- The paper presents Lngram, a latent-space N-gram memory module that offloads static matching to improve effective network depth in Transformer architectures.
- It introduces a three-stage pipeline—discretization, retrieval, and context-aware readout—that enhances performance on language and multimodal tasks with minimal overhead.
- Empirical evaluations show consistent gains in language modeling, long-context tasks, and domain-specific adaptation, outperforming baseline models on key benchmarks.
Lngram: N-gram Conditional Memory in Latent Space
Background and Motivation
Sequential models, especially Transformer architectures, achieve compositional reasoning and local pattern retrieval through entirely dense computation. This conflation leads to inefficient utilization of model depth, as local static matching (e.g., multi-token entity recognition) consumes layers better reserved for dynamic global reasoning. Previous conditional memory modules such as Engram introduced token-based N-gram lookup, but suffered from reliance on text tokenization, hash collisions, and limited extension to non-text modalities.
Lngram proposes a latent-space approach where discrete retrieval keys are learned directly from continuous hidden states rather than textual token IDs, enabling precise N-gram conditional memory and extensibility across modalities. This separation allows static retrieval to be refactored into explicit lookup operations, freeing backbone layers for compositional computations and enhancing effective network depth.
Architecture and Training Methodology
Lngram is introduced as a conditional memory branch within Transformer layers. It comprises three principal stages: discretization, retrieval, and context-aware readout.
- Discretization: Continuous hidden states are independently projected and normalized (RMSNorm), then binarized into multiple discrete symbol streams. These are partitioned into routes (typically 4 bits per route), generating parallel latent indices.
- N-gram Retrieval: At each sequence position, exact N-gram keys are constructed from local windows of each route’s symbols. These keys serve as addresses into route-partitioned memory tables, retrieving static vectors by exact lookup.
- Context-aware Readout: Retrieved memory vectors are filtered and fused via contextual gating (dot-product similarity with query hidden state), followed by short-range causal convolutions for enhanced nonlinearity and residual integration prior to attention.
Lngram supports both single-table and multi-table variants, allowing scalable memory capacity and parallel retrieval branches. Training is stabilized via counterfactual surrogate gradients that analytically differentiate local retrieval results with respect to discrete routing logits, circumventing the non-differentiability of hard thresholding.
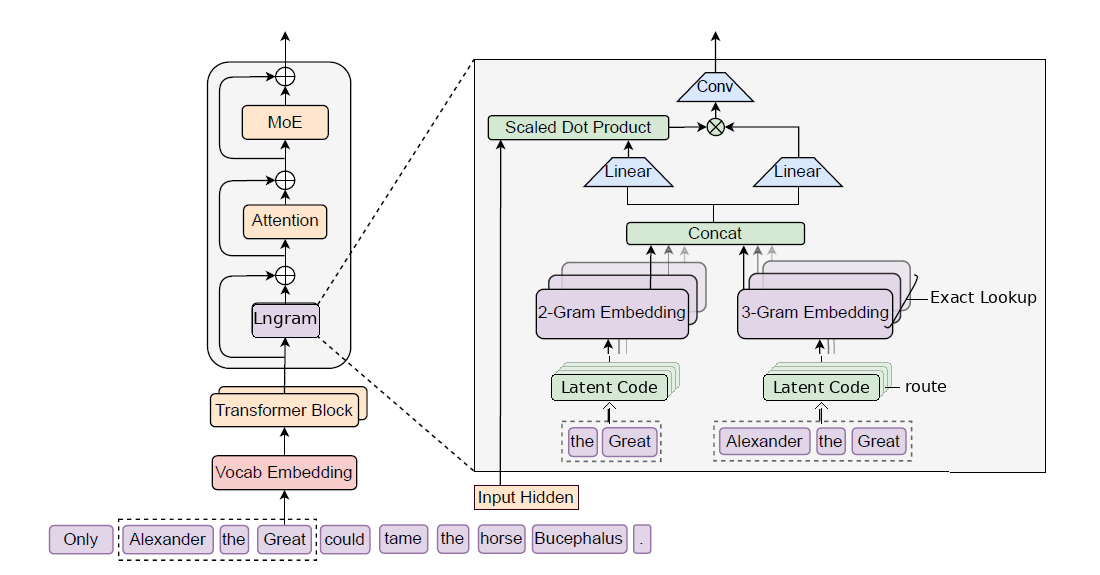
Figure 1: The main architecture of Lngram, illustrating discrete symbol projection, N-gram indexed retrieval, and context-aware readout within Transformer layers.
Empirical Evaluation: Language and Multimodal Tasks
General Language Modeling
Lngram-equipped models (e.g., MoE+Lngram) consistently outperform baseline MoE and Engram variants across benchmarks (HellaSwag, MMLU, SciQ, PIQA, WinoGrande). Statistical bootstrap analysis confirms significance except for WinoGrande. Gains are concentrated in knowledge-intensive and commonsense reasoning tasks, suggesting effective local memory for compositional judgments.
- When scaling data or parameters, Lngram’s performance advantage remains robust, with improvements persisting at both 2B/140BT and 8B/35BT scales.
Long-Context Language Modeling
Lngram-trained models display consistently lower perplexity across all context lengths, especially pronounced for short-medium prefixes, and maintain this advantage even for 64k-token evaluations. Delegating local static patterns to lookup branches allows attention modules to focus on long-range dependencies.
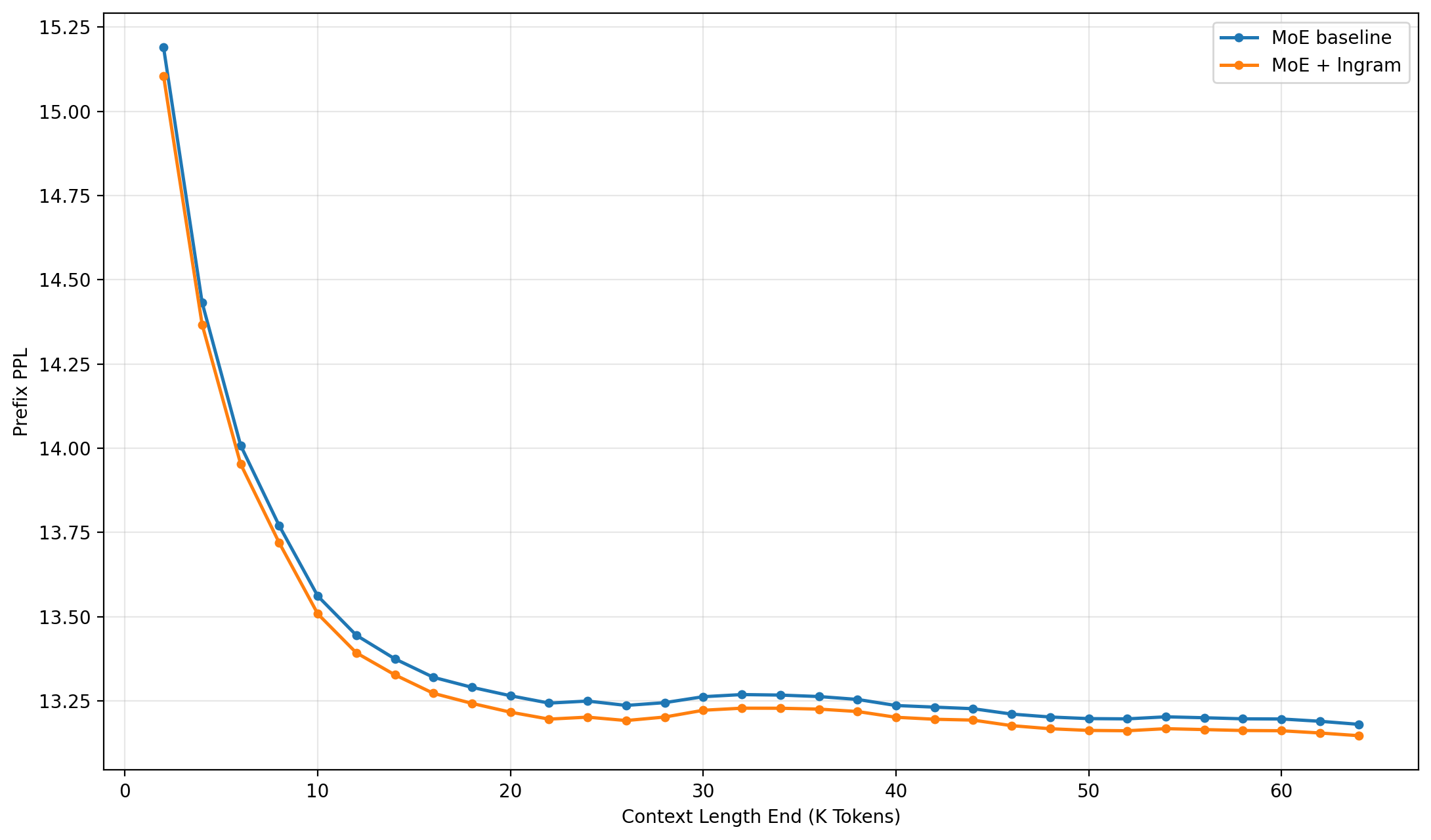
Figure 2: Illustration of prefix perplexity at different context positions in long-context language modeling, showing Lngram’s lower PPL across the sequence.
Domain Knowledge Injection
Lngram can be injected post hoc into pretrained models and trained solely on domain-specific data, achieving domain accuracy near standard full fine-tuning. Joint training yields further improvements. Domain adaptation, however, comes at a modest cost to general benchmark performance, indicating specialization rather than universal augmentation.
Vision-Language-Action (VLA) and Vision-LLMs
Lngram-enhanced VLA and vision-LLMs demonstrate transferable gains in LIBERO and SeedBench evaluations, particularly for Visual Reasoning and spatial tasks. Cross-modal retrieval is enabled by latent-symbol matching, not dependent on tokenization, supporting deployment in image and action domains.
Analysis: Effective Depth and Computational Reallocation
Lngram’s principal effect is to increase effective depth by offloading static matching to memory lookup. This is evidenced by:
- LogitLens Analysis: Lngram reduces KL divergence between intermediate layer outputs and final predictions, indicating emergence of prediction-relevant information in earlier layers.
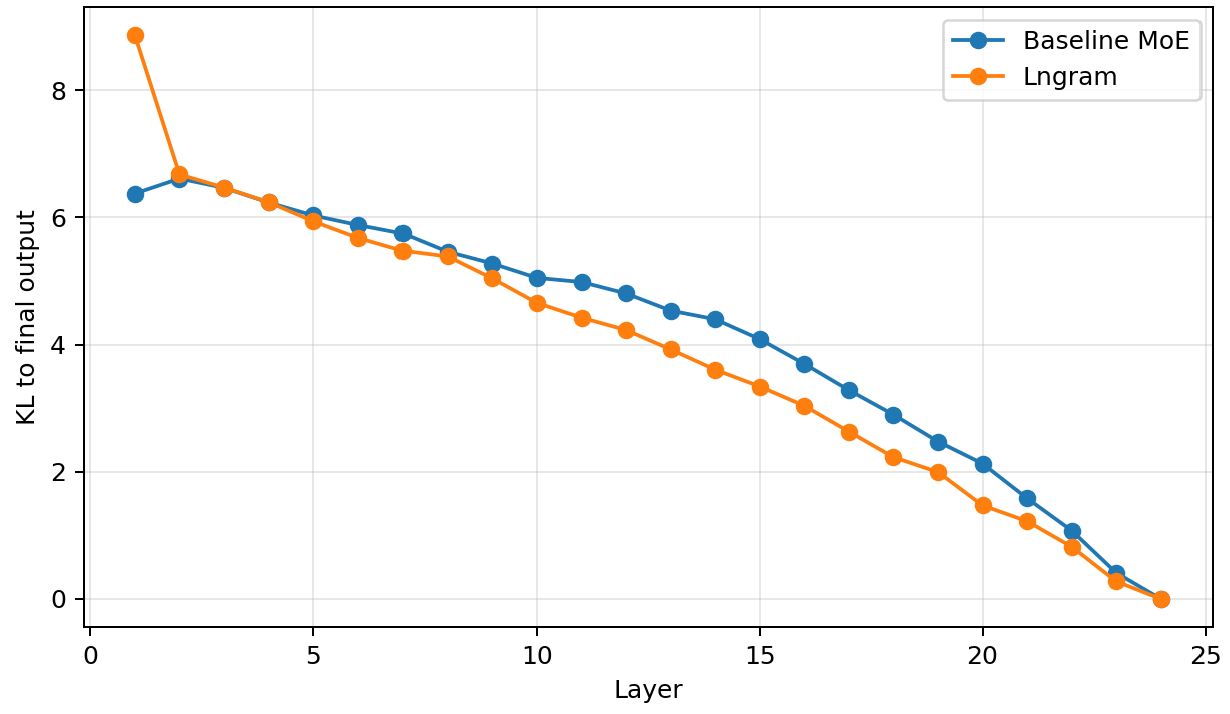
Figure 3: LogitLens KL divergence as a function of layer depth, where Lngram achieves lower divergence after the initial adaptation phase.
- CKA Similarity: Lngram layers align more closely with deeper baseline representations than their nominal layer, yielding +2 to +3 effective depth gains for mid-network layers.
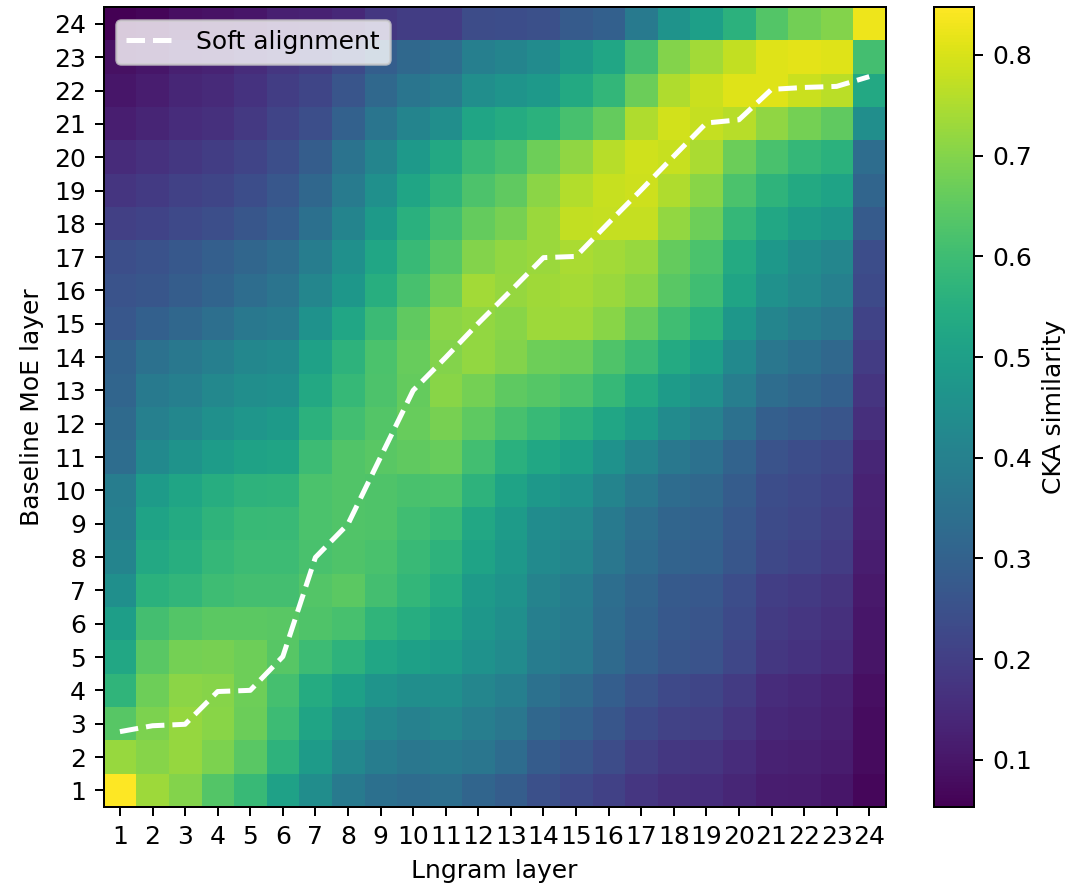
Figure 4: CKA similarity between MoE baseline and MoE+Lngram layer representations; high similarity shifts above the diagonal, showing deeper alignment with baseline.
- Layer Reduction Experiments: Lngram-equipped models with reduced layers maintain or surpass baseline performance (except for some tasks), demonstrating that explicit local memory can replace substantial backbone depth.
- Gate Visualization: Gating responses peak at phrase completion points, e.g., "Great" or "Wales," with readout strength correlated to completed multi-token entities.
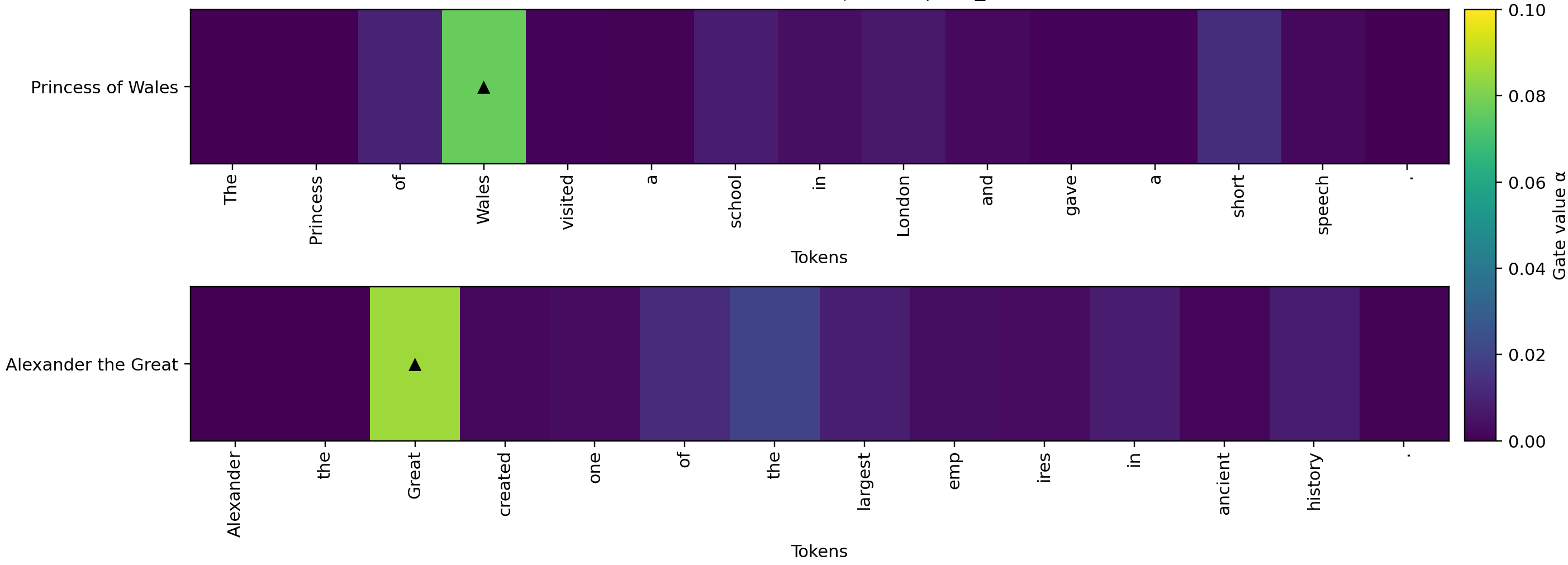
Figure 5: Gating responses for the layer-1 3-gram branch, demonstrating peaks at phrase boundaries such as “Great” and “Wales.”
System Efficiency and Ablation Studies
Lngram introduces minimal inference and memory overhead. Prefill stage throughput increases due to parallelizable lookup, with decode latency rising slightly (≈6.7%) as lookup operations can't be amortized. Memory footprint increment is under 1.5%, and Lngram does not instantiate new caches proportional to generation length.
Ablation studies confirm:
- Optimal performance for joint 2-gram and 3-gram lookup, with 1-gram too coarse and exclusive 3-gram missing shorter patterns.
- Best sparse capacity allocation with Lngram occupying ≈25% of sparse parameters, validating its functional separation from dynamic MoE-MLP computations.
Practical and Theoretical Implications
Lngram demonstrates that functional separation between compositional reasoning and static retrieval improves both representational efficiency and task performance, especially in long-context and domain-specific adaptation regimes. Its memory mechanism is scalable and modality-agnostic, supporting vision-language-action integration as well as classical language modeling.
Theoretically, Lngram reframes key-value memory in Transformers as learnable latent N-gram lookup, breaking free from tokenization constraints and hash-based approximations. This is a step toward conditional computation primitives with latent key learning, potentially reducing dense parameter requirements and system cost in future multimodal architectures.
Future developments may extend Lngram’s matching primitives to richer symbol spaces, dynamic memory allocation, and continual/lifelong learning settings. Integration with vector-symbolic architectures, on-device deployment and fine-grained task adaptation remains an open direction, as does exploration of its compatibility with advanced attention variants.
Conclusion
Lngram introduces latent-space N-gram conditional memory, learning discrete keys from hidden states and performing explicit lookup at low computational and memory overhead. Empirically, it achieves consistent gains in language, vision-language, action, and domain adaptation tasks. It increases effective backbone depth, enables earlier emergence of prediction-relevant features, and provides a scalable retrieval primitive untied to text tokenization. Its architectural decoupling permits efficient reallocation of computational function, marking a substantive step in conditional memory design for next-generation sequence and multimodal models (2605.24869).