Published 26 May 2026 in cs.LG, cs.AI, and cs.RO | (2605.27079v1)
Abstract: Off-policy reinforcement learning of pretrained flow policies remains challenging due to the instability of optimization arising from the multi-step sampling process. Recently, Q-learning with Adjoint Matching (QAM) addressed this issue by reformulating into a memoryless stochastic optimal control (SOC) problem with a learned critic. However, QAM inherits a fundamental fragility of critic-guided improvement: small critic errors are amplified when critics are ill-conditioned, often leading to model collapse. This paper introduces Trust Region Q-Adjoint Matching (TRQAM), a stable off-policy fine-tuning algorithm that adaptively controls the path-space KL with pretrained flow policies through projected dual descent. Specifically, we optimize the trust-region parameter $λ$ in SOC dynamics, and theoretically show that the path-space KL can be represented by a closed-form function of $λ$. As a result, our method can precisely control the exact deviation from pretrained flow policies, achieving stable off-policy RL. Through experiments on 50 OGBench tasks, TRQAM consistently outperforms prior arts in both offline RL and offline-to-online RL. In particular, TRQAM achieves an overall success rate of 68% in offline RL, substantially improves the strongest baseline at 46%.
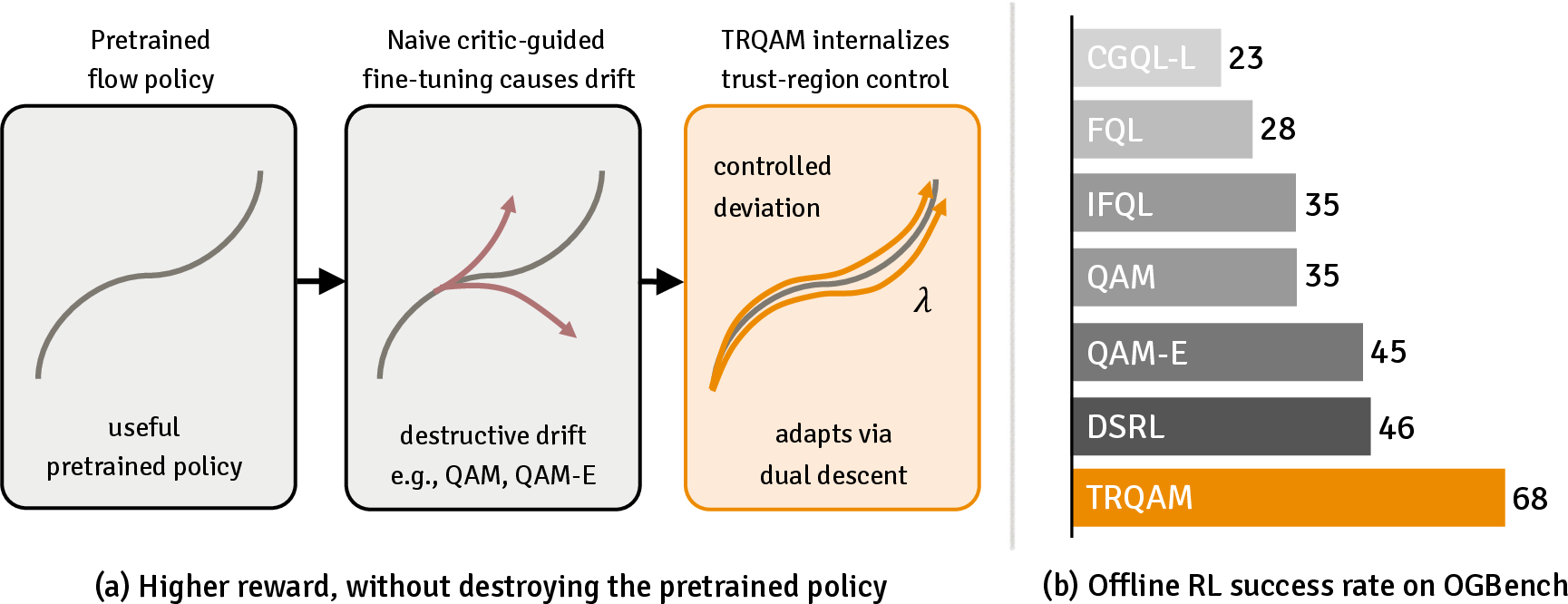
The paper presents TRQAM, which integrates an adaptive trust-region parameter into SOC dynamics to stabilize fine-tuning of pretrained flow policies.
It introduces a closed-form relationship between the trust-region parameter and the path-space KL, curbing critic-induced error amplification.
Empirical results on OGBench and Robomimic show significantly improved success rates, highlighting TRQAM’s robustness in challenging RL settings.
Trust Region Q Adjoint Matching: Stable Fine-Tuning of Pretrained Flow Policies via Adaptive Path-Space KL Control
Introduction and Motivation
Trust Region Q-Adjoint Matching (TRQAM) (2605.27079) addresses critical instability issues in off-policy RL fine-tuning of pretrained flow policies. Prior approaches, including Q-learning with Adjoint Matching (QAM), reparameterize the policy update as a stochastic optimal control (SOC) problem, guiding the flow policy via a learned critic. However, QAM and similar exponentially-tilted update methods are fundamentally fragile: even small critic errors can be amplified through the update, resulting in destructive drift from the pretrained prior and eventual model collapse, especially under distributional shift or imperfect bootstrapped critics.
TRQAM mitigates this problem by integrating an adaptive trust-region parameter λ directly into the SOC dynamics, thereby enforcing a strict path-space KL constraint between the fine-tuned and pretrained policies. By projecting dual descent onto λ, TRQAM tracks a prescribed KL budget across offline and online RL, achieving both practical stability and controllability in policy deviation. Theoretical results establish that the path-space KL is a closed-form function of λ (via Girsanov’s theorem), allowing precise control at the sampling level rather than relying on heuristic loss-level penalties.
Figure 1: TRQAM’s architecture: adaptive trust-region control is internalized into SOC dynamics, stabilizing policy deviation from the pretrained flow prior while outperforming baselines in OGBench.
Theoretical Developments
Critic-Induced Fragility and Exponential Error Amplification
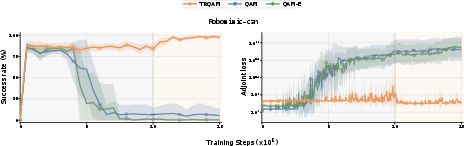
TRQAM formalizes the exponential amplification of critic errors with exponentially-tilted policy updates in Lemma~1. No fixed update temperature β (or, equivalently, trust-region parameter λ) can simultaneously exploit reliable critics and protect against unreliable ones—large β permits destructive drift, while small β hinders effective improvement. This insight underscores the need for adaptive trust-region control rather than fixed global regularization.
Figure 2: Empirical demonstration of fragility—a fixed temperature QAM exhibits catastrophic loss explosion and performance collapse, while TRQAM preserves stability.
Path-space KL as a Closed-Form Function of Trust-Region Parameter
TRQAM’s core technical innovation is to scale the diffusion coefficient in the SOC SDE by λ, allowing the path-space KL between the controlled and base processes to be exactly 2λ1E[∫∥u∥2] (Theorem~1). This makes λ a structural parameter governing the policy’s deviation from the pretrained prior. Proposition~1 further shows that this path-space KL upper-bounds the action-level terminal KL, guaranteeing that controlling λ0 tightly bounds the true policy divergence.
The connection between λ1 and the update temperature λ2 is explicit: increasing λ3 shrinks the terminal KL and bounds critic-error amplification, aligning with trust-region principles in on-policy RL algorithms like TRPO and PPO.
Algorithmic Design: Adaptive Dual Descent
TRQAM adapts λ4 via projected dual descent, utilizing a Monte Carlo estimator for path-space KL (based on Gaussian transition kernels for flow policies). When the observed KL exceeds the target, λ5 increases, pulling the sampler toward the base policy; when below, λ6 relaxes, allowing greater improvement. The algorithm thus couples the trajectory distribution to the KL constraint during sample generation rather than loss optimization.
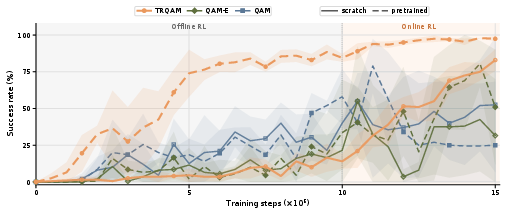
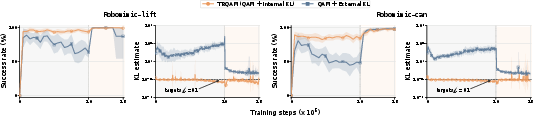
Crucially, TRQAM internalizes λ7 in the sampling dynamics, not as an external loss penalty. Empirical comparison in OGBench and Robomimic experimentally validates this distinction: only TRQAM tracks the KL budget tightly and maintains stability under critic perturbations and distributional shifts.
Figure 3: Offline-to-online RL curves: Only TRQAM substantially leverages pretrained flow priors, outperforming QAM and QAM-E regardless of initialization.
Empirical Results
TRQAM was evaluated on 50 OGBench tasks and the Robomimic manipulation benchmark, comparing against six baselines spanning action-level residuals, noise-space RL, and adjoint-matching variants.
Offline RL: TRQAM achieves 68% mean success rate in OGBench, a 22-point improvement over the best prior method (DSRL, 46%) and a 33-point gain over QAM (35%). Gains are most pronounced in long-horizon and combinatorial planning domains.
Offline-to-Online RL: TRQAM’s stability persists after transition, with per-task curves confirming sustained performance and rapid adaptation.
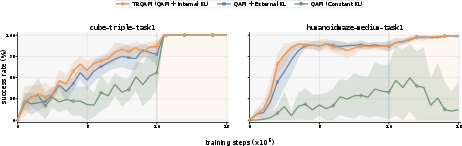
Stability and Mechanism: Only the internalized adaptive KL (TRQAM) enforces the prescribed KL budget; external regularization can be overridden by strong critic guidance (Figures 5/6), leading to drift.
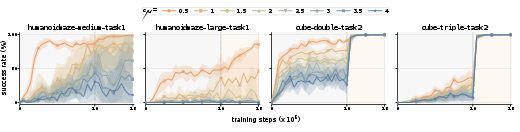
Sensitivity: TRQAM’s KL budget is a robust and predictable knob—success rate varies smoothly with λ8, enabling controlled adaptation to task structure (Figure 4).
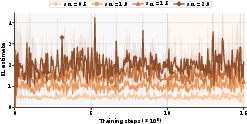
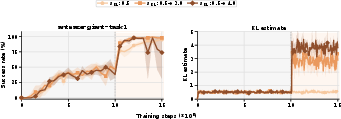
Time-varying KL schedules: TRQAM can immediately track dynamic KL budgets, supporting exploration demands in online phases (Figures 8/9).
Figure 5: Adaptation is necessary—TRQAM and adaptive KL variants outperform fixed-temperature QAM, validating the exponential error amplification theory.
Figure 6: Internalization is necessary—TRQAM tightly tracks the KL budget, whereas external KL regularization admits drift and performance degradation.
Figure 4: Sensitivity analysis: success rate curves depend smoothly on KL budget; tight budgets are generally optimal unless large state space requires broader exploration.
Figure 7: TRQAM tracks the prescribed KL budget across both offline and online training phases.
Figure 8: TRQAM successfully adapts to time-varying λ9 schedules, demonstrating immediate adjustment and high stability.
Practical and Theoretical Implications
TRQAM advances stability and controllability in fine-tuning expressive pretrained flow policies, making RL safer and more predictable under imperfect critics and task distribution shifts. The internalization of trust-region control directly in sampling dynamics, backed by rigorous path-space KL theory, distinguishes TRQAM from prior KL-regularized approaches.
Practically, TRQAM enables transfer of pretrained behavior cloning policies to new tasks via off-policy RL, fully exploiting prior knowledge and regulating the exploration–exploitation balance. The method scales to large, diverse RL domains (OGBench, Robomimic) with minimal risk of collapse, even under adversarial hyperparameter settings.
Theoretically, TRQAM’s framework could generalize to other high-capacity policy classes (diffusion/flow models in vision-language-action domains). The path-space KL formulation provides a principled mechanism for imposing trust-region constraints in generative policy search, potentially influencing future RL architectures where adaptive structural constraints are essential.
Future Directions
Potential future directions include:
Extension to hierarchical RL and vision-language-action models, exploiting structural KL constraints in broader multimodal settings.
Automated selection and adaptation of λ0 via meta-learning or task-specific characterization.
Integration with safety-critical RL filters and constraint-aware exploration.
Low-variance path-space KL estimation in high-dimensional domains.
Conclusion
TRQAM establishes a new structural paradigm for stable off-policy fine-tuning of pretrained flow policies, leveraging adaptive trust-region Q-adjoint matching in SOC dynamics. The method’s tight theoretical linkage between λ1 and path-space KL enables practical enforcement of exact policy deviation bounds. Empirical results demonstrate marked improvements over prior baselines, especially in challenging domains with long-horizon or combinatorial structure. The approach opens new avenues for trust-region stabilization in expressive generative RL and sets a foundation for further theoretical and practical advances.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.