- The paper demonstrates that LLMs can be rewired using a two-stage SFT+RL pipeline to reason exclusively in target languages without performance degradation.
- The methodology fine-tunes LLMs on a high-quality, parallel multilingual corpus and employs reinforcement learning with verified rewards to recover lost performance.
- The analysis reveals that early-to-mid transformer layers serve as a bottleneck for language routing, enabling efficient, minimal modifications for non-English reasoning.
Multilingual Reasoning Language Control in LLMs: Analysis and Implications of ReasonXL
Introduction
ReasonXL addresses a core deficiency in the current architecture and training paradigm of LLMs: the dominance of English as the default internal reasoning and explanation language, even under non-English prompts. This English-centric behavior introduces a mismatch between user expectations and model output, and can attenuate user trust, interpretability, and the quality of downstream supervision in multilingual contexts. The research presents three central contributions: (i) a large-scale, cross-domain, parallel corpus of reasoning traces in five European languages; (ii) an empirical demonstration that LLMs can be accurately and durably rewired to reason fully in a target non-English language through a two-stage training pipeline without sacrificing performance; and (iii) an in-depth representational analysis elucidating where and how this kind of language identity is encoded and causally gated within the model's architecture.
ReasonXL Corpus Construction
The ReasonXL corpus establishes a new resource for supervised multilingual reasoning. It consists of over two million high-quality, balanced reasoning samples per language—English, German, French, Italian, and Spanish—gathered and curated from ten upstream sources, including Nemotron, Olmo, and parallelized through LLM-based high-fidelity translation with strict constraints on terminology, notation, and cultural adaptation. Each triple includes the user input, a detailed reasoning trace, and final answer/output, with extensive property metadata facilitating domain- and quality-aware filtering.
This corpus is designed to fit rigorous downstream training and analysis needs (dense, high-value, information-rich, and domain-diverse), mitigating dataset imbalance and annotation noise. Critically, because all translations are strictly parallel at the prompt-reasoning-output level, the setup supports controlled cross-lingual transfer and mechanistic probing.
Multilingual Reasoning Language Adaptation Pipeline
ReasonXL demonstrates direct controllability of the reasoning language, operationalized on the open-source SmolLM3-3B architecture. The pipeline consists of two sequential adaptation phases for each target language:
- Supervised Fine-Tuning (SFT): The model is fine-tuned on chat-formatted, target-language traces from the ReasonXL split, using only the assistant's reasoning and answers for optimization. This phase enforces surface-level reasoning language compliance but, in isolation, typically degrades science and general-domain task accuracy due to the abrupt representational and procedural shift.
- Reinforcement Learning with Verified Rewards (RLVR/Dr. GRPO): Starting from the SFT checkpoint, RL is performed on translation-augmented, verifiable tasks (e.g., MATH, GSM8K), with a composite reward function over answer correctness, language ID, output format, and (in some cases) naturalness and anti-repetition penalties. This stage recovers the performance lost in SFT and robustly consolidates target-language reasoning behavior.
The central empirical finding is that, for all four non-English targets, the two-stage SFT+RL procedure yields LLMs that—unlike the standard baseline—reason exclusively in the target language, while matching or exceeding the base model's performance on both in-domain (science/math) and out-of-domain (language understanding, region-specific) benchmarks. This demonstrates that the language used for on-chain reasoning is not inherently tied to high task performance; the prevailing English dominance is not required for accuracy under sufficient supervisory signal and proper adaptation schedule.
Notably, RLVR (Dr. GRPO) recovers the SFT-induced performance drop with only minor parameter updates and maintains high faithfulness to the target language (100% compliance on reasoning traces and answers). General English knowledge retention is strong; knowledge drift is modest (≤ ~3 points drop on standard English knowledge benchmarks), indicating that language routing changes do not catastrophically affect general factual competence.
Cross-lingual probing further reveals non-monotonic transfer: for some adaptation languages (German, Italian), non-target languages even see improved performance, while English typically declines, suggesting the underlying representations remain largely language-agnostic except for the controlled reasoning modality.
Mechanistic Analysis: Where and How Language Is Routed
ReasonXL delivers a fine-grained representational investigation using both weight and activation analyses. The adaptation effect is highly layer-localized:
- Weight Changes: Attention and MLP modules show the predominant magnitude of parameter shift in the deepest layers, especially under SFT. RL-induced updates are much smaller and more diffuse, refining rather than reparametrizing the system.

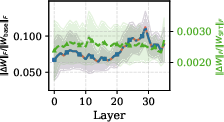
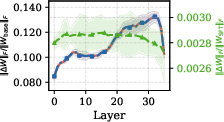
Figure 1: Attention head weight changes concentrate in the uppermost transformer layers during adaptation, signifying late-stage representational specialization.
- Activation Drift: Activation cosine similarity profiles (between base and adapted checkpoints) indicate a pronounced, narrow drift valley at early-to-mid layers (6–8), signaling a strong representational shift specific to target-language steering. Despite the bulk of weight changes accumulating later, this bottleneck controls the locus of language routing.
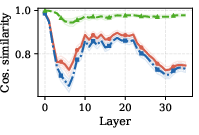
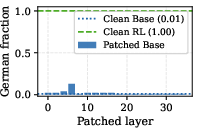
Figure 2: Cosine similarity of last-token activations demonstrates a sharp divergence from the base model in early-to-mid layers, exposing a representational bottleneck responsible for the output language.
- Causal Patching: Single-layer patching—replacing the base model's activations with those from the adapted model at layer 6–8—injects target-language reasoning into the base model's output, leaving other layers inert in this regard. Only these bottleneck layers causally set reasoning language, while deeper layers refine content fluency and logic within the chosen language stream.
Theoretical Implications and Directions
The findings challenge previous assumptions that LLMs must reason in English for maximal performance and that reasoning language shifts require prohibitively large and disruptive changes. Instead, they demonstrate that targeted, stage-wise post-training—supported by high-quality multilingual CoT corpora—can robustly transplant the surface reasoning language without degrading the latent cognitive capabilities or general knowledge.
Mechanistically, these results support a division of labor in transformer depth: early-to-mid layers act as hard routing gates for reasoning language, while upper layers adaptively optimize within that setting. This suggests that efficient language adaptation can be achieved using parameter-efficient or even neuron-level interventions at identified “language bottleneck” layers, informing future approaches such as selective LoRA, activation steering, or minimal circuit editing.
Practically, these insights underpin more interpretable, user-trustworthy, and locally regulated AI deployments, where in-language reasoning and explanations are crucial for oversight and regulatory compliance.
Conclusion
ReasonXL proves that LLMs can be durably and efficiently shifted to reason in any sufficiently supervised target language without incurring accuracy loss—contradicting the default English-centric paradigm. The release of the ReasonXL parallel corpus and associated models provides the community with a foundation for rigorous cross-lingual reasoning studies, mechanistic circuit mapping, and direct control over the internal linguistic substrate of LLMs. The presented mechanistic evidence opens the way to highly targeted, data- and parameter-efficient adaptation strategies and supports a broader vision for universally accessible, multilingual, and culturally contextualized AI systems.

