- The paper introduces Collaborative Parallel Thinking (CPT) to share intermediate reasoning findings across parallel branches, reducing redundant computation.
- It employs synchronized information pooling with semantic clustering and adaptive broadcast scheduling to efficiently merge and disseminate decision-relevant insights.
- Empirical results on math benchmarks demonstrate improved accuracy-token trade-offs and a shifted accuracy-latency Pareto frontier versus traditional test-time scaling methods.
Collaborative Parallel Thinking for Efficient Test-Time Scaling
Motivation and Problem Statement
Test-Time Scaling (TTS) leverages additional inference compute at test time to enhance the reasoning capabilities of LLMs, particularly for complex mathematical tasks. Parallel TTS strategies, which simultaneously sample multiple reasoning branches, have shown empirical gains by accelerating the exploration of the solution space. However, conventional parallel TTS methods exhibit a critical bottleneck: intermediate discoveries made by one branch remain inaccessible to other branches during search, resulting in redundant rediscovery and inefficient compute utilization.
Empirical findings confirm that, as parallel search proceeds, independent sampling increasingly yields duplicate information with diminishing returns in decision-relevant insight (Figure 1), illustrating the inefficiency inherent in information-isolated parallel exploration.
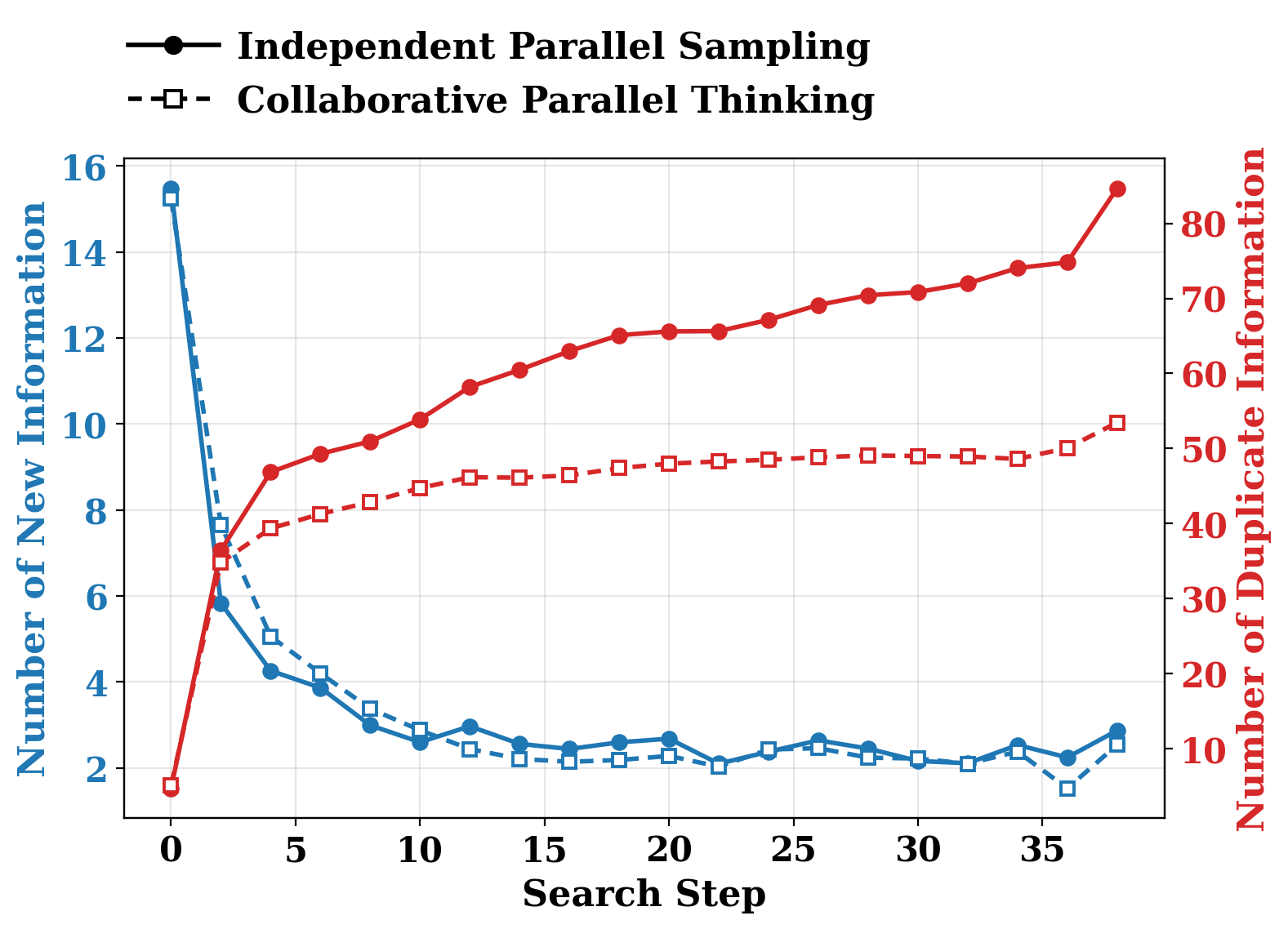
Figure 1: Duplicate and new information statistics during parallel search show the growing redundancy in independent parallel sampling versus CPT.
The Collaborative Parallel Thinking (CPT) Framework
CPT is a training-free inference protocol designed to enable information sharing across parallel reasoning branches. The framework is characterized by three principal components:
- Collaborative Parallel Search: Each of K branches maintains its private reasoning trace, but at fixed-token steps, a synchronization event occurs.
- Shared Information Pooling: After each synchronization, every branch extracts compact, decision-relevant intermediate information (e.g., constraints, intermediate results, pitfalls), which is merged into a deduplicated, query-level information pool. Overlapping entries are filtered using embedding-similarity-based semantic clustering.
- Adaptive Broadcast Scheduling: The broadcast of pooled information back to branches is triggered adaptively, based on diminishing marginal gain in new information. Synchronization begins once redundancy increases and stops when additional sharing yields negligible new discoveries.
The shared pool is injected into each branch's input at designated steps as optional guidance, enabling branches to utilize discoveries made elsewhere while preserving reasoning trajectory diversity. This process transforms the isolated branch search into a collaborative process that accelerates global decision information acquisition and mitigates redundant exploration.
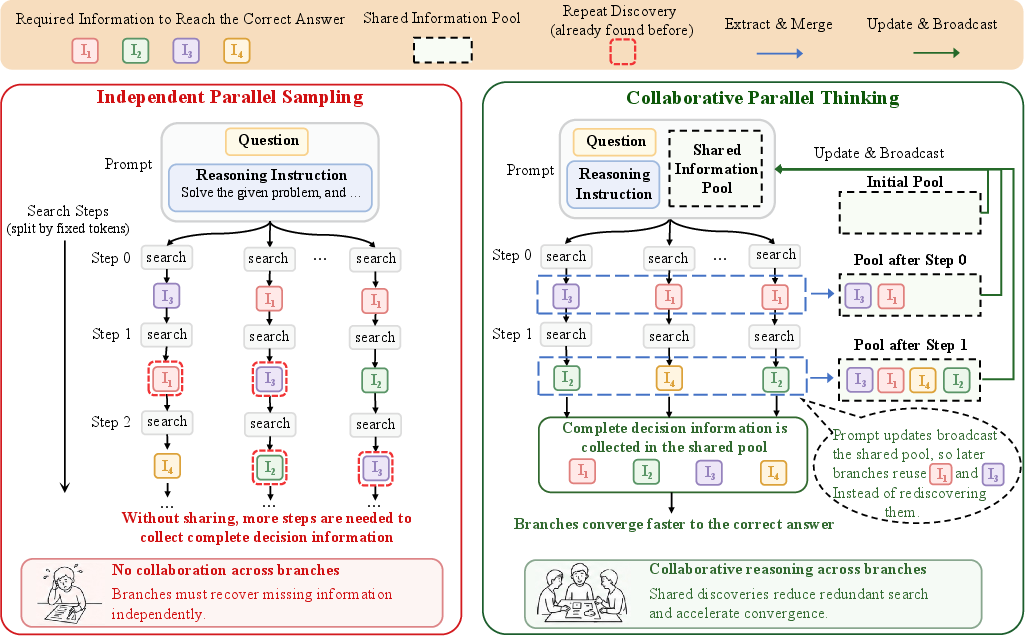
Figure 2: CPT's search-time collaboration: information units discovered by branches are pooled, deduplicated, and broadcast to all branches, enabling convergence with less redundant exploration.
Empirical Results: Accuracy, Efficiency, and Redundancy Mitigation
CPT was evaluated using the HMMT and AIME competition mathematics benchmarks, with multiple LLM backbones and a spectrum of rollout budgets. The key result is a consistent shift of the accuracy-latency Pareto frontier against strong parallel TTS baselines (e.g., DeepConf, LeaP), as shown in Figure 3.
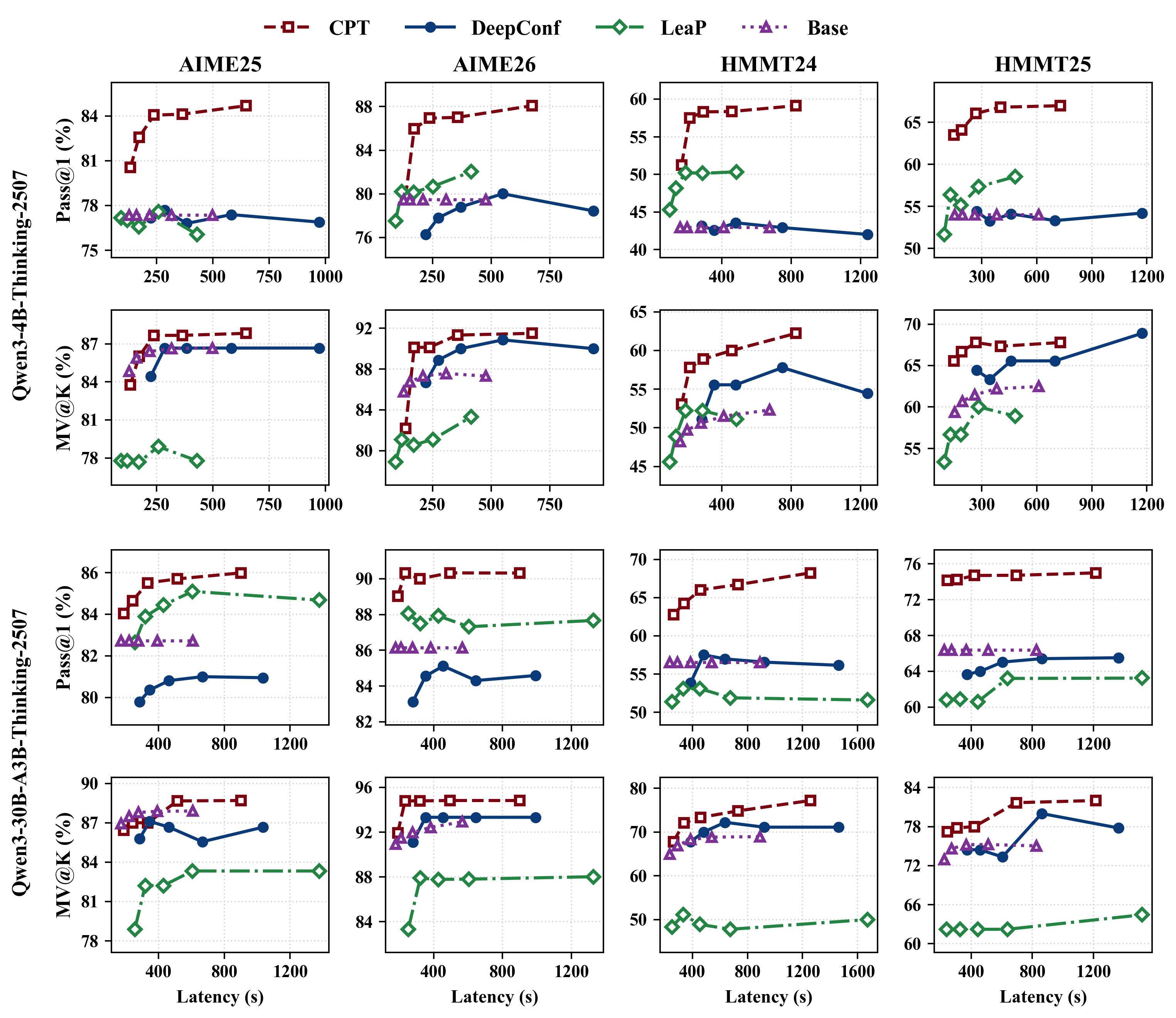
Figure 3: CPT establishes a stronger accuracy-latency Pareto frontier across all tested benchmarks, consistently outperforming baselines.
The mechanism behind these gains is further clarified by:
- Accuracy–Tokens Analysis: CPT yields better accuracy per generated token (Figure 4), confirming improved token-efficiency via reduced redundant computation.
- Accuracy–FLOPs Analysis: While CPT improves total latency and token-efficiency, its prompt-level broadcast incurs overhead in standard decoding backends, suggesting room for future improvement in FLOPs efficiency (Figure 5).
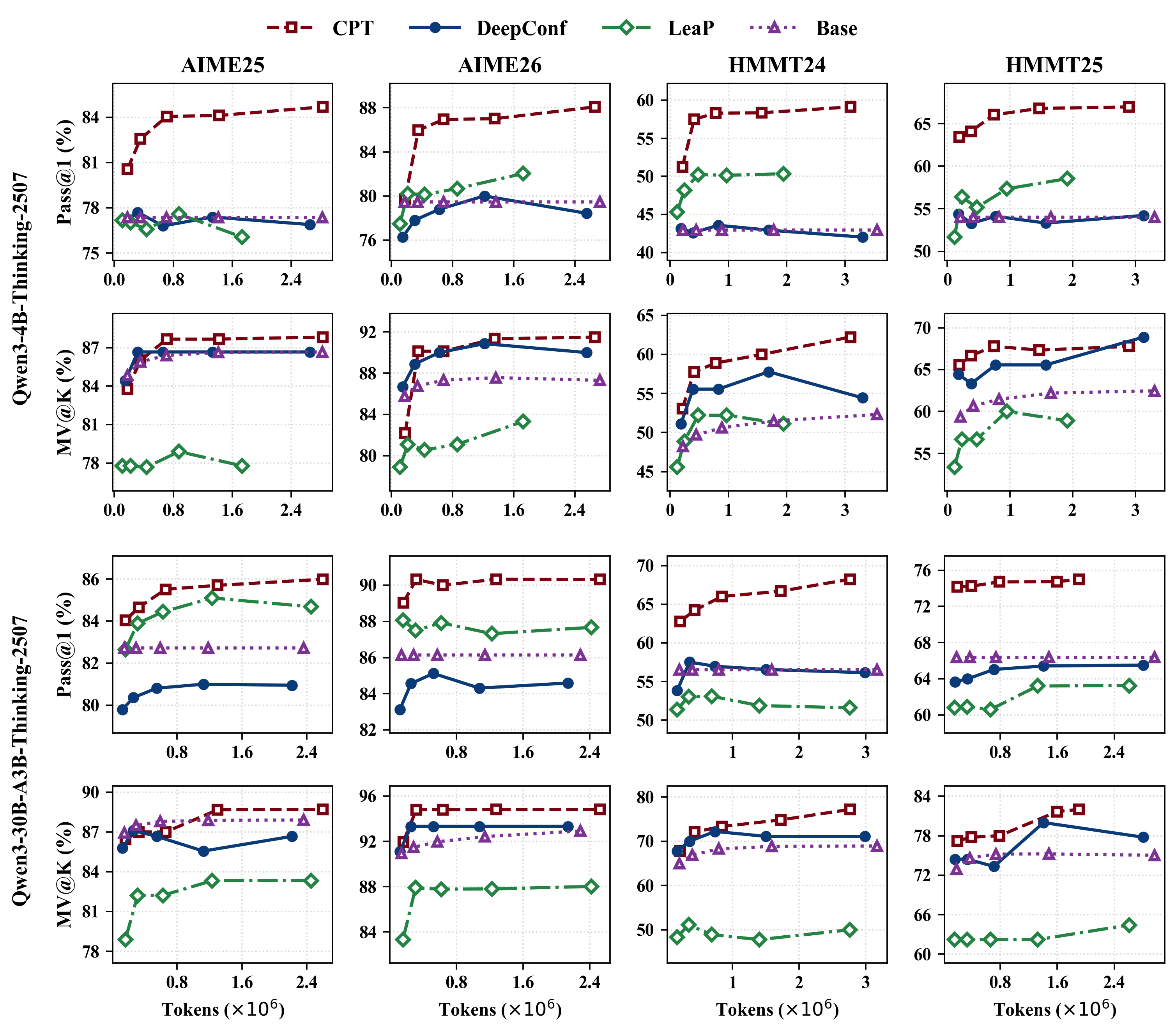
Figure 4: CPT delivers a stronger accuracy-token trade-off, reducing unnecessary decoding steps compared to baselines.
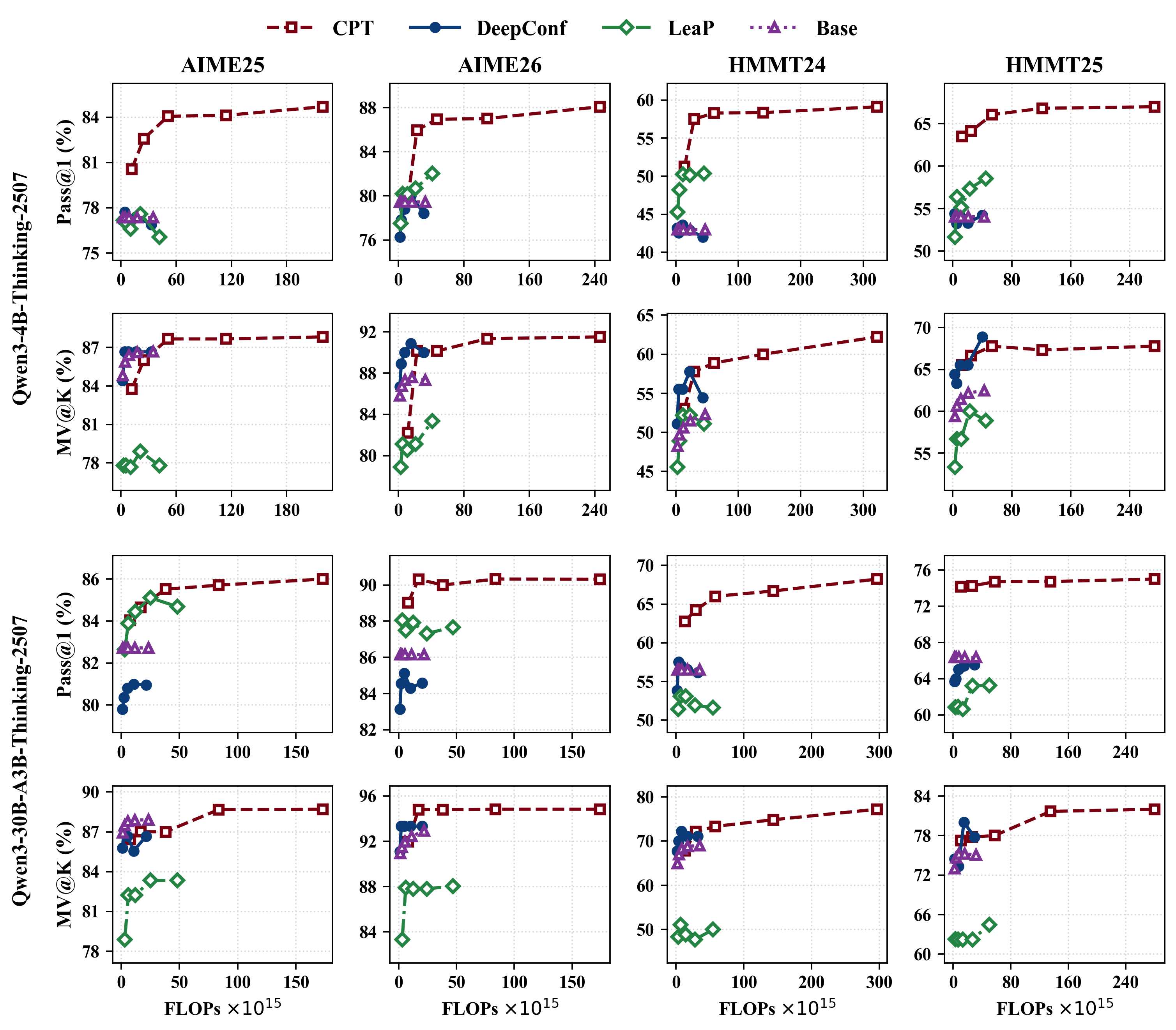
Figure 5: FLOPs-based analysis shows CPT's computational trade-offs; further optimization is possible with cache-aware implementations.
Supplementary results demonstrate:
- Reduction in duplicate findings: CPT maintains high rates of novel discoveries per search step, while sharply reducing rediscovery (Figure 1), affirming that performance gains are due to more effective global information pooling rather than premature branch alignment.
- Hyperparameter Robustness: CPT exhibits stability across broadcast size and deduplication-threshold settings. Best results are observed with a moderate broadcast size (M=512) and a deduplication threshold (Tdup=0.75).
The paper presents an information-theoretic analysis, formalizing how aggregate path-wise information in independent branches is inflated by redundant discoveries, while CPT converts path-local discoveries into pooled, decision-relevant information. Under conditional independence, the effective information gain of K parallel branches is severely limited by redundancy and correlation. The analysis shows that collaborative pooling and deduplication improve the effective parallel width by lowering the total correlation among branch-level findings.
Practical Implications and Future Directions
Practical Impact
CPT demonstrates that training-free, search-time collaboration can significantly enhance the efficiency and efficacy of LLM reasoning under parallel TTS, without necessitating architectural modifications or additional training. The protocol is directly applicable in high-throughput inference settings and can be integrated with diverse backbone models for automated theorem proving, competition math, or other compositional reasoning tasks.
Theoretical Insights
This work highlights that the bottleneck in parallel TTS is not mere lack of exploration width, but rather inefficient information utilization due to search-time isolation. The CPT principle—share more, search less—suggests a paradigm-shift in large-scale inference from brute-force sampling to coordinated, knowledge-sharing processes.
Limitations and Future Work
CPT currently incurs context-update and synchronization overhead at each broadcast step, sometimes requiring prompt re-prefilling. The design is synchronous at fixed-token steps, such that intra-step discoveries cannot immediately benefit other branches. Future research could focus on:
- Cache-aware or attention-level context injection to reduce FLOPs overhead.
- Finer-grained, possibly asynchronous, information sharing to further accelerate convergence.
- Extension to other domains where intermediate knowledge units could be profitably extracted and shared.
Conclusion
CPT addresses the inefficiency introduced by information-isolated parallel branch exploration in TTS, introducing a practical and theoretically sound framework for collaborative, information-sharing search. Empirical evidence confirms improved accuracy-latency and accuracy-token trade-offs across benchmarks and model scales. The work indicates that the next phase of LLM reasoning efficiency will depend not only on scale, but on real-time, structured collaboration among inference trajectories.

