- The paper introduces COSE, a framework that scales the impact of self-generated feedback using intrinsic confidence scores derived from token-level entropy.
- It employs a four-role architecture (Proposer, Validator, Solver, Judge) to filter and prioritize feedback, ensuring reliable policy optimization via confidence-weighted PPO.
- Experiments show that COSE enhances stability and performance across reasoning, mathematics, and code generation tasks, particularly for weaker model backbones.
Confidence-Orchestrated Self-Evolution: A Confidence-Modulated Framework for Self-Evolving LLMs
Self-evolving LLMs automate supervision by generating their own tasks and feedback, removing the dependency on expensive human annotation in reasoning, mathematics, and code. However, as shown in "Confidence-Orchestrated Self-Evolution against Uncertain LLM Feedback" (2605.28010), a critical bottleneck for such approaches is the reliance on noisy model-generated feedback; validators and judges (implemented as LLM-in-the-loop modules) are imperfect, especially on challenging reasoning tasks. Erroneous self-judgments translate into erroneous gradient updates, leading to policy drift and amplification of flawed behaviors throughout sequential self-evolution. Traditional self-evolution protocols—such as MAE and R-Zero—use LLM feedback at face value, treating all accepted feedback as equally reliable, which is suboptimal when the feedback is both noisy and hard to certify.
The COSE Framework
COSE introduces a confidence-aware mechanism that modulates the impact of self-generated feedback according to the LLM's intrinsic confidence score computed from token-level entropy statistics. The system orchestrates four roles using a shared backbone LLM: Proposer, Validator, Solver, and Judge.

Figure 1: The COSE architecture prompts a single LLM πθ to act as Proposer, Validator, Solver, and Judge, integrating confidence signals at the Validator and Judge stages to regulate training via confidence-weighted PPO and prioritized replay.
- The Proposer synthesizes candidate questions, which are scored and filtered by the Validator.
- Filtered questions are added to a replay buffer and sampled for solving.
- The Solver generates answers to these questions, and the Judge rates correctness.
- Validator and Judge supply both a normalized quality/correctness score and a sequence-level confidence estimate c (derived by aggregating normalized per-token entropy over the output).
COSE's central principle is that feedback with higher intrinsic confidence receives proportionally more influence in policy optimization; low-confidence feedback has its gradient scaled down, mitigating amplification of errors due to judge/validator mistakes.
Confidence Estimation and Training Control
Confidence is estimated using normalized entropy over the validation/judge token distributions. For a prediction at token t with softmax output Pt over vocabulary V, token confidence is:
ct=1−log∣V∣H(Pt)
Sequence-level confidence cseq is the average over tokens. This approach is robust to calibration defects and agnostic to the judge's accuracy, providing an intrinsic uncertainty signal widely studied in model selectivity and sample trustworthiness.
During training:
Experimental Results
COSE is benchmarked across 19 held-out datasets including MMLU, GPQA, BBH, ARC-Challenge, GSM8K, MATH, Minerva, Olympiad-Bench, and code generation suites. Evaluation spans four model scales (Qwen/LLama backbones, 0.6B–4B parameters).
General Reasoning: On all four model scales, COSE yields the highest average score on general reasoning, with especially pronounced gains on smaller/weaker backbones—where naive self-evolution quickly amplifies errors due to noisy validators/judges. Gains persist, albeit reduced, even in saturated large-model regimes.
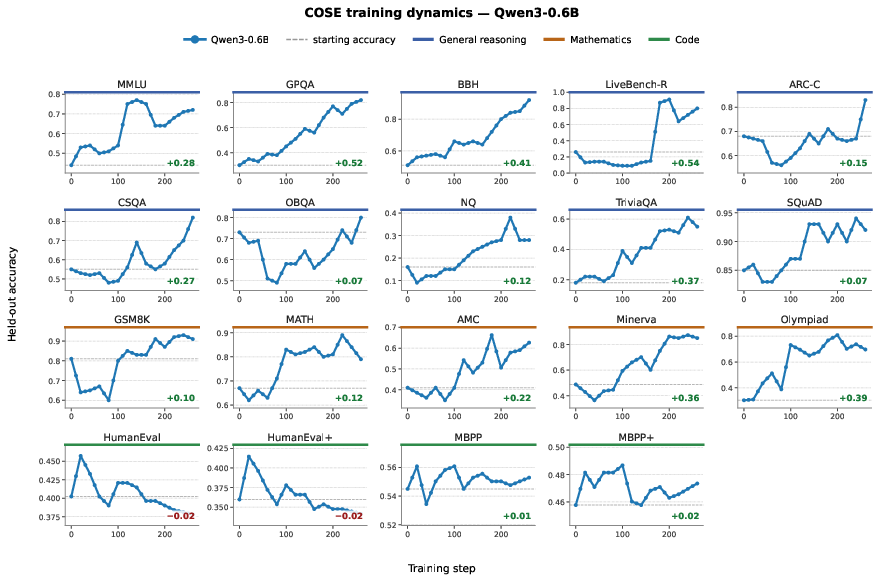
Figure 3: Training dynamics on Qwen3-0.6B: confidence control yields monotonic or plateaued performance, highlighting enhanced stability compared to standard self-evolution.
Mathematical Reasoning: COSE outperforms all baselines with significant deltas on challenging math benchmarks, particularly for less capable backbones. On GSM8K, MATH, and Olympiad-Bench, the margin over MAE/R-Zero is largest precisely where judge reliability is lowest. Notably, for "hard" problems with high judge uncertainty, COSE's advantage widens, confirming that per-sample noise control is essential for stable self-evolution.
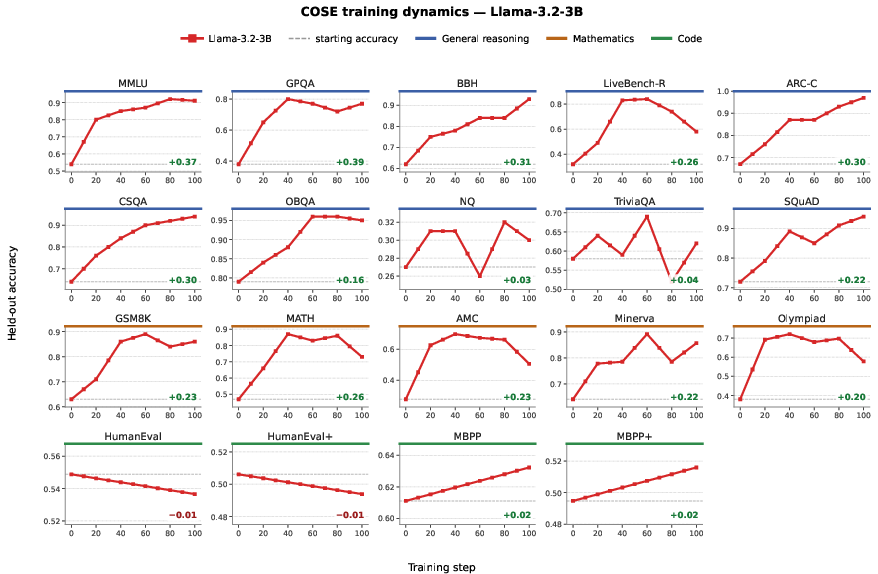
Figure 4: Llama-3.2-3B per-benchmark curves demonstrate that COSE stabilizes training even in the presence of protocol-induced oscillations and bottlenecks from highly noisy feedback.
Code Generation: On execution-verifiable code tasks, where AZR and similar methods have access to precise reward signals, COSE retains competitive performance and never regresses substantially. This confirms that confidence modulation does not harm performance in domains with high-fidelity reward signals.
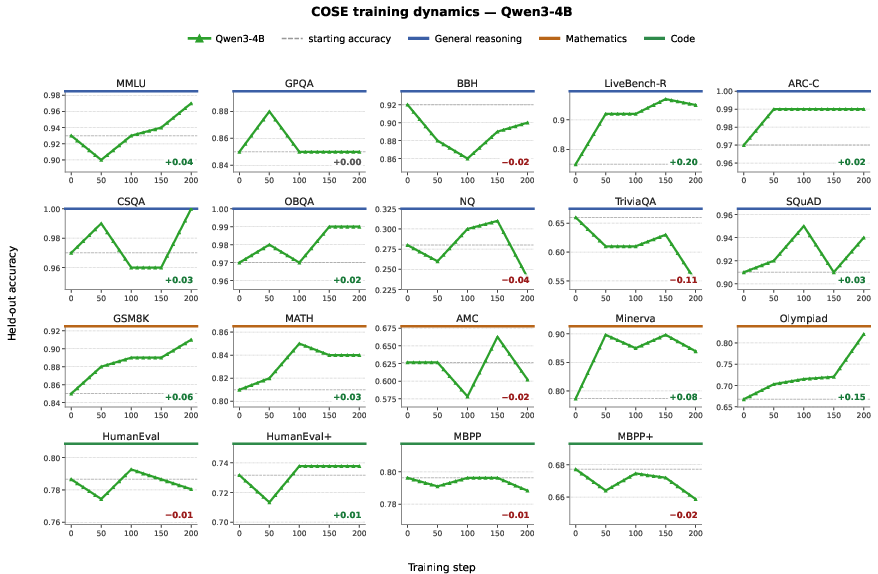
Figure 5: Qwen3-4B per-benchmark results illustrate that on saturated tasks, COSE does not cause regressions and maintains incremental gains on reasoning benchmarks with sustained judge noise.
Ablation and Hyperparameter Analysis
Disabling confidence-weighted updates causes large and systematic drops on math/logic tasks, especially for weaker models. Replay priority also contributes, but less so than per-sample gradient modulation. Batch size and choice of confidence estimator (entropy, margin, logit) yield only secondary effects, confirming the generality of the framework.
Implications and Theoretical Significance
COSE addresses a fundamental limitation of naive self-evolution: the unmoderated amplification of model biases and feedback failures via trust in self-generated supervision. By integrating confidence-based weighting, COSE provides a robust mechanism to dampen policy shifts due to unreliable self-feedback—especially crucial outside domains with programmatic or executable verifiers.
Practically, this enables more aggressive use of self-evolving frameworks in reasoning and mathematics, extending the feasible benchmarking zone beyond code and retrieval. The mechanism is agnostic to backbone, scalable to larger models, and, as shown, compatible with reinforcement learning control variants such as PPO. The comprehensive experiments articulate that the value of trust control over feedback scales with both the difficulty of the learning domain and the model's own accuracy regime.
Theoretically, COSE's approach suggests a pathway where confidence measurements (even when not perfectly calibrated) may serve as an effective form of intrinsic reward shaping or per-example trust control, complementing broader research on selective prediction and LLM self-verification (cf. [geng2024survey], [stechly2024selfverification]).
Limitations and Future Directions
Confidence is a heuristic, not a guarantee: high-confidence LLM feedback can still be incorrect, especially in adversarial or OOD cases. COSE thus does not replace the need for external, human, or environment-based verification, particularly in high-stakes or safety-critical domains. Further, COSE assumes access to token-level logits or probability distributions; for true API-black-box LLMs, alternative (possibly weaker) confidence proxies are needed.
Application to larger, highly capable backbones—and systematic study of behaviors under extreme curriculum drift or over long self-evolution training horizons—remains an open area. Combining COSE with stronger, possibly external, measures of semantic uncertainty or error detection is a natural extension.
Conclusion
COSE advances self-evolving LLM training by formalizing confidence-based trust control in the face of uncertain model-generated feedback. It consistently raises reasoning and mathematics benchmark performance while preserving stability in executable verification regimes. The approach is well-supported by quantitative improvements in weak-to-moderate backbones and demonstrates robustness across experiment settings. COSE sets the stage for future research on more nuanced signals for feedback reliability, integration with external verifiers, and deployment in open-domain, real-world self-improving AI systems.
Reference: "Confidence-Orchestrated Self-Evolution against Uncertain LLM Feedback" (2605.28010)
