- The paper introduces a training-free, self-speculative decoding framework that co-designs algorithm and hardware to achieve lossless output fidelity in edge-deployed reasoning LLMs.
- It employs bit-level techniques like unstructured value pruning, mantissa truncation, and exponent compression to reduce computational and memory overhead during autoregressive decoding.
- Empirical results demonstrate throughput gains up to 2.41× with minimal accuracy loss, outperforming traditional methods in low-batch and memory-constrained settings.
Cassandra: Enabling Reasoning LLMs at the Edge via Self-Speculative Decoding
Introduction and Motivation
Edge deployment of LLMs has become increasingly relevant with the proliferation of consumer-grade AI hardware and high-performing small-scale transformers. Conventional batched inference optimizations provide limited benefit in edge scenarios, especially as modern "reasoning LLMs" yield longer outputs and shift computational bottlenecks to the autoregressive decode phase. Lossy compression and aggressive quantization often fail to maintain accuracy for such workloads, resulting in significant accuracy drops—especially in high complexity benchmarks. These limitations necessitate accurate, low-batch, and resource-efficient algorithmic accelerations for edge LLM inference.
Speculative decoding is a natural candidate for decode-stage acceleration due to its ability to parallelize sequential token generation using a lightweight draft model, improving throughput without sacrificing output distribution fidelity. However, existing speculative decoding frameworks exhibit severe limitations in edge settings, including dependence on additional training, performance degradation in low-batch regimes, and undesirable memory duplication due to draft-target model decoupling.
Cassandra proposes an algorithm-hardware co-designed, self-speculative decoding paradigm. The framework addresses the aforementioned limitations by constructing high-quality, training-free draft models via fine-grained weight and KV cache data selection, leveraging unstructured pruning, mantissa truncation, and efficient exponent compression. Integration with lightweight, hardware-oriented encoder-decoder modules ensures minimal conversion overhead and straightforward deployment on commercial GPUs and NPUs.
Cassandra Algorithmic Approach
Cassandra's central insight is that a high-quality draft model can be directly derived from the target LLM by exploiting bit-level selection, completely obviating the need for retraining or extra parameter storage. The format transformation pipeline involves:
- Unstructured Value Pruning: Weights and KV caches undergo magnitude-based pruning, guided by activation-aware or per-token importance, maximizing the preservation of functionally critical elements while zeroing out less salient data.
- Mantissa Truncation: Following pruning, truncated mantissas further reduce the data footprint with minimal information loss. The truncation approach preserves bit-subset containment, allowing the draft model to be a mathematical subset of the target, unlike quantization.
- Exponent Compression: Since the exponent dominates BFloat16's bitwidth, Cassandra employs both lossy (MX format) and lossless (unary coding) exponent compression. Unary coding, with simple bitstream boundaries, enables nearly entropy-optimal, parallelizable, and table-free decoding.
The transformed model is split into speculation (salient data, for draft generation) and verification data (full data, for parallel validation). During inference, only speculation data is fetched for the draft computation, with verification using the complete, full-precision representation. This design maintains identical output to the original model in expectation, with no extra training steps or model duplication.
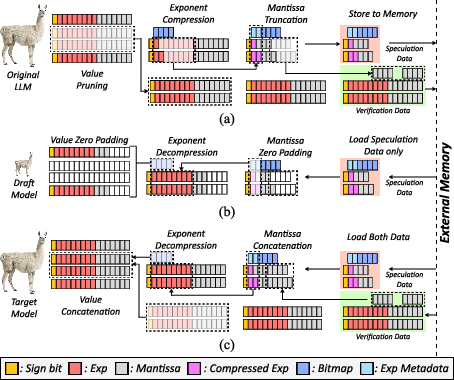
Figure 2: The Cassandra algorithm partitions model states into speculation and verification data, with fast speculation (pruned/truncated/exponent-compressed) supporting the draft, and deferred verification ensuring fidelity.
An extensive methodology is introduced to trade off draft model compression ratio versus acceptance rate. Contrary to traditional lossy compression, Cassandra’s performance scales with acceptance rate, not intrinsic quality loss, since mispredicted tokens are simply rejected and immediately corrected using the target model. This observation enables more aggressive combination of pruning and mantissa truncation than would be viable in standard lossy settings.
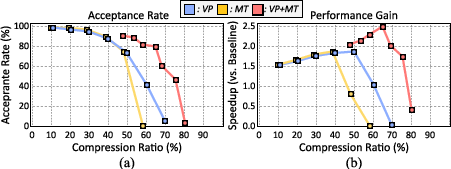
Figure 4: Combining value pruning and mantissa truncation delivers the best acceptance rate/compression ratio curve, supporting Cassandra's aggressive draft compaction.
Efficient Hardware-Accelerated Implementation
A fundamental enabler of Cassandra’s practicality is its hardware encoder-decoder, designed to perform bit-level format transformations (mantissa concatenation, exponent decoding, de-sparsification) with high throughput and minimal area. Unary coding for exponents is implemented with parallel zero counting logic, allowing for scalable, low-latency decomposition of compressed codes.
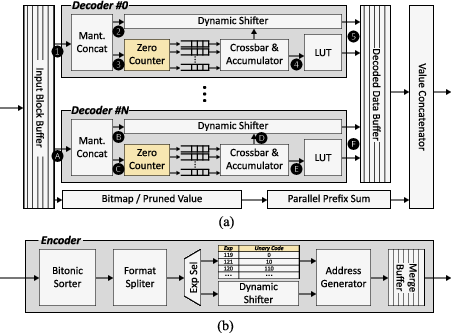
Figure 6: The Cassandra decode path leverages parallelized dataflow for high-throughput exponent and mantissa decoding, supporting both MX (shared exponent) and unary (lossless) modes.
Integration with commodity GPUs places decoders in the memory hierarchy between L2 and the memory controller, orchestrated per memory partition. For NPU deployment, a similar mechanism integrates the Cassandra modules within the DMA data path. Superblock-based memory mapping ensures efficient access, even with variable-length encoding and speculative/verification data partitioning. The area and power impact are minimal (~2% area overhead for a 64 TFLOPS NPU).

Figure 1: Cassandra accelerates both GPU and NPU architectures by assigning the format conversion modules near the memory/data movement boundaries.
Empirical Results
Through simulation and hardware implementation, Cassandra demonstrates robust performance gains across multiple LLMs (Llama3-8B, Deepseek-R1-Distillated-Llama3-8B, Qwen3-4B-Thinking-2507) and diverse reasoning benchmarks (AIME2025, Math-500, GPQA-Diamond, LongBench). Key findings include:
- Throughput gains of 1.78×–2.41× compared to BFloat16 baseline under low-batch settings, with acceptance rates stabilized by aggressive parameter selection.
- Superior memory efficiency: Cassandra enables up to 1.81× more generated tokens than EAGLE-3 and 11.59× more than standard Llama3-based decoding under fixed memory.
- Minimal or no accuracy degradation: Cassandra-1 (unary exponent) provides lossless output fidelity; Cassandra-2 (MX exponent) offers only marginal accuracy loss, substantially outperforming state-of-the-art lossy compression under challenging benchmarks.
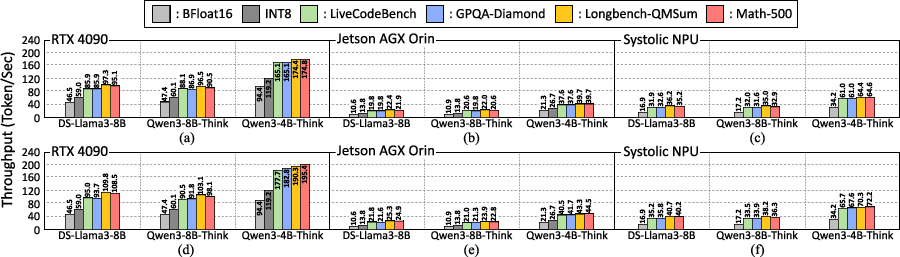
Figure 9: Cassandra delivers normalized throughput improvement versus BFloat16 across GPU and NPU platforms, for both lossless (Cassandra-1) and MX (Cassandra-2) exponent compression.
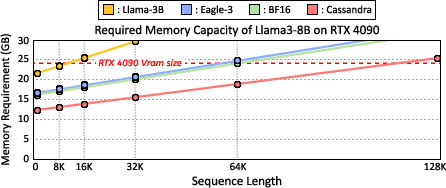
Figure 11: Comparison of memory requirements highlights Cassandra’s significant advantage in max token generation over prior speculative decoders in memory-constrained environments.
Comparative Analysis
Cassandra's performance and flexibility surpass contemporary training-free speculative decoders such as Draft&Verify, QuantSpec, and MagicDec in low-batch inference. Whereas those methods focus on coarse-grained or layer/skipping-based draft models (which yield insufficient bottleneck alleviation in edge decode), Cassandra's bit-level selectivity for both weights and KV cache enables a sharper reduction in bandwidth- and capacity-bound critical paths. Training-based methods like EAGLE-3 can, in certain tasks, offer competitive or better performance, but require orders-of-magnitude more computational investment and model duplication, limiting edge feasibility.
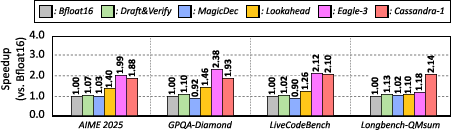
Figure 3: Cassandra achieves robust speedup relative to state-of-the-art speculative decoders, especially when batch sizes are limited and memory/capacity constraints become dominant.
Additionally, Cassandra aligns seamlessly with quantization and lossy compression pipelines. While INT8/FP8 quantization is routinely employed, it demonstrates unpredictable accuracy degradation on reasoning workloads, while speculative decoding maintains fidelity by construction. Cassandra is compatible with quantized baseline formats (e.g., MXINT8, Any-Precision LLM) and can be adapted to other low-bit workflows, providing further flexibility and promise for integration into broader deployment stacks.
Implications and Future Directions
By introducing a low-overhead, self-speculative decoding framework that tightly couples bit-level data selection with hardware-aware execution, Cassandra redefines the feasible operating envelope for high-accuracy LLM inference in edge environments. This work demonstrates that sophisticated algorithm-hardware co-design can unlock lossless, low-latency, and memory-efficient deployment for modern LLMs—an essential capability as the AI ecosystem moves toward pervasive, on-device, privacy-preserving, and real-time applications.
Future work should investigate:
- Extensions to highly quantized formats with even lower precision baselines and synergistic combination with INT-based speculative decoding.
- Adaptive acceptance strategies that can dynamically tune truncation and pruning in response to observed workload/sequence length.
- Integration of Cassandra principles in new memory architectures (beyond GPU/NPU), including near-memory and embedded inference cores.
Conclusion
Cassandra offers an algorithm-hardware co-designed, training-free speculative decoding framework that achieves high-throughput, lossless LLM inference for edge devices. By leveraging aggressive but mathematically safe parameter selection and bit-efficient format transformation, Cassandra surpasses both lossy and prior speculative approaches in decode-stage latency, memory efficiency, and performance robustness, all while requiring minimal engineering overhead and maintaining originality in hardware integration. This framework is a significant step toward universal, scalable deployment of reasoning-capable LLMs in real-life, capacity-constrained settings.
Reference: "Cassandra: Enabling Reasoning LLMs at Edge via Self-Speculative Decoding" (2605.26558)