- The paper demonstrates that speculative decoding improvements, including tree attention and online distillation, enhance Llama inference speeds by up to 2.0×.
- The authors integrate online distillation, extended training, and multi-layer dense draft models to streamline token prediction and reduce computational overhead.
- The proposed approach leverages latency hiding and disaggregated inference techniques to efficiently manage large batches in production environments.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
This essay provides an in-depth exploration of the techniques described in the paper "Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions" (2508.08192). The paper outlines a suite of optimizations for speculative decoding of Llama models, specifically focusing on scaling the EAGLE-based speculative decoding method to production environments. The authors address numerous challenges in implementing tree attention and latency optimizations on GPUs, leading to substantial improvements in inference performance.
Introduction to Speculative Decoding
Speculative decoding is designed to enhance the inference speed of LLMs by adopting techniques like tree-based attention and token prediction. The Llama models, due to their extensive size and autoregressive nature, face significant challenges in production environments, particularly regarding latency. The paper explores the application of speculative decoding, which involves utilizing a draft model to predict and validate multiple tokens, thereby reducing the number of calls to the main model.

Figure 2: An illustration of optimized tree attention. Unlike the standard and unoptimized tree attention (see Figures in other works), this structure allows efficient inference.
Training Optimization Techniques
The authors introduce three major optimizations to improve the EAGLE-based speculative decoding method: online distillation, extended training duration, and a multi-layer dense draft model strategy.
- Online Distillation: This technique uses a combination of a heavier base model and a lightweight draft model to align the hidden states and logits, improving the efficiency and accuracy of token predictions.
- Extended Training: The extended training duration for draft models results in higher tokens per call (TPC) metrics, demonstrating increased efficiency in speculative decoding. The Llama models show varying performance improvements with longer training sessions, enhancing TPC values across benchmarks.
- Multi-layer Dense Draft Models: The use of dense transformer blocks as opposed to sparse MoE layers results in reduced parameter sizes and enhanced performance, particularly in maintaining high TPC metrics without significant overhead.
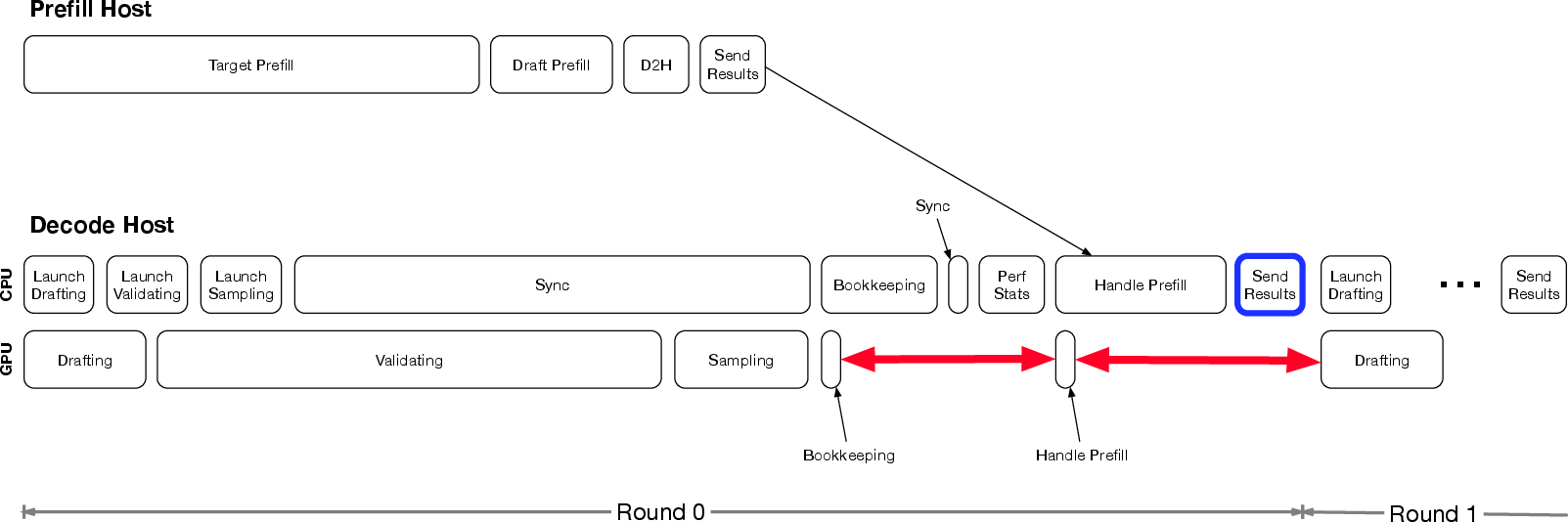
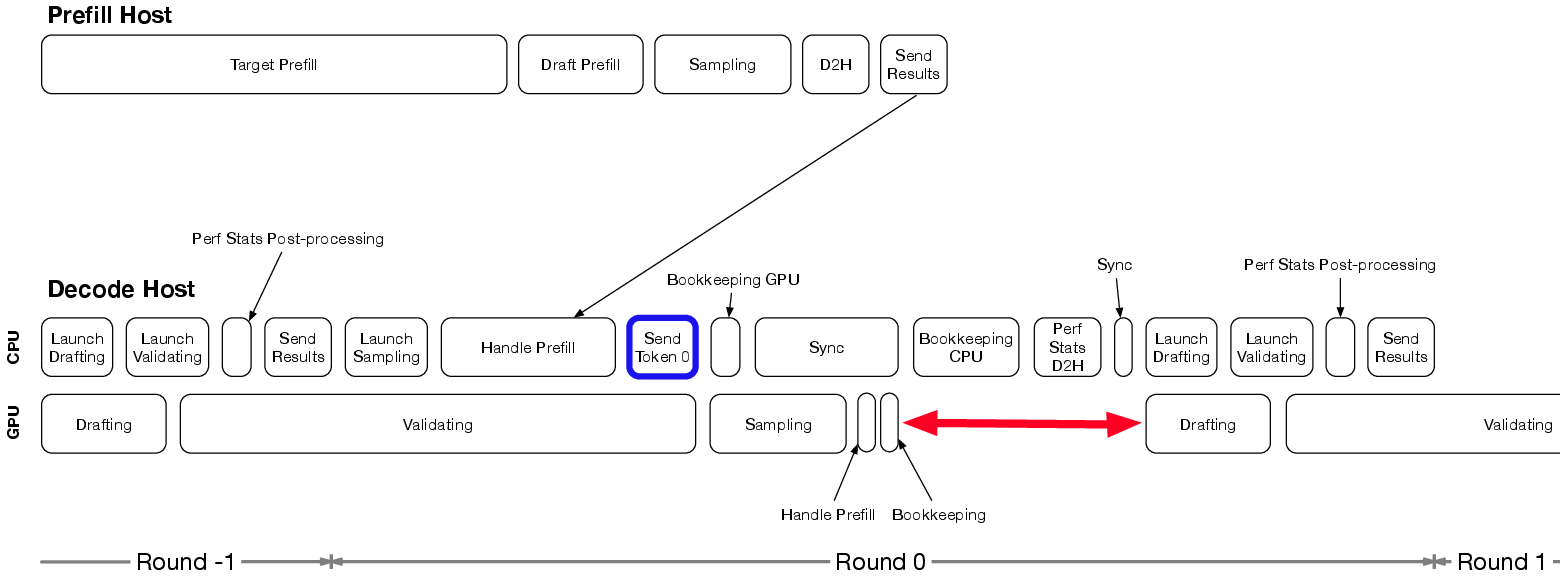
Figure 4: Before latency hiding optimizations.
Inference Optimization
To optimize inference, the paper describes several significant improvements in the speculative decoding process:
- Tree Attention: By optimizing tree attention using two-pass attention operations, the authors achieve more efficient one-shot validation of draft tokens. This strategic splitting into prefix and suffix parts reduces computational overhead.
- Multi-round Speculative Sampling: The integration of PyTorch-2 compilation minimizes CPU overhead with efficient parallelization, significantly boosting inference speed.
- Disaggregated Inference with Large Batches: Through disaggregation techniques and carefully crafted computational strategies, the paper demonstrates improved management of large batch sizes in speculative decoding processes.
- Latency Hiding Strategies: By restructuring inference cycles to overlap CPU and GPU tasks, GPU idle time is minimized, leading to improved overall efficiency.
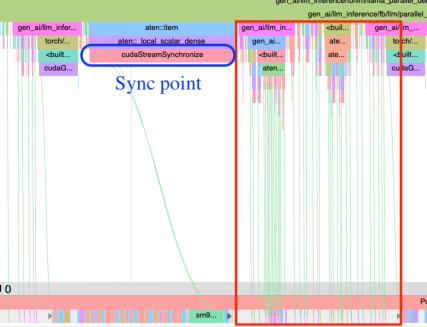
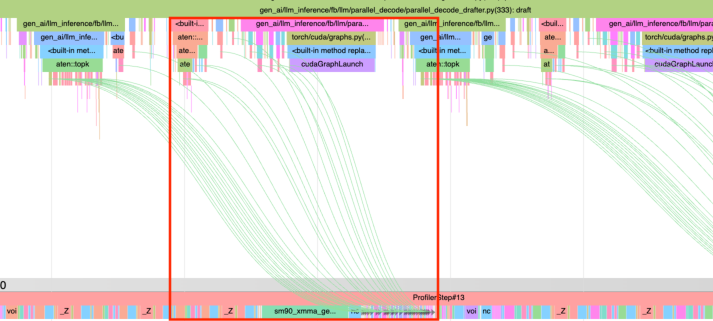
Figure 6: After latency hiding optimizations.
Benchmarks and Results
The paper provides empirical benchmarks illustrating a marked increase in speed-up ratios between 1.4× and 2.0× over traditional inference across a variety of batch sizes and model configurations. These results underscore the effectiveness of the proposed optimizations in real-world setups.
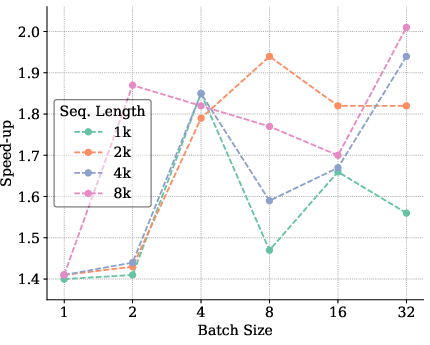
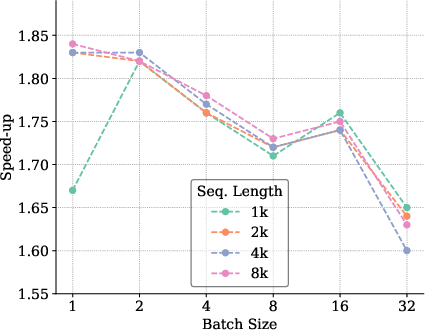
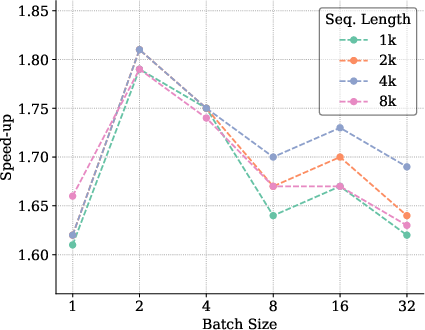
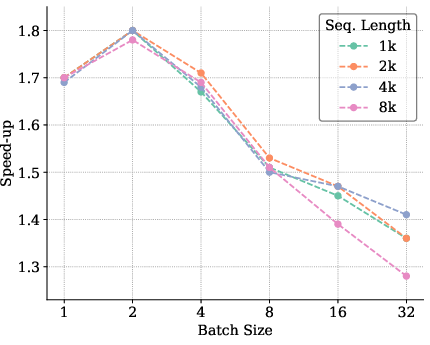
Figure 8: Benchmarking results for Llama3.1 8B model indicating significant speed-up in inference.
Conclusion
The paper's extensive framework introduces robust solutions to the challenges associated with speculative decoding at scale, particularly for Llama models. This pioneering set of optimizations not only shows significant promise in terms of reduced inference latency but also enhances the practical usability of Llama models in production environments. Future work may continue to optimize these techniques further, integrating more advanced hardware-specific accelerations and potentially exploring broader applications across diverse AI tasks.