- The paper presents a comprehensive benchmark and auto scoring framework (PSAS) for evaluating physics-based reasoning in LLMs.
- Key methodology includes multi-modal problems with an average of 8.1 steps per question and categorization into easy, medium, and hard levels.
- Results indicate that while O-like models outperform non-O-like models, all models face performance drops with increasing problem complexity.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Introduction to PhysReason
The paper presents PhysReason, a benchmark explicitly designed to evaluate the physics-based reasoning capabilities of LLMs. Unlike traditional benchmarks focusing on mathematics and logical reasoning, PhysReason emphasizes physics-based reasoning, a complex task that necessitates the application of physics theorems and adherence to physical constraints. This benchmark consists of 1,200 problems, with 25% being knowledge-based and the remaining 75% reasoning-based, categorized into easy, medium, and hard levels. PhysReason introduces a sophisticated evaluation framework—the Physics Solution Auto Scoring Framework (PSAS)—which incorporates both answer-level and step-level evaluations.
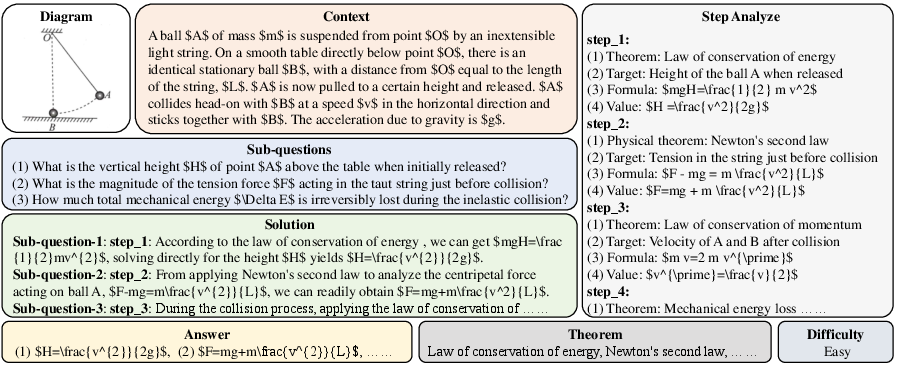
Figure 1: An illustration of example from our PhysReason benchmark. Due to space constraints, only key components are shown.
Benchmark Composition and Characteristics
PhysReason's problems are meticulously curated to cover a broad spectrum of physics domains including classical mechanics, quantum mechanics, thermodynamics, and more. The problems require multi-step solutions, averaging 8.1 steps per problem, with hard problems requiring up to 15.6 steps. This complexity surpasses existing physics benchmarks which typically involve around 3-4 steps.
The benchmark's multi-modal design integrates visual components into 81% of the problems, providing a comprehensive assessment of a model's ability to parse and understand both textual and visual information. Three critical solution metrics—solution steps, theorems used, and text length—demonstrate a strong positive correlation with problem difficulty, validating the classification into easy, medium, and hard problems.
Figure 2: Analysis of solution theorems, solution steps, and solution tokens across different problem categories, with comparisons from SciBench, GPQA, and OlympiadBench.
Evaluation Framework: PSAS
PhysReason employs the Physics Solution Auto Scoring Framework (PSAS) to provide detailed assessments of models' reasoning capabilities. PSAS is divided into two main components:
- Answer-Level Evaluation (PSAS-A): This component evaluates whether model-generated answers to sub-questions are semantically consistent with standard answers, weighted by the lengths of the solution steps.
- Step-Level Evaluation (PSAS-S): PSAS-S conducts a detailed evaluation of each reasoning step, identifying where and how models deviate from correct solutions. The PSAS-S framework advances beyond simple answer correctness, pinpointing critical areas such as theorem application errors and calculation inaccuracies.
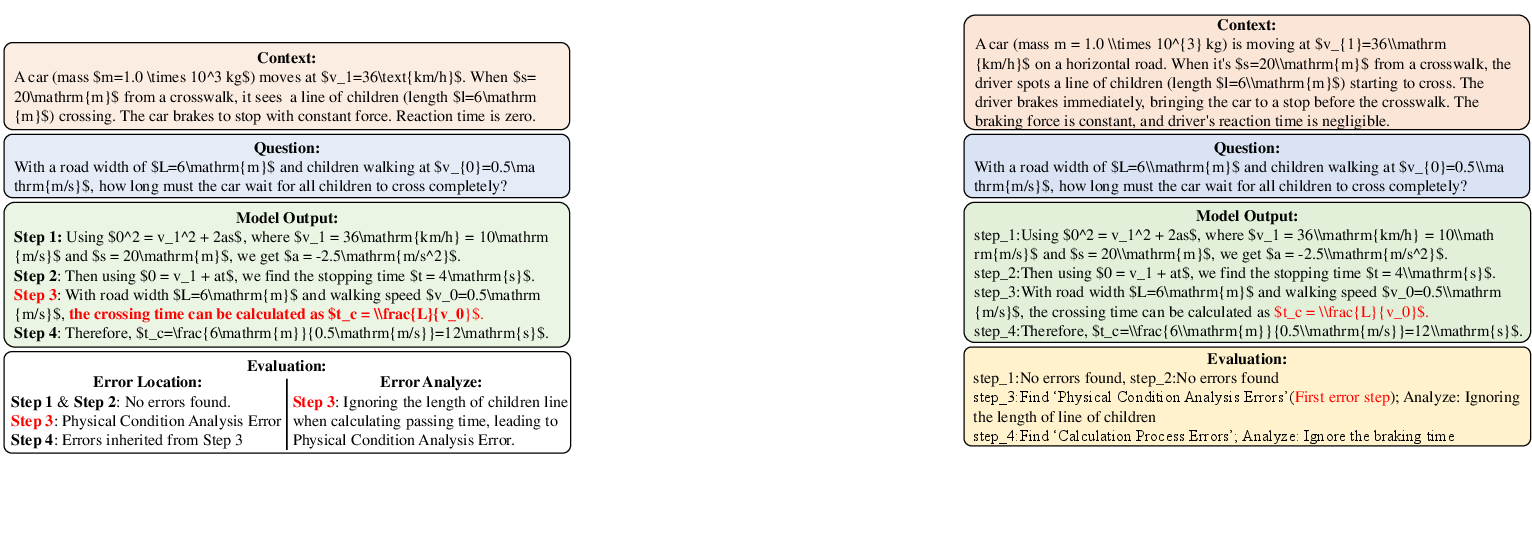
Figure 3: Step-level evaluation example obtained from PSAS-S framework.
Model Evaluation and Insights
The paper evaluates several mainstream models, including non-O-like and O-like models, on the PhysReason benchmark. O-like models consistently outperform their non-O-like counterparts, especially in more complex reasoning tasks. However, all models show a notable performance decline as problem difficulty and required solution steps increase.
The step-level evaluation reveals that models often possess partial knowledge, making correct initial reasoning steps but failing to maintain accuracy through to the solution's conclusion. Four primary bottlenecks are identified: Physics Theorem Application, Physics Process Understanding, Calculation Process, and Physics Condition Analysis.
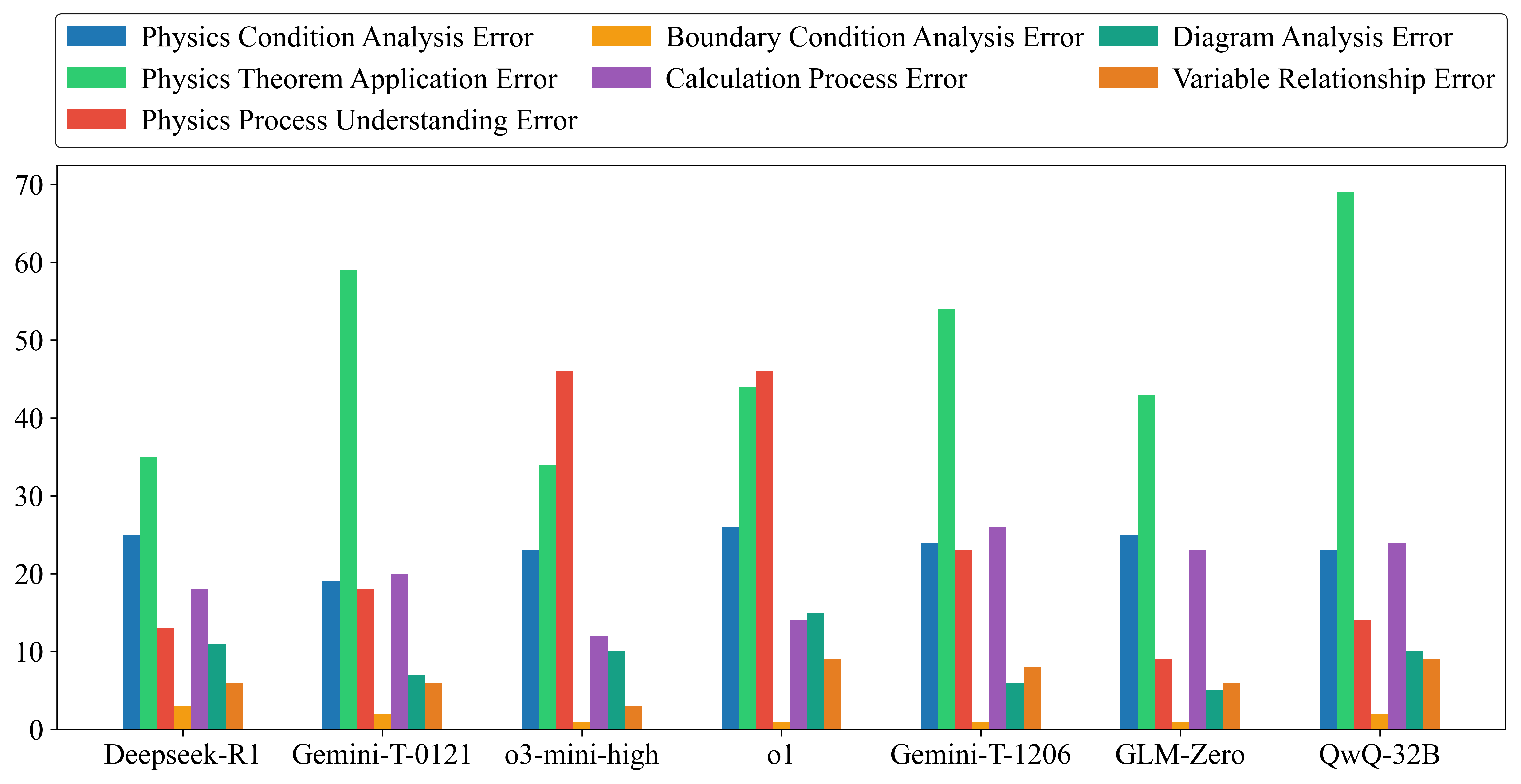
Figure 4: Error statistics with PSAS-S framework in PhysReason-mini, where Gemini-T-1206 and Gemini-T-0121 denote Gemini-2.0-Flash-Thinking-1206 and Gemini-2.0-Flash-Thinking-0121.
Test-Time Compute Scaling
The study explores test-time compute scaling methods such as Best-of-N (BoN) and Tournament-Style selection, which involve selecting the best response from multiple candidates generated by the models. These techniques demonstrate that strategic response selection can effectively enhance model performance on complex reasoning tasks.
Conclusion
PhysReason represents a significant development in benchmarking the physics-based reasoning capabilities of LLMs, offering a detailed and challenging set of problems and evaluations. The benchmark's ability to reveal key reasoning deficiencies in current models suggests important directions for future research in improving models' reasoning capabilities. By providing a comprehensive dataset and a rigorous evaluation framework, PhysReason establishes a new standard for assessing and guiding the development of LLMs in physics-based reasoning.
Overall, PhysReason highlights the necessity for models to not only possess factual knowledge but also to apply it accurately in complex reasoning tasks—a critical step toward advancing AI towards true scientific understanding and capability.

