- The paper introduces ConSelf, a novel method that uses semantic entropy for curriculum curation in code generation.
- It employs diverse observation-guided sampling and filters noisy data via execution trace clustering to select challenging tasks.
- Consensus-driven DPO stabilizes training by optimally weighting preference signals, yielding improvements of 2.7–4% pass@1 on benchmarks.
Self-Improving Code Generation via Semantic Entropy and Behavioral Consensus
Problem Setting and Motivation
The central focus of "Self-Improving Code Generation via Semantic Entropy and Behavioral Consensus" (2603.29292) is to address self-improvement in code generation LLMs without reliance on teacher models, reference solutions, or test oracles. The lack of these supervision signals, especially reliable test oracles, poses a significant bottleneck for scaling and democratizing code LLM alignment. The authors formalize a scenario where only problem descriptions and test inputs are available, which closely mirrors practical constraints prevalent in industrial and scientific settings.
The core challenge is the presence of "noisy data": for certain intractable or unsolved problems, all self-generated code samples may be flawed in diverse ways, providing no meaningful gradient for SFT or preference-based learning (DPO). Without rigorous filtration, iterative self-improvement can lead to performance collapse due to the reinforcement of spurious behaviors and catastrophic forgetting.
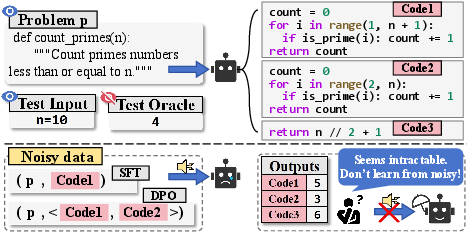
Figure 1: Learning from noisy data on intractable problems renders self-optimization futile and motivates robust problem filtering.
ConSelf: High-Level Methodology
To address the dual questions of what to learn (curriculum curation) and how to learn (robust self-alignment), the paper introduces ConSelf—a procedure grounded in execution-based uncertainty and consensus-aware preference optimization. The pipeline comprises three key steps:
- Observation-guided sampling: To induce functionally diverse candidate pools, the model first generates multiple textual "observations" and then conditions code synthesis on each.
- Code semantic entropy-based filtering: For each problem, the functional diversity among candidate code is quantified via a new entropy metric computed over execution traces; only problems with moderate (non-zero, sub-threshold) semantic entropy are retained.
- Consensus-driven DPO (Con-DPO): Preference pairs are extracted using behavioral consensus scores, and the DPO loss is adaptively weighted by consensus to mitigate noise in label construction.

Figure 2: ConSelf workflow: observation-guided sampling, code semantic entropy-based problem selection, and consensus-driven preference optimization.
Observation-Guided Sampling
The candidate code pool's diversity directly impacts the informativeness of preference datasets. Inspired by search-based code generation, the paper employs sequential prompting: first generating diverse planning statements (observations), then using each to condition code synthesis.
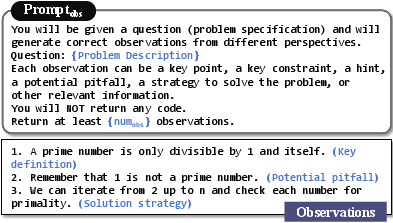
Figure 3: Example prompt template for generating observations, promoting diverse solution strategies.
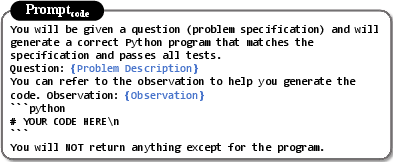
Figure 4: Code generation is conditioned on sampled observations to maximize candidate diversity.
Curriculum Curation via Code Semantic Entropy
A key technical innovation is the introduction of code semantic entropy as a problem-level uncertainty estimator. Unlike internal metrics (token entropy, log-likelihood) or textual clustering approaches, code semantic entropy is calculated by clustering candidate programs according to their execution traces on a common test input set. The method captures true epistemic uncertainty, as high-entropy tasks are those where self-sampled solutions fragment into many distinct, functionally incompatible clusters.
Problems with excessive entropy (high semantic disagreement) are filtered out, as are those with zero entropy (already mastered or universally failed). Curriculum curation thus targets tasks providing maximal reliable learning signal under current model capacity.
Consensus-Driven Preference Optimization (Con-DPO)
Standard DPO assumes ground-truth preference pairs; in a fully self-supervised context, preference noise is inevitable. The authors introduce a consensus score, computed for each candidate as the proportion of test cases where its output matches the majority behavior. Preference pairs are drawn from high- versus low-consensus candidates, and the DPO loss is weighted by the winner's consensus—ensuring preferential learning from reliable pseudo-labels and downweighting ambiguous or outlier pairs.
Empirical Results
Strong empirical results are demonstrated across CodeLlama-7B, DeepSeek-Coder-6.7B, and Qwen2.5-Coder-7B on HumanEval, MBPP, EvalPlus, and LiveCodeBench benchmarks. ConSelf yields consistent average relative improvements between 2.7–4% pass@1, outperforming both unsupervised SFT and previous preference-based methods. Notably, comparable baselines often cause regression if unfiltered, highlighting that indiscriminate self-supervised learning is counterproductive.
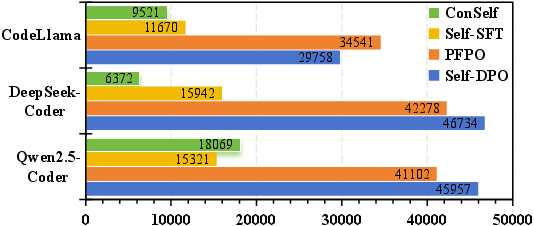
Figure 5: ConSelf uses substantially fewer training pairs than unfiltered baselines, achieving higher quality at reduced compute cost.
Explicit analysis reveals that code semantic entropy is far more correlated with true pass rates and solvability than standard uncertainty metrics. It is the only metric to robustly delineate between "solvable" and "unsolvable" tasks (AUC near 0.8), yielding maximal signal for data curation.
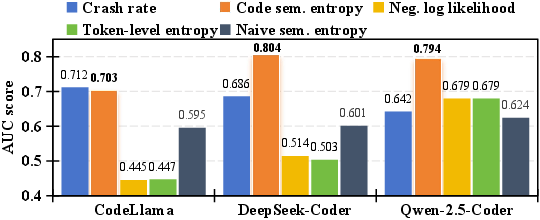
Figure 6: AUC scores for various metrics; code semantic entropy displays consistently higher discrimination between solvable and unsolvable tasks.
Curriculum ablations prove that the major contribution arises from semantic entropy-based filtering (responsible for most of the performance delta). Con-DPO provides further gains by controlling residual noise via consensus weighting. Performance peaks at an intermediate entropy threshold, revealing a principled trade-off between data quality and curriculum diversity.
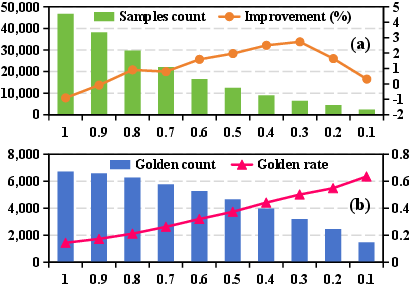
Figure 7: As filtering tightens, golden preference rates rise but the number of effective training samples drops; performance is maximized at moderate threshold settings.
Theoretical and Practical Implications
The research clarifies that functional execution-based metrics—rather than internal confidence—are essential for dependable self-improvement in code generation LLMs. The curriculum design formalized here provides actionable guidelines for data selection in large-scale self-alignment pipelines, particularly for open models where oracles and teacher outputs cannot be assumed. The Con-DPO framework's explicit consensus weighting addresses the well-known issue of preference noise in alignment without costly human curation or external models.
Practically, such an approach enables scalable, low-supervision tuning of foundation code models in specialized domains or contexts with limited resources. The approach is model-agnostic and readily integrates with LoRA-style adaptation, making it tractable at scale for open-source releases.
Future Directions
Highlighted avenues for expansion include:
- Extending behavioral consensus to RL pipelines or settings with limited interactivity.
- Employing fine-grained functional equivalence detection to further improve semantic clustering.
- Investigating the interaction between curriculum entropy and emergent LLM capabilities on hard combinatorial code tasks.
- Exploring guardrails against reward hacking or "self-consistency collapse" in open-ended code generation.
Conclusion
The paper presents a rigorous, execution-grounded framework for self-improving code generation. By combining code semantic entropy-driven curriculum construction with consensus-weighted preference optimization, ConSelf achieves data-efficient and reliable LLM self-alignment in the absence of external supervision. The introduced metrics and algorithms have direct implications for scaling high-quality, open code LLMs and reframe the standards for uncertainty quantification and preference learning in code synthesis.