- The paper demonstrates that fine-tuning multilingual LLMs paired with Layer Swap reduces the native reasoning gap to as low as 1.9–3.5%.
- The methodology includes constructing high-quality multilingual datasets, rigorous benchmark evaluation, and weight-space analysis to validate the swap technique.
- Layer Swap boosts reasoning accuracy while maintaining native chain-of-thought fidelity, with significant improvements observed in low-resource languages like Swahili.
Rethinking the Multilingual Reasoning Gap in LLMs via Layer Swap
Introduction and Motivation
Current multilingual LLMs for complex reasoning—across mathematics, code, and science—default to producing chain-of-thought (CoT) traces in English, regardless of the input language. This "English-pivoted" mode is prevalent due to observed performance drops when constraining the model to reason natively in non-English languages. However, most prior assessments of the so-called native reasoning gap are based on inference-time interventions or fine-tuning on insufficient native data, offering an incomplete perspective on the true extent and nature of the gap.
The paper "Rethinking the Multilingual Reasoning Gap with Layer Swap" (2605.26735) systematically revisits this question, assembling large-scale, high-quality multilingual reasoning datasets across six typologically diverse languages. It rigorously measures the native reasoning gap under matched fine-tuning supervision and introduces a novel application of "Layer Swap"—transferring the English specialist's middle transformer layers into the native specialist—to close this gap with negligible loss of native-language CoT fidelity.
Experimental Setup and Dataset Construction
Data Generation and Filtering
A high-coverage, long-context (up to 32k tokens) reasoning corpus was constructed for English, French, German, Spanish, Chinese, and Swahili, drawing from the allenai/Dolci-Think-SFT-32B dataset as source. Translations into the five target languages were performed using the google/gemma-3-27b-it model via chunk-wise translation of prompts, reasoning traces, and answers, followed by rigorous artifact filtering (e.g., compression ratio anomalies, length deviations, context overflow). The resulting datasets achieved parity in sample counts and token budgets, crucial for a controlled native-vs-pivoted comparison.
Evaluation Benchmarks
Five demanding benchmarks were selected: MGSM-Rev2 (math), Global-MMLU-Lite (knowledge), GPQA-Diamond (science), AIME 24/25 (advanced math), and HumanEvalPlus (code). All were translated and cross-validated for reasoning trace quality. Benchmarks were evaluated using custom prompt templates for each language.
Native Reasoning Gap under Matched Supervision
Previous work found large performance gaps (e.g., 17–19%) when forcing non-English CoTs, but the present study demonstrates that—given matched large-scale post-training—native specialists across French, German, Spanish, Chinese, and Swahili exhibit only a 1.9–3.5% deficit compared to English-pivoted models, averaged across all tasks.
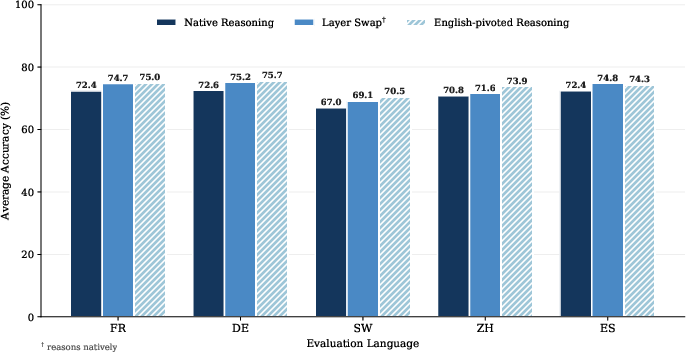
Figure 1: Mean accuracy for native specialists compared to English-pivoted and Layer Swap models across five languages and five benchmarks.
This residual gap is concentrated largely in the most complex mathematics evaluations (AIME), with smaller or negligible discrepancies on other benchmarks. Notably, the benefit of native fine-tuning is most pronounced in low-resource languages, with Swahili specialists nearly doubling the accuracy of English-only models on Swahili benchmarks.
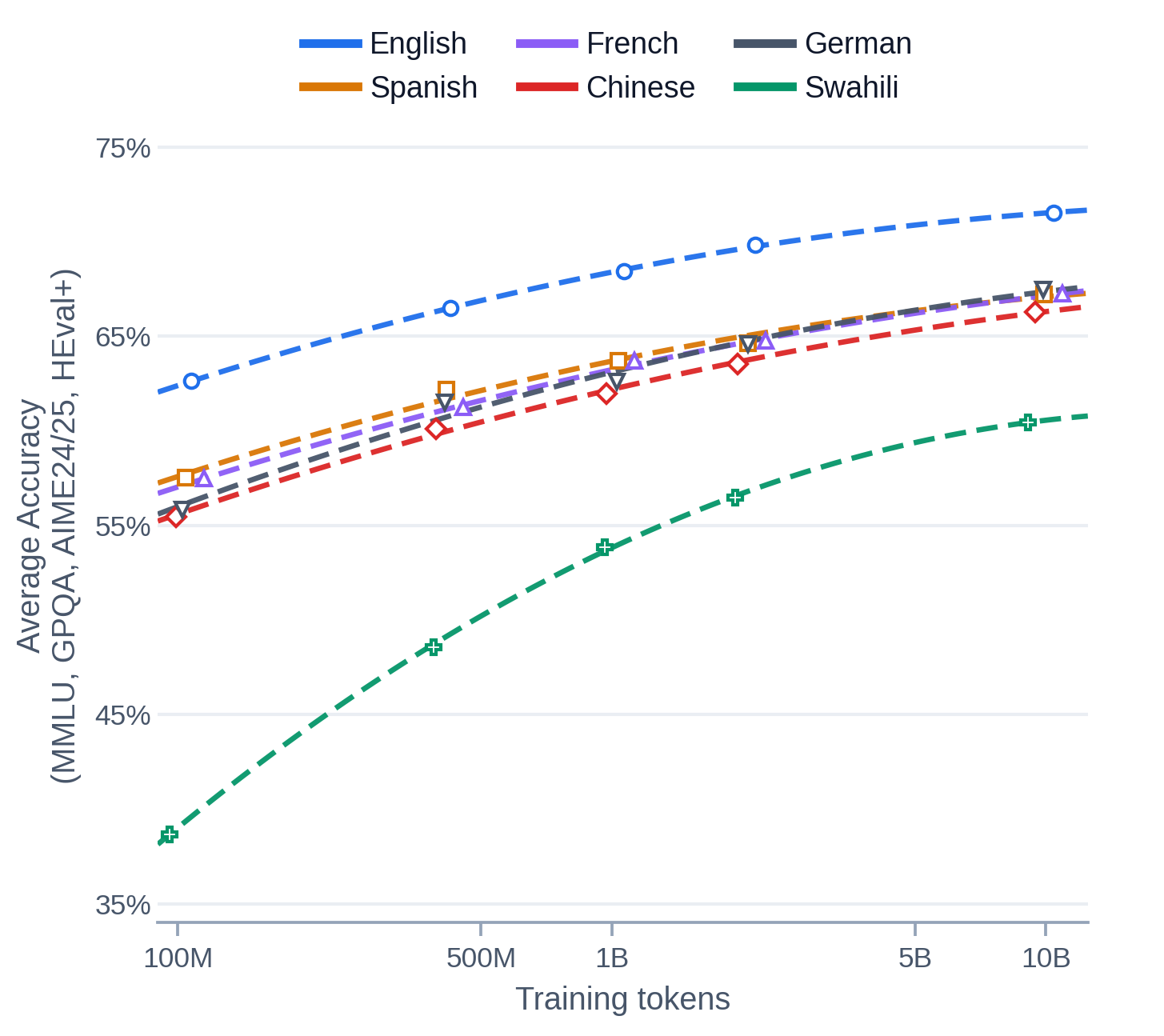
Figure 2: Scaling curves showing native reasoning accuracy as a function of SFT-token budget across six languages.
Scaling analyses show smooth, monotonic advances in accuracy as SFT-token budget increases, across all languages. Resource-rich languages (French, German, Spanish, Chinese) track closely behind English at every budget; Swahili, while lagging, closes a significant portion of its initial gap with sufficient SFT.
Weight-space Analysis and Layer Specialization
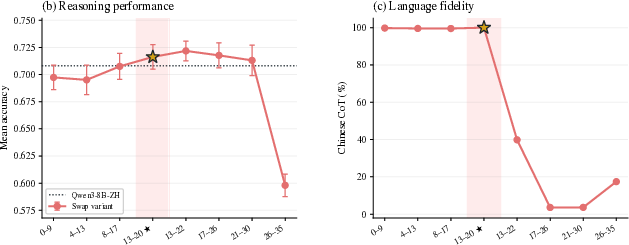
Weight-delta analysis reveals per-language SFT updates are highly aligned in the transformer’s center layers (L13–L22 for Qwen/Qwen3-8B), but diverge towards the input and output layer extremes. Quantitatively, in this mid-stack section, per-layer cosines between SFT deltas and SVD variance ratios indicate a dominant shared cross-lingual direction, suggesting a language-agnostic reasoning core surrounded by language-specific “edges.”
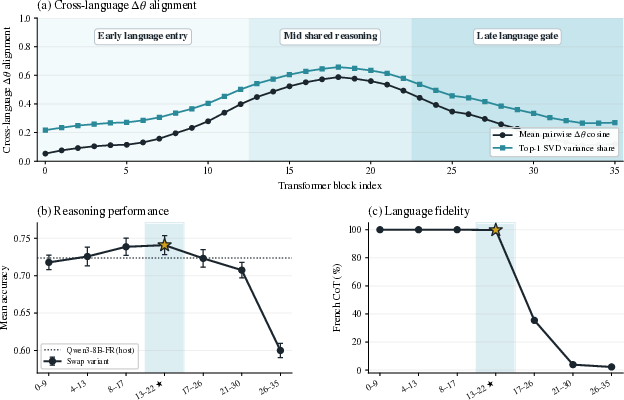
Figure 3: Cross-language alignment of SFT updates highlights mid-stack agreement and outer-layer divergence in weight space.
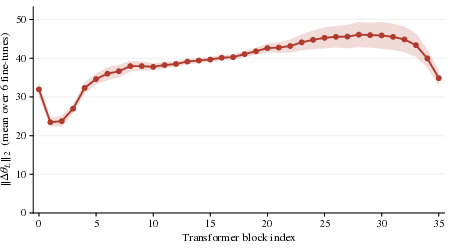
Figure 4: Per-layer L2 norm of language-specific SFT updates is comparable throughout the stack, confirming the mid-stack agreement reflects directionality, not amplitude decay.
Layer Swap: Method and Empirical Outcomes
Building on the observed mid-stack alignment, the study applies "Layer Swap" to construct hybrid models: the native specialist’s input and output layers are retained, but a contiguous mid-stack window (L13–L22, or L13–L20 for Chinese) is transplanted from the English specialist, which is always available in open systems.
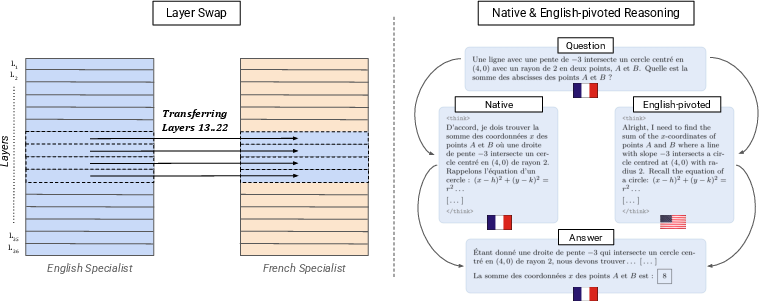
Figure 5: (left) Illustration of Layer Swap, showing the transfer of English specialist’s mid-stack into the native specialist to preserve native CoT and close reasoning gap. (right) Baseline regimes: native reasoning vs. English-pivoted.
This intervention delivers striking results:
An ablation isolating input language from reasoning trace language reveals all non-English specialists score higher when provided English input—despite never seeing English in SFT. The “understanding gap” grows with typological distance and data scarcity, being largest for Swahili.
These findings, in line with logit- and activation-lens probing studies, reinforce the conclusion that multilingual LLMs' representational geometry and data distribution favor English-aligned processing cores, independent of output CoT language [wendler2024llamas, schut2025multilingual].
Implications and Future Directions
Practical Implications
- With strong numerical evidence, the study demonstrates that the performance penalty for enforcing native-language CoT can be minimized via proper SFT and architectural insights.
- Layer Swap offers a practical, training-free recipe to build native-reasoning LLMs in any language for which (a) a matching fine-tuned native specialist and (b) an English specialist exist—a near-universal property in open-source ecosystems.
- Deploying such models can greatly enhance interpretability, inclusivity, and cultural alignment for non-English users, with minimal engineering cost.
Theoretical Significance
The paper provides new evidence for a modular functional decomposition in LLMs: language-specific representations are handled at the stack’s edges, while central layers implement abstract reasoning, acting as a language-agnostic “core.” This architecture is consistent with findings from both probing and arithmetic model-merging literature [bandarkar2024layer, tang2024language, ilharco2023editing].
Limitations
Key limitations include confinement to one model family (Qwen/Qwen3-8B-Base), a non-exhaustive language set, and potential constraints arising from machine-translated corpora and tokenization inefficiencies. The training regime relies on SFT (supervised fine-tuning); additional advances could be realized by integrating RL or preference optimization. Further, the precise boundaries and optimality of Layer Swap windows might be model- and language-specific.
Conclusion
This study empirically and mechanistically redefines the native multilingual reasoning gap in LLMs, showing that most of the previously reported penalties arise from inadequate fine-tuning rather than inherent architectural or data limitations. By analytically dissecting and leveraging the architecture’s internal modularity through Layer Swap, native reasoning models can be constructed with near-parity to English-pivoted models, without sacrificing language fidelity in CoT.
The work bridges experimental rigor with actionable interventions, providing both a refined understanding of multilingual LLMs and a straightforward recipe for extending equitable reasoning capabilities to a diverse range of users. Extending this paradigm to broader model families, more languages, and coupling with preference optimization highlights rich directions for future research in multilingual AI.