Efficient Context Scaling with LongCat ZigZag Attention
Abstract: We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a way to make LLMs read and think over very long texts much faster and cheaper. The method is called LongCat ZigZag Attention (LoZA). It changes how the model “pays attention” to words so it doesn’t have to look at everything all the time. With LoZA, the model can handle up to 1 million tokens (that’s like reading huge books or long codebases) while staying accurate and running faster.
Key Objectives
The paper focuses on a few simple questions:
- Can we make the model look at only the most useful parts of the text instead of everything?
- How do we decide which parts of the model can be safely made “sparse” (meaning they skip some work) without losing quality?
- After we make it sparse, can we train the model so it still performs as well as before?
- Will this actually make the model faster in real use, like answering questions, writing long texts, or working with tools?
Methods and Approach
Think of attention like reading notes: “full attention” means rereading every note on every page to answer a question. That’s slow when the notebook is huge. “Sparse attention” means reading only the most important notes and nearby pages—much faster.
Here’s how LoZA works:
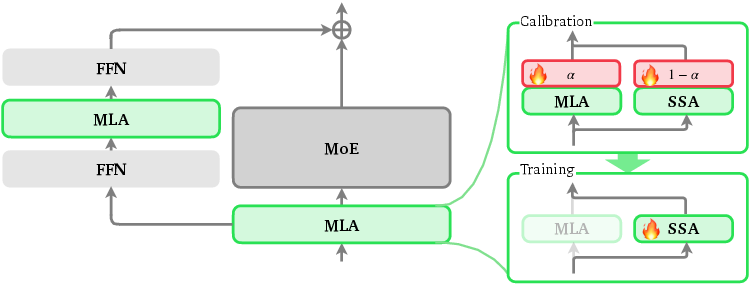
- What’s being changed: Attention layers (a part of the model that decides what to focus on). The paper uses a type of attention called MLA (used in some modern LLMs), but you can think of it as standard attention layers inside the model.
- The LoZA process has three steps:
- Calibration: The team adds a small “mixing knob” (a number called α, between 0 and 1) to each attention layer. This knob blends two versions of the layer’s output: the normal full-attention result and a sparse-attention result. They freeze the rest of the model and adjust only these knobs using a small training set. The size of the knob tells how important full attention is for that layer. Layers with low α are good candidates to become sparse.
- Sparsification: They select 50% of attention layers with the lowest α and switch them from full to “streaming sparse attention” (SSA). In SSA, each new word only looks at a few special “sink” blocks (like bookmarks) and nearby “local” blocks (like neighboring pages), instead of the whole sequence. In their setup: block size b = 128 tokens, sink blocks s = 1, local blocks l = 7 (so each query looks at 1,024 tokens in total).
- Training: After making those layers sparse, they do more training (called “mid-training”) to recover any lost performance, especially for very long contexts.
- Extending to super-long context: They use a technique named YaRN to stretch the model’s context window up to 1,000,000 tokens without retraining everything from scratch.
- Data for training: They feed the model with a smart mix of long materials, such as tough reasoning examples, agent interactions (the model using tools and following protocols), long books and textbooks, and entire code repositories (so it can solve cross-file coding problems).
- Post-training: They use a lightweight finishing process: supervised fine-tuning (SFT) on half the usual data, plus Direct Preference Optimization (DPO) and Reinforcement Fine-Tuning (RFT) to align the model’s behavior with good human-like responses.
- What “prefill” and “decode” mean: Prefill is the “reading” phase where the model ingests the long prompt. Decode is the “writing” phase where it generates the answer tokens one by one. LoZA aims to speed up both.
Main Findings and Why They Matter
The results show LoZA keeps quality high while boosting speed, especially for long inputs.
- Accuracy stays comparable: The base model with LoZA (LongCat-Flash-Exp-Base) performs about the same as the original (LongCat-Flash-Base) on general tests, sometimes slightly better. It does especially well on long-context tasks.
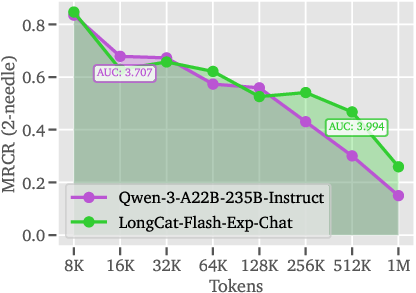
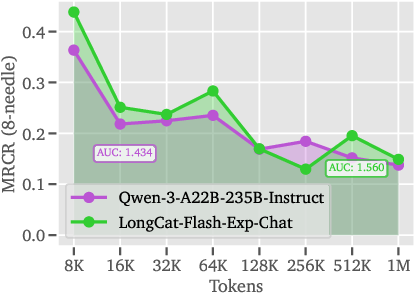
- Long-context strength: The chat version (LongCat-Flash-Exp-Chat) matches or beats strong models on long-text benchmarks, thanks to handling up to 1M tokens.
- Big speed and cost improvements:
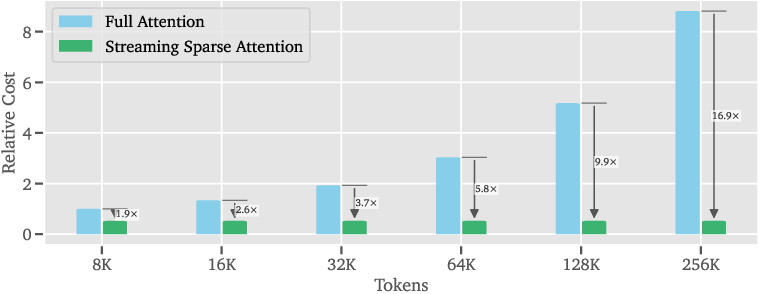
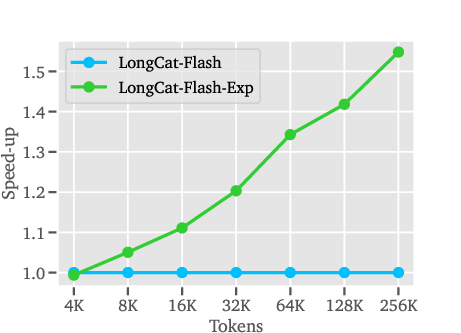
- In the attention “decode” kernel, sparse attention uses up to about 90% less compute cost than full attention at 128K tokens.
- End-to-end serving shows over 50% speed-up in prefill and more than 30% cost savings during decode at 256K tokens.
- Because half the attention layers are made sparse, the ideal speed-up from attention alone can approach 2× in long-context scenarios.
- Calibration matters: In small pilot studies, hand-picked sparse patterns caused big drops on long-context tasks, but using the calibration step to choose which layers to sparsify recovered most performance. Further training then improved results even more.
These findings mean you can make a model faster for long inputs without sacrificing its ability to answer correctly.
Implications and Impact
This approach helps build AI systems that:
- Remember and reason over very long information (like entire books, big code projects, or long research notes).
- Work better with tools and complex tasks that need long-term context.
- Run faster and cheaper, which makes them easier to use at scale.
- Can be adapted to other models that use similar attention designs (like MLA), and potentially to multi-modal models (that handle text plus images or audio).
In short, LoZA makes “context as memory” practical: models can keep huge amounts of information in mind and still respond quickly and accurately.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves missing, uncertain, or unexplored, phrased to be actionable for future research.
- Formal complexity and approximation analysis is absent: the claim that compute “minimally remains constant” with context needs exact asymptotics for SSA (prefill/decode) as functions of , , , and context length , plus bounds on approximation error versus full attention.
- Calibration details are underspecified: no description of calibration dataset composition/size, optimization objective for (or ), training steps, convergence criteria, and stability across random seeds.
- Notation inconsistency and procedure clarity: the paper uses both and for the same gate; “rewound” mid-training is referenced but not defined (what parameters are rewound, to which checkpoints, and how).
- Fixed sparsity fraction without ablation: 50% of MLAs are sparsified globally; no study of varying sparsity levels (e.g., 25–75%), per-layer adaptive sparsity, or input-adaptive sparsity patterns.
- Sparse pattern hyperparameters are not justified: block size , sink blocks , local blocks (effective window 1024 tokens) are presented without sensitivity analyses or task-dependent tuning guidelines.
- Static SSA vs adaptive schemes: LoZA uses a fixed sink+local pattern; it does not explore query-aware or retrieval-aware sparse selection (e.g., QUEST, DuoAttention) or hybrid head/layer sparsity schemes.
- Head-level vs layer-level choice lacks empirical substantiation: kernel/engine arguments are narrative; there is no side-by-side measurement of warp divergence, metadata overhead, rank imbalance, and end-to-end effects for head- vs layer-level sparsity.
- Generalizability beyond MLA is untested: while “universally applicable” is claimed, experiments are only on MLA-based LongCat-Flash; no results on standard self-attention LMs, non-MLA MoE variants, or non-Transformer architectures.
- Model and code availability: LongCat-Flash-Exp is not publicly released; custom kernels/engine changes are not open-sourced, limiting reproducibility and independent verification.
- Efficiency benchmarking misses critical context: batch sizes, prompt lengths, generation lengths, GPU count/type (H20 specifics are vague), throughput/latency definitions, and variance/error bars are not reported; no energy or cost-per-token metrics.
- Short-context regression is acknowledged but unaddressed: 4K degradation due to metadata overhead is mentioned without a systematic analysis or a dense-sparse switch strategy (e.g., auto-switching to dense attention for short inputs).
- Comparisons to prior sparse attention methods are limited: there is no controlled head-to-head on identical hardware/models against QUEST, SpargeAttention, Rectified Sparse Attention, DuoAttention, etc., beyond a single MRCR curve vs Qwen-3.
- Interaction with YaRN extrapolation is unexplored: no ablation on YaRN hyperparameters when combined with SSA, nor analysis of potential instabilities or degradation at ultra-long contexts (e.g., 512K–1M).
- Long-context evaluation depth is insufficient: beyond MRCR/LongBenchV2/HELMET and a single longform-writing metric, there are no end-to-end RAG, cross-document reasoning, or persistent memory agent evaluations at 256K–1M contexts.
- KV cache and memory bandwidth impacts are not quantified: implications of SSA on KV cache size, paging behavior, memory traffic, and batchability under real serving loads are not measured.
- Cost model vs measured speedups mismatch is unexplained: 50% sparsity suggests ~2× attention compute reduction, yet decode cost savings are ~30%; a detailed breakdown of non-attention bottlenecks and metadata overhead is missing.
- Failure modes and statistical significance: some regressions (e.g., code tasks) appear; no significance testing, error analyses, or case studies identifying when sparse attention harms performance (e.g., cross-file code dependencies).
- Sink block mechanism is under-specified: how sink tokens/blocks are selected, updated across layers/steps, trained, and how the number of sinks affects recall of distant information lacks detail and ablations.
- Calibration/training budget and minimal requirements are unclear: pilot studies mention “few tokens” without exact counts; the mid-training budget is large (500B+40B tokens); feasibility at lower compute and data scales is not studied.
- Hardware portability and scalability are unknown: results are on NVIDIA H20; performance/portability on A100/H100, consumer GPUs, TPUs, or other accelerators, and scaling to very deep/wide models, are not evaluated.
- Inference metadata overhead is not profiled: there is no breakdown of where metadata is generated, its runtime cost across layers, and algorithmic mitigations to reduce it.
- Safety/alignment with long contexts is not assessed: sparse attention’s impact on prompt injection resilience, tool-use reliability, and preference alignment in 100K–1M contexts is not evaluated; DPO/RFT specifics are minimal.
- Multilingual long-context behavior lacks granularity: averaged MMMLU/MGSM scores are reported without per-language breakdowns, tokenization effects, or robustness analyses for non-Latin scripts at long contexts.
- Dynamic scheduling across decoding steps is unexplored: strategies that use dense attention early and sparse later (or vice versa) are not considered; the optimal per-step sparsity schedule remains an open question.
- Data quality, leakage, and contamination risks are unaddressed: large-scale long-form, agentic, and repository-level data are used without audits for overlap with evaluation sets or contamination controls.
- Calibration overhead and scalability: computing both dense and sparse outputs per MLA during calibration is expensive; there is no accounting of overhead or strategies to amortize/approximate it at scale.
- Theoretical grounding via lottery ticket hypothesis is only qualitative: there is no formal statement or proof of conditions under which sparsify–rewind–mid-train recovers dense-performance, nor bounds relating performance gap to sparsity level.
Practical Applications
Immediate Applications
The following list distills concrete, deployable use cases that can leverage LoZA’s layer-level streaming sparse attention (SSA) today, given the paper’s reported quality retention and sizable speed-ups (>50% prefill, >30% decode cost savings at 256K; up to 90% kernel decode cost reduction at 128K), and the availability of LongCat-Flash-Exp with up to 1M-token context via YaRN.
- Industry (software): Repository-scale code assistants in IDEs
- Use case: Cross-file reasoning, large monorepo navigation, whole-repo refactoring suggestions, and issue triage aligned with SWE-Bench/FullStackBench-style tasks.
- Workflow: Index repository → stream sparse attention during inference → multi-file context window (100K–1M tokens) → propose fixes and tests → integrate with CI.
- Dependencies/assumptions: Access to MLA-based or LoZA-adaptable LMs; GPU kernels/engine that support SSA; repository ingestion and security policies; quality hinges on calibration + sparse training rather than “hand-crafted” sparsity (per pilot studies).
- Industry (enterprise knowledge/RAG): Million-token retrieval-augmented generation for compliance and legal analysis
- Use case: Ingest multi-year contracts, policies, emails, filings (10-K/8-K), and internal guidelines into a single context; produce audits, compliance checks, and legal summaries.
- Workflow: Vector DB retrieval → chunking tuned to SSA blocks (
s=1, l=7, b=128, ≈1,024 tokens per local window) → prefill-efficient LoZA inference → validated summaries. - Dependencies/assumptions: Reliable retrieval quality; YaRN-based extrapolation for long windows; privacy/governance for sensitive documents; slight short-context overhead acknowledged.
- Industry (customer support/operations): Context-native agents with extended memory
- Use case: Agents that keep thousands of messages and tickets in-context to avoid external memory hops, improving continuity and personalization.
- Workflow: Session log streaming → SSA-backed long decode for tool-integrated reasoning → action execution via MCP servers → updated context state retained.
- Dependencies/assumptions: Tool integration (MCP) and action safety; uniform schedule across ranks mitigates stragglers; choose dynamic switching for short vs long context to avoid overhead at 4K.
- Industry (observability/cybersecurity): Long-log summarization and incident forensics
- Use case: Scanning massive system logs, traces, and alerts to reconstruct timelines and identify root causes or threat paths.
- Workflow: Structured log ingestion → sparse prefill of large windows → stepwise decode for hypothesis testing with tool calls (e.g., grep-like functions) → incident reports.
- Dependencies/assumptions: Domain-specific parsers and tool integrations; adequate GPU memory; calibration maintains long-context accuracy (cf. MRCR/LongBenchV2 gains).
- Finance: Due diligence and risk analysis across multi-year corpora
- Use case: Consolidate filings, research notes, earnings transcripts, and market data into single long contexts for risk summaries and alerts.
- Workflow: Data lake → RAG retrieval → LoZA-based long-context chat/model → human-in-the-loop validation; export to dashboards.
- Dependencies/assumptions: Alignment via SFT+DPO+RFT already demonstrated; domain tuning improves precision; rigorous compliance workflows required.
- Healthcare: Longitudinal patient timeline summarization (pilot deployments)
- Use case: Summarizing years of EHR notes, labs, reports for handoff, care planning, and guideline checks.
- Workflow: De-identified EHR ingestion → RAG into long windows → SSA-enabled reasoning over timeline → clinician-facing summaries.
- Dependencies/assumptions: Regulatory approval and PHI handling; domain fine-tuning needed; strong governance; potential short-context overhead mitigated by dynamic policies.
- Education: Course-scale tutoring and grading for long-form artifacts
- Use case: Tutors that read entire syllabi, textbooks, and student portfolios; graders for long essays and projects.
- Workflow: Curriculum ingestion → long-context comprehension → tailored study plans and rubric-based grading; feedback loops for improvement.
- Dependencies/assumptions: Content licensing and academic integrity; domain alignment; stable long-context performance (paper reports strong long-form writing/HELMET/MRCR results).
- Academia (literature review and meta-analysis): Systematic reviews across thousands of papers
- Use case: In-context synthesis of broad and deep corpora; tracking claims, methods, and conflicts.
- Workflow: PDF/HTML parsing → citation graph + retrieval → LoZA long-context synthesis → queryable “living reviews.”
- Dependencies/assumptions: High-quality parsing and citation linking; reproducibility logging; calibration prevents long-context drop seen with hand-crafted sparsity.
- MLOps/Inference Serving: Cost and latency optimized long-context deployments
- Use case: Deploy LoZA kernels/engines for MLA models to halve attention compute and reduce stragglers.
- Workflow: Replace head-level sparsity with layer-level SSA → uniform kernel schedule and balanced ranks → monitor prefill/decode metrics.
- Dependencies/assumptions: H20-class GPUs or equivalent; kernel integration (FlashMLA compatibility); metadata generation overhead at short windows acknowledged.
- Multilingual support: Long-context multilingual reasoning and translation
- Use case: Consolidate multilingual sources (reports, transcripts) into single contexts for cross-language synthesis.
- Workflow: Language-aware retrieval → long-context inference → terminological consistency checks via tools.
- Dependencies/assumptions: Model exhibits strong multilingual across 8 languages; specialized fine-tuning improves domain fidelity.
Long-Term Applications
The following list captures opportunities that likely require further research, scaling, or productization—e.g., robust domain adaptation, multi-modal MLA, dynamic sparse scheduling, or policy standardization.
- Personal “memory-as-context” assistants with lifelong logs
- Sector: Consumer software; productivity.
- Product vision: Assistants that keep years of notes, chats, emails, and documents in-context (up to 1M tokens) for recall, planning, and context-aware actions.
- Dependencies/assumptions: Efficient storage and streaming; privacy-by-design; adaptive dense–sparse switching to minimize cost; longitudinal evaluation beyond MRCR.
- Robotics and long-horizon planning
- Sector: Robotics.
- Product vision: Planners that retain large procedural histories, environment maps, and instructions directly in the context buffer for extended missions.
- Dependencies/assumptions: Multi-modal MLA support (vision/audio per future OneCAT-like models); real-time SSA kernels; safety verification; tool-use integration.
- Healthcare-grade longitudinal reasoning at scale
- Sector: Healthcare.
- Product vision: Clinical copilots that reason over multi-year EHRs, imaging summaries, guidelines, and trial data for decision support.
- Dependencies/assumptions: Clinical validation (prospective studies), regulatory clearance, robust domain alignment, and bias/robustness audits; scalable privacy-preserving RAG.
- Enterprise “knowledge OS” for governance, audit, and compliance
- Sector: Policy/enterprise governance.
- Product vision: A platform that keeps policies, audits, contracts, and communications in-context for real-time compliance and risk assessments.
- Dependencies/assumptions: Policy frameworks for long-context retention; data residency controls; traceable tool-augmented reasoning; standardized long-context AUC-style metrics.
- Dynamic dense–sparse switching and auto-calibration
- Sector: Software infrastructure.
- Product vision: An “auto-sparsity scheduler” that tunes layer-level SSA ratios in real time based on query structure (QUEST/InfLLM-V2-inspired), balancing quality and cost.
- Dependencies/assumptions: Training for dynamic policies; robust calibration signals; kernel support without warp divergence; cross-rank load balancing.
- Multi-modal long-context foundation models
- Sector: Multi-modal AI.
- Product vision: Extend LoZA to audio/video/images for long-form multimedia understanding (lectures, meetings, surveillance timelines).
- Dependencies/assumptions: MLA generalization to multi-modal; sparse attention patterns validated for non-text modalities; data curation at scale.
- Large-scale codebase autopilot and migration tools
- Sector: Software engineering.
- Product vision: Automatic dependency migrations, API upgrades, and architectural refactors across monorepos using million-token contexts.
- Dependencies/assumptions: Tight VCS integration, code safety checks, policy gates, human oversight; domain-aligned training; scalable inference with SSA.
- Grid/energy and IoT telemetry reasoning
- Sector: Energy/IoT.
- Product vision: Consolidate high-volume telemetry streams into long-context analyses for anomaly detection and forecasting.
- Dependencies/assumptions: Streaming ingestion + SSA; domain-specific tool integration; latency constraints; robustness to noise and drift.
- Standardization of long-context evaluation and governance
- Sector: Policy/standards.
- Product vision: Community standards for long-context benchmarks (e.g., MRCR, LongBenchV2), AUC-based metrics, privacy retention guidelines, and auditability of context-native apps.
- Dependencies/assumptions: Broad stakeholder engagement; regulatory alignment; reproducible evaluation harnesses.
- Hardware–software co-design for long-context SSA
- Sector: Semiconductor and systems.
- Product vision: Accelerators and kernels optimized for layer-level sparsity and uniform schedules, reducing metadata overhead at short contexts.
- Dependencies/assumptions: Vendor support; compiler/runtime innovations; cross-model compatibility; economic viability.
- Cross-model LoZA adoption beyond MLA
- Sector: AI platforms.
- Product vision: Adapting LoZA-like calibration and layer-level sparsification to non-MLA full-attention LMs for universal long-context efficiency.
- Dependencies/assumptions: Empirical validation of calibration/training efficacy; kernel support; maintaining quality on short and long contexts.
Notes on Feasibility and Assumptions Across Applications
- Quality preservation depends on proper calibration (learning per-MLA mixing coefficients) and sparse training; hand-crafted sparsity patterns can degrade long-context performance.
- Engine/kernel support is crucial: layer-level SSA avoids head-level compute imbalance and warp divergence, enabling uniform schedules across parallel ranks.
- YaRN extrapolation underpins 1M-token windows; memory management and chunking (sink/local blocks) must be tuned to workload characteristics.
- Short-context scenarios may see overhead due to metadata generation; dynamic policies that enable LoZA only when contexts are long can mitigate this.
- Alignment and safety (SFT, DPO, RFT) are assumed for user-facing deployments; domain fine-tuning improves reliability in specialized sectors (healthcare, finance, robotics).
- Privacy, compliance, and data governance are heightened concerns when retaining very long contexts; policies for retention, access control, and audit trails are essential.
Glossary
- Agentic: Refers to LLM behaviors that involve autonomous, tool-using, multi-step task execution. "Agentic data: synthesizing large-scale agentic interactions by leveraging a vast array of task-oriented web content and thousands of model context protocol (MCP) servers;"
- AUC: Area Under the Curve; a scalar metric summarizing performance across a range (here, context lengths). "AUC: area under curve."
- Block size: The number of tokens in each attention block used by the sparse pattern. "The block size (i.e., ) is 128,"
- Calibrated sparse pattern: A sparsification layout chosen by ranking layers via calibration parameters rather than hand-crafting. "the calibrated sparse pattern denotes sparsifying the lowest-valued layers during calibration."
- Calibration: A phase where layer-wise mixing coefficients are optimized to measure importance before sparsification. "Then a round of training on the calibration data is carried out by freezing any parameters within the mid-trained LM except all ."
- Context scaling: How computation or performance varies as the input context length grows. "the compute minimally remains constant with respect to the context scaling."
- Decode: The token-by-token generation phase of LLM inference. "saves over 30% cost in decode for a context of 256K tokens."
- Decode-intensive: Workloads dominated by the generation/decoding phase. "decode-intensive (e.g., tool-integrated reasoning) cases."
- Direct Preference Optimization (DPO): A post-training method that aligns models to human preferences via pairwise comparisons. "we employed Direct Preference Optimization (DPO)~\citep{DBLP:conf/nips/RafailovSMMEF23} alongside Reinforcement Fine-Tuning (RFT)~\citep{openai2024rft}."
- Duo-Attention: An approach with retrieval and streaming heads for efficient long-context inference. "Our design is to a great extent inspired by Duo-Attention~\citep{DBLP:conf/iclr/XiaoTZGYTF025}."
- FlashMLA: A high-performance GPU kernel implementation for MLA attention. "full attention kernel (i.e., FlashMLA~\citep{DBLP:journals/corr/abs-2506-01969})"
- Foundation model: A broadly pre-trained model adaptable to many downstream tasks. "serve LongCat-Flash-Exp as a long-context foundation model"
- Full attention: Standard dense attention where each token attends to all others. "Attention~\citep{DBLP:conf/nips/VaswaniSPUJGKP17}, or typically full attention, is a key ingredient in modern transformer architectures and thus LLMs."
- Global synchronization: A distributed-execution barrier where all workers must align before proceeding. "creating stragglers that bottleneck global synchronization."
- H20 (NVIDIA H20 GPUs): The GPU hardware platform used for benchmarking. "The relative cost and speed-up are practically measured on H20 clusters."
- Head-level sparsity: Applying sparsity at the level of individual attention heads. "head-level streaming sparse attention as in Duo-Attention"
- Interleaved sparse pattern: A hand-crafted scheme that sparsifies every other layer. "The interleaved sparse pattern denotes sparsifying one out of two adjacent layers,"
- Kernel (GPU): A GPU-executed function implementing a computation (e.g., attention) with specific control flow. "Head-level sparsity complicates kernel control flow, consuming critical efforts in achieving balanced metadata."
- KV groups: Groupings of key/value tensors processed together for efficiency within GPU kernels. "it is possible that kernels can process multiple KV groups per thread block to maximize occupancy;"
- Layer-level sparsity: Sparsifying entire attention layers instead of individual heads. "bet on layer-level rather than head-level streaming sparse attention"
- Local blocks: Nearby context blocks that each query attends to under streaming sparse attention. "the number of local blocks (i.e., ) is 7,"
- LongCat ZigZag Attention (LoZA): The paper’s proposed sparse attention scheme for efficient long-context scaling. "We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget."
- Lottery tickets hypothesis: The idea that sparse subnetworks can match full model performance when appropriately trained. "lottery tickets hypothesis~\citep{DBLP:conf/iclr/FrankleC19}"
- MCP (Model Context Protocol): A protocol and server ecosystem for tool/context integration with models. "model context protocol (MCP) servers"
- Mid-training: An intermediate training stage between pretraining and post-training for adaptation. "For budget purpose, we decide to locate the training at mid-training."
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized expert networks. "shortcuted-MoE~\citep{DBLP:conf/icml/CaiJQC0025}"
- Occupancy: The degree to which GPU compute resources are utilized concurrently. "maximize occupancy;"
- Prefill: The context-encoding phase computing attention over the prompt before decoding. "LongCat-Flash-Exp realizes more than 50% speed-up in prefill"
- Prefill-intensive: Workloads dominated by the prompt-encoding phase. "prefill-intensive (e.g., retrieval-augmented generation)"
- Post-training: The alignment/fine-tuning stage after base training to improve model behavior. "the post-training recipe is primarily simplified for fast prototyping."
- Ranks (parallel): The individual processes or devices participating in distributed computation. "compute imbalance across parallel ranks"
- Reinforcement Fine-Tuning (RFT): A reinforcement-learning-style alignment method for LLMs. "we employed Direct Preference Optimization (DPO)~\citep{DBLP:conf/nips/RafailovSMMEF23} alongside Reinforcement Fine-Tuning (RFT)~\citep{openai2024rft}."
- Retrieval-augmented generation: Enhancing model inputs with retrieved documents to improve responses. "retrieval-augmented generation~\citep{DBLP:conf/naacl/ShiMYS0LZY24,DBLP:conf/acl/YenG024}"
- Schedule metadata: Auxiliary data describing execution layouts that kernels/engines use to schedule work. "eliminate the runtime overhead of recomputing schedule metadata across layers."
- Shard (workloads): To split and distribute parts of the workload across devices or processes. "Head-level sparsity can shard heterogeneous workloads to different ranks"
- Sink blocks: Fixed attention blocks that queries always attend to in streaming sparse attention. "the number of sink blocks (i.e., ) is 1,"
- Sparse attention: An attention mechanism that limits connections to reduce computation and memory. "a sparse attention scheme"
- Sparse training: Additional tuning after sparsification to recover or improve performance. "The sparse training means further training after sparsification."
- Sparsification: Converting dense components (e.g., attention layers) into sparse versions. "performance gap brought by the sparsification"
- SSA (Streaming Sparse Attention): A sparse attention variant where tokens attend to sink and local blocks in a streaming manner. "streaming sparse attention (SSA)"
- SFT (Supervised Fine-Tuning): Fine-tuning on labeled instruction–response pairs. "we perform supervised fine-tuning (SFT)"
- Streaming sparse pattern: The specific sparse layout where each query attends to sink and local blocks. "sparse attention follows the streaming sparse pattern"
- Thread block: A CUDA execution unit grouping threads that run together on a GPU SM. "per thread block"
- Tool-integrated reasoning: Reasoning that invokes external tools/APIs during generation. "tool-integrated reasoning~\citep{DBLP:journals/csur/QinHLCDCZZHXHFSWQTZLSXZ25,DBLP:conf/iclr/GouSGSYHDC24}"
- Warp divergence: Inefficiency when threads in the same GPU warp follow different control paths. "could induce warp divergence."
- YaRN: A method for extending LLM context windows efficiently. "we equip these recipes with YaRN~\citep{DBLP:conf/iclr/PengQFS24}"
Collections
Sign up for free to add this paper to one or more collections.

