- The paper introduces CoP, a physics-grounded tactile representation that improves sim-to-real transfer by encoding both force and contact location.
- It leverages a differentiable sensor calibration method to align simulation signals with real-world hardware for robust policy learning.
- Experiments demonstrate that CoP-based policies outperform raw tactile baselines in challenging tasks like peg-in-hole insertion and ball balancing.
Introduction and Motivation
Dexterous, contact-rich manipulation remains a foremost challenge in robotics, primarily due to the difficulties of gathering real-world tactile data at scale. Simulation-to-reality (sim-to-real) reinforcement learning (RL) is a promising paradigm, but the sim-real gap, especially for high-dimensional tactile sensing, impedes the transferability of rich touch-based policies. Previous approaches typically either simplify tactile signals into binary or coarse features, sacrificing representational expressivity, or attempt to use raw sensor outputs, incurring misalignment and lack of robustness across simulator and hardware.
This work introduces "Center-of-Pressure" (CoP), a physics-grounded tactile representation—a compact yet expressive fusion of force magnitude and contact location—that balances sim-to-real alignment with the necessary information density for precise manipulation. Coupled with a differentiable sensor calibration method to estimate taxel orientations absent ground-truth force measurements, CoP enables robust policy learning and zero-shot sim-to-real transfer in two blind manipulation tasks: peg-in-hole insertion and ball balancing.
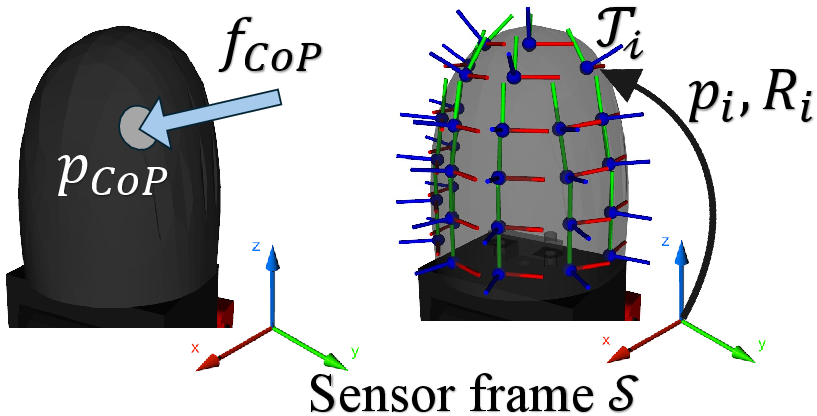
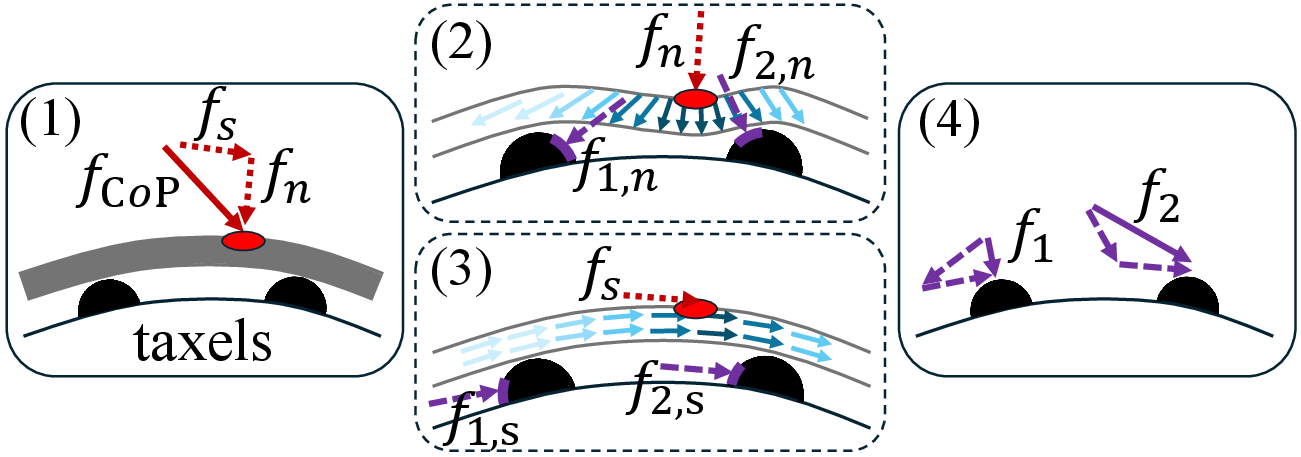
Figure 1: CoP comprises a 3D contact force vector and contact point within the sensor frame; mappings align taxel array signals with compact contact descriptors.
Methodology
CoP summarizes tactile information as a 3D force vector and contact point—grounded in rigid-body physical principles—striking a balance between transferability and informativeness. The authors develop a differentiable mapping between the N-taxel sensor array (force readings per taxel) and the CoP descriptor via a stress-distribution model incorporating normal and shear forces and accounting for silicone layer deformation. Mapping avoids naive aggregation, instead blending taxel normals with distance vectors via Gaussian weighting, and projects shear forces onto the tangent plane, maintaining differentiability and computational efficiency.
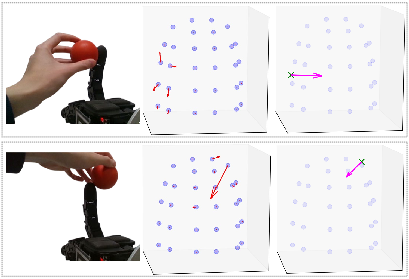
Figure 2: Two hardware examples visualizing CoP force vectors and contact positions computed from raw taxel readings.
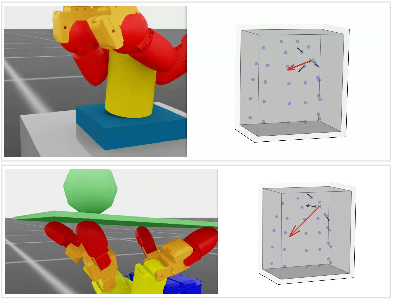
Figure 3: Simulator-derived CoP contacts are mapped to taxel force vectors in the insertion and ball-balancing tasks, filtered by sensor regions.
Closed-form solutions for CoP inference use regularized least-squares minimization, allowing gradient-based alignment across simulation and hardware.
Differentiable Sensor Calibration
Taxel orientations are difficult to calibrate due to the complex geometry of fingertips. The proposed method leverages differentiable dynamics, matching externally inferred wrench signals from tactile readings with measured joint torques under static equilibrium, optimizing rotation parameters via SVD-projected matrices with backpropagation. This approach bypasses expensive ground-truth force sensors, relying instead on internal kinematics and recorded contact responses.

Figure 4: Actuator dynamics alignment via iterative probing with structured trajectories, bridging the sim-real gap in control responses.
Sim-Real Alignment and Policy Architecture
The CoP mapping, calibrated with paired rollout data, ensures consistent contact representations across simulation and real-world deployments. Actuator parameter identification employs Bayesian optimization for dynamic response tuning. Sensor delay is measured and injected during simulation training for robustness.
Policy architecture comparisons reveal that recurrent networks (GRU-based) outperform history-stacked MLPs, achieving superior sample efficiency and learning quality without increasing input dimensionality.
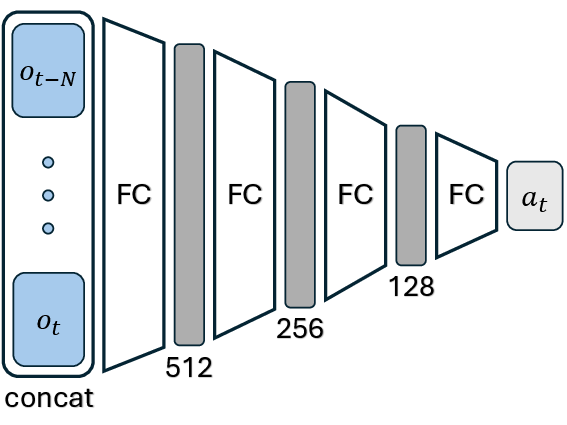
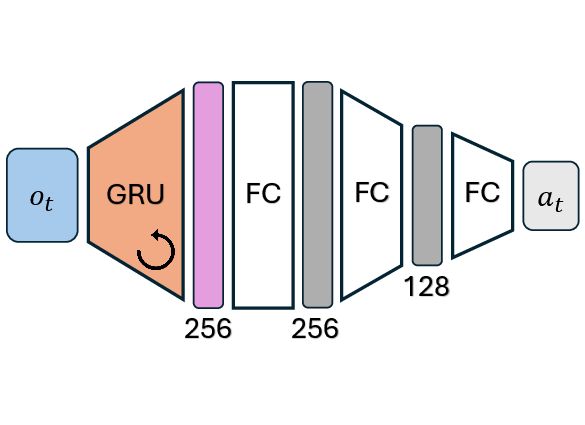
Figure 5: Illustration of temporal context strategies—MLP with stacked observations versus recurrent networks with hidden state fusion.
Experimental Evaluation
Tasks and Baselines
Experiments are conducted on two challenging manipulation tasks using a 16-DOF Allegro hand equipped with XELA uSkin sensors:
- Peg-in-hole insertion with various shaped pegs requiring grasp and adaptive alignment (circle, diamond, ellipse, hexagon, square, triangle).
- Ball balancing on a supported plate, maintaining centrality across diverse balls with varying mass, friction, and surface texture.
Baselines include proprioception-only, binary contact, force magnitude, force vector-only, contact position-only, raw taxel readings, and expert human performance.



Figure 6: Custom assets for the peg-in-hole and ball-balancing tasks, facilitating diverse contact-rich evaluation conditions.
Peg-in-Hole Insertion
CoP-conditioned policies achieve the highest overall success rate (0.78) across shapes, with superior robustness under out-of-distribution initializations and masked sensor signals. Force-only and position-only ablations demonstrate that both components are necessary for optimal performance. Raw taxel baselines performed worse, corroborating the view that sensor-specific raw signals are difficult to align and less effective for transfer unless paired with advanced calibration or encoding. Human performance remains a strong outlier, highlighting the gap attributable to additional cognitive reasoning.
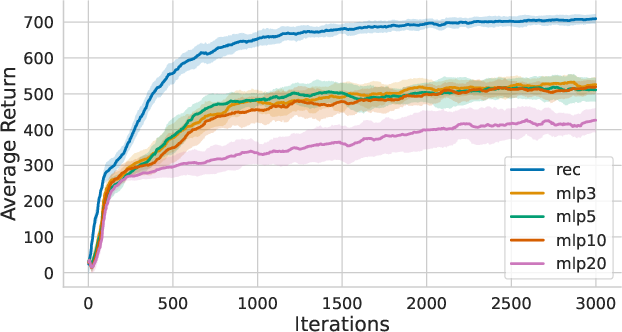
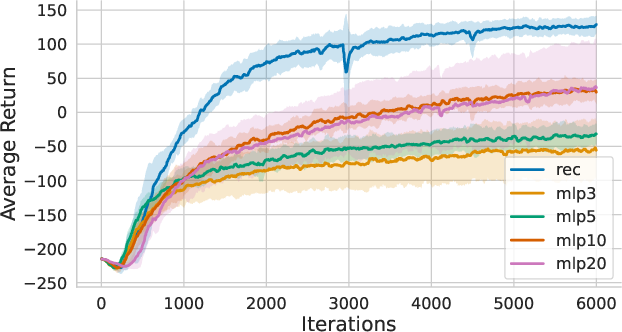
Figure 7: Visual depiction of successful and failed peg-in-hole rollouts—CoP policy adapts under OOD conditions, binary-contact policy lacks recovery.
Ball Balancing
Only CoP, force vector, and taxel-based policies succeeded in learning the dynamic balancing task, with CoP and force vector policies yielding comparable time-to-fall metrics, and other baselines failing to maintain the ball. The robot policy exhibits distinct emergent movement patterns for ball centering, but human prediction and control agility still outperform policies, especially with objects exhibiting nonlinear rolling.

Figure 8: Emergent cop policy movement patterns in ball-centering—accelerate, decelerate, stabilize—reflecting fine control dynamics.
Latent State Analysis
Linear probing and PCA on recurrent policy latents reveal that CoP-based policies implicitly encode task-relevant physical properties, such as ball mass and position. Clustering analysis demonstrates that policies adapt latent embeddings to organize around dynamical parameters, despite these properties being unsupervised.
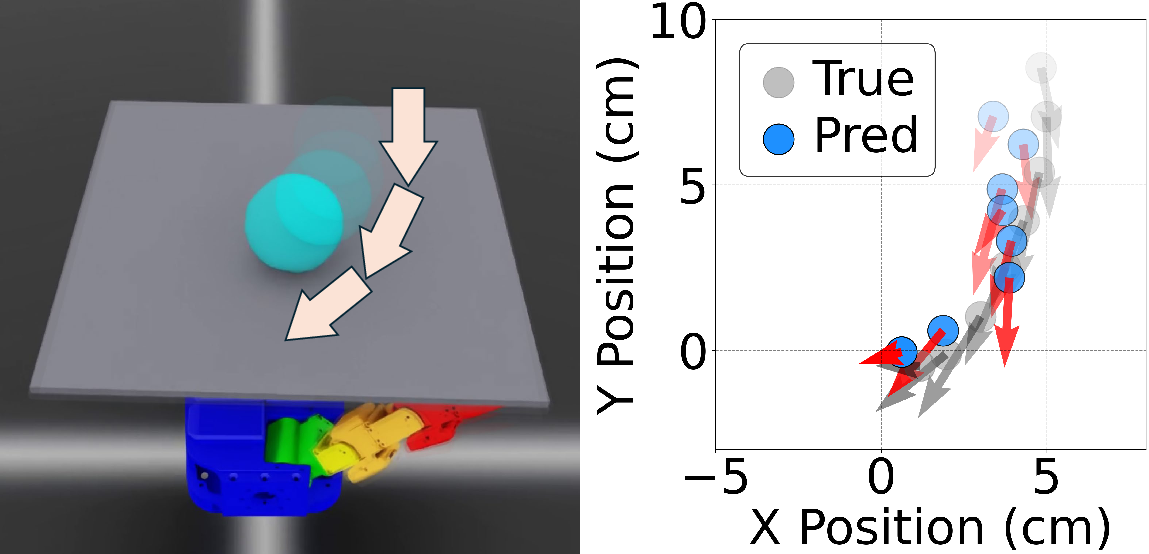
Figure 9: Policy latent predictions closely track ball position, but velocity prediction is degraded due to tactile-based estimation noise.

Figure 10: Latent embedding clusters correlate with object mass as trajectories evolve, evidencing emergent identification abilities.
Implications and Future Directions
The CoP representation substantively advances the sim-to-real paradigm for contact-rich manipulation, offering a compact, physically meaningful descriptor that retains sufficient fidelity for complex policy learning and transfer. Policy architectures leveraging CoP exhibit emergent inference of object dynamics without explicit supervision—a trait valuable for scalable, generalizable robotic manipulation. The methodology obviates the need for expensive force sensors in calibration and bypasses teacher-student distillation paradigms by aligning sensor contact representations directly.
Remaining limitations include loss of sensor-specific detail, restriction to normal force components, and limited sensor types. Extension to arm-hand systems, full-hand tactile coverage, and richer raw tactile mapping remains open. The approach has potential spillover into sample-efficient RL and vision-tactile fusion in imitation learning.
Conclusion
Center-of-Pressure (CoP) contact representation presents an effective, physics-grounded solution for sim-to-real transfer in dexterous manipulation, achieving robust learning and transfer across blind, contact-rich tasks. Its differentiable calibration and alignment with simulation dimensions empower emergent identification and control strategies. The results underscore the promise of physically grounded tactile abstraction in scalable robot learning and suggest fertile ground for future multimodal, sensor-general extensions.