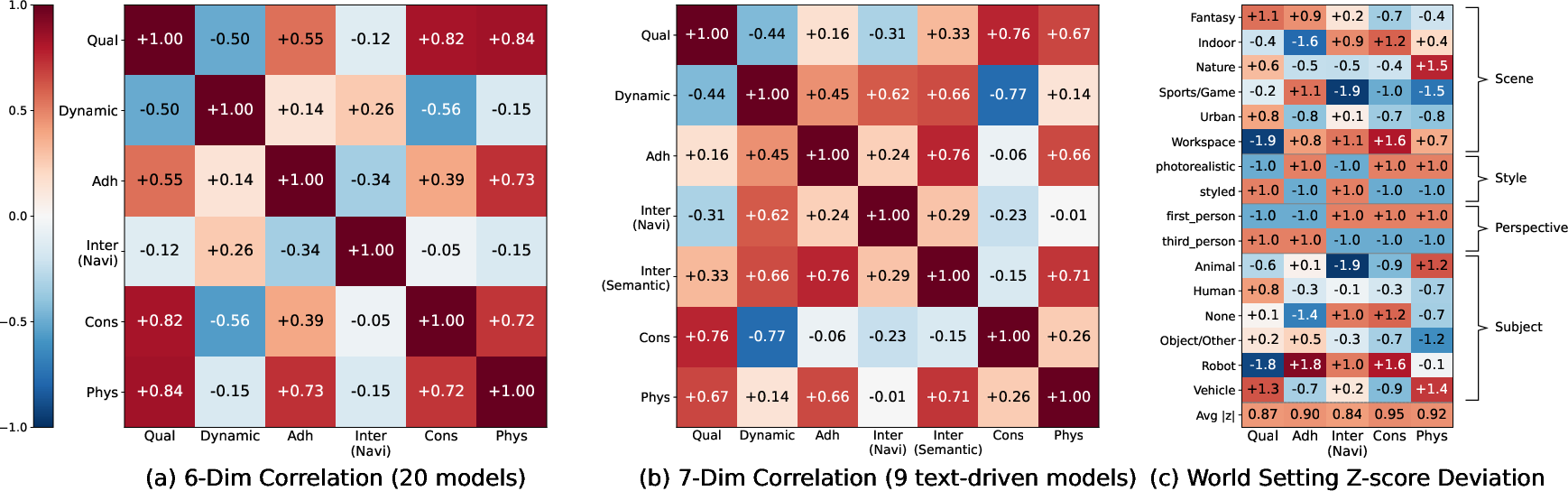
- The paper presents a comprehensive benchmark that evaluates interactive video world models across five key dimensions including navigation, quality, and physics compliance.
- It introduces multi-turn interaction sequences that test models on aspects such as visual rendering, spatial-temporal consistency, and adherence to physical rules.
- Experimental results reveal trade-offs between rendering quality, controllability, and stability, underscoring the need for advanced world model architectures.
WBench: A Unified Multi-turn Benchmark for Interactive Video World Model Evaluation
Motivation and Benchmark Scope
The rapid development of interactive video world models has necessitated rigorous benchmarking protocols capable of evaluating diverse competencies such as visual quality, controllability, long-horizon consistency, world state persistence, and compliance with physical rules. Existing evaluation suites remain fragmented, often covering only subsets of these axes and lacking unified protocols across open-domain scenes, first-/third-person perspectives, and multi-turn closed-loop interactions. WBench addresses this gap by providing a comprehensive, multi-turn benchmark spanning the full spectrum of required capabilities for interactive world models.
WBench decomposes evaluation into five complementary dimensions: video quality, setting adherence, interaction adherence (including navigation, subject action, event editing, and perspective switching), temporal and spatial consistency, and physics compliance. The benchmark contains 289 cases (1,058 interaction turns), sampling diverse scenes, rendering styles, subject categories (human, animal, robot, vehicle, object), and both first- and third-person perspectives, with rich scene-action taxonomies and unified navigation protocols (text, pose, discrete action). The evaluation suite utilizes 22 automatic sub-metrics, combining domain-expert vision models and large multimodal models (LMMs), and validates them against human judgments.
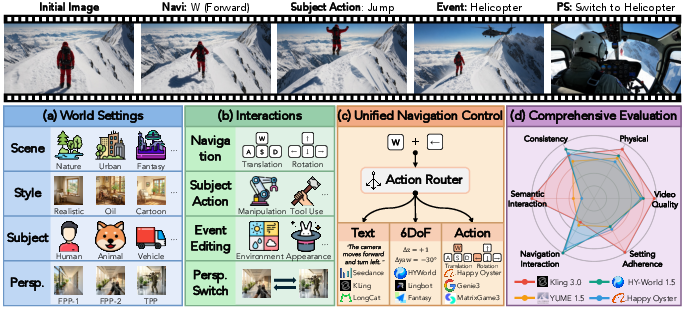
Figure 1: Overview of WBench: multi-turn test cases, taxonomy, unified navigation protocols, and five evaluation axes.
Dataset Design and Taxonomy
Each test case is specified via an explicit world setting (scene, style, perspective, subject) and a multi-turn interaction sequence encompassing four interaction types:
- Navigation: Discrete WASD and arrow-based actions mapped to perspective-specific camera or subject movements, enabling assessment of spatial controllability and geometric consistency.
- Subject Action: Manipulation, locomotion, tool use, combat, and gestural interactions, stressing model capacity for coherent agent behavior and action grounding.
- Event Editing: Scene/environmental changes (e.g., weather, object appearance, mechanical transitions), probing the model’s ability to maintain causal continuity and respond to exogenous events.
- Perspective Switching: Transitions across first-/third-person and scope-modes, challenging models to preserve identity, spatial reference, and consistent world structure across viewpoint changes.
The dataset achieves stratified coverage across scene, style, perspective, subject, and interaction taxonomies, with manual review for prompt-frame consistency and multi-turn coherence. Spatial and temporal diversity is maximized, with interaction sequences designed to probe long-horizon memory and world state persistence.

Figure 2: Scene and style coverage across photorealistic and stylized renderings for all major environment categories.

Figure 3: Style gallery demonstrating the range of rendering appearances tested: realistic, anime, cartoon, oil painting, ink wash, flat, pencil sketch.

Figure 4: Perspective gallery distinguishing first-person (disembodied/embodied) and third-person configurations.

Figure 5: Subject gallery encompassing humans, animals, vehicles, robots, and miscellaneous objects.
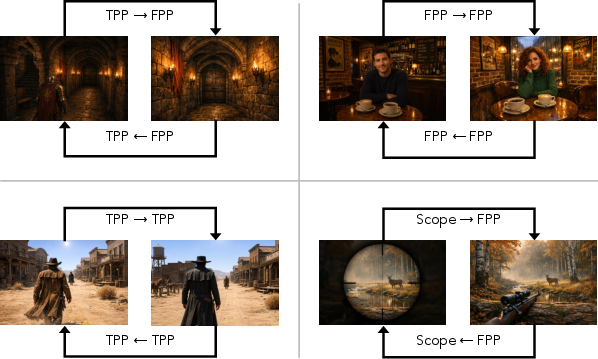
Figure 6: Perspective-switching taxonomy samples: same-subject, multi-subject, and scope/scale transitions.
Evaluation Protocol and Metric Suite
WBench employs a dual-track evaluation protocol for fair cross-paradigm comparison:
- Navigation Track: All models (text-driven, camera-controlled, action-conditioned) are compared on navigation cases with canonical control mappings.
- Full Benchmark Track: Text-driven I2V models are additionally evaluated on the full set of cases using iterative last-frame forwarding with multi-turn prompt chaining.
The metric suite includes:
- Video Quality: Objective measures for aesthetics, imaging quality, temporal flicker, dynamic degree, smoothness, and human-preference alignment.
- Setting Adherence: VLM-based scoring for environment and subject coherence, decomposing visible and offscreen elements as well as appearance/action.
- Interaction Adherence: Navigation accuracy via pose estimation and synthetic ground-truth trajectories; VLM-based turn-level binary checks for event editing, subject action, and perspective switching adherence.
- Consistency: Geometric and photometric alignment via depth-based reprojection; spatial roundtrip checks, segment continuity (cut detection), perspective anchoring (subject tracking), intra-turn object and background stability.
- Physics Compliance: Causal fidelity via global/scene-aware axes (fluid/smoke, collision/clipping, surface tracks, deformation, wind, reflection/lighting, human motion); low-level visual plausibility modeled as ordinal judgment regressed by a fine-tuned LMM.
Automated scores are validated against human-preference annotation (400 annotators, triple redundancy, dimension-specific checklists), achieving Spearman ρ≥0.94 across all ten evaluation aspects.

Figure 7: Human-auto ranking alignment: per-model win rates versus automated WBench scores across ten aspects.
Experimental Results: Diagnostic Findings and Model Analysis
Twenty models across three interaction paradigms (text-driven, camera-controlled, action-conditioned) are evaluated, including both closed- and open-source systems (Seedance 1.5, Wan 2.7, Kling 3.0, YUME 1.5, HY-World 1.5, LingBot-World, Happy Oyster, Matrix-Game, Genie 3, etc.).
Key findings:
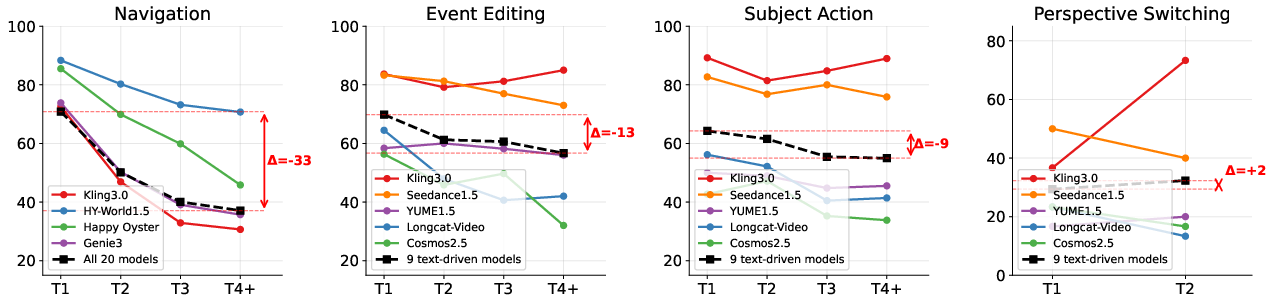
Per-setting analyses reveal structured difficulty: first-person cases and workspace/robot scenes are easier for navigation; sports/game and animal subjects are harder due to complex, non-rigid dynamics.
Physical Compliance: Failure Modes and Decomposition
Physics assessment decomposes causal fidelity into seven dimensions. Reflection/lighting is nearly saturated, while deformation/destruction and fluid/smoke exhibit larger inter-model variation. Scene-aware scoring reveals qualitatively distinct strengths and weaknesses—e.g., LingBot-World excels at human motion and reflection, YUME 1.5 at wind, Wan 2.7 dominates global causal fidelity, but deformation and collision remain challenging.

Figure 10: Qualitative comparisons on physics compliance.
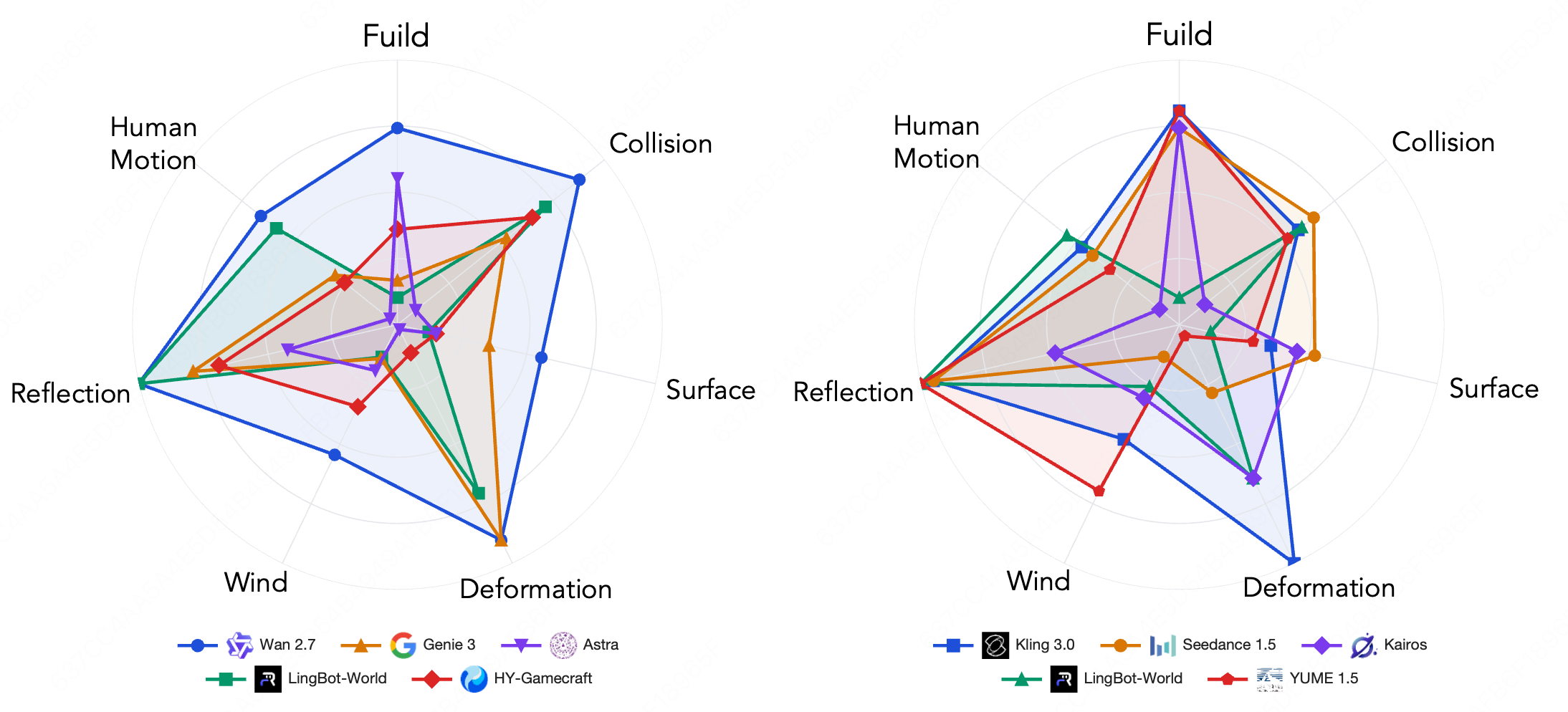
Figure 11: Causal fidelity breakdown by physics dimension and model tier.
Implications, Limitations, and Future Directions
WBench establishes a unified diagnostic baseline for interactive world models, surfacing actionable insights:
- There is no current architecture or training paradigm capable of simultaneously solving high-fidelity rendering, robust closed-loop control, spatial and temporal consistency, and long-horizon causal physics.
- Geometric and semantic memory modules, explicit trajectory representations, and causal context conditioning are promising research directions for world model architectures.
- Joint training on diverse multi-domain, multi-perspective datasets and cross-paradigm prompt alignment may yield further improvements in controllability and generalization.
Limitations include: focus on discrete action sequences, partial reliance on LMMs for semantic and physics scoring, and initial scope confined to benchmarked domains. Extension to continuous control, real-time evaluation, and richer domain transfer are needed.
Conclusion
WBench provides a comprehensive, multi-turn evaluation suite for interactive video world models, advancing the standard for diagnostic benchmarking across rendering, controllability, semantic grounding, spatial consistency, and physics compliance. Results demonstrate significant gaps between current models and the requirements of unified world simulation, suggesting critical avenues for model architecture innovation, data scaling, and metric design. WBench sets a rigorous foundation for future advancement in high-fidelity, reliable, and interpretable interactive video world modeling.