- The paper introduces WorldLens, a unified benchmark evaluating driving world models across five axes and 24 interpretable dimensions.
- It employs a comprehensive methodology combining visual, geometric, and behavioral assessments with both automated and human evaluations.
- Results reveal trade-offs between high 2D visual quality and low 4D functional performance, underscoring the need for holistic, physics-aware model design.
Comprehensive Evaluation of Driving World Models: An Analysis of "Is Your Driving World Model an All-Around Player?" (2605.10858)
Introduction
World models for autonomous driving have achieved significant advances in generating realistic, multi-view dash-cam videos. However, a central challenge persists—visual realism does not necessarily entail geometric, physical, or behavioral fidelity. The increasing reliance on conventional image-based evaluation metrics fails to capture the nuanced requirements of downstream autonomy tasks and human judgment, exposing a critical bottleneck in assessing and advancing generative driving world models. "Is Your Driving World Model an All-Around Player?" (2605.10858) addresses this disconnect by introducing WorldLens, a unified benchmark that evaluates driving world models across five orthogonal axes and 24 interpretable dimensions. The investigation demonstrates that no single existing model dominates every axis, emphasizing the necessity for holistic, physics-aware evaluation and training protocols.
The WorldLens Benchmark: Full-Spectrum Evaluation
WorldLens is designed to provide an exhaustive, multifaceted evaluation protocol for generative driving world models. Rather than relying on isolated visual quality metrics, WorldLens decomposes assessment across five major axes: Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference.
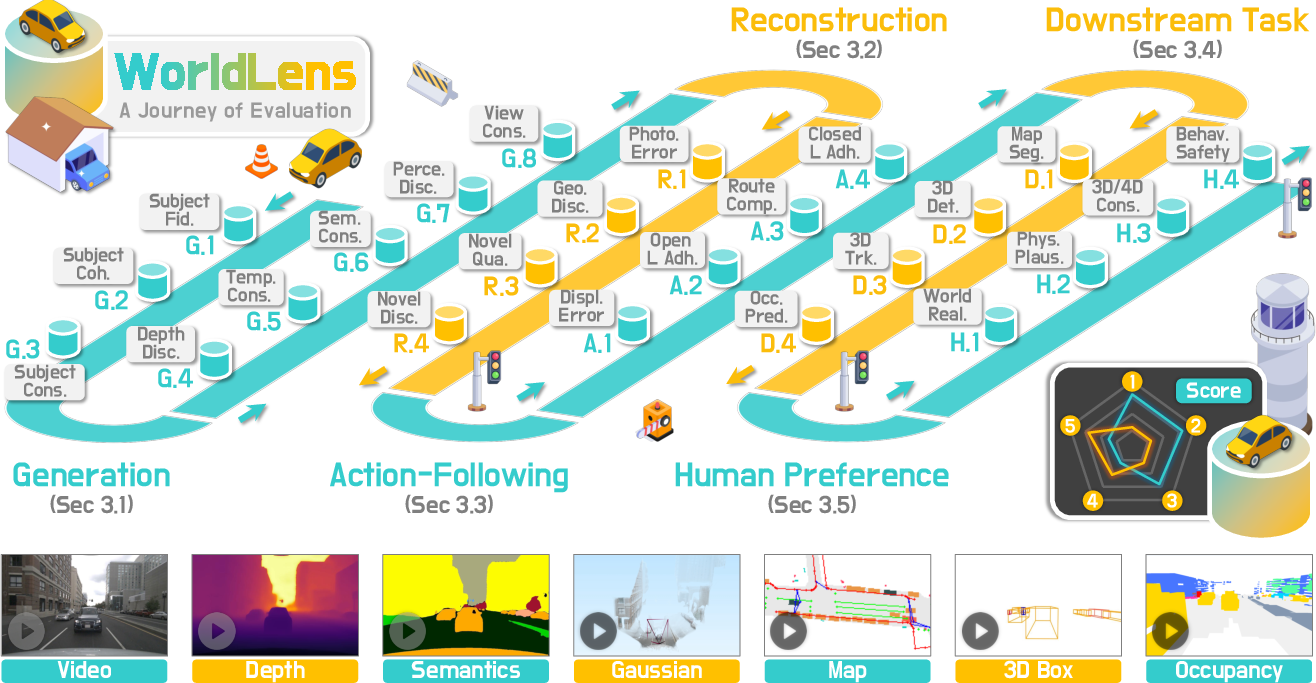
Figure 1: Five complementary aspects—Generation, Reconstruction, Action-Following, Downstream Task, Human Preference—spanning 24 dimensions for exhaustive world model evaluation.
Generation assesses visual realism and temporal stability over individual objects and global scene statistics across eight sub-dimensions, encompassing subject fidelity, identity coherence, depth consistency, semantic alignment, and multi-camera synchronization. Metrics include FID-like perceptual scores, ReID-based coherence, and CLIP- or SegFormer-based stability indices.
Reconstruction probes a model's capacity to generate outputs that can be reliably lifted to geometric 4D representations. This is realized by fitting generated video sequences into 4D Gaussian fields, measuring photometric and geometric errors under both seen and novel viewpoints via LPIPS, PSNR, SSIM, and explicit depth evaluations.
Action-Following interrogates how well generated environments support closed-loop autonomous planning, capturing displacement errors, open-loop and closed-loop adherence, and route completion with direct relevance to real-world driving autonomy.
Downstream Task evaluates whether synthetic data produced by a model advances the performance of critical 3D perception pipelines such as BEV map segmentation, object detection, tracking, and semantic occupancy prediction.
Human Preference incorporates expert human ratings on world realism, physical plausibility, 4D consistency, and behavioral safety, further linking each score to explicit rationales, thus tying quantitative metrics to subjective evaluation.
Dataset and Human-Centric Rationales
The resource-intensive human evaluation underpinning WorldLens was systematically captured as WorldLens-26K, comprising 26,808 rated video entries, each coupled with free-text rationales. Annotator consistency is evidenced by the alignment between word clouds of rationales and target dimensions.

Figure 2: Distribution and semantic focus of WorldLens-26K rationales confirm targeted, consistent annotation.
This data enables not only high-quality direct assessment but also supports the training of a vision-language evaluation agent.
Bridging Human Judgment and Automated Evaluation
To enable scalable, interpretable model evaluation at scale, the authors introduce WorldLens-Agent, a vision-language auto-evaluator. Using LoRA-based SFT on Qwen3-VL-8B, this agent is trained to predict human-aligned ratings and rationales, facilitating automated, dimension-specific assessment for both existing and future models.
Experimental Analysis and Key Results
A comparative analysis across six state-of-the-art models—MagicDrive, DreamForge, DriveDreamer-2, OpenDWM, DiST-4D, and X-Scene—spans all 24 evaluation dimensions. The results reveal several sharp insights:
- No Model Excels Universally: Every model demonstrates trade-offs; texture-focused models frequently violate geometric or physical constraints, while geometry-aware models often underperform in visual appeal or closed-loop control.
- 2D Fidelity Fails for 3D/4D Tasks: Models such as MagicDrive display high 2D visual quality but significant degradation when reconstructed into 4D Gaussian fields, as evidenced by floaters and high photometric errors.

Figure 3: Artifacts and deficiencies in 4D geometric reconstructions expose inconsistencies beyond pixel fidelity.
- Perceptual Quality ≠ Functional Utility: Models optimized for subjective or open-loop visual metrics often degrade critical 3D detection or tracking accuracy in practical pipelines by 30–50%, highlighting the risk of overfitting to image-based metrics.
- Open-Loop vs. Closed-Loop Disparity: Although open-loop performance (e.g., PDMS scores) may appear reasonable ($71$–79%), all models suffer severe degradation (route completion rates <14%) under true closed-loop, feedback-driven simulation.
- Human Scores Remain Modest: Across realism, plausibility, consistency, and behavioral safety, average human ratings remain $2$--$3$ out of $10$, and higher geometric consistency correlates strongly with elevated human realism and safety judgments.
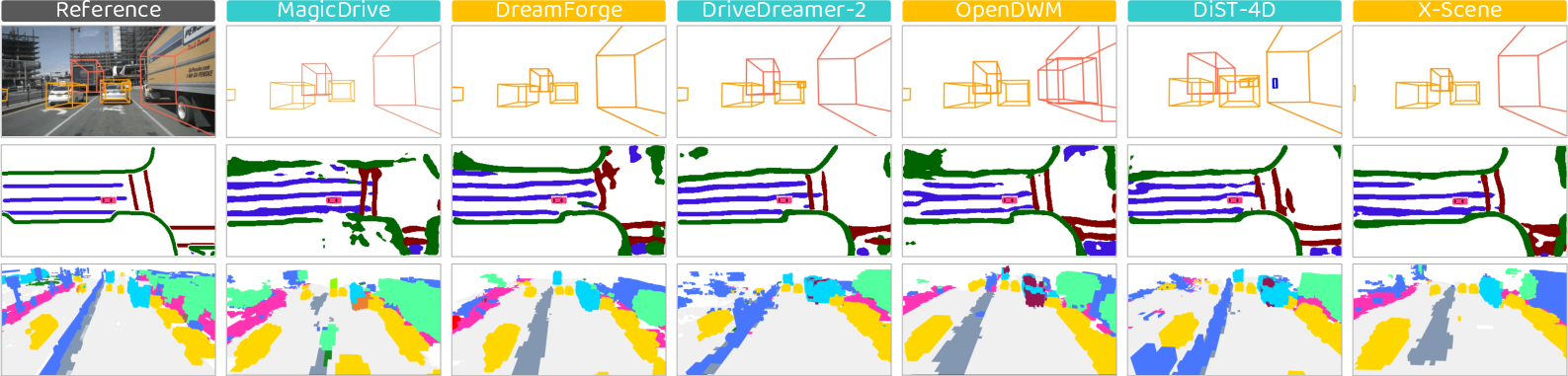
Figure 4: Several downstream perception tasks (3D detection, map segmentation, occupancy) underperform on synthetic data compared to real-world benchmarks.
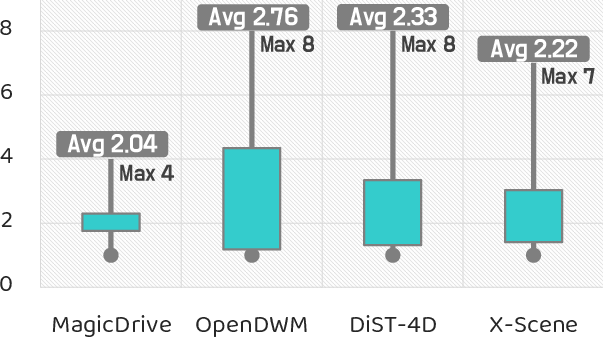
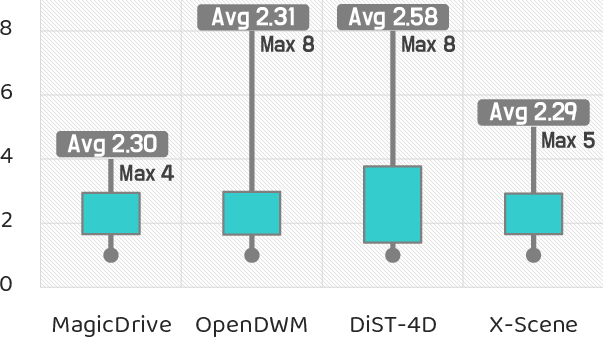
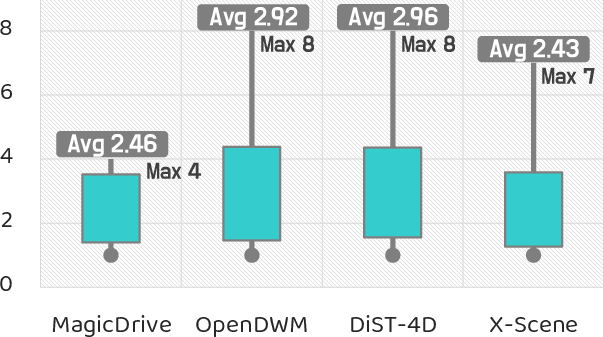
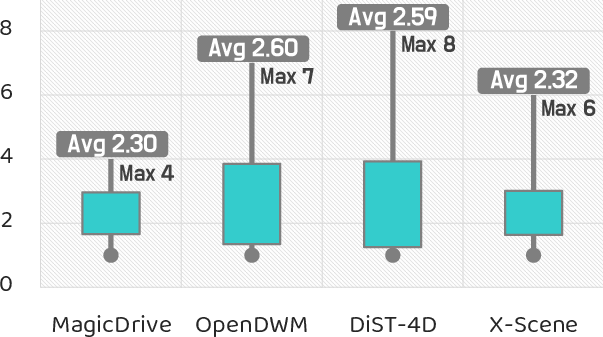
Figure 5: Model realism as perceived by human annotators remains fundamentally limited, highlighting persistent perceptual deficits in current world models.
Implications and Theoretical Insights
This analysis uncovers several actionable design principles for advancing driving world models:
- Treat Geometry as a First-Class Objective: Explicit supervision and metric depth prediction are crucial for bridging the gap between 2D image fidelity and global 4D coherence.
- Joint Optimization of Appearance and Structure: Decoupling texture synthesis from geometric reasoning leads to breakdowns in physical interpretability; future models must unify these objectives.
- Prioritize Closed-Loop Evaluation: Reliable progress in world modeling can only be measured via interactive, agent-in-the-loop protocols, not in isolation.
- Benchmark Comprehensively: Singular or overly narrow metrics fail to reveal trade-offs; a unified protocol like WorldLens is essential for candid model comparison.
From a broader perspective, this paper exposes the urgent need for next-generation benchmarks that move beyond "how real does it look?" to "how real does it function?" in behaviorally relevant, physically plausible, and geometrically consistent ways.
Speculation on Future Directions
The persistent deficiencies quantified across all axes suggest that generative driving world models must evolve towards tightly-coupled, multi-objective learning architectures. The field will likely prioritize advances in:
- Explicitly modeling causality and dynamics, rather than mere appearance.
- Integrating real-world driving simulators and planning agents directly into end-to-end training protocols.
- Employing human-in-the-loop and scalable vision-language evaluators for both training and deployment-time model selection.
- Developing unified, multi-modal benchmarks that extend to LiDAR, map, and multi-agent interaction domains.
These shifts portend a convergence of generative models, simulation platforms, and autonomous planning stacks under comprehensive, physically grounded evaluation.
Conclusion
"Is Your Driving World Model an All-Around Player?" (2605.10858) provides a rigorous, unified protocol—WorldLens—for quantitatively and qualitatively benchmarking generative driving world models. The results establish that no contemporary approach achieves all-around superiority; improvements in appearance often trade off against geometric, physical, or behavioral fidelity. Human ratings remain low, and closed-loop failures are universal. The introduction of WorldLens-26K and WorldLens-Agent bridges automated evaluation with subjective human standards, offering a scalable path forward. These findings make it clear that progress in generative driving world models demands holistic objectives, closed-loop validation, and coordinated advances in benchmark design.
