- The paper demonstrates that inference-time context sparsity is theoretically justified and empirically maintains performance across diverse LLM tasks.
- It shows that stochastic index selection nearly recovers dense quality at high sparsity levels, highlighting the limits of deterministic top-k methods.
- Hybrid architectures and modern hardware acceleration are leveraged to achieve significant speedup and memory efficiency without compromising output quality.
Inference-Time Context Sparsity in LLMs: Robustness, Efficiency, and Architectural Opportunity
Motivation and Theoretical Foundations
The pervasive compute and memory bottlenecks of attention in LLMs have become increasingly accentuated as context windows scale to 100K+ tokens and workloads demand agentic, retrieval-augmented, and long-form processing. This paper (2605.24168) presents a comprehensive empirical and theoretical investigation questioning the necessity of dense attention along the context dimension and advancing a bold stance: extreme, principled context sparsity is not only achievable but optimal for LLM inference.
The core theoretical result is anchored in the “embedding bottleneck” of attention. For a value matrix V∈RN×d and an attention distribution a over N context tokens, the output o=V⊤a maps the simplex to a d-dimensional hidden space. If d<N−1, this map is non-injective, implying there exist distinct, full-support attention distributions (a,a′) mapping to identical post-attention embeddings. In practical terms, no model with d≪N can differentiate fine-grained token importances across million-token contexts, rendering dense attention fundamentally lossy. Thus, context sparsity is not merely a performance hack; it is an architectural imperative.
Empirical Evidence for Extreme Context Sparsity
Robustness of Large and Hybrid Models
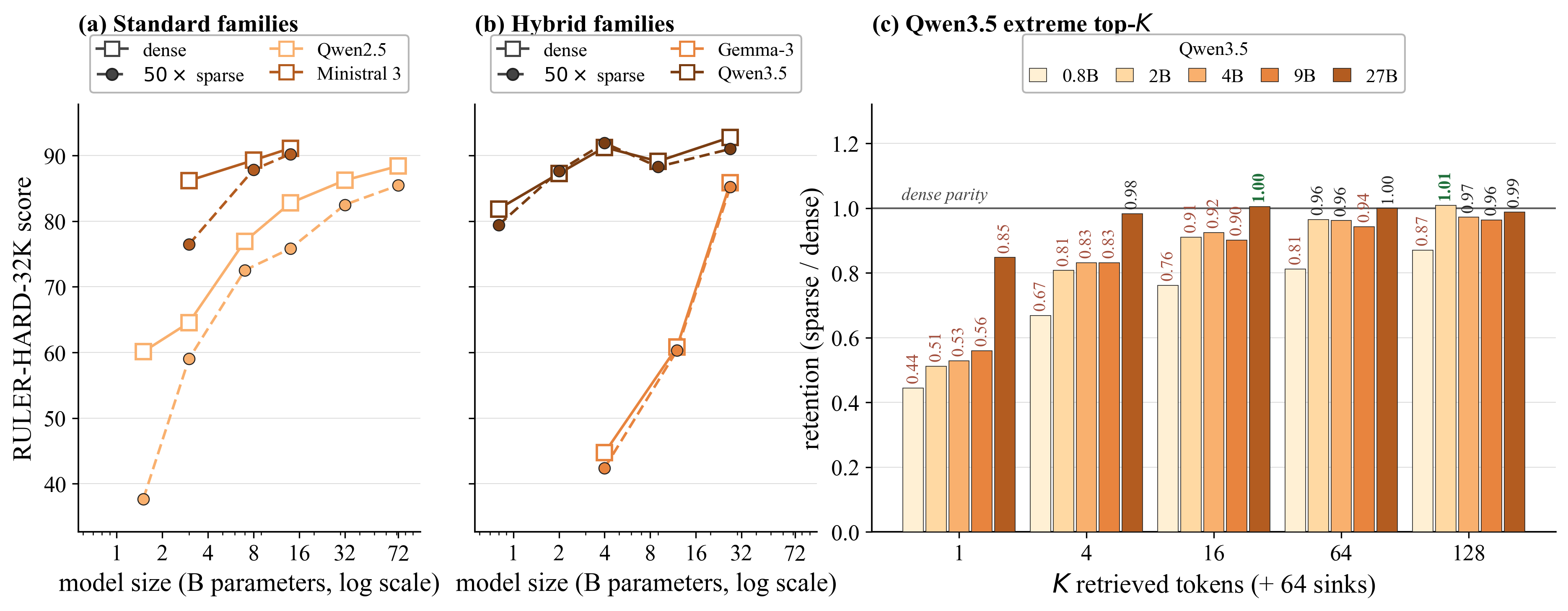
Across 5 model families (Llama3, Qwen2.5, Qwen3.5, Gemma3, Ministral3), 20 models, and diverse benchmarks (retrieval—RULER-HARD, QA/SQL—LOFT, long-form reasoning—AIME2025, agentic coding—SWE-Bench), the authors demonstrate that even inference-time sparsity—where models are forcibly sparsified without training—incurs negligible or no degradation in quality at extreme sparsity levels:
Impact of Sparsity Algorithm
A known issue is that deterministic top-a1 selection fails for smaller, standard transformer models due to diffused attention patterns. This paper shows that stochastic index selection, exemplified by vAttention [desai2026vattention], nearly recovers dense quality at 50a2 sparsity, localizing the problem in conventional top-a3 sparsification to determinism and locality bias rather than sparsity itself.
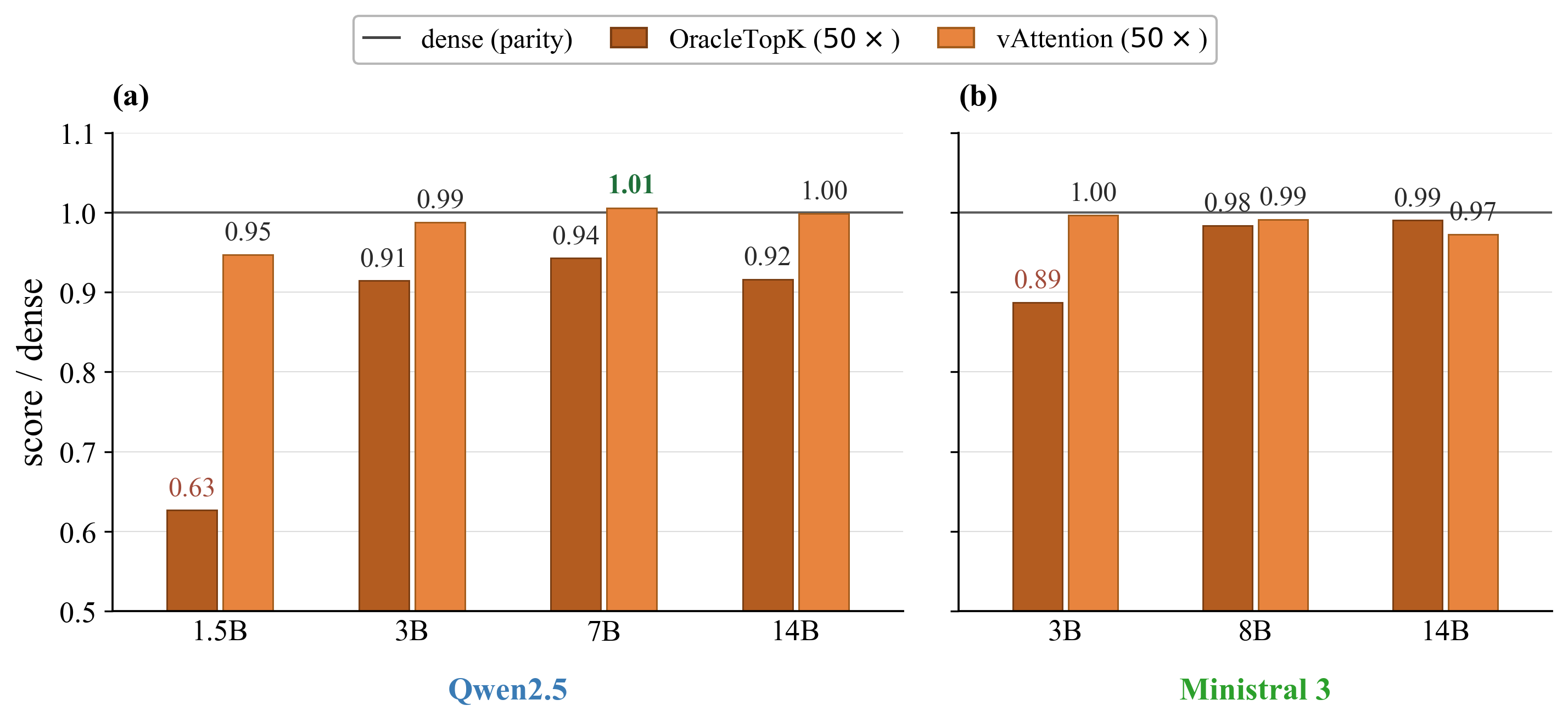
Figure 2: Stochastic vAttention achieves dense parity at 50a4 sparsity; deterministic OracleTopK collapses on small models.
Task Complexity and Long-Horizon Effects
On stringent retrieval tasks (LOFT-128K), mathematical reasoning (AIME2025—up to 65K generation tokens), and agentic coding (SWE-Bench Django—50+ agent turns per task), extreme context sparsity yields robust outcomes. Notably, in long-form generation, the authors show that approximation errors from sparse attention do not compound significantly, and task completion times decrease due to fewer tokens and faster inference.
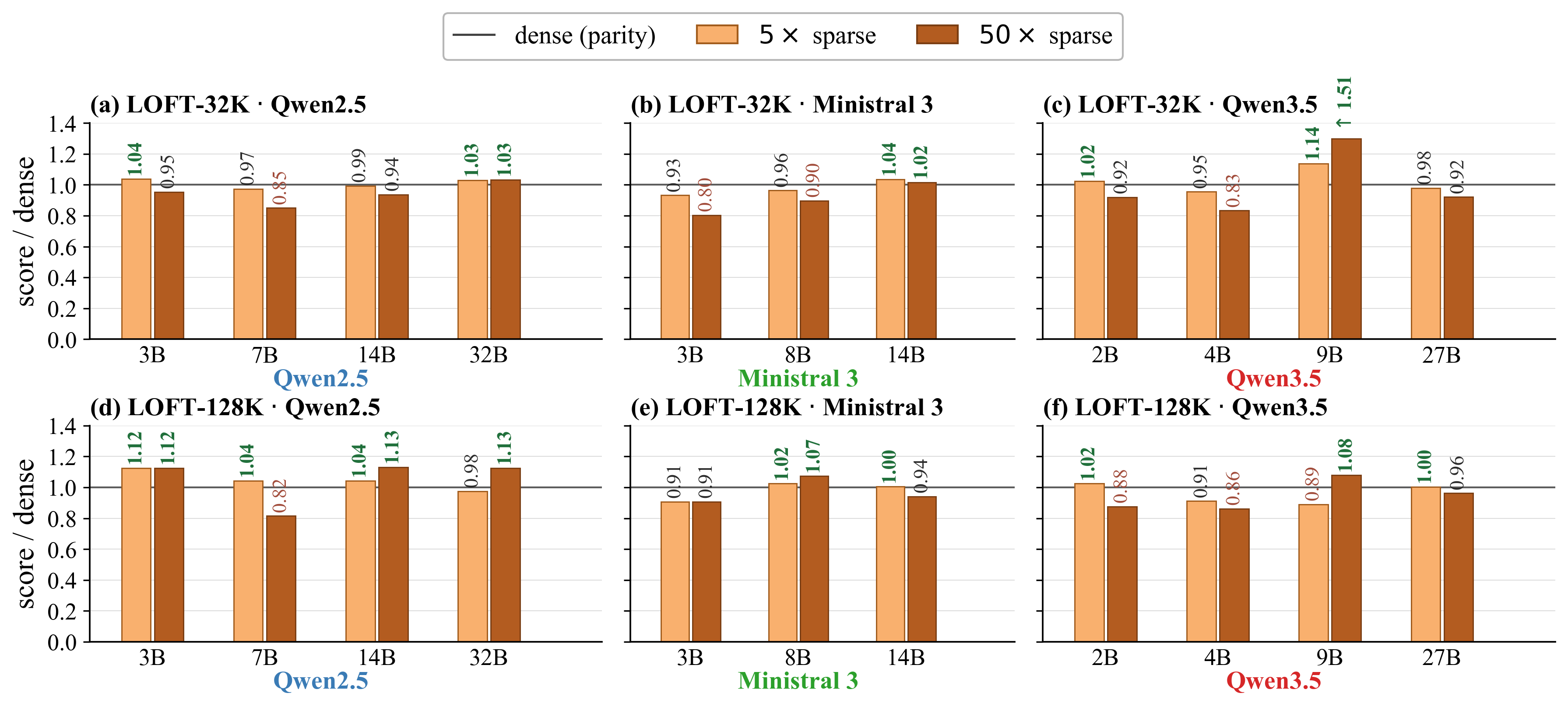
Figure 3: LOFT subspan-EM retention at 5a5 and 50a6 sparsity; hybrid Qwen3.5 models outperform standard architectures.
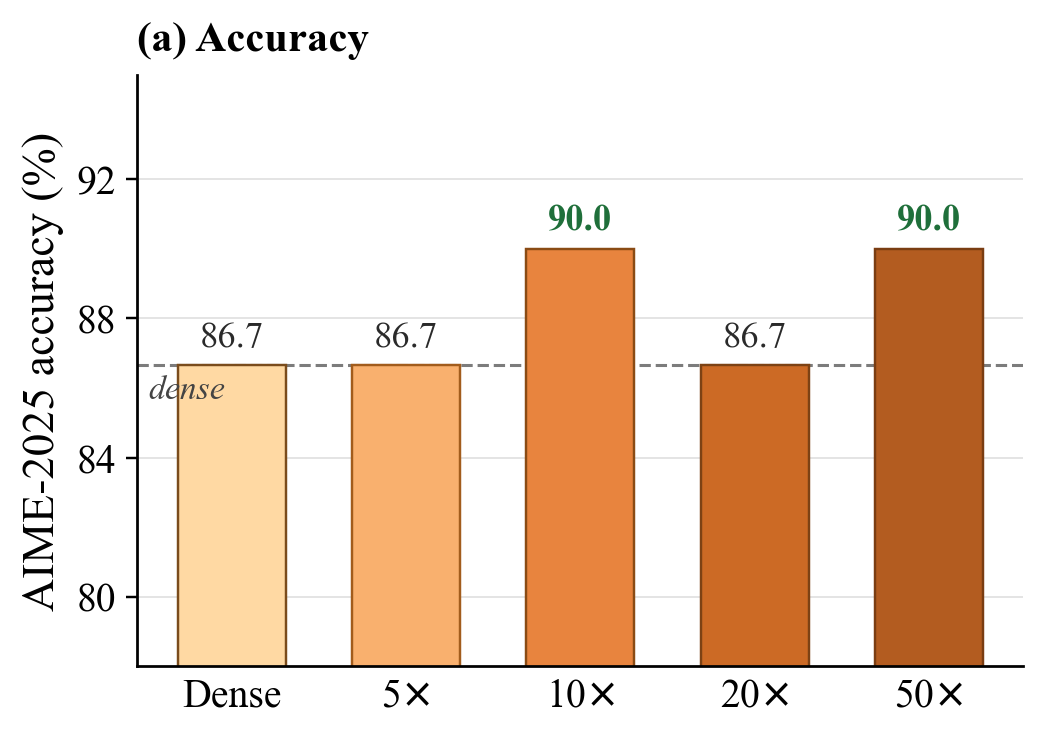
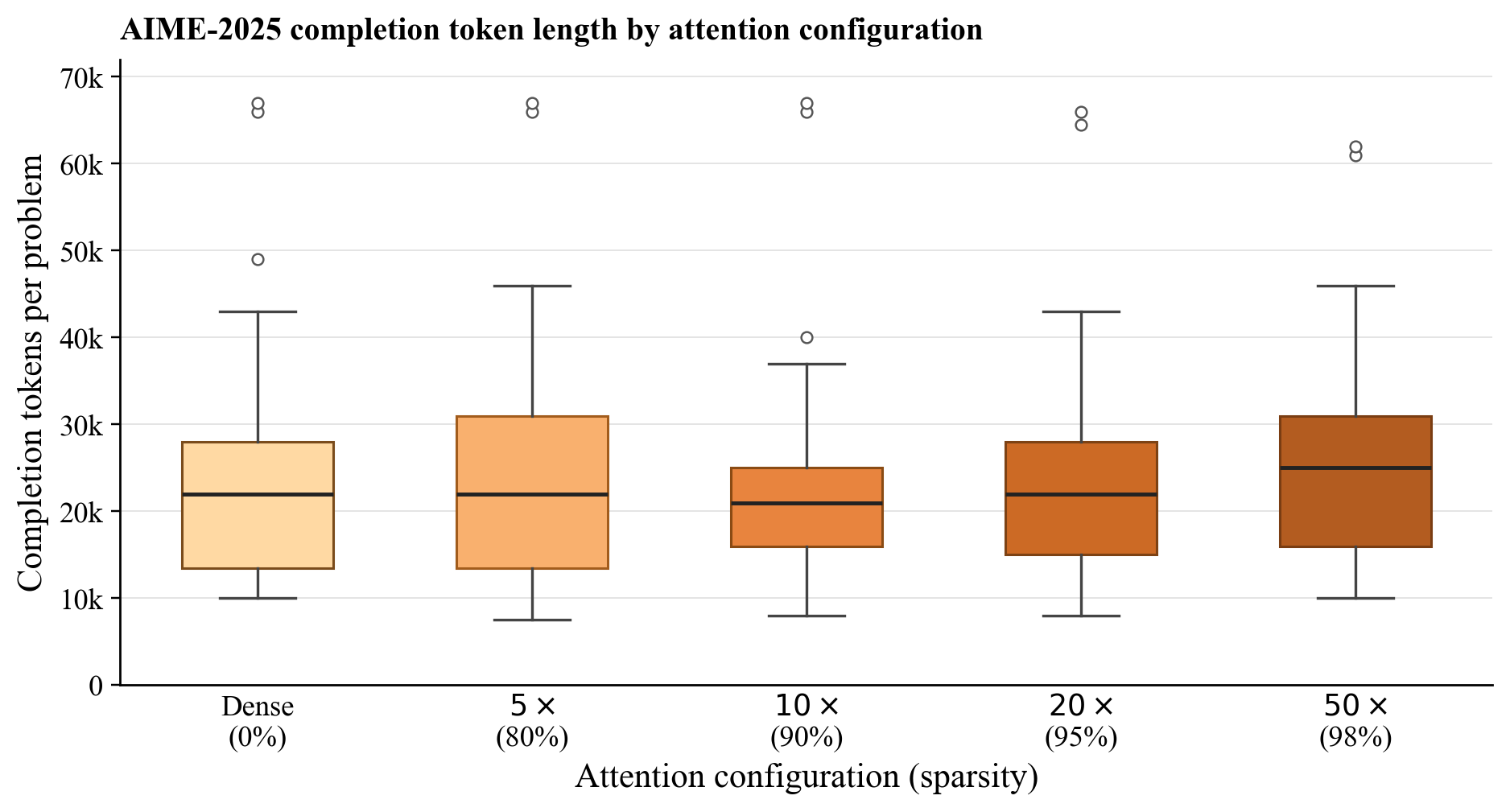
Figure 4: AIME2025 generation remains stable under 50a7 sparsity; the marginal increase in output tokens is negligible.
A practical concern is whether irregular, token-level sparsity can leverage modern hardware efficiently without imposing block structure. The paper benchmarks proprietary sparse decode kernels on the NVIDIA H100, demonstrating:
- Up to 20a8 speedup at 50a9 sparsity vis-à-vis FlashInfer.
- Higher speedups (N0–N1) at 500N2 sparsity for large batch regimes.
- Gains persist even under Grouped Query Attention (GQA), where query-heads far outnumber KV-heads.
These results indicate that current hardware is sufficient for fine-grained sparse attention, and additional indexer overheads (e.g., Double Sparsity [yang2024posttraining]) are modest relative to the speedup envelope.
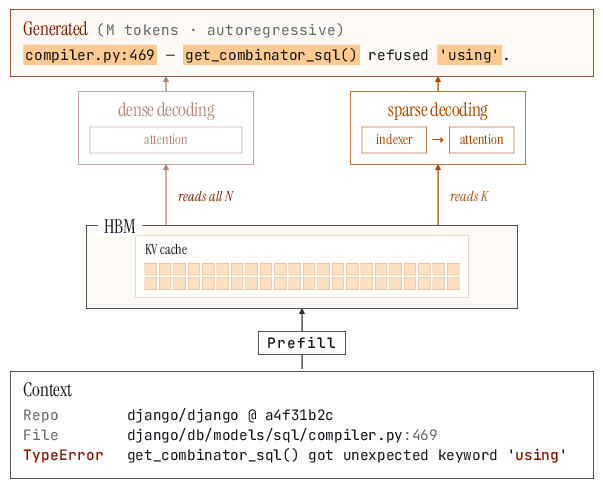
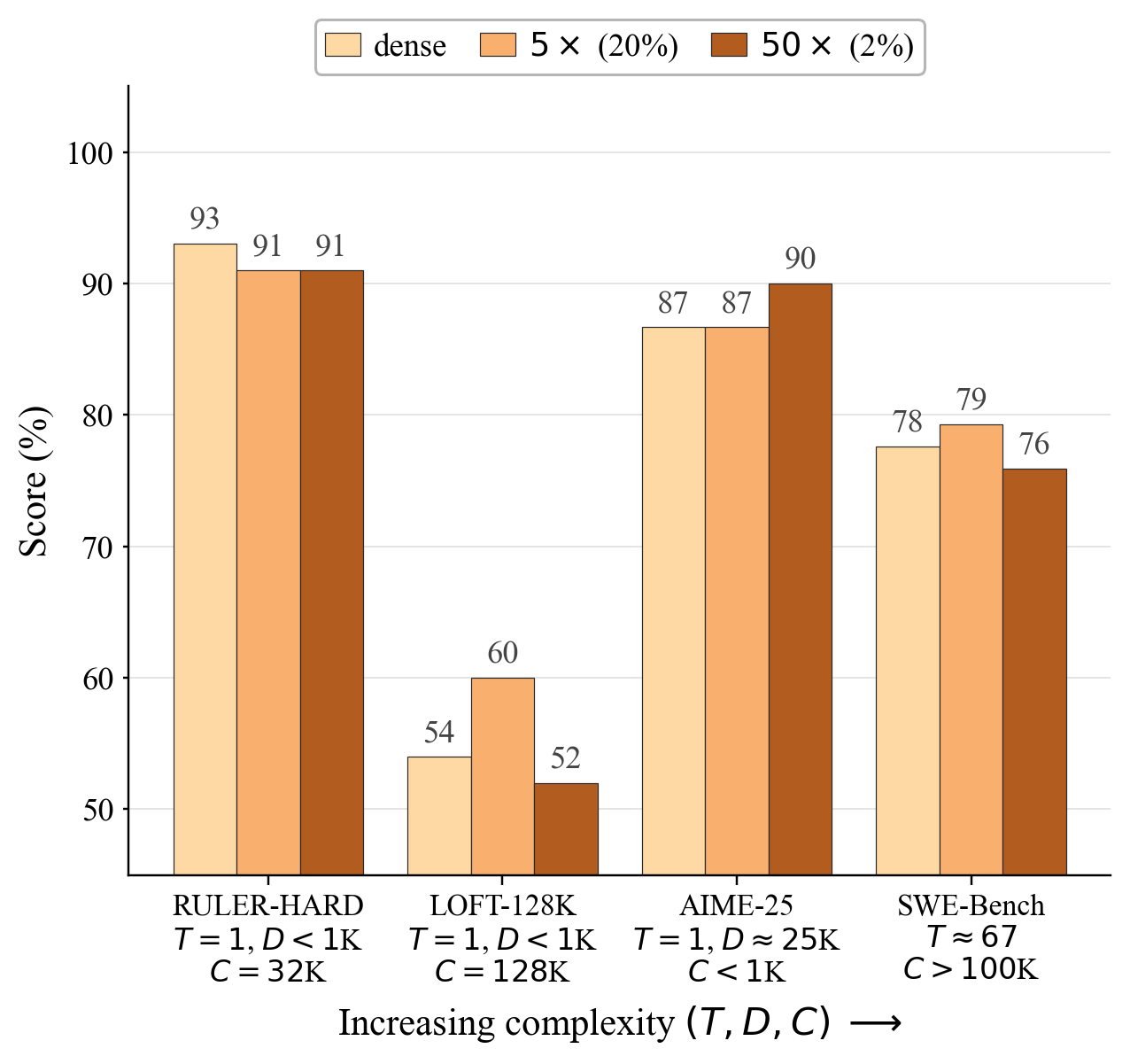
Figure 5: 50N3 context sparsity cuts memory bandwidth, enabling near-dense quality across retrieval, reasoning, and agentic workloads.
Agentic Workloads and Failure Mode Analysis
The SWE-Bench Django experiment underscores that the drop in resolution rate under sparsity is almost entirely attributable to serving-stack instability (InternalServerError, Timeout) rather than attention quality. When controlling for such non-model failures, patch resolution among dense and sparse configurations converges (dense N4, N5 N6, N7 N8 within the strict subset).
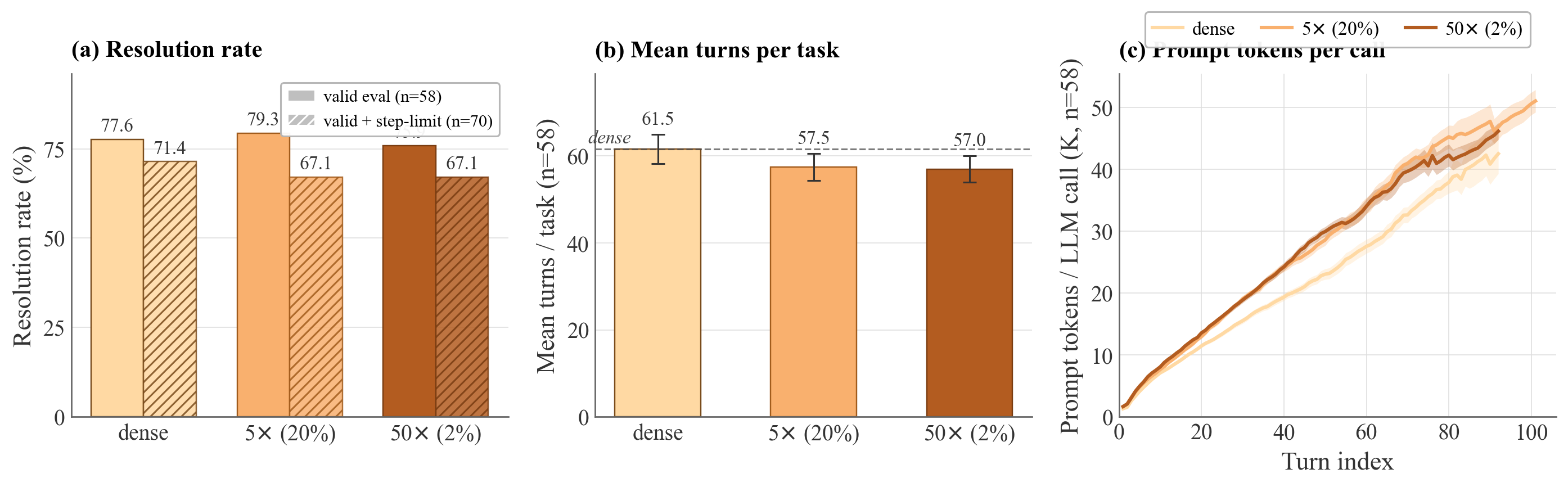
Figure 6: SWE-Bench resolution head-to-head; sparse matches dense within N92 points when controlling for infrastructure noise.
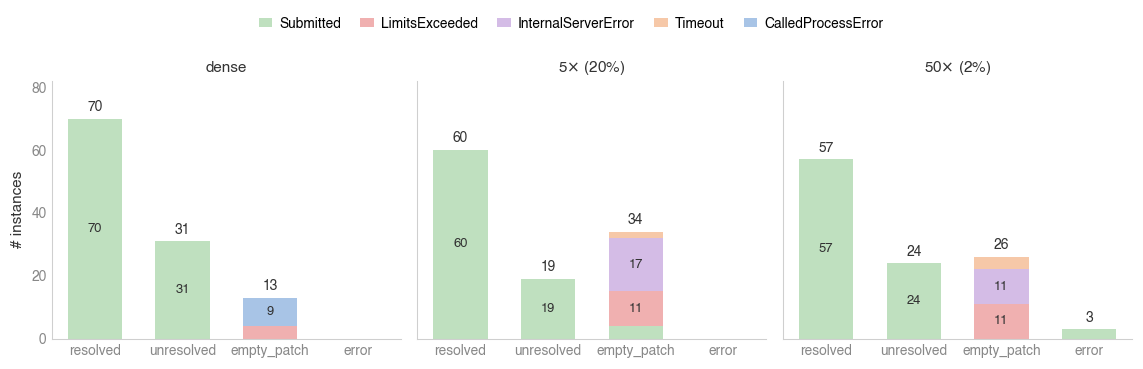
Figure 7: Empty-patch root cause attribution shows serving-stack failures dominate sparse runs; LimitsExceeded is the only model-driven increase.
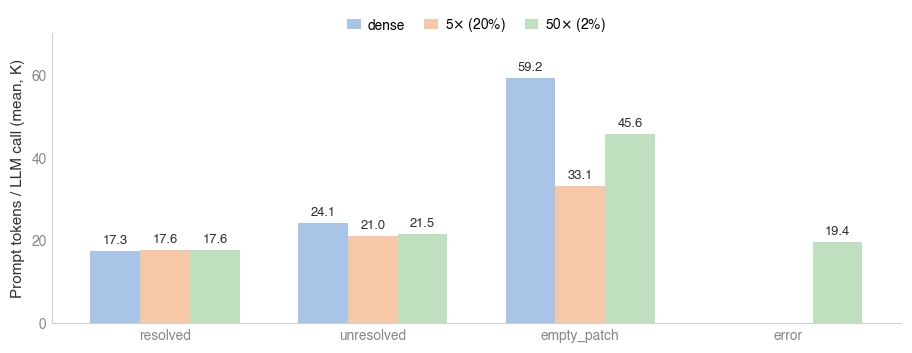
Figure 8: Mean prompt tokens per model call remain almost identical across sparse/dense runs; sparsity impacts attention computation, not context size.
Implications and Future Directions
This work asserts that context sparsity is not a heuristic workaround, but a principle for future LLM architecture and inference design. The findings suggest several implications:
- Model Scaling and Design: Larger and hybrid models inherently adapt to sparse context processing. Training-time sparsification (not explored here) could further reinforce this robustness.
- Hardware and System Engineering: Sparser context processing will drive new memory layouts, backend kernels, KV-cache compression strategies, and scheduling for agentic/long-horizon tasks.
- Algorithmic Advancement: Stochastic or learned index selection methods (e.g., vAttention, HashAttention [desai2025hashattention], PQCache [zhang2025pqcache]) will supplant deterministic sparsification for small-scale, non-hybrid LLMs.
- Application Domains: Extreme context sparsity enables LLMs to scale to code repositories, legal documents, and multi-agent systems, unlocking practical deployments previously bottlenecked by quadratic memory and compute.
Conclusion
Inference-time context sparsity is not merely feasible—it is highly beneficial and foundational for large context LLMs. The “illusion” of dense attention is shattered both by theoretical limits and strong empirical retention of quality across architectures, scales, and workloads at extreme sparsity. Modern hardware can already exploit irregular sparse patterns, and further gains are likely with architectural and hardware co-design. The principle of context sparsity should drive the next generation of LLM modeling and systems research.