- The paper introduces a structural pruning framework that employs both layerwise and widthwise strategies to reduce model size while targeting maintenance of core reasoning abilities.
- The paper demonstrates that supervised finetuning, especially when combined with L2 hidden-state loss, recovers over 95% of original performance at mild compression ratios.
- The paper reveals that widthwise pruning preserves multimodal reasoning more effectively than layerwise methods, achieving data-efficient recovery with as little as 5% of the training data.
Structural Pruning and Recovery Training for Large Vision LLMs
Motivation and Scope
Large Vision LLMs (LVLMs) demonstrate substantial capacity on visual, linguistic, and multimodal reasoning tasks but impose significant computational and memory burdens, complicating their deployment on resource-constrained hardware. Existing size reduction techniques primarily utilize training smaller models from scratch, but these strategies lack flexibility and incur considerable costs. This paper (2604.24380) proposes a systematic approach for compressing LVLMs by applying structured pruning to the language backbone—either layerwise or widthwise—followed by data- and compute-efficient recovery training, including supervised finetuning and knowledge distillation.
Structured Pruning Paradigms
The study operationalizes two distinct pruning schemes:
- Layerwise pruning: Removes transformer blocks based on block influence metrics, leveraging the redundancy of deep layers.
- Widthwise pruning: Eliminates attention heads and MLP neurons via dependency graph-based importance assessments, ensuring structural integrity of layerwise transformations.
A decision framework is articulated for selecting pruning and recovery strategies tailored to resource availability and desired compression ratios.
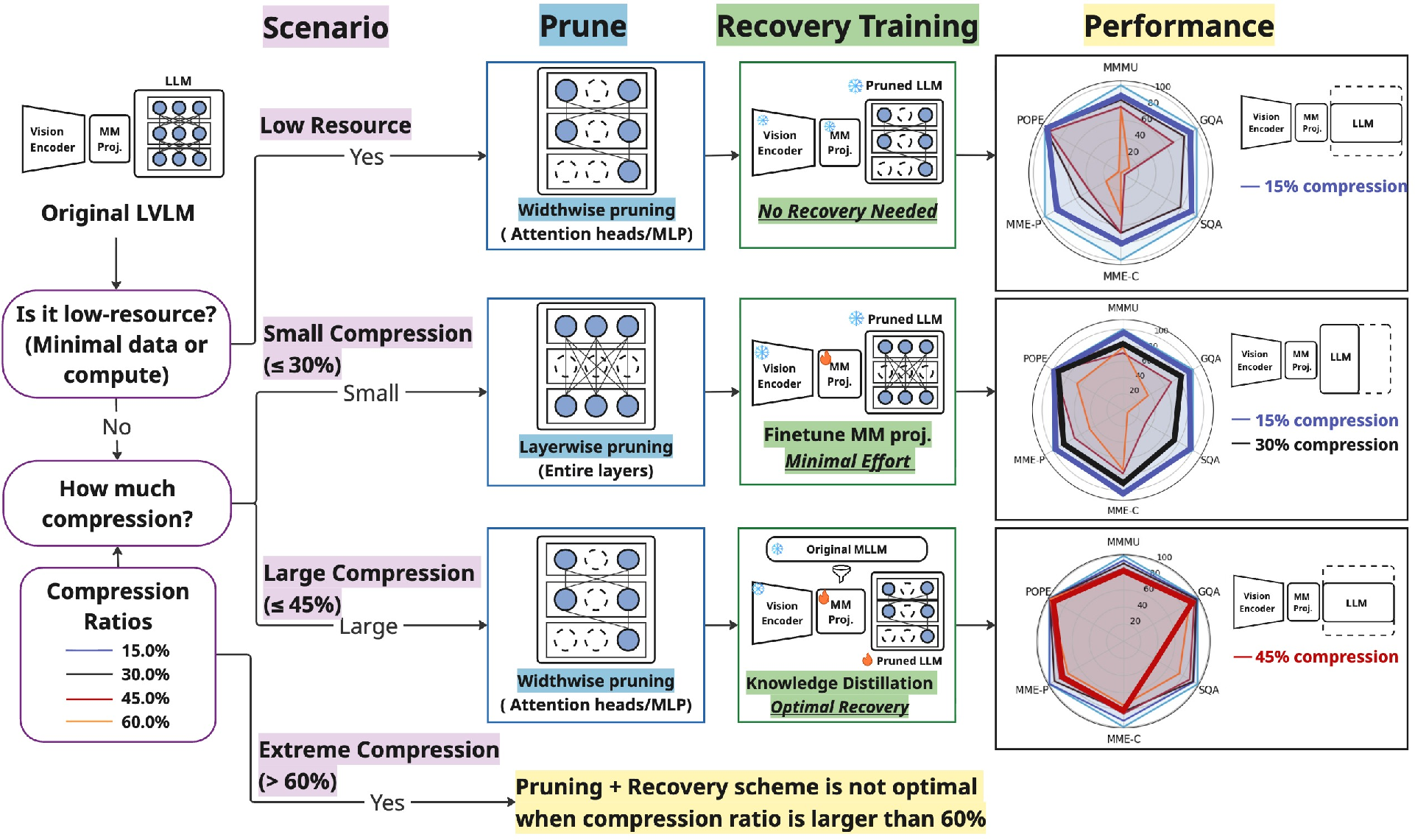
Figure 1: Decision flow for selecting LVLM pruning and recovery strategies according to hardware and fidelity requirements.
The empirical evaluation demonstrates that, in low-resource and zero-shot settings, widthwise pruning preserves model competency more effectively than layerwise pruning. Layerwise removal disproportionately impairs performance on benchmarks with complex free-form generation and reasoning, revealing the criticality of architectural depth for such tasks.
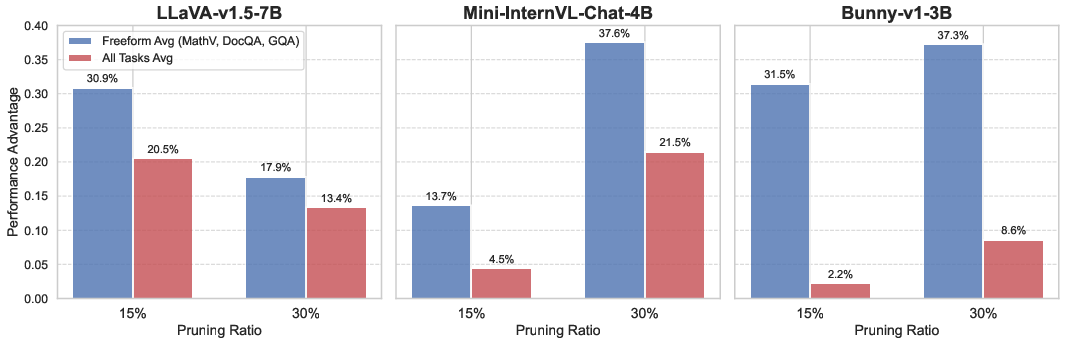
Figure 2: Widthwise pruning offers superior performance on reasoning-intensive benchmarks compared to layerwise approaches, especially at moderate sparsity ratios.
Recovery Training: Supervised Finetuning and Knowledge Distillation
Following pruning, performance recovery is essential to compensate for disrupted cross-modal alignment and degraded linguistic capabilities. The paper analyzes the efficacy of several recovery strategies:
- Supervised Finetuning (SFT): Retraining on ground-truth responses restores modality alignment, particularly via finetuning the multimodal projector.
- Knowledge Distillation (KD): Transfers output distributions or hidden-state representations from the unpruned teacher to the pruned student, utilizing KL, Reverse KL, and L2 objectives.
Key findings include:
- SFT on the projector is sufficient for mild pruning (≤15%), recapturing >95% of original performance with minimal compute.
- Beyond 30%, joint SFT (projector and LLM) becomes necessary as pruning damages both multimodal alignment and core language reasoning.
- KD alone is less impactful at high pruning ratios; however, combining SFT and hidden-state L2 loss yields maximal robustness and recovery.
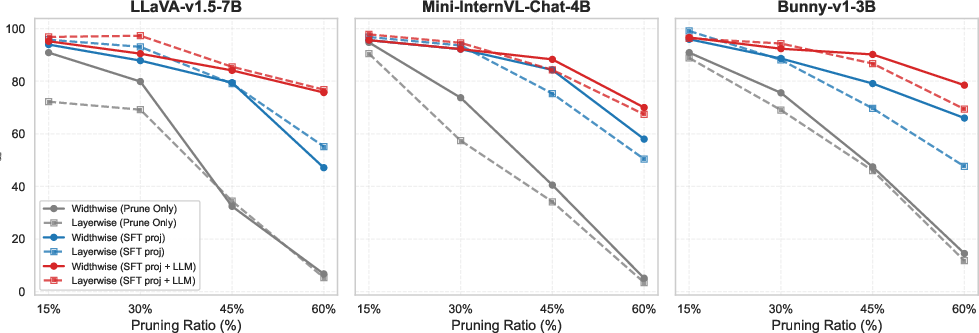
Figure 3: SFT only the multimodal projector recovers alignment at mild compression, but joint SFT is required for higher pruning ratios.
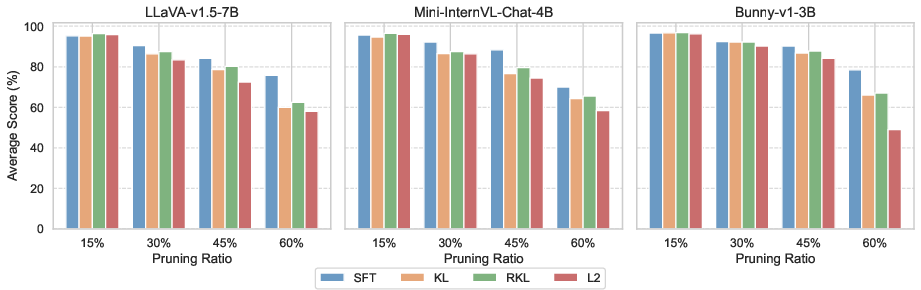
Figure 4: KD performs comparably to SFT at low pruning ratios but is suboptimal at high ratios; SFT+L2 hidden-state matching is optimal for robust recovery.
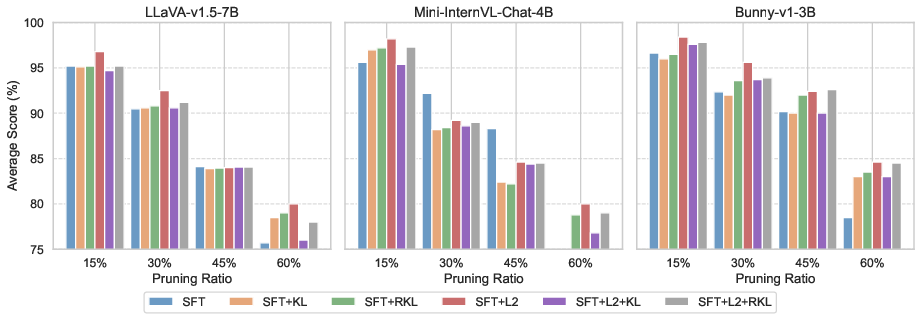
Figure 5: SFT+L2 loss outperforms other combinations in recovery training, consistently restoring performance across compression levels.
Data Efficiency and Calibration Sensitivity
The study systematically evaluates the data efficiency of recovery training, revealing that high-fidelity models (>90% performance retained) can be recovered using only 5% of the dataset for compression ratios up to 45%. For severe pruning (≥60%), larger fractions are required, but full data is only necessary in that extreme regime. Similarly, importance score calibration for pruning converges rapidly; as few as 10 samples suffice for reliable structural pruning.
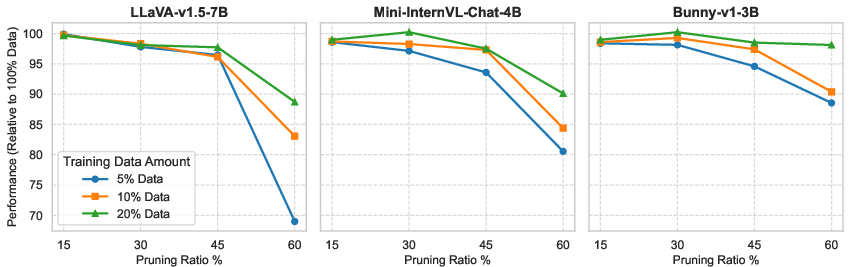
Figure 6: Even minimal data (≥5%) enables effective recovery after moderate pruning; higher ratios demand proportionally more data.
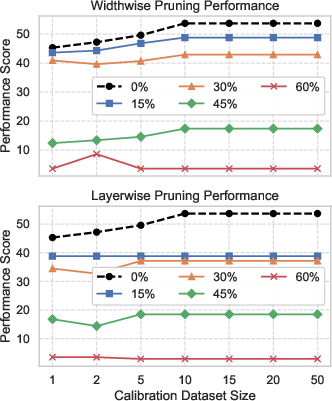
Figure 7: Calibration sensitivity is minimal; model performance stabilizes after a small number of samples for importance score estimation.
Hardware and Latency Implications
Both layerwise and widthwise pruning confer equivalent gains in GPU memory and theoretical FLOPs at equal sparsity, but latency benefits differ. Layerwise pruning yields lower inference time by reducing network depth and kernel launches. However, this must be balanced against its inferior retention of reasoning capacity relative to widthwise pruning at comparable compression ratios.
Practical Guidelines and Implications
The paper distills actionable insights for practitioners:
- Widthwise pruning should be preferred for standalone compression, especially where reasoning and open-ended generation are critical.
- Layerwise pruning, combined with SFT, is effective for modest pruning (≤30%) when latency is the primary concern.
- Combining SFT and L2 hidden-state KD achieves optimal recovery; output KD provides diminishing returns.
- Data-efficient calibration and recovery are feasible, minimizing both compute and data requirements.
- Structural pruning integrates readily with quantization (e.g., LLM.int8), enabling compounded memory reduction without substantial loss in performance.
Theoretical Significance and Future Directions
Findings reinforce the architectural vulnerability of transformer-based LVLMs to layer removal, with widthwise redundancy enabling safe compression without disrupting sequential processing chains essential for complex multimodal reasoning. These results generalize across representative LVLMs (LLaVA-v1.5-7B, Mini-InternVL-Chat-4B, Bunny-v1-3B), providing clarity on balancing structural fidelity, efficiency, and deployment constraints.
Future directions include:
- Extending pruning and recovery techniques to vision encoders and multi-modal fusion modules.
- Exploring unstructured and semi-structured pruning in the context of commodity hardware.
- Scaling up to increasingly diverse datasets and benchmark suites, e.g., for AGI-oriented multimodal tasks.
Conclusion
This comprehensive study establishes a formal framework for structured pruning and lightweight recovery of LVLMs, delineating trade-offs between compression ratio, performance, and resource efficiency. The empirical and theoretical analyses substantiate widthwise pruning and combined SFT+L2 training as optimal for robust, data-efficient compression and deployment. Such insights equip researchers and practitioners to tailor LVLM architectures for real-world scenarios, accelerating progress towards efficient, performant multimodal AI systems.

