- The paper introduces PhySense, a benchmark that evaluates LLMs' ability to apply core physics principles through principle-based reasoning.
- It systematically tests 7 state-of-the-art LLMs on 380 novel physics problems using diverse prompting strategies to assess accuracy and token efficiency.
- Findings reveal that even reasoning-optimized models underperform compared to human experts, emphasizing the need for deeper integration of physical principles.
PhySense: Principle-Based Physics Reasoning Benchmarking for LLMs
Introduction
The study, titled "PhySense: Principle-Based Physics Reasoning Benchmarking for LLMs," addresses a significant gap in the ability of LLMs to emulate the concise, principle-based reasoning that is characteristic of human experts, particularly in the domain of physics. Despite advancements in LLMs, these models often fail to apply core physical principles for efficient problem-solving, generating solutions that are lengthy and opaque. The paper introduces PhySense, a novel benchmark that aims to test LLMs' capacity to solve physics problems using principle-first reasoning, an approach that is typically straightforward for human physicists but challenging for LLMs.
Figure 1: Illustrating how LLMs use lengthy, complex reasoning for physics problems intuitively straightforward to scientists applying core physical concepts.
Benchmark Design and Methodology
Principle-Based Reasoning
PhySense is designed to systematically evaluate LLMs' use of physical principles such as symmetries, conservation laws, and dimensional analysis. Unlike other benchmarks that focus on domain-specific knowledge or complex calculations, PhySense presents problems that are easily solvable using simple principle-based reasoning. The dataset comprises 380 novel physics problems, categorized by difficulty levels—ranging from undergraduate to research-level complexity—but deliberately avoids advanced mathematical techniques or computationally intensive solutions.
Problem Categories and Models
The benchmark tests LLMs on 19 different problem models that encompass a wide range of physics principles. These include symmetry reasoning in two- and three-dimensional fields, infinite resistive lattice circuits, quantum spin chains, dimensional analysis, and topological phenomena in condensed matter physics. The selection of these models ensures a comprehensive assessment of an LLM's understanding and correct application of fundamental physics principles.
Experimental Setup
Models and Prompting Strategies
The experiment evaluates seven state-of-the-art LLMs, including both reasoning-optimized models and standard models, using three prompting strategies: zero-shot, hint, and no-computation prompts. These different approaches test the LLMs' innate problem-solving abilities, their capacity to utilize explicit guidance, and their ability to prioritize simpler, principle-driven solutions over complex computations.
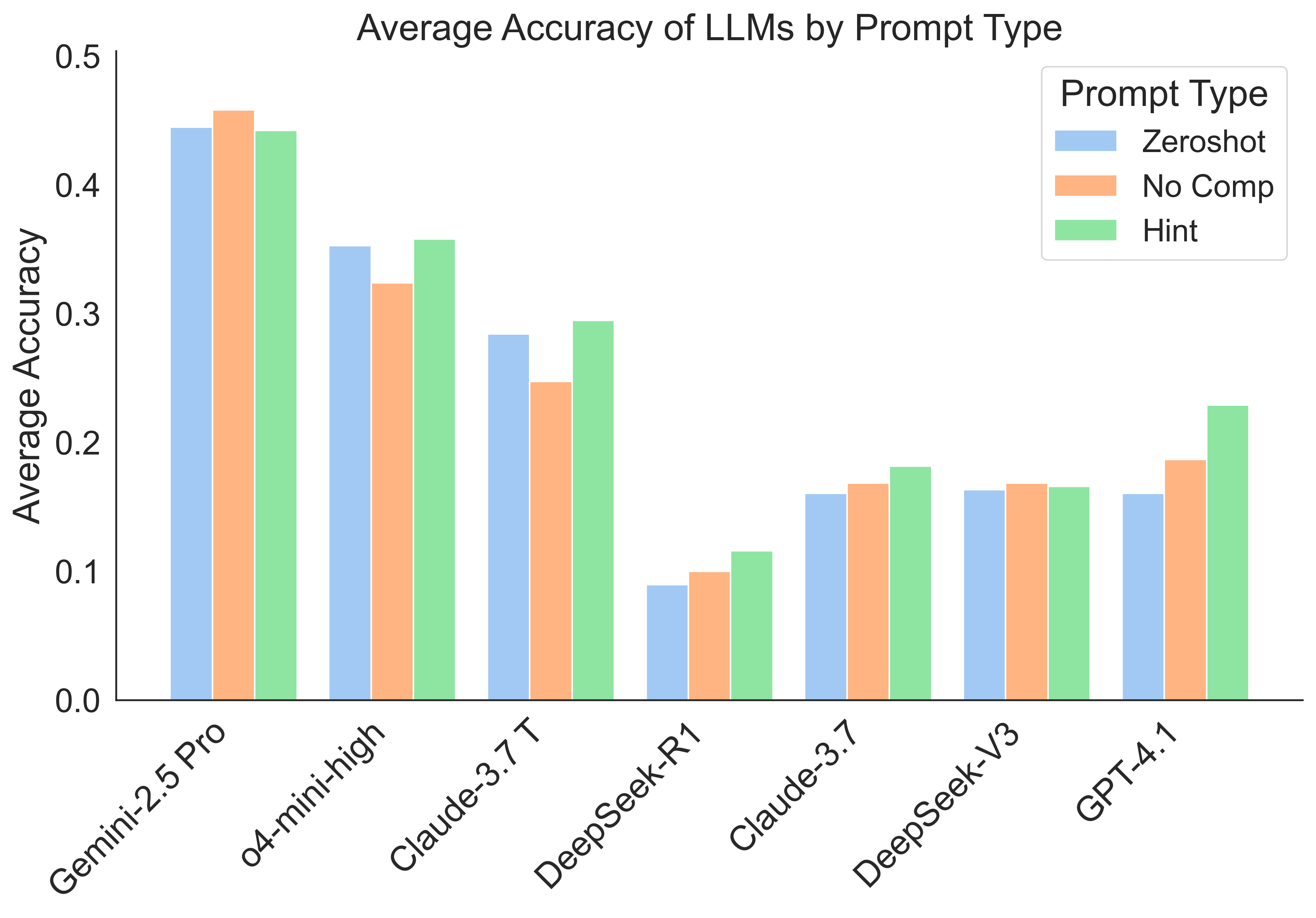
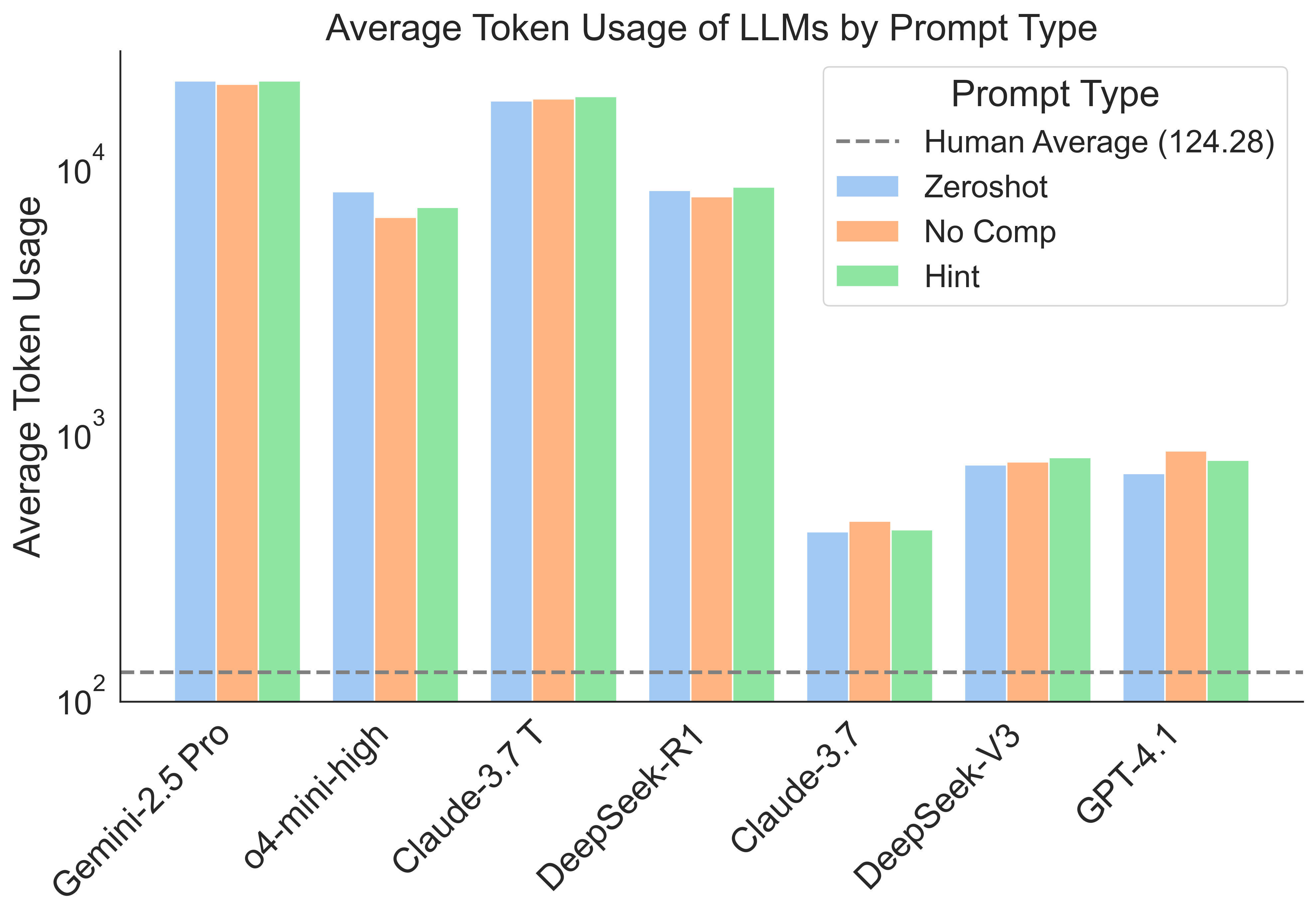
Figure 2: Average accuracy across models.
Results and Analysis
Accuracy and Efficiency
The LLMs' performance is measured by accuracy and token usage, reflecting both the correctness of solutions and the computational resources expended. While reasoning models generally outperform non-reasoning counterparts, all models underperform compared to human physicists, both in terms of accuracy and efficiency. The results highlight significant deficiencies in token efficiency and principled application of physical laws across all evaluated models.
Prompt Impact and Model Comparison
The study reveals minimal improvement in accuracy from auxiliary prompts, suggesting that LLMs' primary errors arise more from misapplication rather than a lack of awareness of physical principles. Additionally, reasoning models demonstrate a better, albeit insufficient, grasp of applying these principles compared to non-reasoning models, which often default to superficial pattern recognition.
Conclusion and Future Directions
The introduction of PhySense represents a pivotal step in evaluating and improving principle-based reasoning in LLMs. Despite some superiority of reasoning models over their non-reasoning counterparts, there remains a substantial gap in performance relative to expert human reasoning. The study suggests that future development should focus on deeper integration of principle-based thinking within LLMs, possibly through supervised fine-tuning or reinforcement learning. It offers critical insights for the design of LLMs with enhanced capabilities for efficient, robust, and interpretable scientific reasoning, essential for advancing AI's role in scientific discovery.