Rectification Difficulty and Optimal Sample Allocation in LLM-Augmented Surveys
Published 19 Apr 2026 in cs.AI and stat.AP | (2604.17267v1)
Abstract: LLMs can generate synthetic survey responses at low cost, but their accuracy varies unpredictably across questions. We study the design problem of allocating a fixed budget of human respondents across estimation tasks when cheap LLM predictions are available for every task. Our framework combines three components. First, building on Prediction-Powered Inference, we characterize a question-specific rectification difficulty that governs how quickly the estimator's variance decreases with human sample size. Second, we derive a closed-form optimal allocation rule that directs more human labels to tasks where the LLM is least reliable. Third, since rectification difficulty depends on unobserved human responses for new surveys, we propose a meta-learning approach, trained on historical data, that predicts it for entirely new tasks without pilot data. The framework extends to general M-estimation, covering regression coefficients and multinomial logit partworths for conjoint analysis. We validate the framework on two datasets spanning different domains, question types, and LLMs, showing that our approach captures 61-79% of the theoretically attainable efficiency gains, achieving 11.4% and 10.5% MSE reductions without requiring any pilot human data for the target survey.
The paper introduces rectification difficulty, a key metric that quantifies post-rectification variance for combining biased LLM predictions with human labels.
It derives a closed-form allocation rule, prioritizing human responses based on meta-learned estimates, cost factors, and question importance.
The framework maintains statistical validity under meta-learner prediction errors, achieving substantial MSE reduction while ensuring robust inference.
Rectification Difficulty and Optimal Sample Allocation in LLM-Augmented Surveys
Problem Setting and Motivation
The integration of LLMs as synthetic survey respondents offers a compelling approach to reducing the cost and operational barriers associated with large-scale survey-based research. However, the reliability of LLM-generated responses varies sharply between questions due to differences in topic complexity, population diversity, and LLM biases. The central design problem addressed in "Rectification Difficulty and Optimal Sample Allocation in LLM-Augmented Surveys" (2604.17267) concerns how to optimally allocate a fixed human-labeling budget across survey questions when abundant, low-cost LLM predictions are available, but their quality is non-uniform and a priori unknown.
A key operational constraint is the ‘cold start’ project phase, in which no human data have been collected for the target survey, but paired historical human–LLM data from earlier studies are available. The authors' framework tackles both the statistical inference challenge (combining biased, variable-quality LLMs with gold-standard human labels) and the design challenge (allocating respondents across heterogeneous questions with unknown LLM reliability profiles).
Framework: Rectification Difficulty and Two-Stage Design
The paper develops a design and inference framework with three principal components:
Rectification Difficulty (Aq): For each question q, the authors define rectification difficulty, the post-rectification variance of the population after the optimally weighted combination of human labels and LLM predictions. Aq quantifies how well LLM responses can replace or augment human data after bias correction, controlling the asymptotic variance of the estimator.
Optimal Allocation Rule: Using the explicit variance scaling Aq/nq, where nq is the number of human responses for question q, the paper derives a sharp, closed-form allocation: nq⋆∝wqAq/cq, prioritizing human labels for questions where the LLM is least informative, optionally modulated by response costs (cq) and importance weights (wq).
Meta-Learning for Cold Start: Since true Aq values for new questions are unobservable before data collection, the framework uses a meta-learner trained on historical paired data to predict q0 from question features (primarily text embeddings). This enables zero-shot allocation without any pilot human data on new surveys.
After allocation and fielding, the final estimator for each question is the variance-minimizing PPI++ estimator with the tuning parameter q1 recalculated from the collected labeled data.
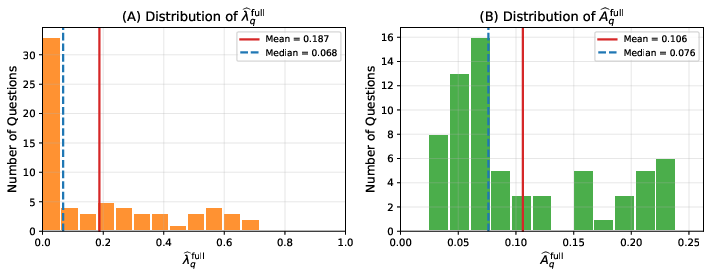
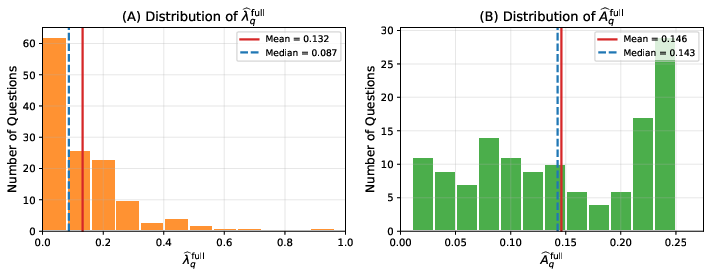
Figure 1: Distribution of full-sample (A) tuning parameter q2 and (B) rectification difficulty q3, revealing heterogeneity in LLM rectifiability across questions.
Theoretical Insights
The allocation rule generalizes classical Neyman allocation in stratified sampling to the hybrid human–LLM regime but leverages question-specific post-rectification variances rather than raw empirical variances.
The framework extends beyond simple means to general q4-estimators (e.g., regression coefficients, multinomial logit/partworths) by adopting an appropriate sandwich covariance.
Crucially, prediction errors in the meta-learner for q5 degrade design efficiency but do not compromise statistical validity: the PPI++ estimator remains consistent and asymptotically normal, preserving valid inference even under substantial meta-model miscalibration.
Empirical Results
The authors validate their approach on two benchmarks:
Twin-2K-500 (Behavioral Economics)
This dataset provides over 2,000 human respondents each answering 500+ diverse questions, with matched LLM “digital twin” responses. Key findings:
The dominant efficiency gains are due to optimal allocation, not merely applying PPI++: about three-quarters of the total MSE reduction stem from reallocating human effort across questions.
The meta-learner, using only historical data and question embeddings, captures 61–79% of the oracle allocation gain, yielding an 11.4% MSE reduction—translating to a significant reduction in label cost required to achieve baseline precision.
The allocation effect is robust to wave-level dependencies and increases with heterogeneity in rectification difficulty.
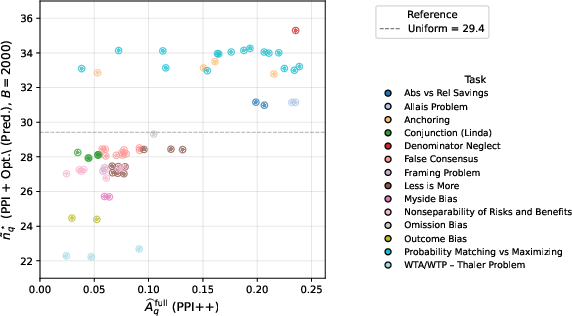
Figure 2: Per-question predicted allocation at q6 versus full-sample rectification difficulty q7, showing concentration of human effort on difficult items.
Figure 3: Distribution of full-sample (A) tuning parameter q8—a mass at zero shows many questions where LLMs provide no usable signal.
Cooperative Election Study (CCES 2024; Politics)
In this large-scale, demographically diverse survey using a different LLM (Gemini 2.5 Flash):
Heterogeneity in rectification difficulty across questions is even larger, driven by the coexistence of factual questions (where LLMs excel) and highly polarized policy items (where they fail).
The oracle allocation yields a 17.1% MSE reduction. The meta-learned allocation, despite less accurate difficulty prediction than in the behavioral domain, still achieves 10.5% MSE reduction—about 61% of the maximal potential gain.
Even when meta-learned prediction of q9 is imperfect, most of the benefit is retained due to the allocation rule’s robustness to relative ordering errors (as shown in Proposition 3 of the Appendix).
Additional Diagnostics
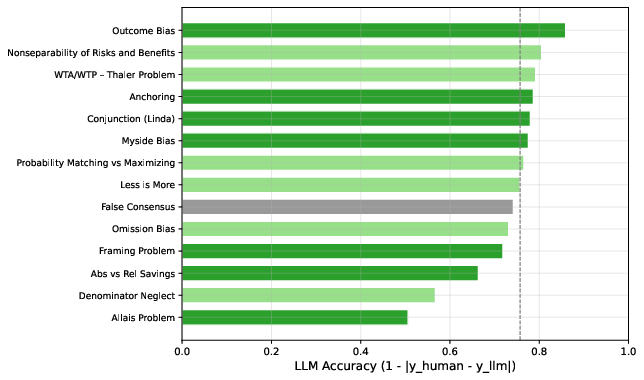
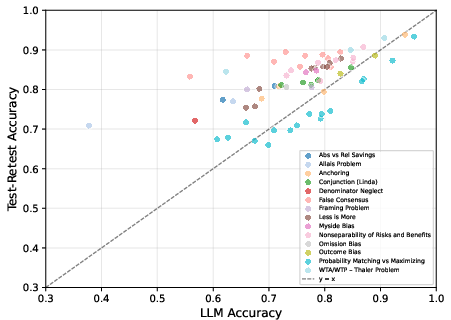
Human test–retest reliabilities are strongly correlated with rectification difficulty, confirming that ambiguous survey items are problematic for both LLMs and humans.
Figure 5: Human test–retest accuracy versus LLM accuracy for 68 questions; problematic items are difficult for both.
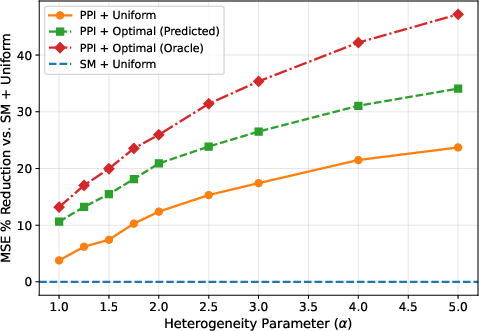
Figure 6: MSE percent reduction versus simulated rectification difficulty dispersion parameter Aq1 under different allocation policies.
Practical and Theoretical Implications
Practical
The framework provides practitioners with a workflow for reallocating respondents—ex ante and before pilot data acquisition—by leveraging embeddings and prior data, delivering substantial savings in human-data costs.
The benefits increase as survey question heterogeneity widens (e.g., when mixing subjective and objective items).
Validity of inference does not depend on meta-model calibration; thus, efficiency can be increased safely without risk to correctness.
Theoretical
The formalization of rectification difficulty as the appropriate design statistic for PPI-style hybrid inference generalizes several prior methods and provides a modular plug-in for broader ‘prediction-powered’ statistical designs.
The compatibility with power analysis, alternative loss metrics (including cube-root allocation for MAE), and matrix-sampling extensions makes the framework broadly applicable across experimental design in the presence of synthetic observations.
Future Research Directions
Incorporate adaptive designs where meta-learned allocation is updated as pilot labels accrue.
Extend meta-learning to explicitly model LLM–domain shift, developing models that handle transfer across new LLM variants and under covariate shift.
Combine domain-specific LLM fine-tuning with rectification-based allocation to reduce rectification difficulty [cf. (2511.19486)].
Conclusion
This paper advances LLM-augmented survey methodology by connecting modern prediction-powered estimators with principled optimal allocation, mediated by a new design-directed concept of rectification difficulty. Its robust two-stage solution—meta-learned zero-shot allocation followed by bias-corrected estimation—enables efficient, resilient survey designs applicable across diverse empirical contexts. The empirical evidence suggests substantial cost–precision tradeoff improvements are attainable even when explicit pilot data are unavailable, with greater efficiency as the degree of between-question LLM reliability heterogeneity increases.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.