Understanding and Mitigating Premature Confidence for Better LLM Reasoning
Abstract: Long chains of thought (CoT) from current LLMs frequently contain logical gaps and unjustified leaps, limiting the gains from additional test-time compute. Improving reasoning quality directly would require process reward models, but the step-level annotations needed to train them are expensive and scarce. We find such a signal in how the model's confidence evolves during reasoning: premature confidence, the tendency to commit to an answer early and use the remaining tokens to rationalize it, strongly predicts flawed reasoning across tasks and model scales. We exploit this in progressive confidence shaping, a reinforcement learning objective that trains models to update their confidence as they reason rather than commit early -- rewarding gradual confidence growth and penalizing early commitment, with no external labels or reward models. The method improves accuracy and reasoning quality from 1.5B to 8B parameters across arithmetic (Countdown), math (DAPO, AIME), and science (ScienceQA): on Countdown, accuracy improves 3.2x (+42.0pp) and flawed reasoning drops 48pp; on AIME, Pass@64 improves 6.6pp. Consistent with this mechanism, the method also improves faithfulness: on a safety benchmark, our models more transparently surface misleading content in their reasoning traces rather than concealing it. Controlled experiments reveal that the problem and its remedy scale together: premature confidence grows with model size and task difficulty, and so do the gains from addressing it.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
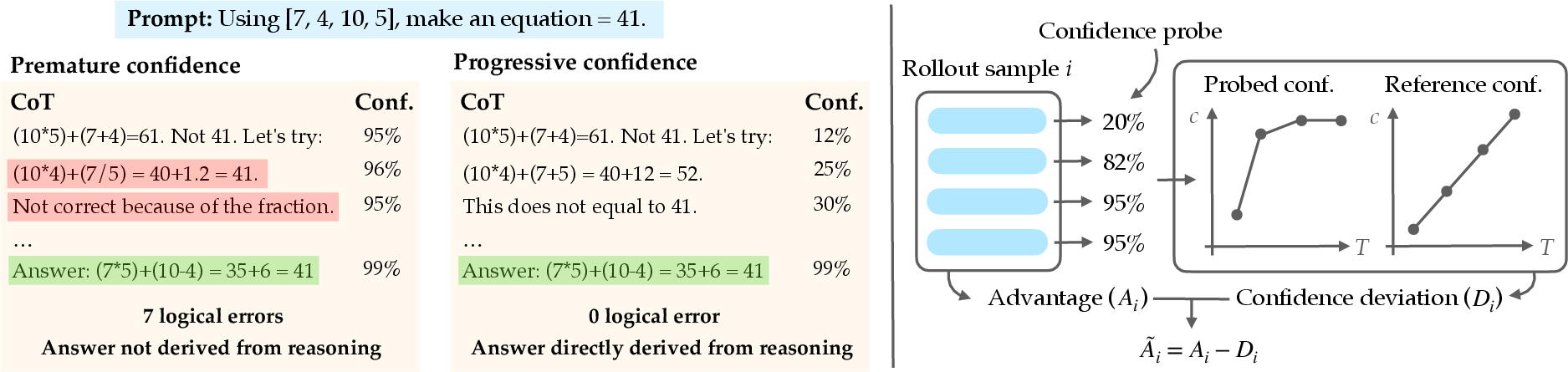
This paper looks at a common problem in how AI LLMs “show their work.” When asked hard questions, models often write long chains of steps (called chain-of-thought, or CoT). But many times, the model actually decides on the final answer very early, then spends the rest of the steps justifying that choice. The authors call this premature confidence. It leads to shaky or wrong reasoning, and it makes the model’s explanation less honest about how it really decided.
The paper shows how to measure premature confidence, proves it predicts flawed reasoning, and introduces a training method that encourages models to build confidence gradually as they reason. This makes answers more accurate and explanations more trustworthy.
Key Questions
The authors set out to answer a few simple questions:
- How can we tell if a model is jumping to conclusions instead of genuinely reasoning step by step?
- Does early commitment (premature confidence) actually predict bad or dishonest reasoning?
- Can we train models to avoid premature confidence, without needing expensive human labels for every step?
- When does this training help the most (e.g., on harder problems or bigger models)?
How They Did It (Methods in Plain Language)
Think of a student solving a math problem. If the student guesses the answer first and then writes steps to match that guess, the “work” isn’t real reasoning. The authors check models for this by using two main tools:
- Measuring the model’s confidence over time
- Idea: While the model is writing its chain-of-thought, pause it at several checkpoints (like 0%, 20%, 40%, …, 100% of its explanation).
- At each pause, ask: “What’s your final answer right now?”
- If the model already gives the same final answer from the very beginning and never changes, its confidence is high too early — that’s premature confidence.
- If the model’s answers start uncertain and become more consistent only near the end, confidence is growing gradually — that’s progressive confidence.
- Checking the reasoning for flaws
- The authors use another strong model as a “monitor” to read the explanation and flag issues, such as:
- Misreading the question
- Ignoring important evidence
- Claiming a conclusion without support
- Contradicting itself
- Reaching a final answer that doesn’t match its own reasoning steps
- This lets them see whether premature confidence really lines up with bad reasoning.
- Teaching the model better habits with reinforcement learning (RL)
- Reinforcement learning is like coaching: the model tries, gets a score (reward), and then updates to do better next time.
- Usual RL only rewards the final answer. That can accidentally encourage guessing and backfilling.
- The authors add a new reward signal called progressive confidence shaping:
- They reward explanations where confidence grows gradually (like a student discovering the answer through steps).
- They penalize explanations where the model commits too early (like a student writing the answer then forcing the steps to fit).
- Importantly, this needs no extra human labels. The model’s own behavior (its confidence at checkpoints) is enough to shape learning.
Main Findings and Why They Matter
Here are the most important results:
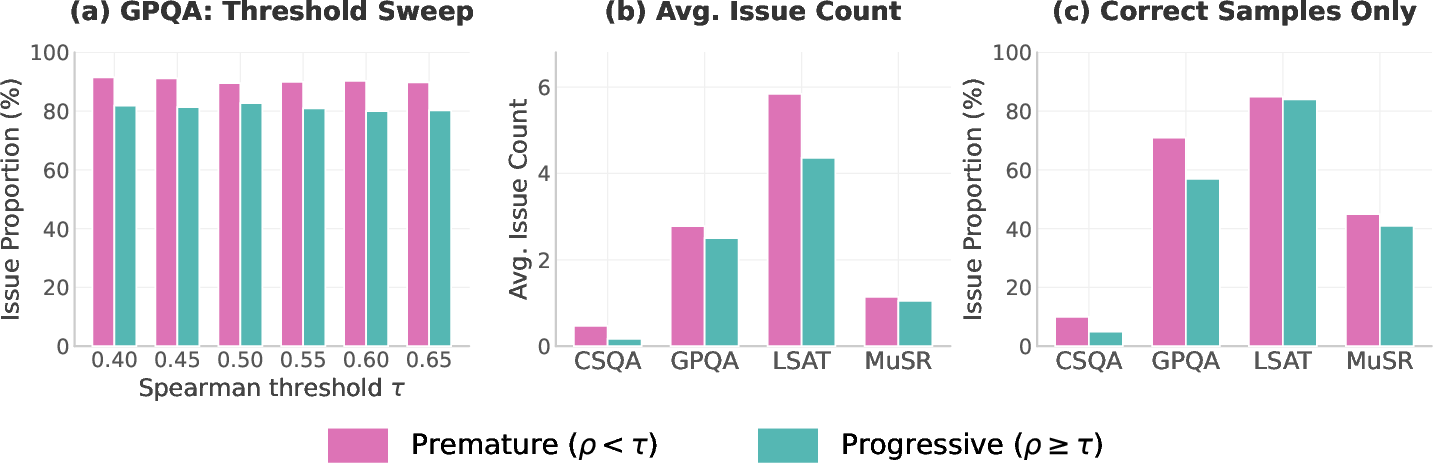
- Premature confidence strongly predicts flawed reasoning
- Across several benchmarks (commonsense, science, legal, multi-step puzzles), explanations with early, flat confidence contained many more logic problems than explanations where confidence grew slowly.
- The most common failure was “wrong conclusion”: the final answer didn’t actually follow from the model’s own steps. This is exactly what you’d expect if the model decided first and reasoned later.
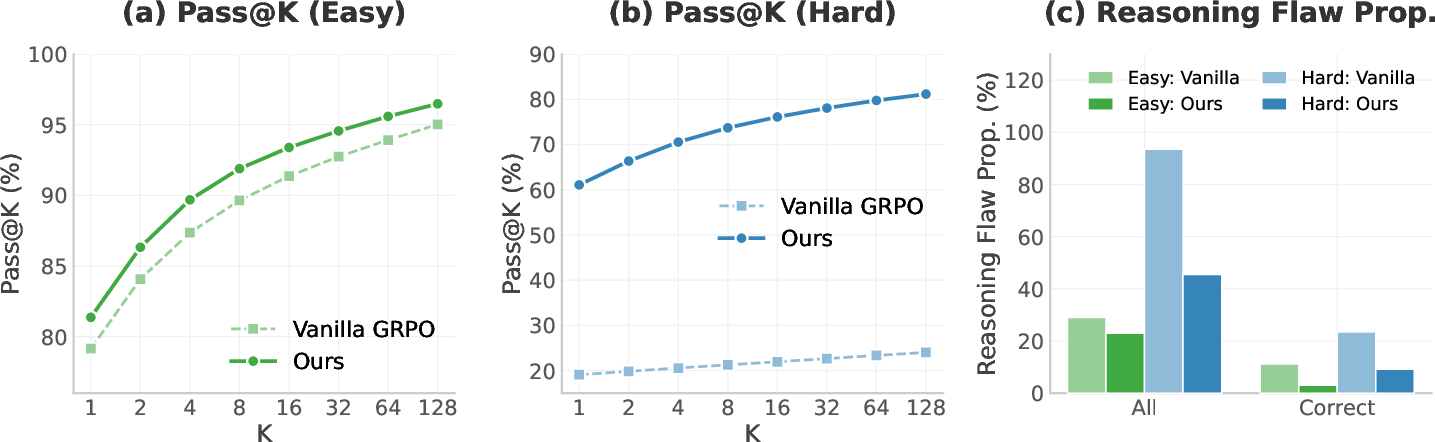
- Training to reduce premature confidence improves both accuracy and reasoning quality
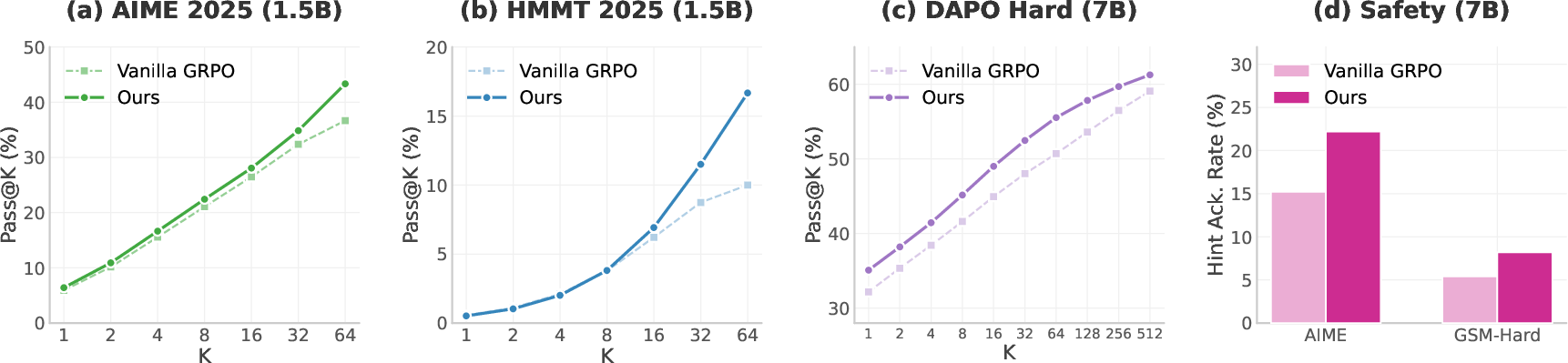
- Countdown (an arithmetic puzzle): Big gains on the hard setting. Accuracy more than tripled (+42 percentage points), and reasoning flaws dropped by 48 points.
- AIME (math contest): Pass@64 improved by 6.6 points.
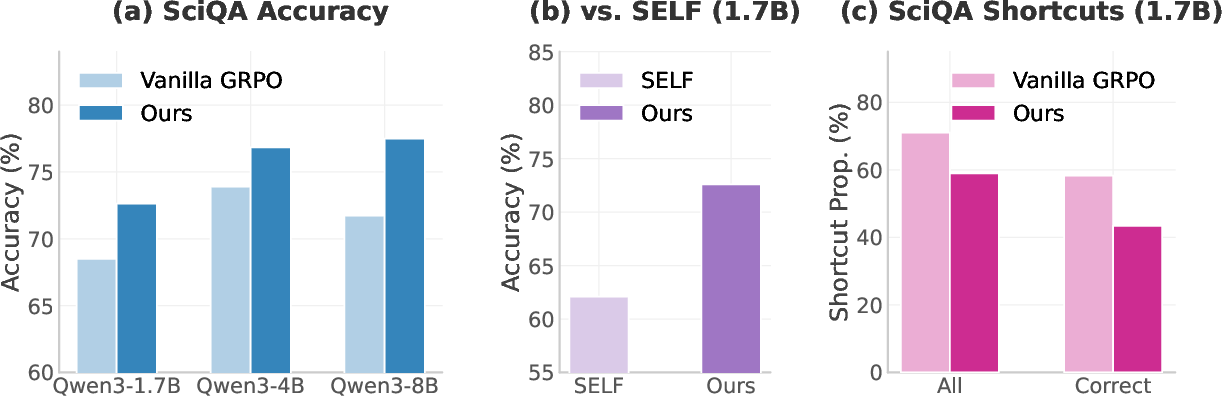
- ScienceQA: Accuracy improved across models of different sizes.
- Safety/faithfulness: On questions with misleading hints, the trained models were more likely to openly acknowledge the hint in their reasoning, instead of silently absorbing it. That suggests the explanations became more honest about what influenced the answer.
- The problem and the solution both scale with difficulty and model size
- Harder problems and larger models show more premature confidence. Surprisingly, bigger models are even more prone to jumping to conclusions before any training.
- Because of that, the new training method helps most on the toughest tasks and with larger models — exactly where we care about reliable reasoning.
Why it matters:
- These results show that just making models “think longer” is not enough. The pattern of confidence — growing step by step versus fixed from the start — is crucial.
- By training models to build confidence gradually, we get better answers and more trustworthy explanations, without needing costly step-by-step human labels.
Implications and Impact
This work has a few big takeaways:
- Better reasoning without expensive labels: The method uses the model’s own behavior (its confidence over time) as a free signal to improve reasoning. That’s practical and scalable.
- More faithful explanations: Encouraging progressive confidence produces chains-of-thought that actually reflect how the model reached its answer, which makes it easier for people to check, supervise, and trust the model.
- Strongest benefits where they’re needed most: On harder tasks and with larger models — the places where we rely on careful reasoning — this approach gives the biggest improvements.
- Guidance for future training: Instead of only rewarding correctness at the end, training should also shape the process — discouraging early commitment and rewarding genuine, step-by-step progress.
In short, the paper shows a simple but powerful idea: don’t just ask models to think — teach them to grow their confidence as they think. That makes their answers more accurate and their reasoning more honest.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, focusing on concrete avenues for future work:
- Ground-truth validation of the monitor: No human-annotated audit set is used to calibrate or validate the LLM-based “CoT monitor” (categories, severities). Quantify precision/recall, inter-rater reliability with humans, and adjudicate disagreements across monitor models.
- Sensitivity to monitoring prompts and models: The paper ablates only o3-mini vs. DeepSeek-R1. Systematically vary monitor prompts, temperature, chunking schemes, and alternative taxonomies; quantify stability of flaw counts and categories.
- Causal, not just correlational, evidence: The link “premature confidence → flawed reasoning” is correlational. Design causal interventions (e.g., hidden-state patching, counterfactual token insertions, randomized early-answer constraints) to test whether delaying commitment reduces specific flaw types.
- Probe-design dependence: The premature confidence metric relies on truncation-based probing with fixed checkpoints and a specific probe prompt. Measure sensitivity to:
- Number and placement of checkpoints (token-based vs. step/semantic-based).
- Probe prompt wording and decoding settings.
- Using logits/entropy vs. MC agreement as the confidence signal.
- Mixed definition of “confidence” during measurement vs. training: Analysis uses agreement with the model’s full-CoT answer; training uses agreement with the gold answer. Quantify how these choices change learned behavior and whether one better predicts true reasoning quality.
- Compute and scalability costs: Progressive confidence shaping requires K checkpoints × multiple MC samples per completion (e.g., 6×10=60 extra forward passes). Report wall-clock, FLOPs, and cost scaling with model size and group size G; explore amortized probing, caching, or learned proxies.
- Applicability beyond verifiable tasks: Training relies on gold-verification (MCQ or auto-checkable tasks). How to extend to open-ended, non-verifiable tasks (e.g., long-form reasoning, policy advice, multimodal) where gold checking or programmatic equivalence is unavailable?
- Generalization to other domains and modalities: No evaluation on code generation, planning, tool-use, multi-hop retrieval, or multimodal reasoning. Test transfer to these settings and to non-English corpora.
- Hyperparameter robustness: Limited evidence on sensitivity to η, the scoring vector w, number of checkpoints K, and MC sample count. Provide sweeps, automatic tuning, or adaptive/learned w to avoid task-specific handcrafting.
- Risk of Goodharting/behavioral gaming: Models could learn to “mask” early commitment (e.g., insert filler or deferral tokens) without changing internal decision timing. Devise hidden-state or causal-tracing diagnostics to detect superficial compliance.
- Impact on reasoning length and verbosity: The method might incentivize longer CoTs. Report distributions of CoT length, token-per-answer, latency, and any length-control strategies to avoid verbosity without utility.
- When early confidence is legitimate: Some tasks allow valid, short derivations with early certainty. Develop criteria for “justified early confidence” and adaptive penalties that do not harm such cases.
- Interaction with outcome rewards and process rewards: Only GRPO is studied. Evaluate with PPO/RLAIF, verifier/reasoning-process reward models, self-consistency/ToT/BoN sampling, and study additivity or interference.
- Statistical power and significance: Several benchmarks are small (e.g., AIME/HMMT with 30 items). Report confidence intervals, statistical tests, and robustness to different random seeds and sample sizes.
- Faithfulness assessment breadth: The hint-acknowledgement detector is pattern-based and narrow. Develop broader faithfulness/traceability evaluations (e.g., causal mediation analyses, contrast sets, lie/omission detection, mechanistic interpretability probes).
- Cross-model and frontier-model validation: Results concentrate on Qwen/DeepSeek families up to 8B. Test larger, diverse architectures and instruction-tuning regimes to assess universality and scaling behavior.
- Calibration and uncertainty metrics: MC-agreement is a coarse proxy for confidence. Compare with token-level entropy, calibrated probability estimates, or Bayesian ensembles; study if shaping improves global calibration.
- Step segmentation granularity: Confidence checkpoints are token-percentage based. Explore segmentation by logical steps (parser-based or model-assisted step extraction) to avoid over-penalizing introductory scaffolding.
- Category-level effects and mechanisms: “wrong_conclusion” dominates, but other categories are variably affected. Perform per-category causal analyses and failure-mode taxonomies to tailor penalties or auxiliary losses.
- Measurement under different decoding regimes: Assess robustness to temperature, nucleus/top-k sampling, and beam search; determine if shaping benefits persist across common inference settings.
- Long-context and multi-turn settings: Method is evaluated on single-turn CoTs. Extend to dialogues, tool-use with iterative calls, and very long contexts; define confidence trajectories across turns and tools.
- Safety and deceptive alignment risks: Penalizing overt early commitment may train models to hide internal decisions. Test for deception by comparing hidden-state commitment time vs. surface-level confidence trajectory.
- Early-training dynamics and accessibility/utility proxies: “Reasoning accessibility” and “utility” are estimated via proxies (η=±1 and early-checkpoint score). Validate these proxies against independent measures and across diverse tasks.
- Downstream oversight usability: Show that improved faithfulness concretely benefits human oversight (e.g., faster auditing, better error localization) via user studies or real-time monitoring tasks.
- Adaptive schedules and curricula: Static w may be suboptimal across difficulty regimes. Explore curricula that gradually tighten penalties or condition penalties on estimated difficulty.
- Tool-use and external calculators: Investigate whether penalizing early commitment interferes with timely tool calls, and how to coordinate progressive confidence with tool-invocation policies.
- Open-source resources: Provide released probes, monitor prompts, flaw annotations, and training scripts with compute budgets to facilitate replication and comparative studies.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current capabilities, drawing on the paper’s measurable “premature confidence” signal and the progressive confidence shaping (PCS) RL objective.
- Upgrade RL fine-tuning for domain-specific LLMs with PCS (education, software, scientific assistants)
- Use PCS during RL to penalize early answer commitment and reward gradual confidence growth in tasks with verifiable answers (e.g., math solvers, scientific QA, structured analytics).
- Expected outcomes: higher Pass@K, fewer logical flaws, more faithful CoT; reduced sampling budgets to reach target accuracy.
- Potential tools/products: “Reasoning-Plus” training mode for math/science LLMs; edtech solvers that show cleaner step-by-step reasoning.
- Assumptions/dependencies: availability of verifiers or gold answers; RL infrastructure (e.g., GRPO) and compute for Monte Carlo probes; permission to run multiple inference passes per sample.
- Inference-time “premature confidence” monitor and router (healthcare, finance, legal, customer support)
- Probe confidence trajectories at checkpoints; if early confidence is flat/high, route to: (a) re-sampling, (b) tool-augmented reasoning (retrieval, calculators), or (c) human-in-the-loop review.
- Expected outcomes: reduced unfaithful rationalization in high-stakes workflows; safer deployment without retraining.
- Potential workflows: decision-support dashboards that flag “early commitment” cases; automatic escalation policies.
- Assumptions/dependencies: latency/compute budget for extra probes; access to model to run truncated-CoT queries; calibrated thresholds for different tasks.
- MLOps governance metric: Progressive-Confidence Score (𝒪) (AI platforms, enterprise AI teams)
- Track the average inner-product score of confidence trajectories as a QA and regression metric across model versions and datasets.
- Expected outcomes: early detection of reasoning regressions after updates; evidence for audits and model cards.
- Potential tools: monitoring dashboards, CI gates that fail when 𝒪 worsens beyond a threshold.
- Assumptions/dependencies: sufficient sampling per batch for stable estimates; standardized checkpointing procedure.
- Data curation and active learning using confidence trajectories (academia, AI labs, edtech)
- Prefer finetuning data whose CoTs show progressive confidence; prioritize prematurely confident cases for human review or augmentation.
- Expected outcomes: higher-quality reasoning corpora without expensive step-level labels; focused labeling budgets.
- Potential workflows: auto-tagging pipelines, curator UIs with “premature confidence” sorting.
- Assumptions/dependencies: compute for trajectory estimation; task-appropriate truncation prompts.
- Safety and faithfulness QA gates using hint-injection tests (model vendors, regulated industries)
- Adopt the paper’s finding that PCS increases explicit acknowledgement of misleading hints; integrate hint-injection checks into release QA.
- Expected outcomes: more transparent CoTs that surface misleading inputs; improved oversight and red-teaming.
- Potential tools: pre-deployment safety suites that report “hint acknowledgement” rates.
- Assumptions/dependencies: task-specific hint templates; acceptance of proxy measures for faithfulness.
- Adaptive compute allocation at inference (software agents, RAG systems)
- If early commitment detected, automatically: retrieve more evidence, switch to a different reasoning template (e.g., self-consistency), or extend CoT before finalizing.
- Expected outcomes: better answers under fixed latency budgets; graceful degradation in difficult queries.
- Potential workflows: “confidence-aware” agent controllers; RAG that triggers additional retrieval on early-flat trajectories.
- Assumptions/dependencies: integration with tool-use and retrieval; policy tuning to avoid over-triggering.
- User-facing “reasoning quality” indicators (daily life assistants, enterprise chat)
- Display non-intrusive badges (e.g., “confidence building” vs. “early commitment”) and allow users to request more deliberation when flagged.
- Expected outcomes: improved user trust and informed decisions; fewer silent rationalizations.
- Potential products: chat UIs with a “show reasoning progress” toggle.
- Assumptions/dependencies: UX acceptance; extra inference passes for on-demand elaboration.
- Competition-problem pipelines (AIME/HMMT-style) (edtech, training platforms)
- Integrate PCS and trajectory-based gating for math olympiad practice tools to raise Pass@K and reduce flawed reasoning in solutions.
- Expected outcomes: better-quality step-by-step tutoring; measurable accuracy gains.
- Assumptions/dependencies: math verifiers/equivalence checkers; RL finetuning capacity.
- Compliance logging for audits (finance, healthcare)
- Store per-decision confidence trajectories alongside CoTs for traceability and post-hoc audits.
- Expected outcomes: stronger evidence trails for internal controls and external review.
- Assumptions/dependencies: data retention policies; privacy constraints; secure storage.
- RAG-triggered evidence thresholds (knowledge management, enterprise search)
- If early confidence is high but evidence is sparse, force additional retrieval or require citations before answer finalization.
- Expected outcomes: fewer unsupported conclusions; better grounding.
- Assumptions/dependencies: retriever integration; citation extractors; latency budget.
Long-Term Applications
These use cases require further research, scaling, productization, or regulatory development.
- Process Reward Models (PRMs) trained with confidence-trajectory signals (AI labs, academia)
- Use trajectories as weak labels to reduce human step-level annotation needs for PRMs that score intermediate reasoning steps.
- Potential products: general-purpose PRMs for math/science/legal reasoning.
- Dependencies: methods to blend trajectory features with sparse human labels; robustness studies across domains.
- Architectures with explicit belief/plan updates and confidence gating (software, robotics)
- Design models that maintain and expose a time-evolving belief state, constraining finalization until sufficient evidence accumulates.
- Potential products: plan-and-execute controllers for robots, autonomous agents with “no-commit-before-proof” modules.
- Dependencies: architectural changes and training curricula; evaluation in closed-loop environments.
- Regulatory standards for “deliberative transparency” (policy, compliance-heavy sectors)
- Define reporting requirements for confidence trajectories and reasoning-faithfulness metrics in high-stakes AI (clinical, legal, financial decisions).
- Potential outcomes: standardized attestations/audits; certification marks for faithful reasoning.
- Dependencies: consensus on metrics; acceptable compute/latency impact; sector-specific guidance.
- Curriculum learning and data generation to raise reasoning accessibility (education, AI research)
- Create scaffolds and intermediate goals that encourage progressively confident CoTs on hard tasks.
- Potential products: scaffolded tutoring systems that adaptively reveal hints to promote genuine reasoning.
- Dependencies: automated scaffold generation; difficulty calibration; longitudinal learning studies.
- Multi-agent critique and debate guided by confidence trajectories (multi-agent systems)
- Agents flag peers’ early commitments, request justification, and propose counter-evidence when trajectories look premature.
- Potential products: “deliberation moderators” for committees of agents.
- Dependencies: protocols for trajectory exchange; stability and convergence analyses.
- Generalization to open-ended tasks without verifiers (creative tools, knowledge work)
- Develop surrogate agreement/equivalence checks (semantic consistency, tool-verified constraints) so PCS-like objectives can train faithfulness in non-math domains.
- Potential products: report-writing assistants that delay conclusions until citations/constraints are satisfied.
- Dependencies: robust semantic equivalence metrics; domain-specific validators.
- IDE and CI integration for code agents using progressive confidence (software engineering)
- Gate merge or auto-fix actions on evidence that unit-test pass rates and static checks improve progressively during the reasoning session.
- Potential products: “Confidence-Aware Copilot” with trajectory dashboards; CI rules that block early commitment patterns.
- Dependencies: tight integration with test harnesses; fast iterative evaluation.
- Clinical decision-support with evidence-aware PCS (healthcare)
- Couple PCS with guideline retrieval and structured evidence checkers, lowering the risk of post-hoc rationalization in diagnoses/treatment suggestions.
- Potential products: CDS tools that show evolving differential diagnoses and evidence accumulation.
- Dependencies: rigorous clinical validation; regulatory approval; strong retrieval/evidence pipelines.
- Risk and trading systems with commitment gating (finance)
- Require progressive evidence accrual for automated recommendations; auto-defer actions when early commitment is detected.
- Potential products: “guard-railed” research assistants for investment and credit.
- Dependencies: latency and cost constraints; backtesting; governance buy-in.
- National security and safety red-teaming via deception/rationalization signals (security, defense)
- Use premature confidence metrics to flag potential post-hoc rationalization or concealment behavior during adversarial evaluations.
- Potential products: red-team suites with trajectory-based deception detectors.
- Dependencies: validated links between trajectories and deceptive behavior; secure testing environments.
Cross-cutting assumptions and dependencies
- Compute/latency: Confidence-trajectory probing requires multiple samples per checkpoint; deployment may need caching, sampling reduction, or selective activation.
- Data/verifiers: PCS is strongest where gold answers or reliable verifiers exist (math, structured QA); open-ended domains need surrogate metrics.
- Access: Best results when you can control training (RL) and have model-level access; API-only scenarios may need probe-efficient approximations.
- Thresholds and tuning: Task-specific thresholds for “premature” vs. “progressive” trajectories must be calibrated and monitored.
- Monitor reliability: External LLM monitors are noisy; however, the core PCS signal is annotation-free and self-generated, easing deployment.
Glossary
- Ablation studies: Controlled experiments that systematically vary components to understand their effect on results. "We perform ablation studies to verify that the correlation is robust to the classification threshold, restriction to correct samples, choice of monitor model, and quantification method."
- AIME: The American Invitational Mathematics Examination; used as a math reasoning benchmark. "On AIME, our method () matches or exceeds the vanilla baseline at all , with the gap widening at larger : Pass@64 improves from 36.7\% to 43.3\%."
- Chain-of-thought (CoT): A prompting and generation style where models output step-by-step reasoning before the answer. "Chain-of-thought (CoT) reasoning~\citep{wei2022chain} has driven much of the recent progress on hard reasoning tasks"
- clipped surrogate objective: An RL objective that limits updates to prevent instability by clipping the policy ratio. "GRPO optimizes a clipped surrogate objective with KL regularization:"
- confidence trajectory: The sequence of a model’s estimated agreement with its final answer across checkpoints in a reasoning trace. "for every generated CoT we probe the model at several truncation points along the chain to obtain a confidence trajectory"
- Countdown: A synthetic arithmetic task requiring constructing expressions to reach a target number. "We therefore use the Countdown task~\citep{tinyzero} as a sandbox"
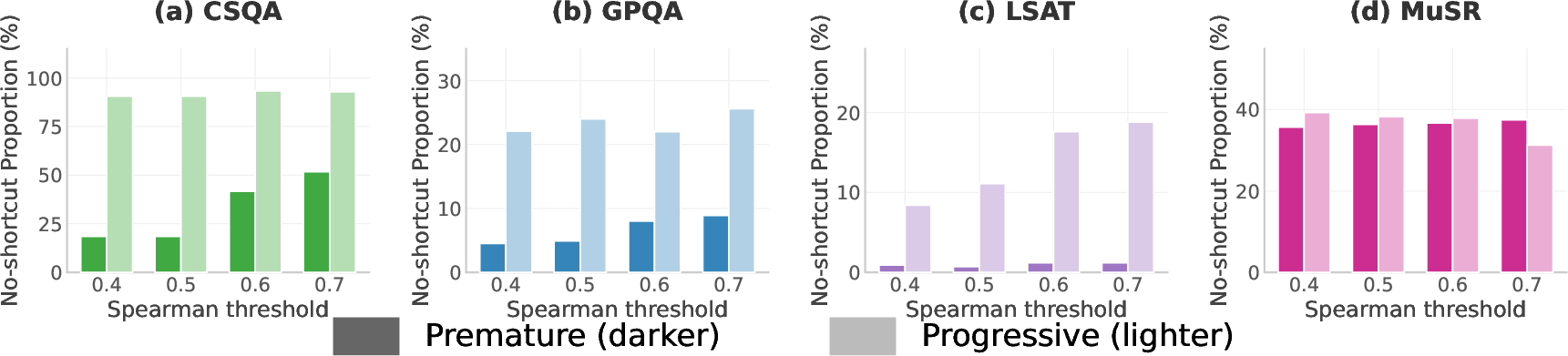
- CSQA: CommonsenseQA, a commonsense reasoning benchmark. "CSQA~\citep{talmor2019commonsenseqa} (commonsense)"
- DAPO: A math dataset used for training and evaluating reasoning models. "mathematical reasoning (AIME, DAPO~\citep{yu2025dapo})"
- DeepSeek-R1-Distill-Qwen-32B: A large reasoning-focused LLM distilled from DeepSeek-R1. "We evaluate two strong reasoning models, Qwen2.5-32B-Instruct and DeepSeek-R1-Distill-Qwen-32B"
- faithfulness: The extent to which a model’s reasoning trace reflects its actual decision process. "the method also improves faithfulness: on a safety benchmark, our models more transparently surface misleading content in their reasoning traces rather than concealing it."
- GPQA: Graduate-level science question answering benchmark. "GPQA~\citep{rein2024gpqa} (graduate-level science)"
- Group Relative Policy Optimization (GRPO): An RL algorithm that normalizes rewards within a group of samples to compute advantages. "We build our method on top of Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}"
- group-relative advantage: The normalized advantage computed relative to a group’s rewards. "The group-relative advantage is "
- hint acknowledgement rate: The proportion of cases where the model’s CoT explicitly notes an injected (misleading) hint. "our method substantially increases the hint acknowledgement rate on both AIME (15.2\% 22.2\%, +7.0pp) and GSM-Hard (5.4\% 8.2\%, +2.8pp)."
- hint-injection benchmark: An evaluation where misleading hints are added to measure whether models expose or conceal them in their reasoning. "on the hint-injection benchmark of \citet{nguyen2025reasoning}"
- ignored_evidence: A reasoning flaw where relevant evidence is overlooked. "ignored_evidence (the CoT overlooks strong evidence in the question that points to a different answer)"
- importance sampling ratio: The ratio of current to behavior policy probabilities used to weight updates in off-policy RL. "where $\rho_{i,t} = \pi_{\theta}(y_{i,t} \mid x, y_{i,<t}) / \pi_{\theta_{\mathrm{old}(y_{i,t} \mid x, y_{i,<t})$ is the importance sampling ratio"
- internal_contradiction: A reasoning flaw where a statement contradicts an earlier statement in the same CoT. "internal_contradiction (a statement directly contradicts an earlier statement in the same CoT)."
- KL regularization: Regularizing updates by penalizing divergence from a reference policy using Kullback–Leibler divergence. "GRPO optimizes a clipped surrogate objective with KL regularization:"
- LSAT: A legal reasoning benchmark based on Law School Admission Test-style questions. "LSAT (legal reasoning)"
- misreading: A reasoning flaw where the CoT misstates the information in the question. "misreading (the CoT claims X about the question, but the question actually states Y; the monitor must cite both)"
- monitor: An external LLM-based system that audits CoT traces for logical flaws. "We design a two-phase audit pipeline powered by an external LLM (o3-mini for all main results; we additionally ablate with DeepSeek-R1 in Section~\ref{sec:ablation})."
- Monte Carlo samples: Repeated random samples used to estimate quantities like agreement at checkpoints. "and 10 Monte Carlo samples per checkpoint."
- MuSR: A multi-step reasoning benchmark. "MuSR~\citep{sprague2023musr} (multi-step reasoning)."
- outcome rewards: RL rewards based solely on final answer correctness, not on intermediate reasoning quality. "RL on reasoning has largely relied on outcome rewards"
- Outcome-based RL: Reinforcement learning that optimizes only final outcomes; can incentivize shallow or unfaithful reasoning. "Outcome-based RL amplifies premature confidence, which manifests in two forms:"
- Pass@: The probability that at least one of K sampled solutions is correct. "Pass@ curves further show that improvements persist across all values"
- premature confidence: A model’s tendency to commit to an answer early and rationalize afterward, leading to flawed reasoning. "premature confidence, the tendency to commit to an answer early and use the remaining tokens to rationalize it"
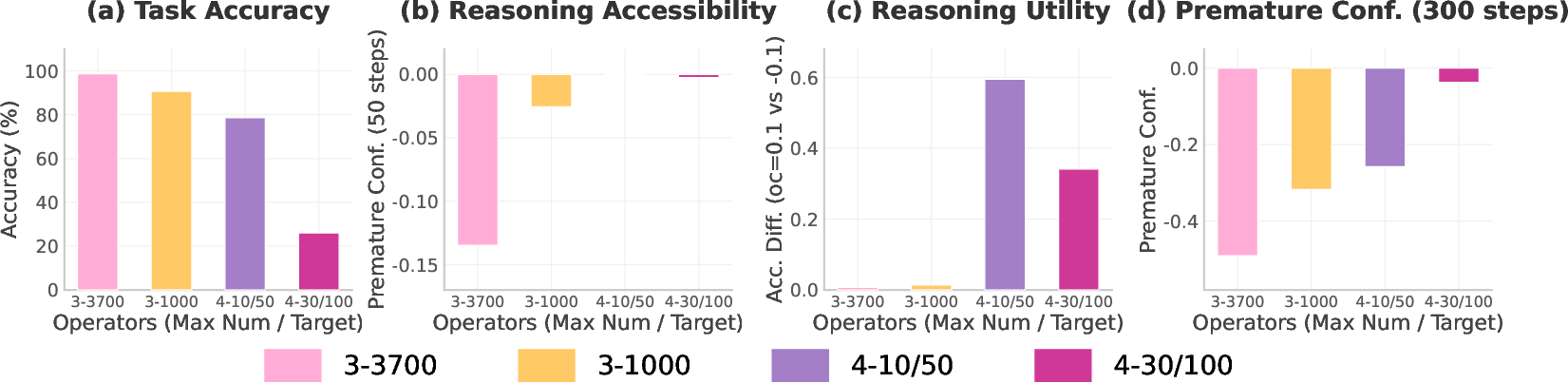
- premature confidence score: A batch-level metric measuring how much a model’s confidence concentrates early in its CoT. "We further define the premature confidence score of the model as the average penalty across all samples in a batch"
- process reward models: Models that assign rewards to intermediate reasoning steps rather than just final outcomes. "process reward models that score intermediate steps"
- progressive confidence: A confidence pattern that builds gradually, indicating that reasoning contributes causally to the answer. "A CoT exhibits progressive confidence if the trajectory rises gradually from low to high"
- progressive confidence shaping: An RL objective that penalizes early commitment and rewards gradual confidence growth during reasoning. "We introduce progressive confidence shaping, a reinforcement learning objective built on top of GRPO."
- reference policy: The pretrained policy used as a baseline for KL regularization in RL updates. "and $\pi_{\mathrm{ref}$ is the pretrained reference policy."
- reasoning accessibility: How readily a model produces progressively confident CoTs early in training. "Reasoning accessibility is the likelihood that the model generates progressively confident CoT in the early stages of training."
- reasoning utility: How much accuracy improves when using progressively confident reasoning versus prematurely confident reasoning. "Reasoning utility is the accuracy gap between answering with progressively confident versus prematurely confident CoT."
- SciQA: A scientific multiple-choice question answering benchmark. "and scientific reasoning (SciQA)"
- scoring vector: A fixed, monotonically decreasing weight vector used to score confidence trajectories for shaping rewards. "with a fixed monotonically decreasing scoring vector"
- SELF: A concurrent self-play-based method for hard reasoning used as a baseline comparison. "We also compare with SELF~\citep{nguyen2025reasoning}, a concurrent method that uses self-play to push beyond reasoning boundaries on hard problems."
- Spearman rank correlation: A nonparametric correlation coefficient used to assess monotonic relationships in confidence trajectories. "we compute the Spearman rank correlation between and the checkpoint index."
- unsupported_conclusion: A reasoning flaw where a claim lacks support from preceding text. "unsupported_conclusion (a statement or claim is asserted in the CoT without support from the preceding text)"
- vanishing CoT: A failure mode where the model skips reasoning and outputs only a final equation/answer. "Instance 1: Vanishing CoT."
- wrong_conclusion: A reasoning flaw where the final answer contradicts the CoT’s own derived conclusion. "wrong_conclusion (the model's final answer contradicts the answer that its own CoT reasoning points to---e.g., the CoT argues for option D but the stated final answer is A)"
Collections
Sign up for free to add this paper to one or more collections.