specific model families (Qwen3, Olmo 3) under an OPSD recipe (reverse-KL, EMA teacher, non-thinking mode, 50 steps); other domains/models likely require calibration.
- High-quality, verifiable, tokenizable world feedback is critical; weak or noisy feedback may collapse the gap signal or mislead the self-teacher.
- Reporting discipline matters: use consistent validation splits and decoding parameters for computing the initial gap; version the fitted linear models used for prediction.
- Legal, privacy, and IP constraints govern feedback logging (e.g., code, clinical data, financial records); adopt compliant data pipelines.
- Very large models (e.g., ≥14B) may need recipe adjustments (learning rates, EMA rate, KL settings), and the linear slope/intercept can shift with hyperparameters.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient update to improve training stability. Example: "Optimizer & AdamW"
- Decoding parameters: The sampling settings used to generate model outputs (e.g., temperature, top-p), which can differ between training and validation. Example: "decoding parameters"
- Distillation top-k: Limiting supervision to the top-k teacher logits/tokens during distillation to reduce noise and compute. Example: "Distillation top-"
- Empirical scaling laws: Data-driven relationships describing how performance metrics scale with model size or compute. Example: "empirical scaling laws"
- Exponential moving average (EMA): A smoothed running average of model parameters used to form a more stable teacher. Example: "exponential moving average (EMA)"
- Exposure-bias gap: The mismatch caused by training on a different state distribution than is encountered at inference time. Example: "exposure-bias gap"
- Few-shot learning: Inducing task competence from a handful of in-context examples without parameter updates. Example: "few-shot learning"
- GRPO: A reinforcement learning approach used in LLM post-training; cited as a strong baseline method. Example: "GRPO"
- In-context learning: The model’s ability to adapt its behavior using information provided in the prompt/context without changing weights. Example: "in-context learning"
- KL divergence (reverse KL): A divergence measuring how one distribution differs from another; the reverse direction is often mode-seeking in distillation. Example: "reverse KL divergence"
- Leave-one-out cross-validation: A validation scheme where one configuration is held out to test a predictor trained on the rest. Example: "leave-one-out cross-validation"
- LiveCodeBench v6: A benchmark for evaluating coding performance of LLMs. Example: "LiveCodeBench v6"
- Logit-level credit assignment: Using token-level logits from a teacher signal to provide dense supervision instead of scalar rewards. Example: "logit-level credit assignment"
- mean@4: A pass-rate metric computed over four samples per problem. Example: "mean@4 pass rate"
- Nucleus sampling (Top-p): Sampling from the smallest set of tokens whose cumulative probability exceeds p. Example: "Top-"
- On-policy: Using data (trajectories/rollouts) generated by the current policy during training. Example: "on-policy"
- On-policy distillation (OPD): Distillation where the student learns from a teacher under the student’s own state distribution. Example: "on-policy distillation (OPD)"
- On-policy self-distillation (OPSD): Distilling from a self-teacher formed by conditioning the same model on privileged context. Example: "On-policy self-distillation (OPSD)"
- Ordinary least squares (OLS): A linear regression method that minimizes squared residuals. Example: "ordinary least squares (OLS)"
- Outcome-level rewards: Rewards assigned only based on final outcomes (e.g., success/failure) rather than intermediate steps. Example: "outcome-level rewards"
- Pearson correlation: A correlation coefficient measuring linear association between two variables. Example: "Pearson and Spearman correlations"
- Privileged context: Additional information available to the teacher but not the student, used to strengthen supervision. Example: "privileged context"
- Process reward model (PRM): A model that scores intermediate reasoning steps to provide fine-grained credit assignment. Example: "process reward models (PRMs)"
- Reinforcement learning with verifiable rewards (RLVR): RL post-training that uses programmatically verifiable signals to guide learning. Example: "Reinforcement learning with verifiable rewards (RLVR)"
- Retrieval-augmented generation (RAG): Enhancing generation by retrieving relevant external documents into the prompt. Example: "retrieval-augmented generation"
- Reverse-KL objective: Training objective that minimizes KL(student || teacher), typically encouraging the student to match teacher modes. Example: "reverse-KL objectives"
- RMSE (Root mean squared error): A measure of prediction error magnitude used to assess fit quality. Example: "RMSE"
- Rollout: A sampled trajectory/output produced by a policy for a given prompt. Example: "Rollouts per prompt ()"
- R2 (Coefficient of determination): A goodness-of-fit metric for regression indicating the fraction of variance explained. Example: "R2 = 0.949"
- Self-teacher: A teacher distribution formed by the same model as the student but conditioned on privileged context and often stabilized via EMA. Example: "self-teacher"
- Spearman correlation: A rank-based correlation measuring monotonic association between variables. Example: "Spearman correlations"
- stopgrad: An operator that prevents gradients from flowing through a computation path (e.g., the teacher). Example: "\mathrm{stopgrad}"
- Student policy: The current trainable policy being improved during post-training. Example: "student policy"
- Student–self-teacher gap: The performance difference between the student and its context-privileged self-teacher before training. Example: "studentâself-teacher gap"
- Temperature (sampling): A parameter that smooths or sharpens the output distribution during decoding. Example: "Temperature"
- Thinking mode: A decoding configuration where models produce explicit intermediate reasoning tokens or remain in non-thinking mode. Example: "Thinking mode"
- Tokenized feedback: Arbitrary textual/environmental feedback represented as tokens used to guide learning. Example: "tokenized feedback"
- Verifiable environments: Evaluation settings where solution correctness can be programmatically checked. Example: "verifiable environments"
- Weight decay: A regularization technique that penalizes large weights to reduce overfitting. Example: "Weight decay"
- World feedback: Rich, structured signals from the environment (e.g., unit tests, runtime errors) used to supervise learning. Example: "world feedback"
Collections
Sign up for free to add this paper to one or more collections.