- The paper introduces a Prover-Verifier protocol that decomposes LLM responses into sub-claims to determine answer trustworthiness.
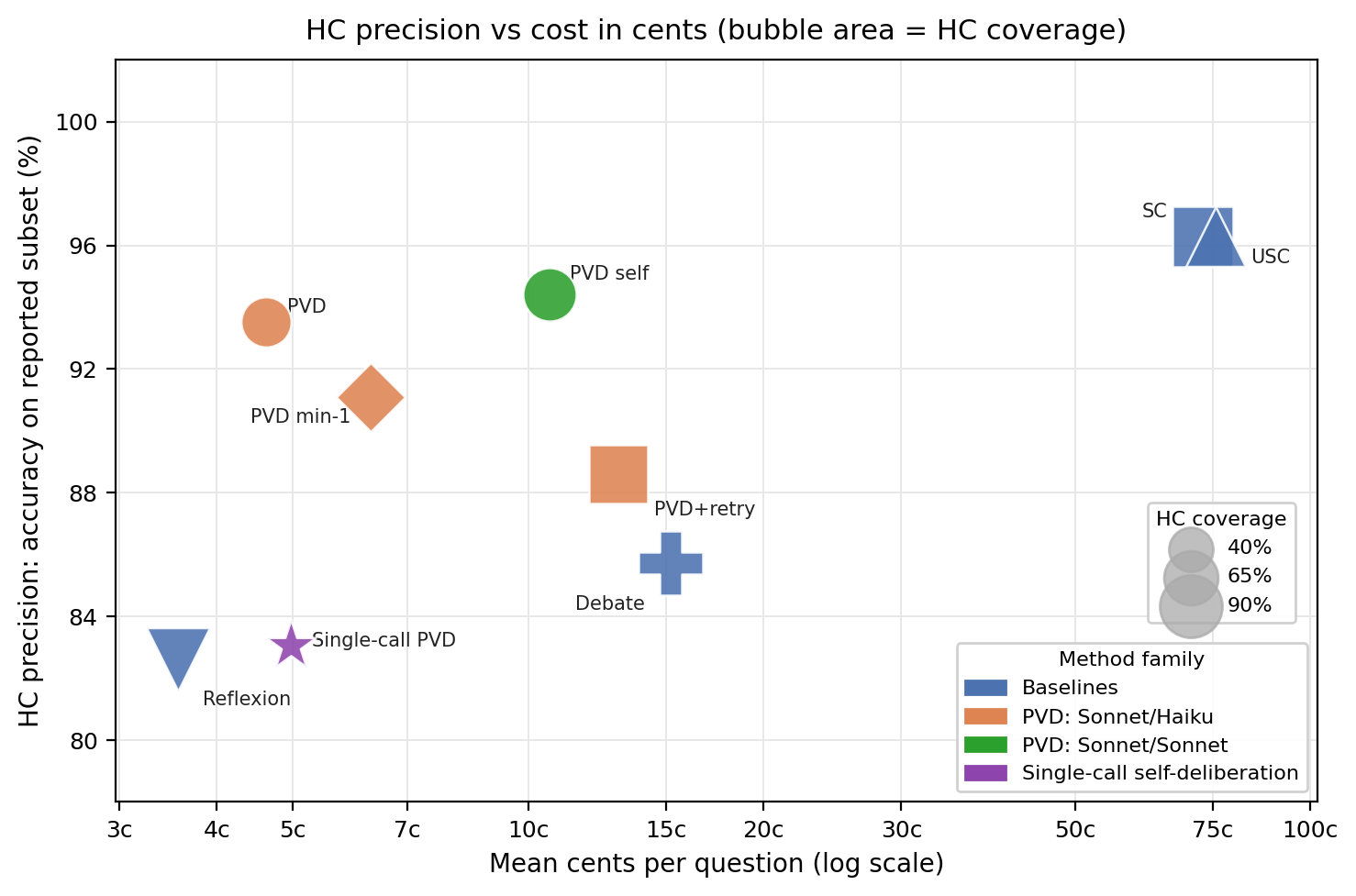
- It demonstrates that structured deliberation achieves high coverage and precision at a lower computational cost compared to ensemble methods.
- The study reveals that verifier competence and strictness are pivotal in ensuring reliable abstention and actionable diagnostics for deployment.
Prover-Verifier Deliberation for Selective LLM Prediction
Motivation and Background
The paper "Trust but Verify: Prover-Verifier Deliberation for Selective LLM Prediction" (2605.25133) addresses selective prediction for LLMs—a problem where a model must reliably indicate when its answers are trustworthy, enabling abstention on cases where confidence is low. While inference-time reasoning strategies (e.g., chain-of-thought, self-consistency, debate, Reflexion) enhance accuracy, their confidence signals are indirect or insufficient for structured abstention. By grounding the approach in interactive proof theory, the authors instantiate a protocol where a Prover defends a candidate answer through atomic sub-claims while a Verifier challenges and either Accepts, Challenges, or Rejects the answer. Empirical evaluation replaces formal completeness/soundness, measuring whether the protocol reliably separates correct from incorrect answers via coverage-precision operating points.
Protocol Design and Theoretical Considerations
Prover-Verifier Deliberation (PVD) is a multi-round, challenge-guided selective prediction framework. The Prover decomposes its answer into structured atomic sub-claims and a reasoning chain, while the Verifier issues targeted skepticism, requesting deeper substantiation of the weakest sub-claim or terminating with Accept/Reject. The Accept + No Change (ANC) subset—the answers accepted without revision—defines the high-confidence reported set. Fatigue and retry limits cap deliberation rounds and failed attempts, with majority vote fallback for non-ANC cases.
Classically, interactive proofs guarantee soundness/completeness if the verifier is effective; with frozen LLMs, such guarantees break down. The empirical focus is "effective verifier" regions—domains where the verifier's independent competence facilitates non-trivial challenge. The protocol is strictly asymmetric: Prover bears the burden of proof, Verifier maintains skepticism with only local evaluation of the argument.
Experimental Results
Evaluation benchmarks are GPQA Diamond (graduate-level science questions) and Humanity's Last Exam (expert academic questions). The main metrics are high-confidence coverage (HC-Cov) and precision (HC-Prec), with the gap (difference between HC-Prec and the complement subset's accuracy) quantifying selective signal strength.
On GPQA Diamond, PVD achieves:
Domain breakdowns reveal strong ANC gaps in Chemistry and Physics, contingent on the verifier's domain expertise. Comparing baselines:
- Self-Consistency achieves high precision (~91.5%) with greater compute cost (8 calls per question); PVD yields similar or superior coverage/precision at a fraction of compute.
- Debate, Reflexion, and Universal Self-Consistency select different question subsets; overlap analysis shows PVD and SC agree on ~54% of questions (96.3% joint accuracy), with partially distinct error profiles.
On Humanity’s Last Exam, pairing weaker provers/verifiers (Sonnet 4.6/Haiku 4.5) collapses or inverts the ANC gap, a diagnostic for ineffective deliberation outside the verifier’s domain competence. The strongest GPT-5.5/Gemini 3.1 Pro pairing achieves HC-Prec 59.0% at HC-Cov 52%, gap +27.9pp.
Discussion and Analysis
Argument defensibility in PVD is empirically more informative than stability or sample agreement. Logical inconsistency, reasoning slip, and insufficient domain knowledge are readily exposed by competent verifiers, leading to large selection gaps. PVD's selection signal is not a proxy for output stability—Reflexion's high coverage has negligible selection gap, demonstrating that repeated output consistency is insufficient for reliable abstention. Model separation and multi-round challenges reinforce defensibility as a correctness signal, showing advantage over single-model self-deliberation.
Verifier competence and strictness critically impact signal strength; permissive or uninformed verifiers degrade the gap. The protocol’s cost-coverage frontier demonstrates controllability: stricter verifiers or retry-based variants trade increased compute for more robust coverage.
Comparison with self-consistency shows partial complementarity. Ensemble signals (intersection of ANC and SC consensus) sharpen coverage-precision tradeoff, suggesting utility in multimodal abstention workflows. Structured re-deliberation (restarting PVD until ANC) may further optimize selective calibration.
Practical and Theoretical Implications
PVD introduces a low-cost, inference-time calibration mechanism for selective LLM prediction, requiring neither additional training nor ground-truth labels. Its structured report/abstain protocol enables downstream escalation—non-ANC questions can trigger more capable models or human review, and system deployment can exploit coverage-precision tradeoffs. The empirical collapse of the ANC gap serves as a diagnostic for regions where verifier capability is insufficient. The architectural implication is that structured selective prediction is feasible without ensemble budgets or reward head training, and that cost-efficient, verifier-mediated deliberation yields actionable reliability signals.
Theoretically, PVD situates practical selective prediction within the framework of interactive proofs, but forfeits formal guarantees; future extensions might explore learned selectors, ensemble approaches, or hybrid methods combining argument defensibility with output agreement.
Future Directions
Potential research avenues:
- Extending PVD to open-ended generation, multilingual QA, or long-form synthesis.
- Developing learned selectors combining ANC signal, round counts, answer revisions, and agreement metrics.
- Systematic exploration of verifier strictness, domain adaptability, and cross-family pairings.
- Open-weight model benchmarks and reproducible experiments, mitigating proprietary model drift.
- Integration with conformal risk-control and selective classification protocols.
- Embedding PVD in multi-stage cascading systems for robust deployment.
Conclusion
The Prover-Verifier Deliberation protocol operationalizes interactive proof structure for LLM selective prediction, empirically establishing argument defensibility as a sharp selective calibration signal. Coverage-precision and gap metrics demonstrate reliable abstention and actionable deployment diagnostics. Verifier competence, strictness, and protocol parameters modulate efficacy. PVD’s structured deliberation approach yields competitive calibration with lower inference cost relative to ensemble baselines, advancing practical selective prediction for LLMs and offering principled mechanisms for deployment deferral and trust calibration.