Transformers Can Learn Posterior Predictive Distributions In-Context
Abstract: Prior-data fitted networks (PFNs) have recently emerged as a powerful approach for Bayesian prediction tasks, approximating the posterior predictive distribution (PPD) through in-context learning. Despite their strong empirical performance and ability to go beyond point predictions, theoretical understandings of the algorithmic capability of transformers to learn distributions in context are still lacking. Focusing on Gaussian process regression problems, we show by construction that transformers can implement a gradient descent algorithm targeting the posterior predictive mean and variance, followed by nonlinear mappings that yield binned probabilities of PPD. We study the error bounds of the approximated PPD in terms of attention depth and bin resolution. Based on these results, we further demonstrate the key role of normalization and the choice of attention depth in enabling the extrapolation abilities of transformers beyond the pretraining sample size range. We conduct simulations that corroborate our findings, providing insight into the expressivity of PFNs targeting PPDs and how architectural choices may influence generalization capabilities.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a neat question: can a Transformer (the kind of AI model behind chatbots) learn not just a single best answer, but a full range of likely answers and how confident it is—just by looking at examples placed in its input? The authors show that the answer is yes. They prove and test that a Transformer can learn the whole “posterior predictive distribution” (PPD), which is a fancy name for “the full curve of how likely each possible answer is,” using only in-context learning (no weight updates at test time).
They focus on a common prediction setup called Gaussian process (GP) regression, where the exact PPD is known, so they can check the Transformer’s output precisely.
Key Questions
The paper asks simple but important questions:
- Can a Transformer compute not only a point prediction, but the whole probability distribution of outcomes in context?
- How does the number of attention layers (depth) affect how accurate that learned distribution is?
- Why do some Transformers keep working well when they see more examples at test time than they saw during training?
- What role does “normalization” inside attention play in making that generalization stable?
Methods Explained Simply
Here are the main ideas, using everyday language and analogies.
- In-context learning (ICL) and PFNs:
- Think of the Transformer as a student who learns from examples written on the test sheet itself. It doesn’t change its brain (weights) at test time; it just reasons from the examples it sees.
- Prior-data fitted networks (PFNs) are Transformers pre-trained on lots of synthetic tasks so they learn how to read a small training set and make predictions in one forward pass.
- Gaussian process (GP) regression:
- Imagine you’re trying to guess the height of a smooth hill at a new spot, based on heights measured at nearby spots. GP regression gives you:
- A best guess (the mean).
- Uncertainty around that guess (the variance).
- The PPD is the full picture: all possible heights and how likely each one is.
- Transformer as a step-by-step calculator:
- The authors show that a Transformer’s attention layers can act like a calculator that repeatedly refines an answer—similar to taking small steps downhill to reach the bottom of a valley (a process like gradient descent).
- Each attention layer is one “step” in this solver. More layers = more steps = a more accurate answer.
- Using these steps, the Transformer can compute both the mean (best guess) and the variance (uncertainty) of the GP’s PPD.
- From “moments” to the full distribution:
- Moments are summary numbers like the mean and variance.
- To turn moments into a full distribution, the model uses a small neural head (an MLP) to output probabilities over a set of “bins,” like a fine-grained histogram. More bins = more detail.
- This binning uses a softmax so the probabilities add up to 1. The paper also trims extreme tails (very unlikely values) to keep things practical.
- Normalization (why it matters):
- Attention “normalization” means dividing each token’s attention weights by their total, making them behave like percent weights that sum to 100%.
- This is like adjusting your steps to the terrain so you don’t trip when the dataset (number of examples) gets bigger. In math, this is a form of “preconditioning” that keeps the solver stable across different sample sizes.
Main Findings
Here are the major takeaways, summarized for clarity:
- A Transformer can learn the whole distribution in context:
- Construction result: the attention stack can implement a step-by-step solver that computes the GP mean and variance; the MLP head turns these into binned probabilities.
- Error control: the main error shrinks quickly as you add more attention layers (more steps), and it also shrinks as you use more bins. The total error comes from:
- Solver inaccuracy (fixed by more layers).
- Coarse bins (fixed by more bins).
- Tiny tail mass outside the chosen range.
- A small MLP approximation error.
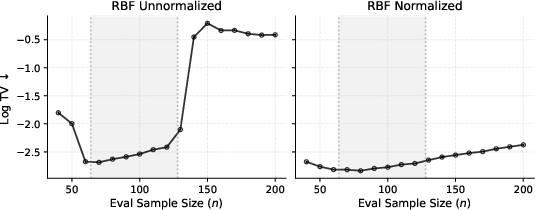
- Normalized attention is key for generalizing to new sizes:
- Without normalization, the “safe step size” for the solver shrinks as the number of examples grows, which can make the process unstable or too slow.
- With normalization (preconditioning), the solver stays stable even when you test on bigger datasets than seen during pretraining. This is crucial for real-world use.
- Bigger datasets need deeper models:
- As the number of examples grows, the underlying math problem gets harder to solve quickly. That means you need more attention layers (more solver steps) to reach the same accuracy.
- For common smooth kernels (like the RBF kernel), the needed depth grows roughly linearly with the dataset size if you want a fixed accuracy.
- Experiments match the theory:
- Increasing attention depth and bin count reduces the gap to the true PPD, just as predicted.
- Normalized attention keeps performance stable when tested on larger sample sizes than used in training; unnormalized attention often fails.
- Deeper models and training on a wider range of sample sizes both improve generalization.
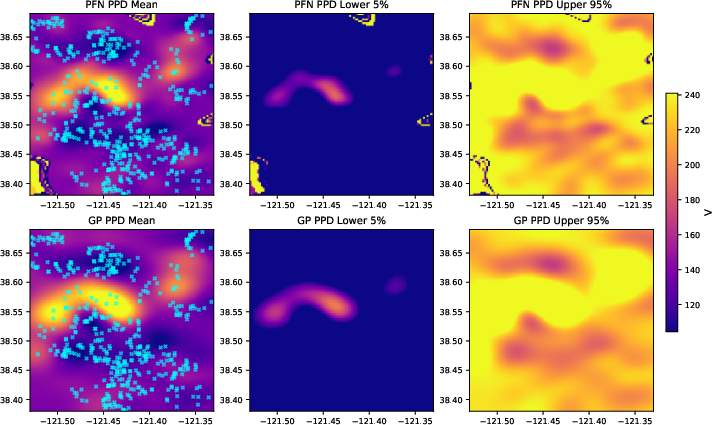
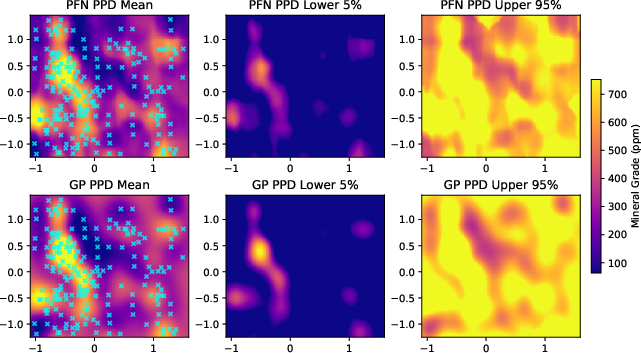
- On a real housing dataset, the PFN’s predicted means and 5%/95% quantiles closely track those of an exact GP, except in areas with almost no data—exactly where uncertainty should grow.
Why This Matters
This work explains how and why Transformers can deliver fast, high-quality uncertainty estimates “on the fly,” which is valuable when you need both a guess and a sense of confidence:
- Faster decisions with uncertainty: Great for tasks like Bayesian optimization, scientific modeling, and risk-aware predictions, where you need probabilities, not just a point.
- Practical guidance for building better PFNs:
- Use attention normalization to handle a wide range of dataset sizes safely.
- Add attention depth to improve accuracy and to cope with larger datasets.
- Use enough output bins to capture fine details of the distribution.
- Foundations for broader models:
- The approach suggests paths to mixtures of models (e.g., multiple GP components using multi-head attention) and potentially to non-Gaussian problems that still rely on iterative summaries.
Limitations and Future Directions
- The proofs focus on Gaussian process regression because it has a known “correct” answer to compare against.
- The paper shows Transformers can do this in principle and in controlled experiments; it doesn’t guarantee that any training recipe will always discover the exact mechanism.
- Extending to more complex priors and non-Gaussian data is promising but will require additional work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete enough to guide follow-up research.
- Formal learning guarantees: The results are constructive (existence) but do not prove that standard PFN pretraining will reliably discover the proposed iterative-solver mechanism; a theory linking optimization dynamics to the constructive solution remains absent.
- Beyond GP priors: The work is limited to GP regression (Gaussian likelihood). It lacks a theory and empirical validation for non-Gaussian likelihoods (e.g., classification, count data), latent GP models, and general Bayesian models where PPDs are not in closed form.
- Hyperparameter uncertainty: The analysis assumes fixed GP hyperparameters and noise variance. There is no mechanism or error analysis for in-context estimation or marginalization over hyperparameters, nor for hierarchical GPs beyond a brief “in principle” sketch.
- Mixture modeling: The multi-head extension for finite mixtures (hierarchical GPs) is suggested but not worked out; explicit constructions, convergence rates, and guarantees for approximating mixture weights are missing.
- Standard transformer attention: The construction uses kernelized attention and sum-normalization. The relationship to standard dot-product attention with softmax (and typical transformer stacks used in PFNs) is not analyzed, including whether and when dot-product softmax implicitly implements the required preconditioning.
- Negative or indefinite kernels: Normalization-based preconditioning is developed for strictly positive kernels (e.g., RBF). It is unclear how to extend the approach to linear or polynomial kernels that induce signed/indefinite Gram matrices, and what normalization or preconditioning schemes are appropriate there.
- Solver choice and acceleration: Only Richardson iteration is considered. Whether transformers can implement faster or better-conditioned solvers (e.g., conjugate gradient, Chebyshev acceleration, momentum-based methods) and how that affects required depth and generalization is unaddressed.
- Adaptive step sizes: The analysis assumes fixed step sizes (per layer). How transformers could learn and adapt step sizes in-context (as a function of spectra proxies, n, or token statistics) to improve stability and speed is not explored.
- Depth scaling practicality: The sufficient condition L ≳ n·log(1/ε) may be impractical for large n. The paper does not quantify realistic limits for L (memory/compute, optimization stability) or propose architectural alternatives that reduce depth requirements.
- Dimensionality scaling: The theory and experiments focus on moderate d. There is no analysis of how eigenvalue scaling, solver stability, and required depth change with increasing d, or of the interaction between d and n.
- Input distribution shift: Most theory assumes Gaussian covariates. Robustness to other input distributions (heavy-tailed, bounded, multimodal) and the resulting changes in spectrum and step-size bounds are not analyzed beyond limited covariate-shift experiments.
- Output discretization design: The MLP head uses equidistant bins and midpoint approximation. There is no study of non-uniform/adaptive binning, learned bin boundaries, or alternative density parameterizations (mixture models, splines, normalizing flows) and their impact on TV error and calibration.
- Truncation and tails: The approach relies on truncating y to (a, b] with small tail mass ε. How to set (a, b] in practice for heavy-tailed or skewed PPDs, and the sensitivity of calibration and coverage to tail choices, is not investigated.
- Calibration under extrapolation: While interval coverage is evaluated, systematic study of PPD calibration (e.g., PIT histograms, tail coverage) under extrapolation (far from context, sparse regions) and out-of-range n is limited.
- Role of architectural components: Token embeddings, multi-head attention, and layer normalization are stated to “increase expressivity” but their concrete effects on solver implementation, preconditioning, and n-generalization are not theoretically or empirically characterized.
- Preconditioning choices: Only Jacobi (row-sum) preconditioning via attention normalization is studied. Other preconditioners (e.g., diagonal-plus-low-rank, incomplete Cholesky) and whether they can be implemented in attention—and improve n-generalization—remain unexplored.
- Learning over n ranges: The paper shows benefits of wider pretraining ranges but does not analyze optimal sampling distributions over n, curriculum strategies, or how to weight tasks to improve both stability and solver convergence across n.
- Multiple queries and batching: The construction targets a single query token. How the mechanism scales to batched queries, streaming contexts, or dynamic insertion/removal of tokens and its effect on convergence is not studied.
- Robustness to misspecification: There is no analysis of PFN behavior when the true data-generating process violates GP assumptions (non-stationarity, heteroscedasticity, discontinuities), including the failure modes and remedies.
- Error constants and tightness: The TV bound combines terms e{-(1−ρ)L}, δ_MLP, 1/C, and ε_tail, but constants and tightness are not quantified. Practical guidance for selecting L, C, and MLP width to achieve target TV thresholds is lacking.
- Moment-to-density mapping: Theoretical guarantees rely on exponential-family structure. How to map moments or other summaries to non-exponential-family PPDs and what statistics the MLP should learn (beyond T(y) = (y, y2)) is not addressed.
- Spectral proxies in practice: The analysis depends on Gram spectra, which are not observable at inference. Methods for transformers to estimate or proxy spectral quantities in-context (e.g., via attention scores) to adjust behavior are not proposed.
- Computational cost and memory: The work acknowledges pretraining range constraints but does not provide a quantitative analysis of training/inference cost versus L, C, and n, nor memory bottlenecks and engineering strategies to mitigate them.
- Real-world validation breadth: Empirical results are primarily synthetic (Gaussian design) with a single spatial dataset illustration. Broader real-data evaluation across diverse tasks, kernels, and likelihoods is needed to validate generality.
- Failure analysis in sparse regions: Figure 1 notes PFN deviations where no nearby observations exist. A systematic study of extrapolation failure modes and architectural/training remedies (e.g., priors, uncertainty inflation) is absent.
- Integration with state-of-the-art PFNs: The simplified architecture differs from TabPFN variants. How the proposed mechanisms map onto those models, and whether their additional components aid or hinder solver-like behavior, remains to be determined.
Practical Applications
Immediate Applications
The following use cases can be implemented with current PFN and transformer tooling by adopting the paper’s design guidance (normalized attention as preconditioning, sufficient attention depth, appropriate binning/truncation) and training on synthetic priors (e.g., Gaussian processes) representative of the target domain.
- Fast, uncertainty-aware surrogate modeling for GP regression
- Sectors: geospatial/environment (kriging, housing prices), manufacturing (process modeling), energy (forecasts/simulation surrogates), healthcare (risk curves), finance (return/volatility surfaces).
- Workflow/product: Pretrain a transformer-based PFN on synthetic GP data; at inference, feed a context dataset and query features to obtain full posterior predictive distributions (PPDs), quantiles, and credible intervals without retraining or MCMC. Deploy as a microservice/API that outputs binned predictive densities and summary intervals.
- Assumptions/dependencies: A reasonable prior predictive simulator (e.g., GP kernel and noise) is available; choose truncation interval (a,b] and bin count C large enough for tails and resolution; use normalized attention and sufficient depth L for the target sample size n to ensure stability and accuracy.
- Drop-in PFN surrogate for Bayesian optimization (BO) with acquisition functions
- Sectors: materials discovery, robotics/control tuning, chip design, A/B testing.
- Workflow/product: Replace GP surrogates with PFNs that directly output mean/variance and quantiles needed for EI/UCB/PI; leverage the paper’s result that attention computes PPD moments in-context and that accuracy improves with depth and bin count.
- Assumptions/dependencies: Pretrain on function classes reflective of the task; calibrate acquisition outputs under domain shift; normalized attention to generalize across varying batch sizes n.
- Sample-size–robust PFN design for tabular AutoML and MLOps
- Sectors: software/ML engineering.
- Workflow/product: Adopt normalized attention (Jacobi-like preconditioning) to stabilize across dataset sizes; select attention depth based on expected n (depth grows with n) and increase pretraining range n∈[n_min,n_max] to cover wider spectra; tune bin resolution for desired interval fidelity.
- Assumptions/dependencies: Compute budget for deeper models and broader pretraining; monitoring for coverage and calibration drift.
- Rapid spatial risk mapping with uncertainty for planning
- Sectors: urban planning, public health, environmental monitoring.
- Workflow/product: Train PFNs on spatial kernels (e.g., RBF) and deploy dashboards showing predictive means and 5–95% quantile maps (as in the housing example), updating on-the-fly as new context data arrive.
- Assumptions/dependencies: Appropriate spatial priors/hyperparameters; validate coverage versus held-out observations; careful handling of regions far from observations.
- Real-time, on-device adaptation without retraining
- Sectors: robotics, IoT/edge.
- Workflow/product: Use in-context PFNs to adapt to new tasks/conditions by conditioning on recent examples and returning PPDs for safe exploration and control; integrate with safe-BO or risk-sensitive controllers.
- Assumptions/dependencies: Edge compute and memory for deeper attention stacks; pretraining coverage of operating regimes; normalized attention to ensure stability as context length varies.
- Academic benchmarking and courseware for probabilistic prediction
- Sectors: academia.
- Workflow/product: Use the paper’s constructive approach to build teaching labs that connect attention depth and binning to PPD error; benchmark PFNs on TV distance, interval coverage, and moment errors across L and C.
- Assumptions/dependencies: Availability of synthetic GP data generators; evaluation harnesses for calibration metrics.
Long-Term Applications
These use cases require further research, scaling, or engineering—e.g., broader priors, non-Gaussian likelihoods, improved preconditioning, or regulatory validation.
- PFNs for hierarchical and non-Gaussian Bayesian models
- Sectors: healthcare (classification, survival), spatio-temporal modeling (epidemiology, climate), genomics.
- Workflow/product: Extend to hierarchical GPs via multi-head attention computing component-wise moments and an additional head for mixture weights; map to discretized non-Gaussian PPDs (e.g., logistic/Poisson likelihoods) using the MLP head as a sufficient-statistic mapper.
- Assumptions/dependencies: Training procedures that discover/represent mixtures reliably; approximate-inference targets defined by domain experts; empirical validation of coverage and calibration.
- Scaling PFNs to very large context sizes
- Sectors: finance (tick data), climate/reanalysis, recommender systems.
- Workflow/product: Develop advanced preconditioning in attention (beyond row-sum normalization), dynamic depth or adaptive iteration budgets, curriculum pretraining across n, and sparsity (kernel sparsification, inducing points, or sparse attention).
- Assumptions/dependencies: Algorithmic advances to counter linear growth in required depth with n; memory-efficient architectures; high-throughput pretraining.
- Standardized uncertainty-aware AutoML for probabilistic tabular prediction
- Sectors: software/enterprise ML.
- Workflow/product: Libraries that expose PFN-PPD models with defaults for normalized attention, depth scheduling vs. n, bin calibration tools, and coverage audits; scikit-learn–style interfaces for credible-interval predictions and acquisition scoring.
- Assumptions/dependencies: Domain-specific priors and simulators for pretraining; robust out-of-distribution handling; user education for interpreting probabilistic outputs.
- Regulatory-grade decision support with quantified uncertainty
- Sectors: healthcare, finance, public policy.
- Workflow/product: PFN modules that provide calibrated intervals and traceable uncertainty for decisions (triage, credit risk, resource allocation); pipelines with continual monitoring, revalidation, and dataset-shift detection.
- Assumptions/dependencies: Rigorous validation frameworks (coverage guarantees, fairness audits), documentation of priors and training data, and governance compliance.
- Consumer applications with transparent uncertainty
- Sectors: real estate, e-commerce, personal finance.
- Workflow/product: Apps that surface predictive intervals (e.g., price ranges with probabilities) instead of point estimates, powered by PFN-PPD backends; explainers that connect intervals to context examples.
- Assumptions/dependencies: UX for uncertainty communication; liability and compliance considerations; priors aligned with consumer data distributions.
- Hybrid PFN + classical Bayesian solvers
- Sectors: engineering simulation, scientific computing.
- Workflow/product: Use PFNs to produce high-quality initializations (moments/PPDs) for MCMC/VI to reduce burn-in and variance; fall back to exact methods for final refinement or audit.
- Assumptions/dependencies: Interfaces between PFN outputs and sampling/VI frameworks; guarantees that hybrid pipelines maintain accuracy in edge cases.
- Tooling and diagnostics around n-generalization
- Sectors: ML engineering, research.
- Workflow/product: “n-generalization validators” that stress-test models beyond the pretraining range; depth planners that suggest minimum L given target n and error tolerance; spectral diagnostics based on attention score matrices.
- Assumptions/dependencies: Methods to estimate effective condition numbers from data; integration with training loops to adjust depth or pretraining curricula.
Notes on key dependencies and assumptions across applications:
- Prior misspecification: Performance hinges on how well synthetic pretraining covers real-world function classes and noise levels. Hierarchical or mixture priors can mitigate mismatch but increase complexity.
- Dimensionality: High-dimensional inputs can stress GP priors and hyperparameter realism; structure (e.g., ARD kernels, feature selection) or dimensionality reduction may be needed.
- Discretization/truncation: Binned outputs require careful choice of interval (a,b] and bin count C; heavy tails or extreme values increase C and memory/compute.
- Training discovery vs. existence: The theoretical construction shows capability, not that standard training always discovers it. Empirical evidence is promising, but robust training recipes and diagnostics are essential.
- Generalization in n: Normalized attention (preconditioning) is crucial; required depth grows with n, and broader pretraining ranges improve robustness. Continuous monitoring and capacity planning are advised.
Glossary
- Acquisition functions: Utility functions used in Bayesian optimization to decide where to sample next. "accurately computing common acquisition functions such as expected improvement"
- Attention depth: The number of stacked self-attention layers in a transformer. "report markedly improved accuracy by increasing attention depth to 18 or 24 layers"
- Attention normalization: Normalizing attention weights (e.g., by their sum) to stabilize and precondition computations. "attention normalization is essential for achieving generalization"
- Bayesian linear regression (BLR): A linear regression model with Bayesian treatment of parameters. "Bayesian linear regression (BLR) (, )"
- Bayesian optimization: A strategy for optimizing expensive black-box functions using probabilistic surrogate models. "serve as flexible surrogate models for Bayesian optimization"
- Condition number: The ratio of the largest to smallest singular (or eigen) value of a matrix; measures numerical stability of solving linear systems. "where $#1{cond}(\cdot)$ denotes the condition number"
- Covariate shift: A mismatch between training and test input distributions. "covariate shift experiment in Section~\ref{supp-sec:exp additional}"
- Credible intervals: Bayesian intervals expressing uncertainty about parameters or predictions. "95\% credible intervals of produced by PFNs"
- Empirical Bayes: Estimating prior hyperparameters from data before Bayesian inference. "an empirical-Bayes Gaussian process (GP)"
- Expected KL divergence: The expectation of Kullback–Leibler divergence used as a training objective. "This is equivalent to minimizing the expected KL divergence between PPD and "
- Exponential family: A class of distributions with densities of the form exp(⟨natural parameter, sufficient statistic⟩ − log-normalizer) times a base measure. "consider a one-dimensional exponential family density "
- Gaussian design: A setting where covariates are sampled from a Gaussian distribution. "Under the Gaussian design, for both linear and RBF kernels"
- Gaussian process (GP): A distribution over functions where any finite set of function values is jointly Gaussian. "Gaussian process regression problems"
- Gaussian process regression: Regression using a GP prior on functions to obtain predictive distributions. "Focusing on Gaussian process regression problems"
- Gaussian state-space models: Dynamical models with Gaussian latent states and observations. "Gaussian state-space models"
- Gram matrix: The matrix of pairwise kernel evaluations over data points. "is a Gram matrix"
- Hierarchical GPs: Gaussian process models with hierarchical (e.g., hyperparameter) priors. "Extension to hierarchical GPs"
- In-context learning (ICL): A model’s ability to learn from examples provided in its input at inference time without parameter updates. "In-context learning (ICL) is the ability of a pre-trained model to adapt to new tasks"
- Integral operator: An operator defined by integration against a kernel; its spectrum characterizes kernel methods. "the eigenvalues of the population integral operator decay geometrically"
- Jacobi preconditioning: Diagonal preconditioning that scales a linear system to improve iterative solver convergence. "A standard remedy is Jacobi (diagonal) preconditioning"
- Kernel aggregate: The sum of kernel similarities from a point to all context points, used as a normalizer. "where is the kernel aggregate for "
- Kernel ridge regression (KRR): Regularized least squares in an RKHS, equivalent to GP posterior mean estimation. "kernel ridge regression (KRR) problems"
- Layer normalization: A normalization technique applied within layers of neural networks to stabilize training. "layer normalization) can be viewed as architectural refinements"
- Logits: Unnormalized scores output by a model before applying softmax to form probabilities. "vector of finite length (``logits'')"
- Markov chain Monte Carlo (MCMC): Sampling algorithms for approximating posterior distributions. "such as Markov chain Monte Carlo (MCMC)"
- Masked self-attention: Self-attention with a mask restricting which tokens can attend to which others. "Denoting Attn a masked self-attention"
- Monte Carlo integration: Numerical integration via random sampling. "PPD is typically computed through Monte Carlo integration"
- Natural parameter: The parameterization of an exponential family appearing linearly with sufficient statistics. "is the natural parameter map"
- n-generalization: Generalization across different context sizes n beyond those seen in pretraining. "referred to as -generalization"
- Posterior predictive distribution (PPD): The distribution of a future observation given observed data under a Bayesian model. "approximating the posterior predictive distribution (PPD) through in-context learning"
- Preconditioned gradient descent: Gradient descent with a linear transformation to improve conditioning and convergence. "implements a single iteration of preconditioned gradient descent"
- Pretraining range: The range of sample sizes or conditions used during PFN pretraining. "beyond the pretraining sample size range"
- Prior predictive model: The joint distribution of data induced by the prior before observing data. "a joint prior predictive model of "
- Prior-data fitted networks (PFNs): Transformers pretrained on synthetic data from a prior predictive model to perform Bayesian prediction in-context. "Prior-data fitted networks (PFNs) have recently emerged as a powerful approach"
- Radial basis function (RBF) kernel: A popular kernel κ(x,x′)=α² exp(−∥x−x′∥²/(2ℓ²)) used in GPs and kernel methods. "GP regression with RBF kernel"
- Reproducing kernel Hilbert space (RKHS): A Hilbert space of functions associated with a positive definite kernel. "reproducing kernel Hilbert space (RKHS)"
- Representer theorem: A result stating the solution to certain RKHS problems lies in the span of kernel evaluations at data points. "By the representer theorem"
- Residual connection: A skip connection adding the input to the output of a layer to ease optimization. "comprises a residual connection"
- Richardson iteration: An iterative method for solving linear systems using successive residual corrections. "A Richardson iteration"
- Row-stochastic matrix: A matrix whose rows sum to one, often representing normalized transition weights. "is a row stochastic matrix"
- Row-sum matrix: The diagonal matrix of row sums used in Jacobi preconditioning. "the inverse row-sum matrix "
- Self-attention: A mechanism where tokens attend to each other via content-based weights. "self-attention implements an iterative solver for the predictive mean and variance"
- Softmax normalization: Converting logits into a probability distribution via exponentiation and normalization. "softmax normalization removes the additive constant "
- Spectral properties (attention score matrix): Characteristics of eigenvalues/singular values governing convergence and stability. "Using the spectral properties of the attention score matrix"
- Sufficient statistic: A function of data that captures all information about a parameter in an exponential family. "is the sufficient statistic map"
- Surrogate models: Approximate models used to replace expensive objective functions in optimization. "serve as flexible surrogate models for Bayesian optimization"
- Total variation distance: A metric measuring the maximum discrepancy between two probability distributions. "the total variation distance between the true posterior predictive"
- Transformer: A neural architecture based on self-attention mechanisms. "transformer architectures, which have become the dominant modeling component"
- Truncation (truncated distribution): Restricting a distribution to an interval, renormalizing the mass inside it. "truncated to "
- Universal approximation theorem: A result that sufficiently wide neural networks can approximate continuous functions on compact sets. "By the universal approximation theorem"
- Variance reduction term: The component of GP predictive variance reduced by conditioning on data. "the variance reduction term in "
Collections
Sign up for free to add this paper to one or more collections.

