- The paper introduces the Representation Locality Score (RLS) to quantify inter-layer redundancy, guiding adaptive, training-free pruning strategies.
- The LoRP framework leverages spectral clustering and a two-stage pruning process to achieve lower perplexity and improved downstream reasoning accuracy.
- Empirical evaluations reveal that architecture-dependent, locality-aware pruning outperforms fixed heuristic methods, especially for models with distributed redundancy.
Locality-Aware Redundancy Pruning for LLM Depth Compression
LLMs with deep Transformer stacks exhibit substantial representational redundancy across network depth, leading to opportunities for compression via layer-wise pruning. Previous training-free pruning approaches have generally assumed consistent redundancy structures across architectures or relied on heuristics based on local layer importance or contiguous depth regions, which can obscure heterogeneous redundancy patterns present in different LLMs. This paper introduces a formal analysis, using inter-layer hidden-state cosine similarity matrices, to demonstrate that some architectures have strongly localized redundancy (layer similarity concentrated near diagonal), while others present globally distributed redundancy (high similarity off-diagonal). This observation motivates the development of an architecture-dependent redundancy quantification, which is essential for effective depth pruning in Transformer-based LLMs.
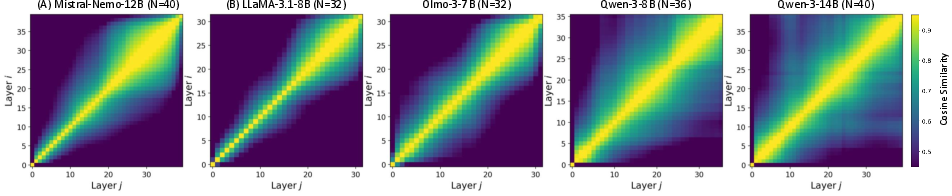
Figure 1: Pairwise inter-layer hidden-state cosine similarity matrices S for five pre-trained LLMs; higher Sij values indicate strong representational overlap between corresponding layers.
Representation Locality Score (RLS) and Depth Pruning Framework
The Representation Locality Score (RLS) is introduced as a global metric summarizing inter-layer similarity, quantifying the decay of representational overlap across depth. Higher RLS values indicate more localized redundancy, while lower values reflect distributed similarity. The paper leverages RLS as a guiding principle for training-free, one-shot depth pruning. The Locality-Aware Redundancy Pruning (LoRP) framework proceeds as follows: hidden states from all blocks are extracted on a calibration corpus, a pairwise similarity matrix is computed, spectral clustering is applied to partition layers into representational clusters based on the affinity matrix, and a two-stage pruning procedure is performed. Stage 1 removes one layer per cluster (coverage-aware), while Stage 2 prunes further according to intra-cluster redundancy.
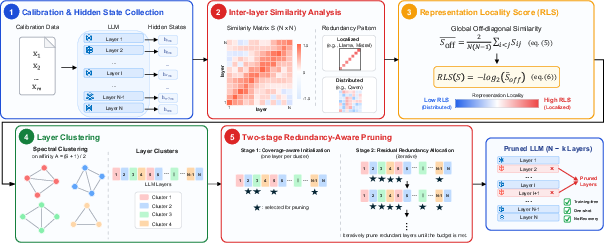
Figure 2: Overview of LoRP—hidden-state collection, similarity matrix computation, RLS summarization, spectral clustering, and two-stage pruning allocation.
Empirical Characterization of Redundancy Structures
Empirical analysis across five open-source LLMs reveals pronounced variance in redundancy patterns. LLaMA, OLMo, and Mistral exhibit steep similarity decay (localized redundancy), with higher RLS. In contrast, Qwen models manifest broadly distributed similarity (lower RLS), necessitating distributed pruning rather than contiguous layer removal.
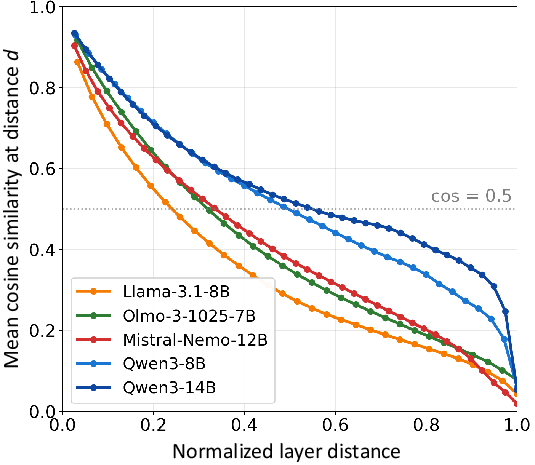
Figure 3: Mean inter-layer cosine similarity as a function of normalized layer distance; slower decay implies distributed redundancy.
The effectiveness of LoRP is validated through perplexity and downstream reasoning benchmarks, utilizing nine zero-shot tasks on (ARC, HellaSwag, WinoGrande, BoolQ, OBQA, RTE, COPA, RACE). Across aggressive pruning budgets, LoRP consistently achieves lower perplexity and higher downstream accuracy compared to ShortGPT, LLM-Streamline, LaCo, and other baselines. Notably, LoRP’s architecture-adaptive pruning is especially robust for Qwen models, where other methods suffer significant degradation due to inappropriate contiguity assumptions. These results contravene the standard belief that fixed pruning heuristics suffice, highlighting the importance of locality-aware, architecture-dependent allocations.
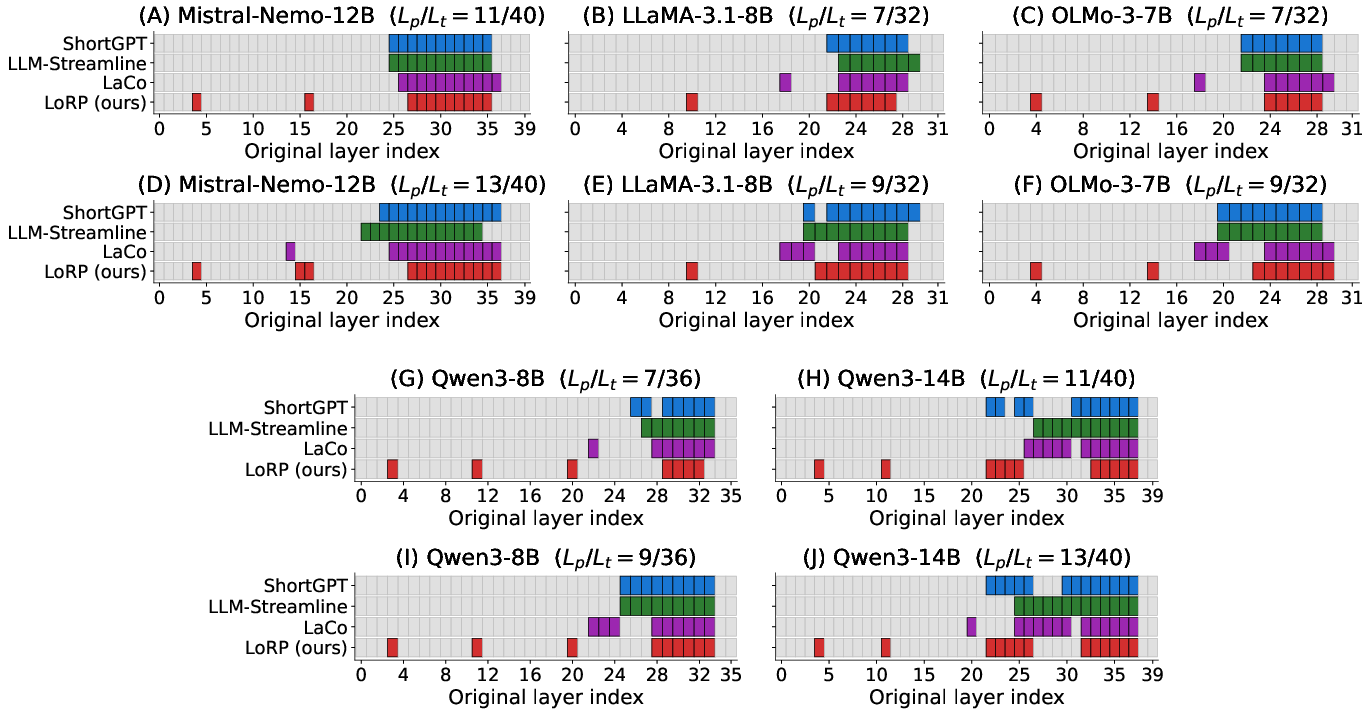
Figure 4: Visualization of pruned layer indices selected by multiple methods; LoRP yields architecture-dependent, distributed patterns for Qwen and localized patterns for LLaMA, Mistral.
Cluster Granularity and Ablation Study
Cluster granularity is critical: models with globally distributed redundancy benefit from larger K in spectral clustering; those with localized redundancy are less sensitive to this parameter. Ablation shows that LoRP remains competitive or superior even as K is varied, further supporting the need for redundancy-adaptive clustering.
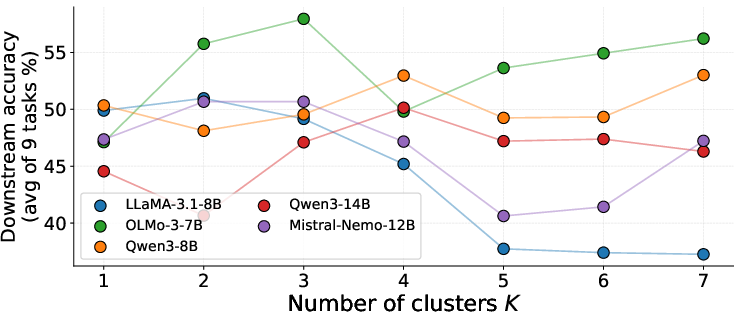
Figure 5: Effect of the number of representational clusters K on downstream accuracy for different LLM architectures.
Implications and Future Directions
LoRP demonstrates that practical depth pruning must be guided by architecture-specific representation geometry, with RLS serving as a principled global metric. The findings demand a reassessment of current pruning strategies, advocating for explicit locality modeling in compression pipelines. The method’s training-free, one-shot design makes it readily deployable without recovery steps, although integration with post-pruning tuning could further increase compression ratios. Extending LoRP to broader architectures, attention-level redundancy analysis, and fully automated cluster selection are promising directions.
Conclusion
This work establishes that representational redundancy across depth is architecture-dependent and not universally contiguous. The proposed LoRP framework, guided by the Representation Locality Score, allocates pruning decisions in a manner reflective of each model’s redundancy structure, achieving improved perplexity and downstream accuracy over prior methods. The empirical results compel the community to abandon universal pruning heuristics in favor of locality-aware, adaptive compression strategies for Transformer LLMs.

