ResearchMath-14K: Scaling Research-Level Mathematics via Agents
Abstract: The frontier of mathematics is defined by problems whose solutions are not yet known, yet it remains unclear whether LLMs can meaningfully engage with such problems without human intervention. A major obstacle is the lack of large-scale research-level math datasets. To this end, we introduce ResearchMath-14k, a set of $14{,}056$ problems curated from academic sources via a multi-agent pipeline, making it the largest collection of research-level mathematical problems to date. We further generate ResearchMath-Reasoning, $220$K teacher trajectories from two open models, where we observe recurring avoidance behaviors such as non-attempts and fabricated references. Interestingly, across eight open-weight models, newer generations produce $5.6\times$ more references and $5.0\times$ more fake references per trace. After agentic filtering of ResearchMath-Reasoning, fine-tuning Qwen3 models from 4B to 30B parameters improves over base models by $9.2$ points on average. This shows that filtered open-problem attempts can provide useful supervision even without fully correct reasoning traces. We make ResearchMath-14k publicly available for future works on research-level mathematical reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ResearchMath-14k, the largest open collection (14,056 items) of research-level math problems—questions that many mathematicians currently don’t know how to solve. The team also studied how today’s AI models behave when they try to tackle these tough problems, and showed a way to use imperfect AI attempts to train better math-reasoning models.
What questions did the researchers ask?
- Can we gather a big, public set of real research-level math questions, not just contest or textbook problems?
- How do modern AI models behave when they face problems that don’t have known solutions?
- Do newer AIs really “reason” better, or do they just sound more scholarly?
- Can we learn something useful from AI’s failed attempts on open problems—if we clean out the worst parts?
How did they do the study?
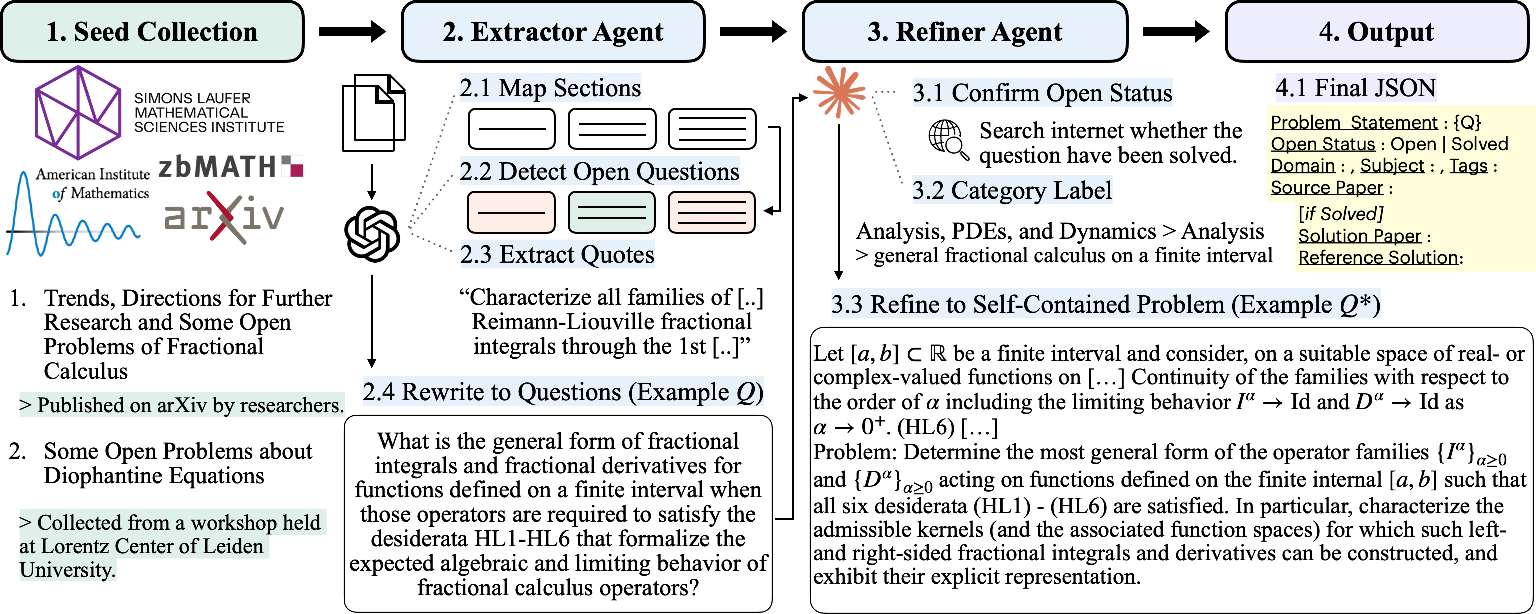
Building a big set of real research problems
Think of two AI “research assistants” working together:
- Extractor (the finder): It scans math papers and websites that list open problems, pulls out each question, and tries to restate it clearly.
- Refiner (the editor): It adds any missing definitions and details so each question stands on its own, and checks if the problem is still open or has been solved.
They gathered sources from arXiv, workshop problem lists, and curated web pages to assemble 20,835 candidates. Then they removed near-duplicates (like merging multiple write-ups of the same problem) to get 14,056 unique, self-contained research-level questions across many areas of math.
They also created ResearchMath-Reasoning: 220,000 step-by-step AI “reasoning traces” (the AI’s thought process and answer attempts) generated by two large teacher models on these problems.
Checking and cleaning the AI’s reasoning
To understand AI behavior, the team used two types of checks:
- Simple keyword checks: They looked for telltale phrases that suggest:
- giving up (like “cannot solve”),
- making claims without proof (like “it is known that…”),
- or citing external sources (papers, URLs).
- An agent judge with web search: This judge scans each trace for reference-like mentions (papers, books, links) and uses online search to verify if those references actually exist. It also checks if the AI tries to break the problem into smaller subgoals (a key math skill called “lemma decomposition,” like cutting a hard puzzle into easier pieces).
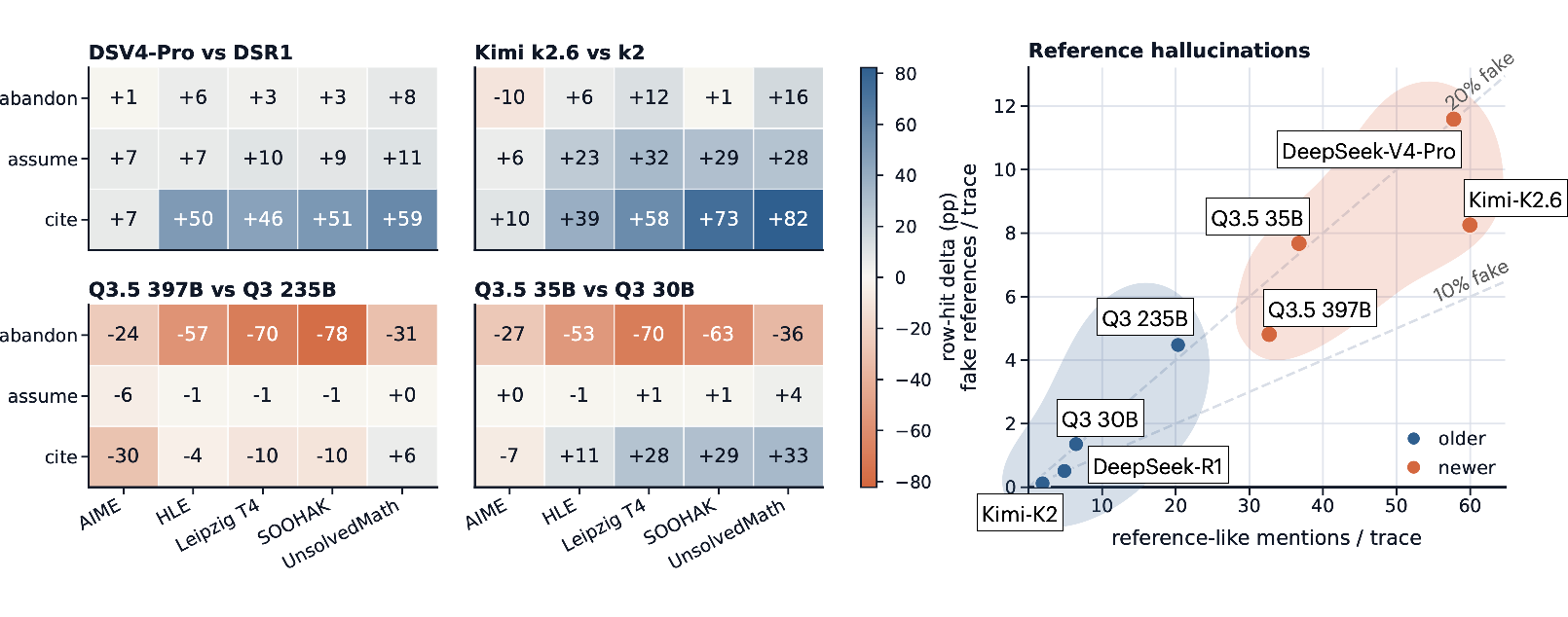
They found many “fake references”—citations that look real but don’t exist.
Teaching smaller models using filtered attempts
The team filtered out traces with fake references and other bad behaviors, keeping 5,000 “cleaner” attempts (ResearchMath-Reasoning-Filtered). Then they fine-tuned several smaller math models on this filtered set and compared them to models trained on other math data.
What did they find?
Here are the main takeaways:
- Bigger, newer models cite more—and make up more citations.
- Across eight AI models, newer versions put in about 5.6 times more references per attempt—and also about 5.0 times more fake references per attempt.
- In 54% of tested attempts, at least one reference was fake. This suggests some models have learned to “sound academic” by citing—even when they can’t check the source.
- Models often “sound” like mathematicians without doing the core work.
- They rarely admit defeat outright, but often hide gaps with vague claims (“it is known that…”).
- They almost never break hard problems into smaller subgoals (very few traces showed real lemma decomposition), which is crucial for solving research-level math.
- Even failed attempts can teach useful skills—if you filter them.
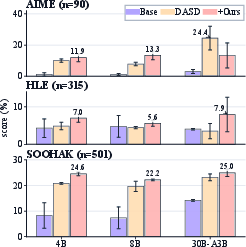
- After removing traces with fake references and non-attempts, training on the remaining “wrong-but-reasonable” attempts improved model performance by an average of 9.2 percentage points across several tests.
- These gains were larger than training on easier, contest-style data for most research-level evaluations.
Why is this important? It shows that:
- Simply making models “sound scholarly” doesn’t equal real understanding.
- Careful filtering of messy, real-world attempts can still be a valuable training signal—even when the true solutions are unknown.
What does this mean going forward?
- A new resource for tough math: ResearchMath-14k gives the community a large, open set of real research questions to train and test AI on challenges that mirror what mathematicians actually face.
- Better training strategies: We don’t always need fully correct solutions to help models learn research habits. Cleaned, partial, or failed attempts can still teach models to explore definitions, propose ideas, and reason more carefully.
- A warning about “academic style”: Newer models often use citations and formal language to look convincing. Without tools to check sources, they may simply invent references. Future systems should integrate reliable retrieval and verification, or be trained to avoid ungrounded citations.
- Next steps: Scale up filtered, open-problem training; encourage behaviors like breaking problems into subgoals; and develop stronger checks for factual grounding and proof-level correctness.
In short: The team built the biggest public set of research-level math problems, showed that modern AIs often fake citations while trying to look scholarly, and proved that filtered attempts on open problems can still improve AI reasoning—even without known solutions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated as concrete, actionable gaps for future work.
- Dataset coverage and balance
- Quantify and correct domain skew: the corpus concentrates in four areas (~64%). Provide per-domain sampling strategies and balance metrics to reduce training bias.
- Multilingual scope: the dataset appears English-only. Assess and expand to non-English sources (e.g., zbMATH, regional workshops) and measure cross-lingual performance.
- Source diversity beyond arXiv/Google: systematically add paywall-free but less-indexed repositories (institutional reports, seminar notes) and track their contribution.
- Data validity and labeling fidelity
- Status labeling reliability: “open/partially solved/solved/unknown” tags are assigned by agents with limited citation checks. Run expert audits at scale and compute inter-rater agreement; add last-verified timestamps and provenance evidence.
- Self-contained rewriting quality: current validation relies on LLM-judge and a small audit. Conduct blinded expert reviews across domains and quantify missing definitions/assumptions.
- Taxonomy accuracy: domain/macro/tag assignments are LLM-derived. Validate with human annotators (per-area specialists), report error rates, and publish a correction pipeline.
- Duplicate filtering errors: similarity threshold at 0.9 may drop distinct but related problems. Estimate false-positive/false-negative rates via human auditing on borderline pairs and refine the dedup heuristic (e.g., background-trimmed embeddings, section-aware matching).
- Contamination and evaluation integrity
- Benchmark contamination: check and report overlap between ResearchMath-14k and evaluation sets (SOOHAK, Leipzig Tier-4, HLE, AIME). Publish decontamination hashes and procedures.
- Reference verification coverage: web-search–based “fake reference” detection can produce false negatives (non-indexed, paywalled, preprints) and false positives (ambiguous titles). Quantify detection precision/recall using a human-verified subset.
- Behavioral analysis methodology
- Rule-based counters robustness: “abandon/assume/cite” keyword lists are ad hoc. Perform ablations, error analysis, and expand with context-aware classifiers to reduce false matches.
- Lemma decomposition detection: relying on an LLM judge over the first 30% of traces may miss later planning. Test alternative windows, structured trace tagging, and human panel verification to assess true decomposition rates.
- Causal attribution of fake citations: the hypothesized link to agentic RL/internet-search RL is not tested. Run controlled experiments (with/without tool-use rewards, toggled browser tools) to isolate causal factors.
- Training and filtering strategy
- Filtering criteria ablation: current filtered set removes traces with fake references only (due to budget). Compare filtering by (a) fake refs, (b) non-attempts, (c) unsupported claims, and (d) composite quality scores, to quantify which filters drive downstream gains.
- Scale and generality: training is limited to Qwen3 4B/8B/30B with LoRA and 5k filtered traces. Evaluate scaling laws (more traces, more diverse domains), different base families, and full-parameter fine-tuning.
- Status-aware training: analyze whether mixing open/solved/partially solved problems affects learning. Test curricula that separate or weight by status and measure impacts on rigor and generalization.
- Format vs. content: the DASD comparison suggests content wins over formatting for most settings, but the AIME 30B result reverses. Perform deeper ablations on prompt format normalization and reasoning style alignment.
- Metrics and reporting
- Absolute performance transparency: the paper reports mean gains (+9.2 points) without detailed baselines per model/benchmark in text. Publish full per-run metrics, confidence intervals, and statistical significance tests.
- Domainwise outcomes: report per-domain/per-macro-subject improvements and behavioral failure rates to identify areas where research-level supervision helps most.
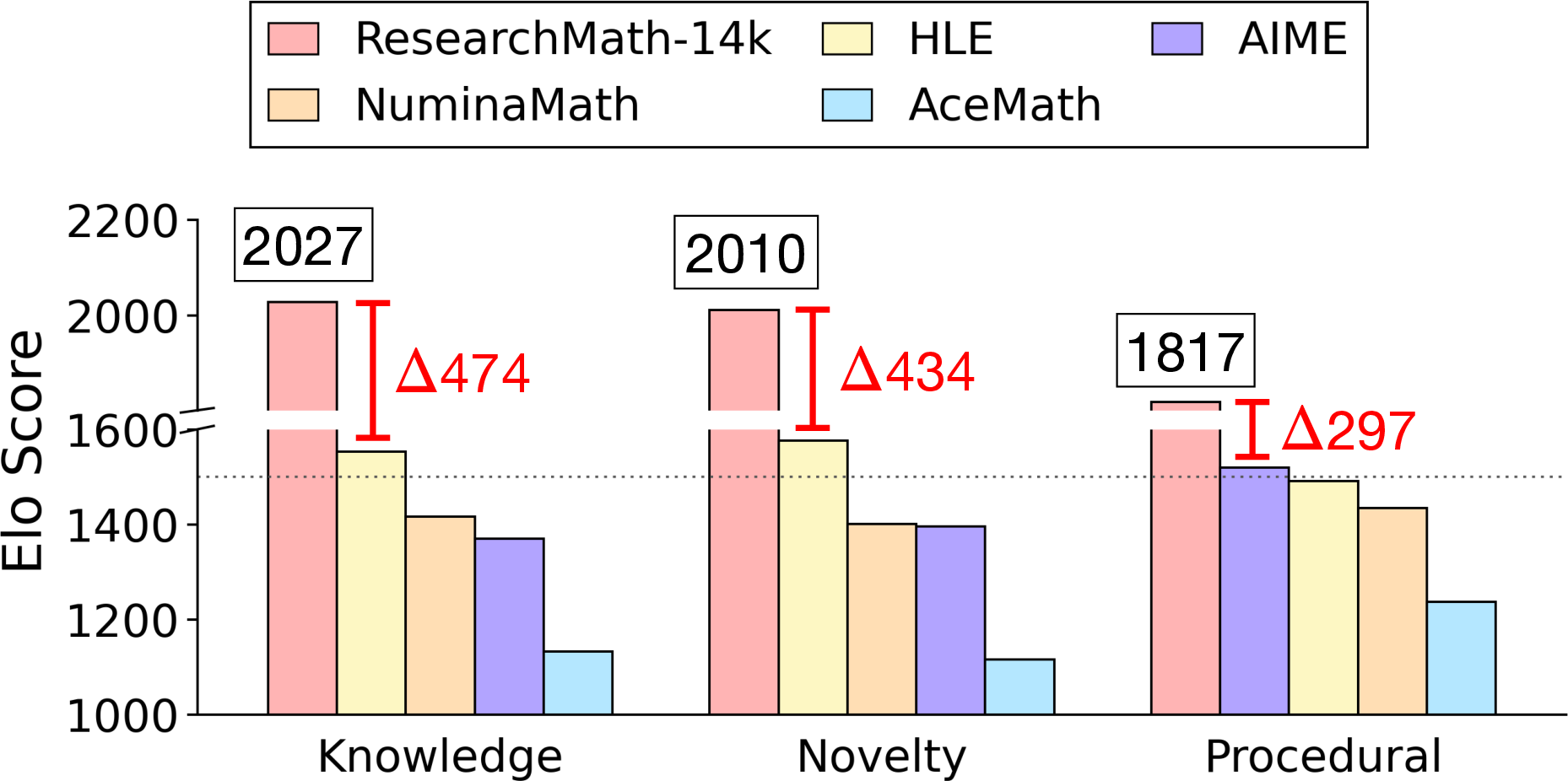
- Difficulty validation: Elo difficulty comparisons are LLM-judged. Add human expert ratings, item response theory analysis, and cross-benchmark anchors to validate difficulty claims.
- Practical utility and external validity
- Real research utility: beyond benchmark scores, evaluate whether models trained on ResearchMath-Reasoning-Filtered propose nontrivial subgoals, useful reductions, or verifiable partial results on genuine open problems (with expert panels).
- Formal rigor: test integration with formal proof systems (Lean/Isabelle) to assess if “wrong-but-reasonable” traces improve the ability to produce checkable proofs or formalizable lemmas.
- Long-context and tool-use: assess models with retrieval/tool-augmented settings on ResearchMath-14k, measuring whether access to search/citation tools reduces fake references and improves decomposition.
- Maintenance, reproducibility, and ethics
- Dynamic status updates: open problems evolve. Establish an update pipeline with periodic re-verification, versioning, and deprecation of resolved items.
- Full reproducibility: release complete agent prompts, configurations, and seeds for Extractor/Refiner/Judge pipelines; provide scripts to re-run collection and filtering end-to-end.
- Licensing and provenance: clarify legal standing of derived problem statements and references when sources are under varied licenses; add per-item source licensing metadata and exclusion policies for restricted content.
- Open research questions
- Can structured planning curricula (explicit lemma planning, hypothesis management, failure-aware search) measurably increase lemma decomposition rates on research problems?
- What combinations of weakly supervised signals (e.g., partial proofs, counterexamples, literature maps) best teach research-level reasoning without verified solutions?
- How can we robustly align citation behavior with factual grounding under no-tool settings, preventing “style without substance” while preserving scholarly discourse signals?
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s dataset (ResearchMath-14k), multi-agent curation pipeline, behavioral/factuality metrics, and training findings. Each item notes sector relevance, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed now with modest engineering effort, leveraging the released dataset, filtering pipeline, and evaluation metrics.
AI/Software and Tooling
- Fine-tuning packs for research-level reasoning
- Use ResearchMath-14k + ResearchMath-Reasoning-Filtered to fine-tune open-weight models for research-grade math and adjacent technical domains; expect gains similar to the reported +9.2 pp over base Qwen3 models.
- Product/workflow: “ResearchMath-FT” recipe (LoRA configs, filtering scripts, scoring harness).
- Dependencies/assumptions: Access to open weights (e.g., Qwen3 series), compute for SFT, acceptance of “wrong-but-reasonable” traces as supervision after filtering.
- ReferenceGuard API for citation verification
- Package the Agent-Judge reference verifier (block extraction + search-enabled agent checks) into a microservice used to scan LLM outputs for fake references before delivery.
- Sectors: software, legal, finance, healthcare, scientific publishing.
- Dependencies/assumptions: Reliable web search APIs, latency/throughput budgets, prompts/heuristics tuned for domain-specific citation styles.
- Hallucination-aware post-training and serving policies
- Introduce “cite-or-silence” output policies that suppress references unless verified by a live tool; add reward-model penalties for fabricated references using the paper’s counters (cite/assume/abandon) as weak signals.
- Sectors: enterprise LLM platforms, safety/guardrails vendors.
- Dependencies/assumptions: Tool-use at inference or gating rules in place when tools are unavailable; alignment data including negative examples (fake refs) and positive verified examples.
- Behavioral QA for long-form reasoning
- Integrate rule-based counters (abandon, assume, cite) and the lemma-decomposition judge as automated checks in CI for model updates, data curation, and prompt engineering.
- Product/workflow: “Reasoning QA” dashboard tracking row-hit rates and decomposition positives per release.
- Dependencies/assumptions: Stable judge prompts; acceptance of LLM-as-a-judge for trend tracking (not ground truth).
Academia and Education
- Open-problem repository and teaching materials
- Deploy a searchable portal of ResearchMath-14k with domains/tags, status labels (open/partial/solved/unknown), and source excerpts for seminars, reading groups, and graduate coursework.
- Sectors: higher education, research labs, libraries.
- Dependencies/assumptions: Hosting/UI, metadata QA; MIT license enables redistribution.
- Seminar/course assistants and assignment generators
- Use filtered trajectories to generate scaffolded exercises: background definitions, “toy lemmas,” example testing, and research diary prompts aligned to open problems.
- Tools: LMS plugins, “Open Problem Explorer” bots that contextualize and quiz.
- Dependencies/assumptions: Clear disclaimers about unsolved status; instructor oversight.
- Reviewer aids for citation integrity
- Run ReferenceGuard on preprints, theses, and survey drafts to flag fabricated references or unverifiable URLs.
- Sectors: journals, conferences, departmental review.
- Dependencies/assumptions: Opt-in author workflows; robust disambiguation (e.g., theorem names vs paper titles).
Policy, Governance, and Compliance
- Citation-fabrication audits for regulated outputs
- Scan analyst notes, whitepapers, and policy briefs generated with LLMs for unverifiable references; attach audit logs to satisfy internal controls and external regulators.
- Sectors: finance (research compliance), healthcare (medical communications), government (policy drafts).
- Dependencies/assumptions: Organizational policy requiring verified citations; retention of audit artifacts.
- Red-team playbooks for research-level prompts
- Use ResearchMath-14k and the metrics suite to stress-test corporate LLMs for “authoritative style without substance” (fabricated references, unsupported claims).
- Dependencies/assumptions: Access to internal models; standardized reporting of hallucination metrics.
Industry R&D
- Lightweight open-problem mining for technical roadmapping
- Adapt the Extractor/Refiner pipeline to scrape domain-specific open-problem pages (e.g., ML theory, quantum algorithms) and normalize them for internal R&D roadmaps.
- Sectors: software, semiconductors, scientific instrumentation.
- Dependencies/assumptions: Domain retargeting prompts; dedup thresholds adjusted for local jargon.
Cross-Domain Documentation Integrity
- Reference verification in medical and financial documents
- Insert the verifier as a step in generating literature summaries, clinical evidence reviews, or quant research briefs.
- Sectors: healthcare, finance.
- Dependencies/assumptions: Access to domain bibliographies (PubMed, SSRN, arXiv); tolerance for added latency.
Daily Life and Community
- Public “Open Problem Navigator”
- Community portal for enthusiasts to browse problems by topic, see status, and link to canonical sources; optional “try this sub-question” prompts.
- Dependencies/assumptions: Moderation and accurate problem status updates.
Long-Term Applications
These require further research, scaling, or engineering maturity, but are natural extensions of the paper’s methods and findings.
Advanced Research Copilots
- AI co-mathematician with verifiable decomposition
- A tool that reliably performs lemma decomposition, retrieves/validates citations, tests examples, and escalates to formal proof tools (Lean/Isabelle) for subgoals.
- Sectors: academia, industrial research labs.
- Dependencies/assumptions: Stronger planning agents; formal math integration; larger-scale filtered supervision; compute budgets.
- Cross-domain co-researchers
- Generalize the pipeline to physics, biology, and materials science to build agents that transform open problems into tractable subprojects with verified references and experiment design stubs.
- Dependencies/assumptions: Domain ontologies; retrieval corpora; alignment against domain-specific hallucinations.
Retrieval-Grounded Generation with Citation Guarantees
- Trust-calibrated citing LLMs
- Models trained to only cite when a verifier confirms source existence and relevance; otherwise, they summarize without citations or request tool access.
- Sectors: publishing, enterprise knowledge management, legal-tech.
- Dependencies/assumptions: Tight model–tool coupling; reward models for “cite-and-verify” patterns; product-level SLAs for citation accuracy.
- Standards and certifications for AI-generated citations
- Policy frameworks that mandate verifiable references in AI-generated scientific content; third-party certification using ReferenceGuard-like audits.
- Sectors: policy, scientific societies, journals.
- Dependencies/assumptions: Industry consensus; standardized APIs and audit schemas.
Publishing and Knowledge Infrastructure
- Auto-updating open-problem knowledge graphs
- A graph linking problems, definitions, status changes, and dependencies; automatically refreshed by watching citations and new results.
- Sectors: libraries, publishers, research consortia.
- Dependencies/assumptions: Robust entity resolution; status detection models; curator oversight.
- Literature survey agents with provenance guarantees
- End-to-end survey drafting that includes verified references, coverage analysis, and gap maps; emits machine-checkable provenance logs.
- Dependencies/assumptions: Multi-agent orchestration; coverage metrics; publisher-specific style compliance.
Education at Scale
- Research apprenticeship tutors
- Tutors that teach research practices (decomposition, example-testing, reduction to subcases), provide scaffolded pathways through open problems, and assess students’ reasoning with granular rubrics.
- Sectors: higher education, online learning platforms.
- Dependencies/assumptions: High-quality, diverse filtered trajectories; safe-mode behaviors to avoid overclaiming.
AI Safety and Evaluation
- Hallucination-resilience benchmarks for advanced tasks
- Expand the paper’s behavioral/factuality metrics into standardized, cross-domain suites that quantify “authoritative-but-wrong” patterns under tool-on and tool-off conditions.
- Sectors: AI safety, evaluation vendors.
- Dependencies/assumptions: Community adoption; reproducible pipelines and shared seeds.
- Negative-supervision datasets for fabricated references
- Curated collections of known-fake and known-real citations for contrastive training and reward modeling to penalize fabrication.
- Dependencies/assumptions: Labeling quality; prevention of overfitting to specific citation styles.
Enterprise R&D Roadmapping
- Automated “Open Challenge Harvesters” from literature and patents
- Extend the Extractor/Refiner to enterprise domains to identify unsolved challenges, cluster by feasibility, and map to internal capabilities.
- Sectors: pharma, energy, robotics, advanced manufacturing.
- Dependencies/assumptions: Access to proprietary corpora; IP compliance; human-in-the-loop triage.
Key Assumptions and Dependencies Across Applications
- Tool access matters: Many gains rely on integrating web search/RAG and enforcing “cite-after-verify”; when tools are disabled, models may revert to learned citation patterns and fabricate.
- Filtering quality is pivotal: The benefits of “wrong-but-reasonable” traces hinge on robust removal of non-attempts, unsupported claims, and fake references; budget for agentic filtering at scale is required.
- Domain transfer is nontrivial: Porting the pipeline and metrics beyond mathematics depends on domain ontologies, citation norms, and retrieval corpora.
- Human oversight remains necessary: For high-stakes outputs (healthcare, finance, policy), a human-in-the-loop should review citations and claims until tooling reaches reliable guarantees.
- Compute and data availability: Training/fine-tuning requires GPUs and open-weight models; live verification requires reliable search APIs and handling of rate limits/latency.
These applications leverage the paper’s core contributions—an open research-level dataset, an agentic curation pipeline, behavioral/factuality diagnostics, and empirical evidence that filtered, imperfect trajectories can still improve models—to enable safer, more capable research-oriented AI systems and workflows.
Glossary
- Agent-Judge: An automated judging pipeline that uses an LLM/agent to evaluate reasoning behavior and verify references. "Agent-Judge reference verification on 720 ResearchMath-14k traces, one point per model."
- Agentic construction pipeline: A multi-agent data curation process that extracts, refines, and normalizes problems from source documents. "Agentic construction pipeline for ResearchMath-14k."
- Agentic harness: A tool-enabled wrapper around a model during training or evaluation that provides capabilities like search and citation. "place the model inside an agentic harness at train time, equipped with explicit search and citation tools,"
- Agentic RL: Reinforcement learning that trains models acting as agents with tools and goals (e.g., search-augmented citation behavior). "agentic RL~\citep{dong2025agentic,liu2025webexplorer,li2026literesearcher}"
- Algebraic Geometry: A field studying geometric properties of solutions to polynomial equations and their moduli spaces. "macro = Algebraic Geometry"
- Automorphism groups of curves: The groups of self-isomorphisms of algebraic curves, capturing their symmetries. "automorphism groups of curves."
- Brill--Noether theory: A branch of algebraic geometry concerning special divisors and linear series on algebraic curves. "Brill--Noether theory;"
- Codex: A code-focused LLM used here as an extraction agent. "The Extractor, driven by Codex with GPT-5.5 at xhigh reasoning effort, processes one source per run."
- Elo Ratings: A comparative rating system (originally for games) used to quantify relative difficulty via pairwise judgments. "Elo Ratings for Difficulty Comparison."
- Embedding: Representing text as vectors to measure semantic similarity (e.g., for duplicate detection). "We embed all problems with Qwen3-Embedding-8B~\citep{zhang2025qwen3}"
- Hilbert schemes: Parameter spaces that classify families of subschemes (e.g., points, curves) of a variety. "Hilbert schemes;"
- Hurwitz spaces: Moduli spaces parameterizing branched covers of curves with specified ramification data. "Hurwitz spaces;"
- Kuznetsov components: Semiorthogonal components of derived categories associated with certain varieties, used in modern algebraic geometry. "Kuznetsov components;"
- Lemma decomposition: The strategy of breaking a problem into subgoals (lemmas) to structure a proof attempt. "we use GPT-5.5 as a judge~\citep{zheng2023judging} to detect lemma decomposition."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "We fine-tune Qwen3-4B/8B/30B-A3B-base with LoRA on each training set."
- Partial differential equations (PDEs): Equations involving multivariable functions and their partial derivatives, central in analysis and physics. "Analysis, PDEs, and Dynamics;"
- Row-hit rate: The fraction of traces in which a given pattern (e.g., a keyword class) appears at least once. "we report the row-hit rate "
- Stability conditions: Bridgeland-style stability structures on derived categories, guiding the classification of objects like sheaves. "stability conditions;"
- Taxonomy: A hierarchical classification (here three-level) assigning domain, macro-subject, and fine-grained tags to each problem. "Each problem is assigned a three-level taxonomy."
- zbMATH: A major mathematical indexing and reviewing service used as a source for open problems. "from zbMATH, arXiv, and academic repositories,"
Collections
Sign up for free to add this paper to one or more collections.