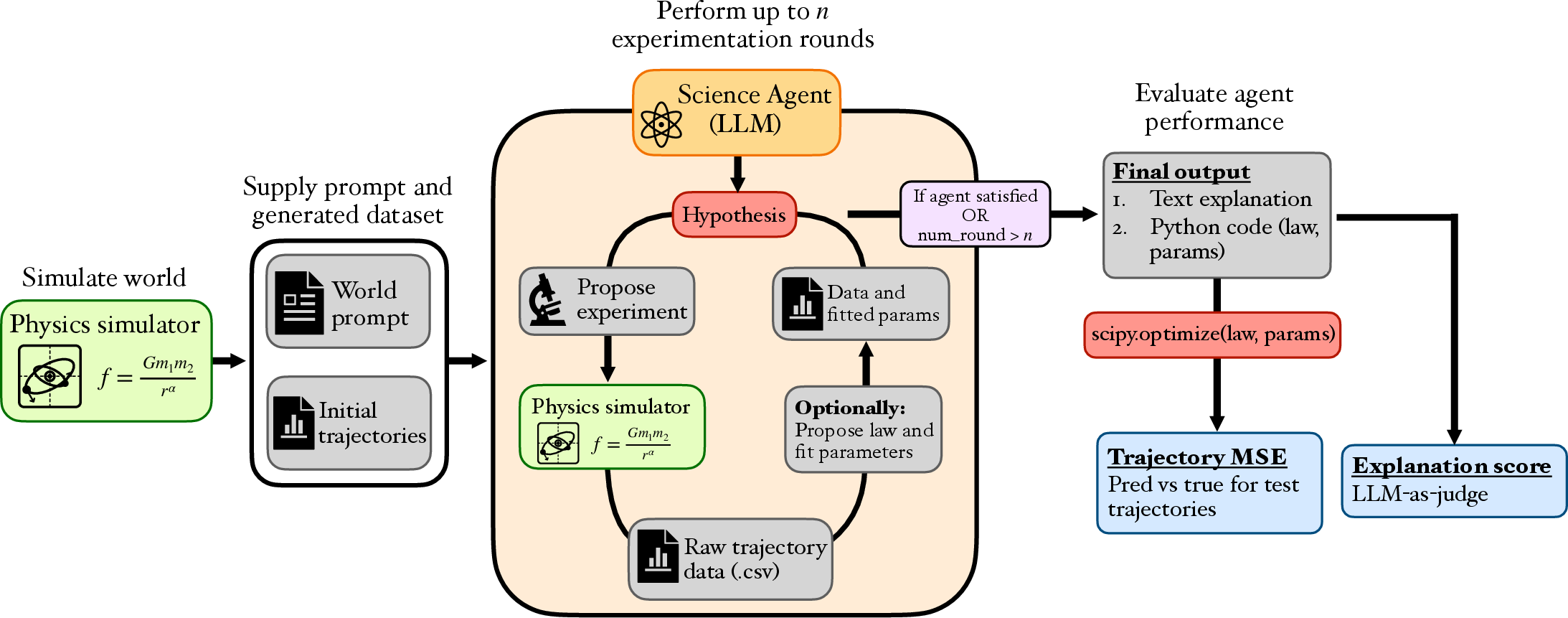
DiscoverPhysics: Benchmarking LLMs for Out-of-the-Box Scientific Thinking
Abstract: Frontier LLMs now perform strongly across a wide range of physics evaluations, but it is hard to disentangle genuine reasoning from recall of established science. We introduce DiscoverPhysics, an interactive benchmark that asks a LLM agent to discover the laws of motion of a simulated world whose physics deliberately deviates from our own. We construct 22 worlds governed by, among others, screened and fractional-power gravity, multi-species couplings, hidden dark-matter-like particles, non-coordinate-free physics, and time-varying interactions. Each world is generated on demand by an N-body simulator, for which the agent proposes several rounds of experiments, observes raw trajectory data, and ultimately submits both a natural-language explanation of the world's physics and a Python implementation of the inferred law. Because solving a world requires the agent to design informative experiments and revise its hypotheses, the benchmark probes long-horizon reasoning over an experimental history. We evaluate submissions along two complementary axes: trajectory MSE on held-out particles and an LLM-judged explanation score following an expert-written rubric assessing conceptual understanding of each world. Across eleven frontier models, we find that the strongest agents pass only half of the worlds and consistently fail on those where latent structure must be uncovered. Open-source models lag substantially behind commercial models, both in their ability to design informative experiments and in extracting conclusions from the data. We further find that good predictive accuracy does not guarantee high explanation quality and that conceptual understanding depends on hypothesis refinement through well-chosen experiments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces DiscoverPhysics, a “science sandbox” for AI. In this sandbox, an AI acts like a scientist in a strange universe where the rules of physics are different from ours. The AI must run experiments, look at what happens, and figure out the hidden rules that control how objects move. The goal is to test whether AIs can truly discover new ideas—not just repeat what they’ve memorized.
The big questions the paper asks
- Can AI systems design smart experiments and change their ideas when the data doesn’t fit?
- Can they discover unusual, “non-textbook” laws of physics in worlds that deliberately break our normal rules?
- Do AIs that predict motion well also explain the ideas behind the motion well—or are those different skills?
How the researchers tested the AIs
Think of it like a video game where the physics is unfamiliar. The team built 22 different simulated worlds with odd rules—for example:
- Gravity that fades quickly at short distances
- Forces that change over time
- Hidden “dark-matter-like” particles you can’t see directly
- Multiple kinds of particles that interact differently
- Extra dimensions or rules that depend on direction
In each world, the AI gets several “rounds” to do science:
- It proposes experiments (for example: place particles here, give them this push, measure their positions at these times).
- The simulator runs the experiment and returns raw motion data (trajectories).
- The AI studies the data, updates its ideas, and plans better experiments.
- After a set number of rounds, the AI submits:
- A short, plain explanation of the world’s physics
- A small piece of Python code that implements the law it discovered
The team scored each AI in two ways:
- Prediction score (trajectory error): How well does the AI’s final law predict the motion of new, unseen test particles? In simple terms, if the AI says “the particle will be here,” how close is it?
- Explanation score: Does the AI’s written explanation match the key concepts of the true rule? A separate AI judge (using a human-made rubric) checks if the explanation captures the right ideas.
Why both scores? Because in science, being able to fit data isn’t enough—you also want to understand the principle behind it.
What they found and why it matters
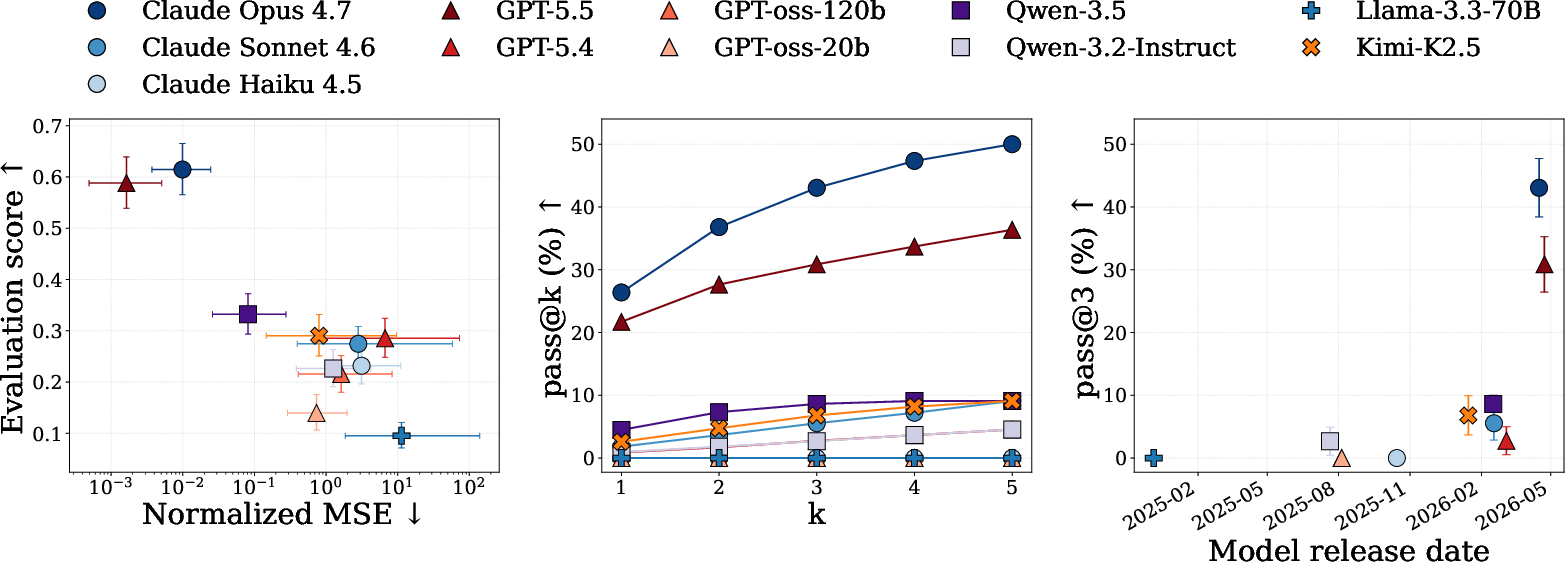
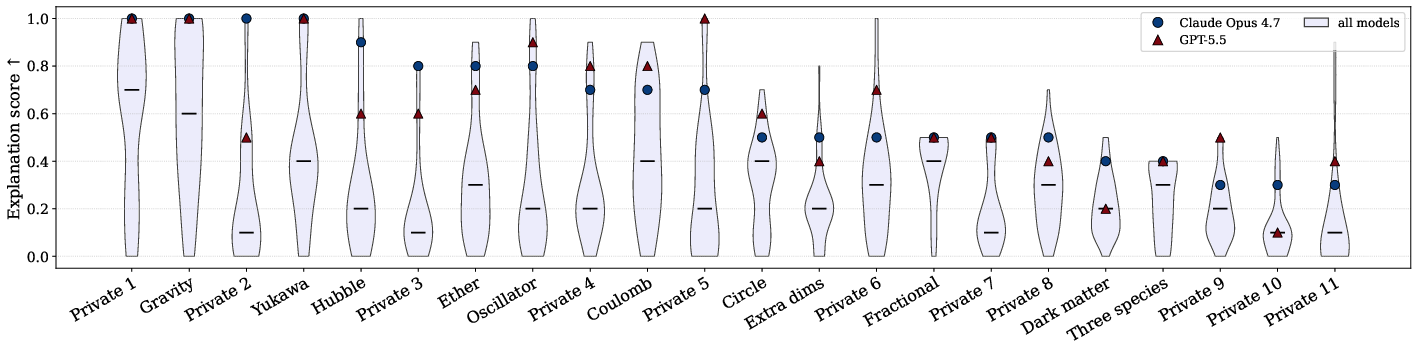
- Strong AIs did well, but not great: The best models solved only about half of the worlds, even with multiple attempts. The trickiest worlds had hidden structure—like invisible particles, different particle species, or time-varying forces—that required clever experiments to uncover.
- Prediction is not the same as understanding: Some models could predict motion very accurately but still failed to identify the big idea behind the rule. In other words, “curve fitting” without true insight.
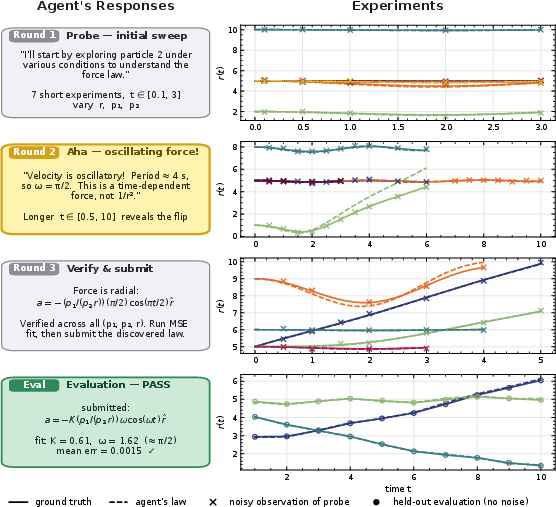
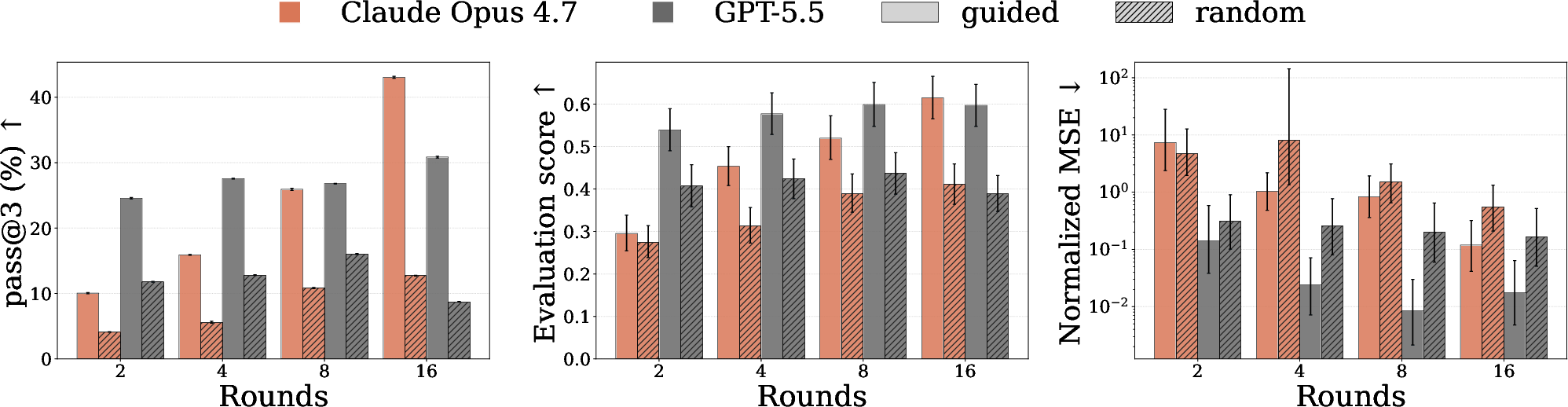
- Experiment design really helps: When AIs chose their own experiments, they generally did better than when experiments were random. One top model improved steadily as it ran more rounds and refined its ideas, showing that good science needs well-chosen tests.
- Not all AIs performed the same way:
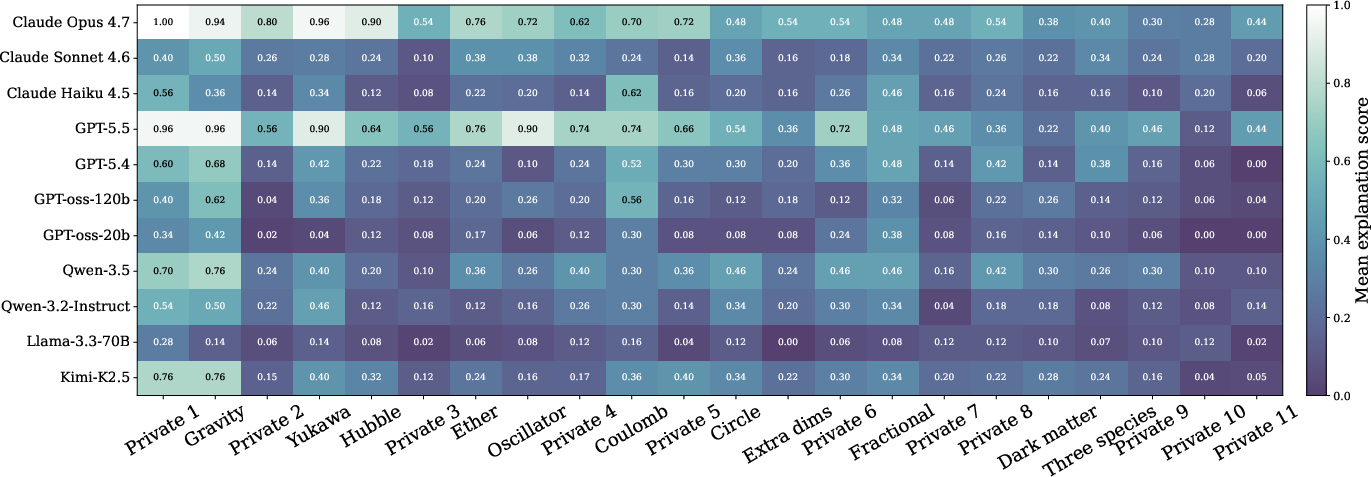
- One leading model (called “claude-opus-4-7” in the paper) had the best explanation scores and passed the most worlds, especially as it got more experiment rounds.
- Another top model (“gpt-5.5”) got the lowest prediction errors but gained less on explanation quality from extra rounds—suggesting it often refined numbers rather than revising its concepts.
- Open-source models lagged behind: They struggled both to design informative experiments and to extract the core ideas from the data, and often did no better than with random experiments.
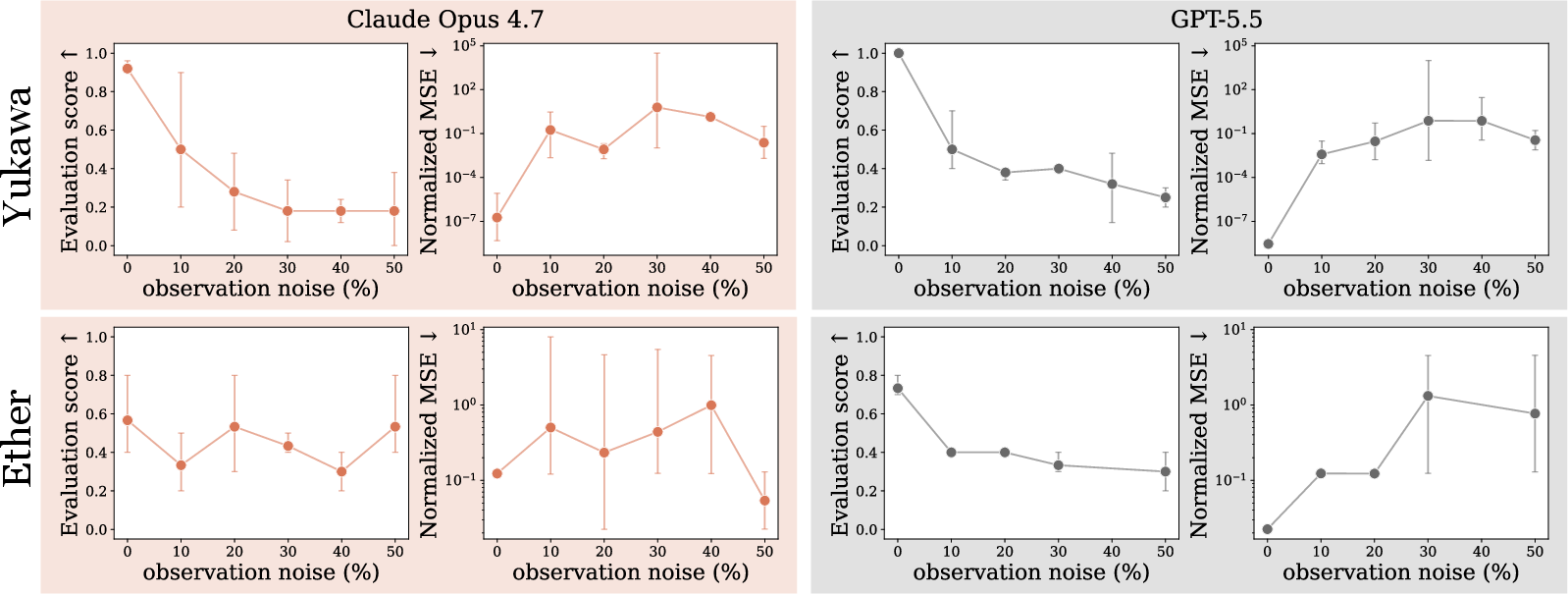
- Noise matters, but strategy helps: When the researchers added measurement noise, scores fell—especially in small systems—but some AIs adapted by designing experiments that reduced the effects of noise.
Why this research is important
DiscoverPhysics is a tough, fair test of “scientific thinking” for AI. It doesn’t just ask, “Can you remember physics?” or “Can you fit an equation?” It asks, “Can you discover the rules of a brand-new world by experimenting, revising your ideas, and explaining what you learned?”
This matters because real science often means:
- Figuring out which variables matter
- Designing clever experiments
- Updating beliefs when evidence disagrees
- Explaining the why, not just the what
By releasing this simulator and benchmark, the authors give researchers a way to evaluate and train future AIs that can think more like scientists—curious, adaptive, and explanation-driven. If AIs get better at this, they could become stronger partners in real scientific discovery, beyond textbooks and into the unknown.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, framed to guide actionable future research:
- Benchmark scope and diversity: worlds are curated and relatively small-scale (N ≲ 35) with pairwise interactions; no explicit many-body (non-pairwise) forces, retardation effects, non-local kernels, or PDE-mediated fields (e.g., grid-based field solvers), limiting assessment of discovery in richer physical regimes.
- Latent structure complexity: only certain latent features are included (e.g., hidden species, extra dimensions, time modulation); unexplored are memory effects (non-Markovian dynamics), time delays, hysteresis, nonlocal couplings, or causal structures requiring multi-step interventions.
- Dimensionality and coordinates: the dimensional setting and coordinate choices are not systematically varied; robustness to 2D vs 3D, rotating/non-inertial frames, or arbitrary coordinate transforms remains untested.
- Instrumental realism: observation noise is Gaussian and simple; missing are actuator/initialization noise, sensor drift and bias, missing data, occlusions, irregular sampling, correlated noise, or outliers—factors crucial for discovering laws in realistic experimental contexts.
- Experimental cost model: experiments are effectively costless; no resource/latency/precision trade-offs, penalties for repeated measurements, or budget-aware planning metrics that would test efficient experimental design under constraints.
- Integrator sensitivity: dependence on the chosen integrator (Yoshida4 by default), time step, and numerical stability/softening is not analyzed; potential numerical artifacts and their impact on inference and experiment planning are unknown.
- Scalability in N and compute: O(N2) pairwise force computation is untested for larger N; effects on agent strategies, experiment utility, and runtime under higher particle counts or long horizons are unexplored.
- Held-out evaluation mismatch: parameters are fit to noisy trajectories, yet MSE is computed on noise-free held-out data; the impact of this train–test noise mismatch on ranking and robustness is unquantified.
- Metric breadth: normalized trajectory MSE may miss physically salient structure; no complementary metrics (e.g., energy/momentum error, invariant preservation, symmetry adherence, long-horizon stability, counterfactual validity) are reported.
- Explanation scoring reliability: a single LLM judge (claude-opus-4-6) is used; no multi-judge aggregation, human inter-rater reliability, calibration of bias, or adversarial robustness analysis of explanation grading.
- Rubric sensitivity: explanation rubrics are human-authored and partially private; sensitivity of scores to rubric wording/style and the risk of keyword gaming are untested.
- Threshold arbitrariness: pass/fail cutoffs (10% normalized MSE, ≥0.9 explanation) are heuristic; no sensitivity analysis on how model rankings change with threshold choices.
- Human baselines: no human-in-the-loop or human-expert baseline using the same interface; difficulty calibration against domain experts is missing.
- Experiment informativeness: difference between guided and random experiments is reported but not quantified; no information-theoretic or statistical measures of experimental value, coverage of phase space, or optimal design diagnostics.
- Tooling limitations: agents have only a least-squares fitter; impacts of richer tools (code execution, plotting, filtering/smoothing, symbolic regression, Bayesian inference, active design via information gain) are not studied.
- Token/compute parity: reasoning token budgets, chain-of-thought availability, and compute limits are not standardized across models (especially for proprietary APIs), raising fairness and comparability concerns.
- Multi-attempt learning: pass@k indicates potential gains from learning across runs, but no investigation of RL fine-tuning, memory across attempts, curriculum schedules, or sample efficiency on this benchmark.
- Transfer and generalization: no study of cross-world transfer (meta-learning), out-of-distribution generalization to unseen law families, or correlations with other discovery benchmarks.
- Private worlds vs reproducibility: half the worlds are private to prevent overfitting, but this limits full reproducibility and community auditing; strategies for continual refresh, leakage detection, and public–private balance are unspecified.
- Security/sandboxing: safety of executing model-submitted Python (e.g., preventing environment introspection or cheating) is not detailed; code sandboxing and auditing protocols are unclear.
- Parameterization cap: final law submissions allow up to five free parameters; the effect of this cap on discovering richer or multi-regime laws is not evaluated.
- Randomized baseline design: random experiments are sampled from a uniform grid; whether this baseline is sufficiently challenging/representative and how results change under alternative randomization policies is not examined.
- Noise ablations: tested on only two worlds and primarily Gaussian noise; robustness across more worlds, noise types (e.g., heavy-tailed, correlated), and partial observability remains open.
- Causal and counterfactual validity: the benchmark does not explicitly test counterfactual predictions under interventions or assess learned causal structure beyond predictive fit and rubric-matched narratives.
- Decoupling diagnosis: while prediction–explanation decoupling is observed, no diagnostic tasks evaluate recovery of formal structure (e.g., symmetry groups, conservation laws) to explain why models succeed/fail conceptually.
- World difficulty taxonomy: difficulty is inferred from scores; a principled taxonomy (e.g., latent dimensionality, nonlinearity, stiffness, identifiability) to stratify worlds and predict model failure modes is absent.
- Round budgets and stopping: fixed round counts are used; benefits of adaptive stopping criteria, budget allocation across measurements vs new experiments, or per-world adaptive planning are unexplored.
- Visualization and perceptual aids: agents receive textual/CSV trajectories only; whether access to plots, animations, or derived features changes discovery outcomes is untested.
- Multi-agent collaboration: coordinated agents (e.g., planner–analyst–critic) and their impact on hypothesis revision and experiment design have not been evaluated.
- Cross-integrator ground truth: no cross-check that different high-accuracy integrators yield consistent ground-truth trajectories and identical pass/fail outcomes.
- Benchmark contamination risk: with public code and worlds, long-term risk of training-on-the-benchmark is unaddressed; mechanisms for freshness, versioning, and contamination audits are not specified.
Practical Applications
Immediate Applications
The following use cases can be deployed now with modest adaptation of the released simulator, interface, and evaluation framework.
- Benchmarking and procurement of “AI scientist” systems (industry, academia, policy)
- Use case: R&D groups and funding agencies evaluate LLM agents for autonomous or semi-autonomous science using a standardized, interactive test that separates curve-fitting (trajectory MSE) from conceptual understanding (explanation score).
- Tools/workflows: DiscoverPhysics worlds + dual-metric dashboard; pass@k reporting to assess robustness; guided vs random experimentation ablation to detect genuine experimental design skill.
- Assumptions/dependencies: Access to frontier LLMs with tool-use; API cost/latency; multi-judge or human review to mitigate single-judge bias.
- Model selection and A/B testing of lab-assistant agents (industry, academia; software/MLOps)
- Use case: Choose among LLM agents for experimental planning in internal simulations or digital twins by comparing performance on DiscoverPhysics, prioritizing agents that improve with more experimental rounds and guided experimentation.
- Tools/workflows: CI pipelines that run agents through preset worlds each model upgrade; alerting when explanation score regresses despite stable MSE.
- Assumptions/dependencies: Simulator integration in CI; careful versioning of worlds to prevent overfitting.
- Curriculum and instruction in scientific reasoning (education; daily life via edtech)
- Use case: Instructors deploy DiscoverPhysics as an interactive lab to teach hypothesis generation, experiment design, and model revision under noise; students inspect why low MSE can coexist with poor explanations.
- Tools/products: Classroom “world packs” with rubrics, instructor dashboards, and editable noise levels; student-facing notebooks with experiment JSON schema.
- Assumptions/dependencies: Age-appropriate rubrics; compute and API credit management for classes.
- Auditing agents for “concept drift” toward overfitting (software, safety/governance)
- Use case: Monitor whether production scientific agents start to “hack” predictive metrics at the expense of mechanistic understanding by tracking the decoupling between MSE and explanation score over time.
- Tools/workflows: Dual-metric telemetry; periodic re-evaluation on unseen worlds; noise stress-tests.
- Assumptions/dependencies: Agreement on domain-appropriate explanation rubrics; judge diversity to counter bias.
- Training and fine-tuning pipelines for scientific agents (AI/ML tooling)
- Use case: Use the simulator to generate rich, on-demand trajectories and reasoning traces for RL/RLAIF to improve hypothesis revision and experiment selection.
- Tools/workflows: RL loops that reward pass@k, explanation score gains with round budget; failure-mode tags from the paper’s capability axes to shape curricula.
- Assumptions/dependencies: Avoiding benchmark overfitting; rotating private worlds; compute for long-horizon episodes.
- Rapid stress-testing under measurement noise (industry, academia)
- Use case: Evaluate agent robustness to observation noise and degraded sensors before deploying to real labs or field experiments.
- Tools/workflows: Noise ablation module (position vs velocity noise, amplitudes); analysis of how experiment choices change under noise.
- Assumptions/dependencies: Real-world noise differs from Gaussian; requires domain-specific extensions for systematics.
- Robotics system identification and auto-calibration in simulation (robotics, software)
- Use case: Test agents that design probing motions and estimate unusual dynamics/friction via the active experimentation loop, before transferring to physical robots.
- Tools/workflows: Replace N-body world with robot dynamics world; retain JSON experiment schema and parameter-fit tool.
- Assumptions/dependencies: Sim-to-real gap; integrators and force laws must reflect robotic dynamics.
- Agent evaluation for online experimentation platforms (tech, finance; A/B testing)
- Use case: Adapt the guided-vs-random experimentation check to identify agents that design informative interventions rather than passively analyze fixed data.
- Tools/workflows: Map “worlds” to controlled-simulation A/B environments; track dual metrics (predictive lift vs causal-explanation rubric).
- Assumptions/dependencies: Requires domain-appropriate definition of “explanation score” tied to causal hypotheses.
- Open-source model benchmarking and improvement (open-source community, academia)
- Use case: Community-driven improvement targeting observed deficits (e.g., poor use of experimental rounds), measured on public worlds with reproducible seeds.
- Tools/workflows: Public leaderboard; standardized scripts; reproducible integrator settings (Yoshida4 default).
- Assumptions/dependencies: Clear separation between public and private worlds to avoid hard-coded solutions.
- Educational and citizen-science games (daily life, education)
- Use case: Gamified “discover the laws” apps where learners (or their personal assistant LLMs) run experiments, compare hypotheses, and learn from rubric feedback.
- Tools/products: Web UI over the simulator; hints tied to rubric; shareable experiment logs.
- Assumptions/dependencies: UX polish; content moderation; compute budgeting for interactive sessions.
- Internal validation of “autonomous lab” claims (policy, standards bodies)
- Use case: Standards organizations use the benchmark to baseline vendor claims of discovery capability, requiring pass@k and dual-metric thresholds before approval.
- Tools/workflows: Conformance test suite; multi-judge explanation scoring; standardized reporting templates.
- Assumptions/dependencies: Agreement on thresholds; periodic refresh of hidden worlds to prevent gaming.
Long-Term Applications
These use cases require additional research, domain extensions (beyond idealized N-body worlds), integration with real instruments, or more scalable architectures.
- Closed-loop AI scientists in real labs (biotech, materials, physics; healthcare, energy)
- Use case: Agents propose wet-lab or materials experiments, revise mechanistic hypotheses as data arrives, and prioritize experiments that maximally reduce uncertainty.
- Tools/workflows: Integration with robotic labs/LIMS; multi-modal observation ingestion; domain-adapted explanation rubrics (e.g., mechanism-of-action).
- Assumptions/dependencies: Robust handling of non-Gaussian noise, systematics, batch effects; safety and oversight frameworks.
- Mechanism-seeking drug discovery and assay design (healthcare/biopharma)
- Use case: Prioritize assays that distinguish between competing mechanisms, not just predictive activity; track “explanation score” as a proxy for mechanistic insight.
- Tools/workflows: Domain-specific worlds (kinetic models, signaling networks); causal rubric design; experiment-budgeted planning.
- Assumptions/dependencies: High-fidelity simulators; validated mappings from rubric scores to real mechanistic understanding.
- Autonomous experimental design for next-gen materials and batteries (energy, manufacturing)
- Use case: Agents select electrochemical tests, interpret degradation pathways, and refine physics-based models of transport and kinetics.
- Tools/workflows: Physics-informed “worlds” of coupled PDE/ODE surrogates; multi-objective metrics (performance + explanation).
- Assumptions/dependencies: Accurate, fast surrogates; standardized explanation rubrics accepted by domain experts.
- Space and field science with on-board autonomy (aerospace, environmental sensing)
- Use case: Satellites or rovers run budget-limited experiments, detect latent phenomena (e.g., time-varying couplings), and adapt plans.
- Tools/workflows: On-board simulators/digital twins; compressed-telemetry explanation summaries; pass@k-like mission KPIs.
- Assumptions/dependencies: Compute and energy constraints; fault tolerance; robust uncertainty calibration.
- Safety and risk audits for agentic physical systems (policy, safety engineering)
- Use case: Before deployment, require agents to uncover latent hazards via experiment (hidden species/extra dimensions analogues → hidden modes/rare failures).
- Tools/workflows: Hazard-focused worlds; judge rubrics for failure-mechanism articulation; escalation when explanation diverges from predictive performance.
- Assumptions/dependencies: Domain-appropriate hazard simulators; governance processes for audit outcomes.
- Standard-setting for “explainability beyond accuracy” (policy, standards bodies)
- Use case: Formalize dual-metric benchmarks in certification of AI systems that interact with the physical world (medical devices, industrial automation).
- Tools/workflows: Multi-judge panels, inter-rater calibration; open reference rubrics; longitudinal audits.
- Assumptions/dependencies: Broad stakeholder agreement; legal frameworks recognizing explanation metrics.
- Cross-domain scientific reasoning benchmarks (academia, AI labs)
- Use case: Extend “non-canonical worlds” to chemistry, biology, climate, and economics to develop agents that generalize discovery strategies across domains.
- Tools/workflows: Modular simulator APIs; shared JSON experiment schemas; domain-specific integrators and noise models.
- Assumptions/dependencies: Community-authored worlds and rubrics; preventing data leakage and memorization.
- Agent architectures that revise hypotheses over long horizons (AI research)
- Use case: Develop memory and self-monitoring mechanisms that—unlike current models—continue improving explanation quality with more rounds.
- Tools/workflows: Curriculum learning on progressively harder worlds; credit assignment for conceptual revisions; chain-of-experiments traces.
- Assumptions/dependencies: Scalable training with tool-use; evaluation that distinguishes parameter tweaking from hypothesis change.
- Human-in-the-loop discovery workflows (industry, academia)
- Use case: Scientists pair with agents that propose experiments and explanations; humans critique with rubric-like feedback; agent updates beliefs.
- Tools/workflows: Interactive UIs linking logs, code, and rubrics; suggestion–critique–revision loops; provenance tracking.
- Assumptions/dependencies: Usability research; aligning reward with human judgments; IP and data governance.
- Simulation-to-reality transfer learning for control and calibration (robotics, manufacturing)
- Use case: Train agents to identify hidden system parameters/dynamics in sim, then transfer policies for rapid real-world commissioning.
- Tools/workflows: Domain randomization; adaptive experiment design policies; safety envelopes for real trials.
- Assumptions/dependencies: Accurate sim physics; methods to detect and correct for sim-to-real discrepancies.
- Public evaluation programs for national research investments (policy)
- Use case: Government programs benchmark vendors’ autonomous discovery platforms using evolving private worlds, linking scores to milestone payments.
- Tools/workflows: Secure evaluation environments; transparent reporting; periodic world refresh.
- Assumptions/dependencies: Procurement rules accommodating dynamic benchmarks; independent oversight.
- Consumer-facing science learning assistants (daily life, education)
- Use case: Personal AI tutors that run “discover the rule” mini-experiments at home (e.g., with sensors or microcontrollers), explaining reasoning steps.
- Tools/workflows: Edge-friendly simulators; sensor kits; guided rubrics adapted for K–12.
- Assumptions/dependencies: Safety with hardware; content alignment for age groups.
Notes on feasibility and dependencies across applications
- Judge bias and variance: The paper uses a single LLM judge for explanations; real deployments should aggregate multiple judges and/or human panels, with calibration protocols.
- Sim-to-real gap: Worlds are curated, small-scale, and noise-limited; transferring to real systems requires modeling non-Gaussian noise, systematics, and instrument constraints.
- Cost and latency: Frontier APIs incur nontrivial costs and variable reasoning token usage; budget-aware evaluation and caching are advisable.
- Overfitting and leakage: Maintain rotating private worlds and blind scoring to avoid hard-coded solutions and benchmark gaming.
- Safety and oversight: For physical experimentation, human-in-the-loop safeguards and domain-specific ethical reviews are prerequisites.
Glossary
- ablation: An experimental methodology where components or factors are systematically removed or varied to assess their impact on performance. "Noise ablation."
- advective/retardation coupling: A velocity-dependent interaction term analogous to advection or propagation delay effects in fields. "a radial-velocity term (analogous to an advective/retardation coupling)"
- ARC: The Abstraction and Reasoning Corpus, a benchmark designed to test general reasoning without relying on memorization. "ARC \citep{chollet2019measure} introduces few-shot puzzles explicitly designed to resist memorization through novel task generation."
- bootstrapped standard error: An uncertainty estimate obtained by resampling data with replacement many times and computing the variability of a statistic. "presenting the mean and bootstrapped standard error for all reported results with 5,000 bootstrap resamples."
- causal-graph discovery: The process of inferring a causal structure among variables represented as a directed graph, often via interventions. "and causal-graph discovery via interventions \citep{chen2025autobench}."
- closed-loop experimentation: An experimental approach where results from one step inform the design of subsequent experiments in an ongoing loop. "closed-loop experimentation in biology \citep{roohani2024biodiscoveryagent, mitchener2025bixbench}"
- Coulomb world: A test environment governed by Coulomb-like (inverse-square) interactions used to evaluate model performance. "they struggle more than others on the coulomb world"
- Dormand–Prince: A family of adaptive Runge–Kutta ODE solvers (often RK5(4)) used for numerical integration. "Dormand-Prince (jax.experimental.ode.odeint) \citep{jax2018github}"
- Euclidean distance: The standard straight-line distance measure in Euclidean space (L2 norm). "The trajectory MSE is the mean squared Euclidean distance between true and predicted positions across these held-out trajectories."
- explanation score: An LLM-judged metric assessing the conceptual correctness and clarity of a model’s explanation against a rubric. "An explanation score, computed by an LLM judge using a human-written rubric, measures whether the agent has correctly identified the conceptual features of the world"
- extra dimensions: Additional spatial dimensions beyond the usual three, affecting physical laws. "time-varying couplings, and extra dimensions are some of the examples."
- fractional Laplacians: Operators corresponding to non-integer powers of the Laplacian, modeling anomalous diffusion or nonlocal effects. "short-range exponentially screened forces, fractional Laplacians, hidden particle species"
- fractional-power gravity: A modified gravitational law where force depends on distance with a non-integer exponent. "screened and fractional-power gravity"
- Gaussian noise: Random noise drawn from a normal distribution added to measurements or simulations. "Optionally, Gaussian noise can be added to simulator outputs"
- geometric mean: A multiplicative average that reduces the impact of outliers compared to the arithmetic mean. "We report the geometric mean across worlds to reduce the influence of occasional large outliers."
- generalized charges: Vector-valued parameters attached to particles that determine how they source and respond to forces. "together with a set of generalized charges that determine how it couples to forces."
- held-out trajectories: Data reserved for evaluation that the model has not seen during experimentation or fitting. "The held-out trajectories are noise-free."
- hidden dark-matter-like particles: Unobserved particle species that influence dynamics analogously to dark matter. "hidden dark-matter-like particles"
- JIT compilation: Just-in-time compilation that compiles code at runtime to accelerate execution. "We use Yoshida4 by default because it is symplectic, 4th-order accurate, and fast under JIT compilation."
- kick-drift: A symplectic integration step pattern where velocities (kick) and positions (drift) are updated in sequence. "symplectic Euler (kick-drift)"
- latent structure: Underlying, unobserved variables or relationships that must be inferred from data. "consistently fail on those where latent structure must be uncovered."
- leapfrog (velocity-Verlet): A widely used symplectic integration scheme for Hamiltonian dynamics. "and leapfrog (velocity-Verlet)."
- least-squares fit: Parameter estimation that minimizes the sum of squared residuals between predictions and observations. "performs a least-squares fit of the parameters of its current candidate law"
- long-horizon reasoning: Planning and inference that unfold over multiple steps or rounds, integrating information over time. "the benchmark probes long-horizon reasoning over an experimental history."
- Lorentz transformations: Transformations between inertial frames that preserve the speed of light in special relativity. "Lorentz transformations were derived empirically to explain electromagnetic phenomena"
- N-body simulator: A computational tool that simulates the dynamics of multiple interacting particles under specified force laws. "Each world is generated on demand by an N-body simulator"
- Noether’s theorem: A fundamental result linking continuous symmetries of a system to conservation laws. "Noether's theorem revealed why: conservation laws arise from continuous symmetries."
- non-coordinate-free physics: Physical laws that depend explicitly on the choice of coordinate system. "non-coordinate-free physics"
- normalized MSE: Mean squared error scaled by a reference (e.g., trajectory variance) to enable fair comparison across settings. "the per-trajectory normalized MSE is below 0.1 ( error)"
- O(N2): Quadratic computational complexity in the number of particles N. "its computational cost scales as ."
- Pareto plot: A visualization highlighting trade-offs between two performance metrics along the Pareto frontier. "we show a Pareto plot of evaluation score as a function of normalized MSE"
- parameter fit: The process of estimating model parameters to best match observed data. "The agent may also propose a candidate law and request a parameter fit against the trajectories observed so far."
- pass@k: The probability (or expected fraction) of tasks solved in at least one of k independent attempts. "We report the expected worlds passed from independent attempts as pass@."
- phase space: The combined space of all positions and momenta (or velocities) describing a dynamical system. "The agent must decide which regions of phase space to probe"
- pairwise force laws: Interaction rules defined for forces between pairs of particles. "The worlds are defined by their pairwise force laws"
- response charge: A charge component that controls how strongly a particle feels fields generated by others. "a response charge controlling how strongly it feels the field generated by others."
- RK4: The classical fourth-order Runge–Kutta method for numerically integrating ordinary differential equations. "RK4, 4th- and 6th-order Yoshida"
- rubric: A scoring guide with defined criteria used to assess explanation quality. "We present each physics world with a rubric of human-labeled explanation scores from ."
- scipy.optimize: A Python library module providing optimization and curve-fitting algorithms. "using scipy.optimize."
- screened forces: Interactions attenuated with distance, often exponentially, yielding short-range behavior. "short-range exponentially screened forces"
- softening term: A small modification to force calculations to avoid numerical singularities at short distances. "A small softening term is added to avoid numerical instabilities."
- source charge: A charge component that determines how strongly a particle generates a field. "a source charge controlling how strongly particle generates the field"
- symmetries: Invariances of a system under transformations, often implying conservation laws. "conservation laws arise from continuous symmetries."
- symplectic: Refers to integrators that preserve the geometric structure of Hamiltonian dynamics (phase-space volume). "We use Yoshida4 by default because it is symplectic, 4th-order accurate"
- symplectic Euler: A first-order symplectic integration method for Hamiltonian systems. "symplectic Euler (kick-drift)"
- trajectory MSE: Mean squared error between predicted and true positions across trajectories, used as an accuracy metric. "Trajectory MSE measures how well the agent's discovered law predicts the dynamics on held-out test particles."
- velocity-Verlet: A specific formulation of the Verlet integrator used for time-reversible, symplectic integration. "leapfrog (velocity-Verlet)."
- Yoshida: Higher-order symplectic composition methods introduced by Haruo Yoshida for accurate long-term integration. "4th- and 6th-order Yoshida \citep{yoshida1990construction}"
- Yukawa: A screened potential (Yukawa interaction) producing short-range forces; used here as a test world. "Noise ablations over the Yukawa (top) and Ether (bottom) worlds"
Collections
Sign up for free to add this paper to one or more collections.