Hierarchical Concept Geometry in Language Models Emerges from Word Co-occurrence
Abstract: We propose a distributional theory of how hypernymy -- the ``is-a'' relation between general and specific concepts -- is encoded geometrically in language representations. Starting from the empirically verified assumption that words closer on the WordNet hypernym graph co-occur more often, we characterize theoretically the spectrum of the resulting embedding Gram matrix of word2vec embeddings. Under mild positivity and decay conditions on the co-occurrence kernel, we prove that the leading eigenvectors first separate broad taxonomic branches and then progressively finer sub-branches, producing a \emph{hierarchical splitting geometry} with a coarse-to-fine spectral organization that mirrors the tree. We confirm these predictions in word2vec embeddings across many sampled WordNet subtrees, and show that the same signature extends strikingly well to Gemma 2B unembeddings. Our results indicate that hierarchical concept geometry in LLMs need not reflect a hierarchy-specific functional mechanism, but emerges from the spectral structure of pairwise word statistics.

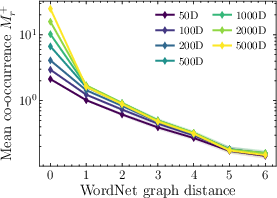
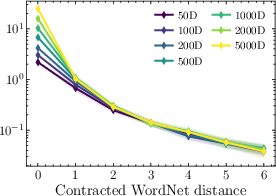

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Hierarchical Concept Geometry in LLMs Emerges from Word Co-occurrence
Overview: What is this paper about?
This paper asks a simple question: How do LLMs and word embeddings (like word2vec) organize meanings like “animal,” “bird,” and “owl”? The authors show that a neat, layered structure—where broad ideas split into more specific ones—naturally appears because of how often words occur together in text. This structure doesn’t need a special “hierarchy rule” inside the model; it comes from word co-occurrence statistics.
Key Questions the Paper Tries to Answer
To make this idea easy to grasp, here are the main questions the paper answers:
- How is the “is-a” relationship (called hypernymy)—like “owl is a bird,” “bird is an animal”—encoded inside word vectors and LLM representations?
- Does simple word co-occurrence (how often words appear near each other) predict this hierarchical structure?
- Can we see the same structure both in classic word embeddings (word2vec) and in a modern LLM (Gemma 2B)?
- If this structure appears, does it follow a clear “coarse-to-fine” pattern (first big splits like animals vs. plants, then smaller splits like birds vs. fish)?
Methods: How did they study this?
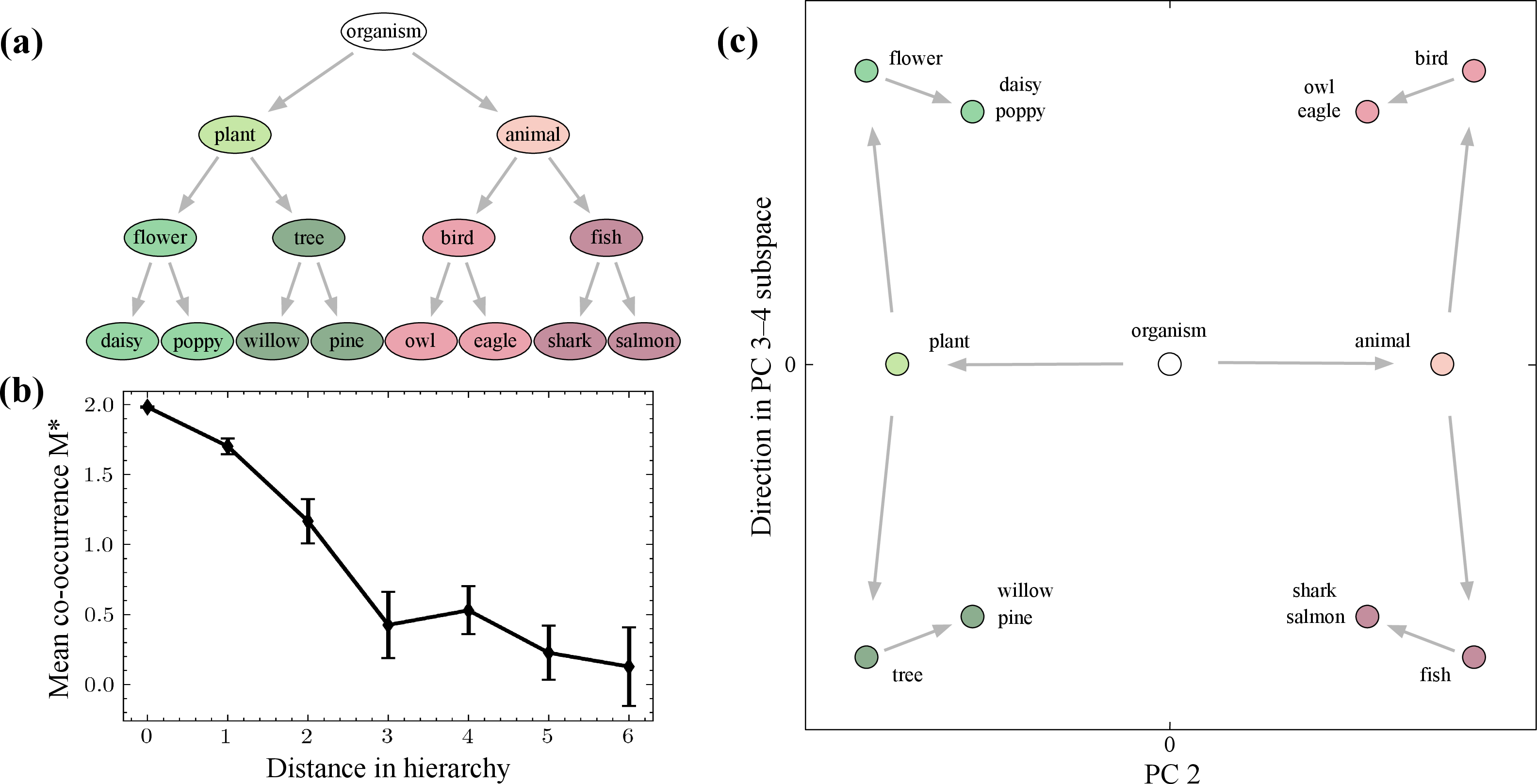
Think of WordNet (a well-known dictionary of word meanings) like a family tree for concepts. At the top you have very general ideas (like “organism”), and each level splits into more specific ideas (like “animal” → “bird” → “owl”). The authors do three main things:
- Build a distance measure on the WordNet tree: Words that are close on the tree (like “bird” and “animal”) are “near”; words farther apart (like “tree” and “fish”) are “far.”
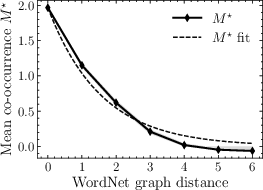
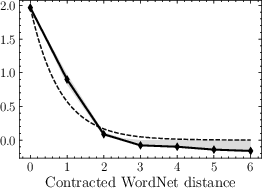
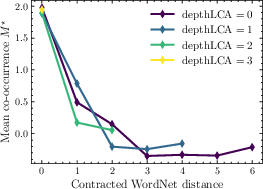
- Measure word co-occurrence: This is how often two words show up near each other in text. The key observation is simple: words that are closer on the WordNet tree tend to co-occur more often.
- Turn co-occurrence into geometry:
- They use a matrix that encodes word co-occurrence (you can think of a matrix like a big table where each cell shows how strongly two words are related).
- They then look at the matrix’s main “directions” (called principal components or eigenvectors). These directions act like sliders that split the concept tree:
- First, broad splits (like animals vs. plants).
- Next, finer splits (like birds vs. fish).
- And then even finer ones (like daisy vs. poppy).
- An easy analogy: Imagine you’re sorting a huge set of photos. The first slider separates indoor vs. outdoor scenes. The next slider separates beaches vs. forests. The next splits forests into pine vs. oak. Each slider is a “direction” the model discovered from word usage.
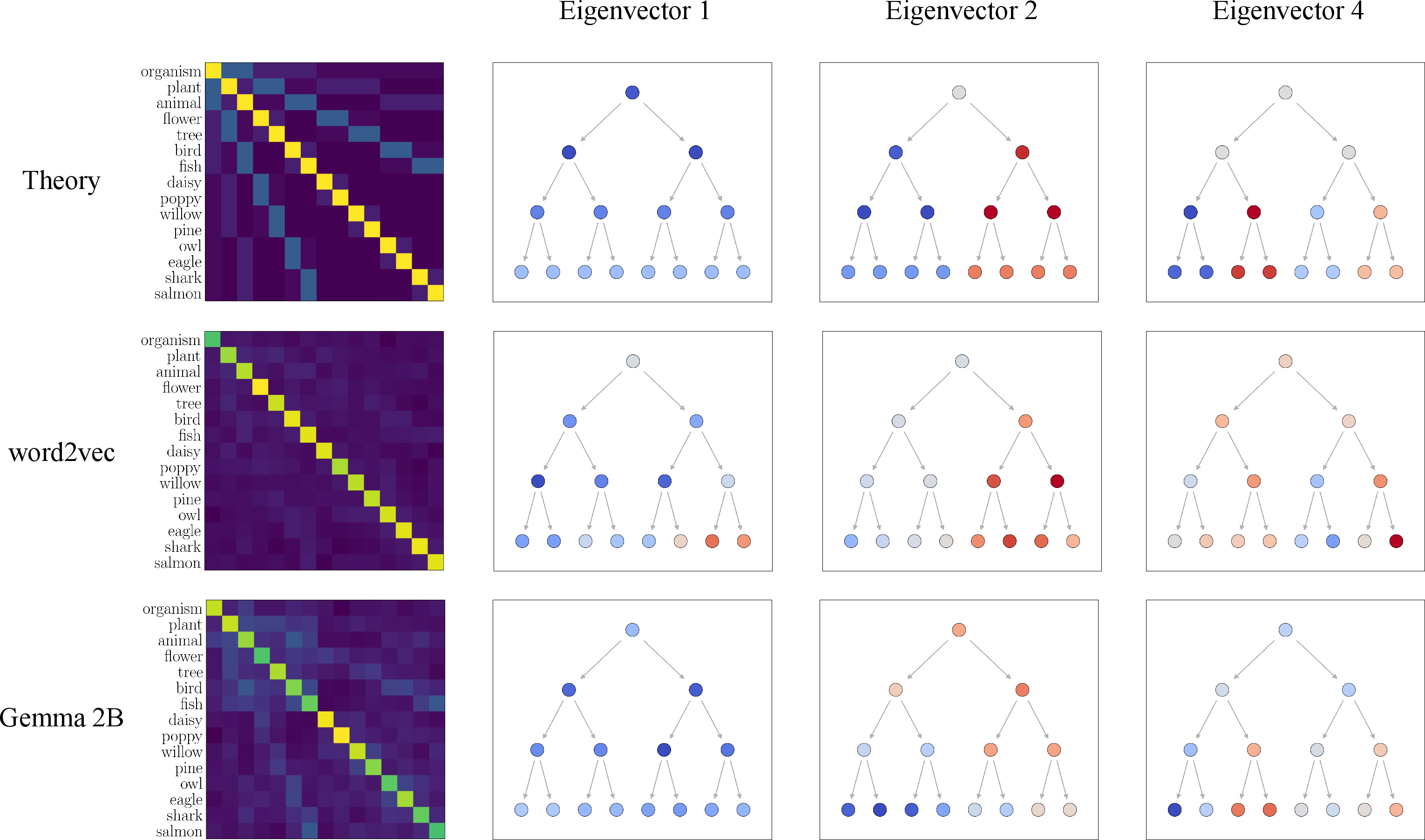
They test this theory in two places:
- Word2vec embeddings built from co-occurrence.
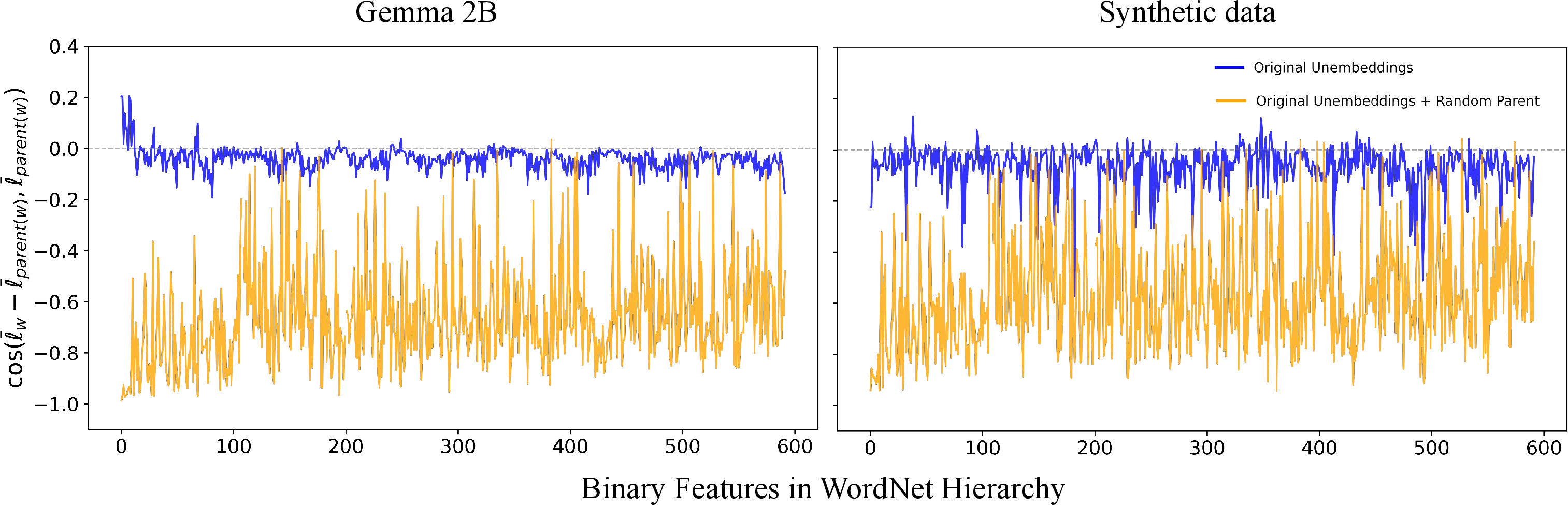
- Gemma 2B’s unembedding vectors (a part of the model that helps map its internal signals back to words), after basic processing to remove global bias.
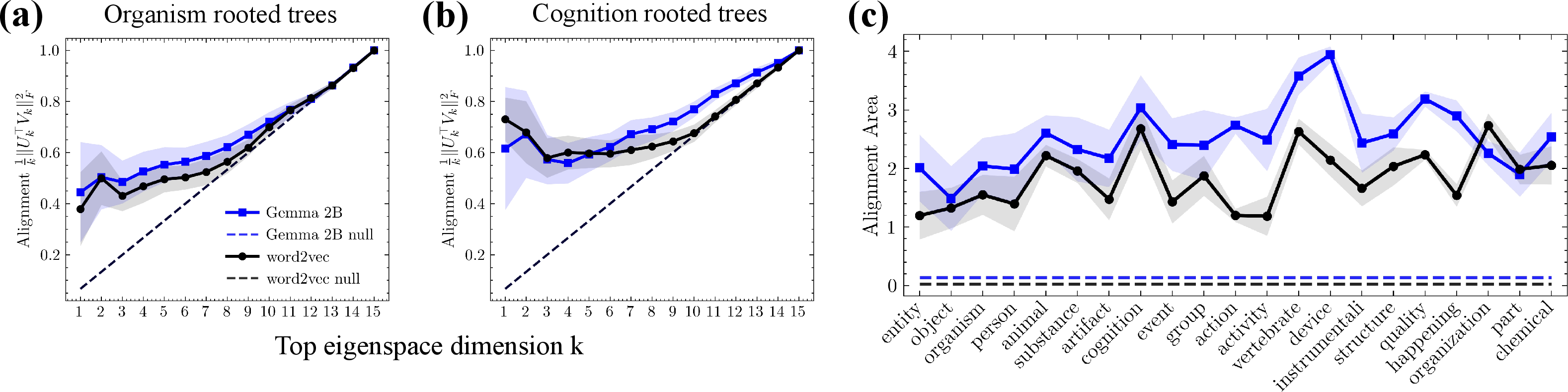
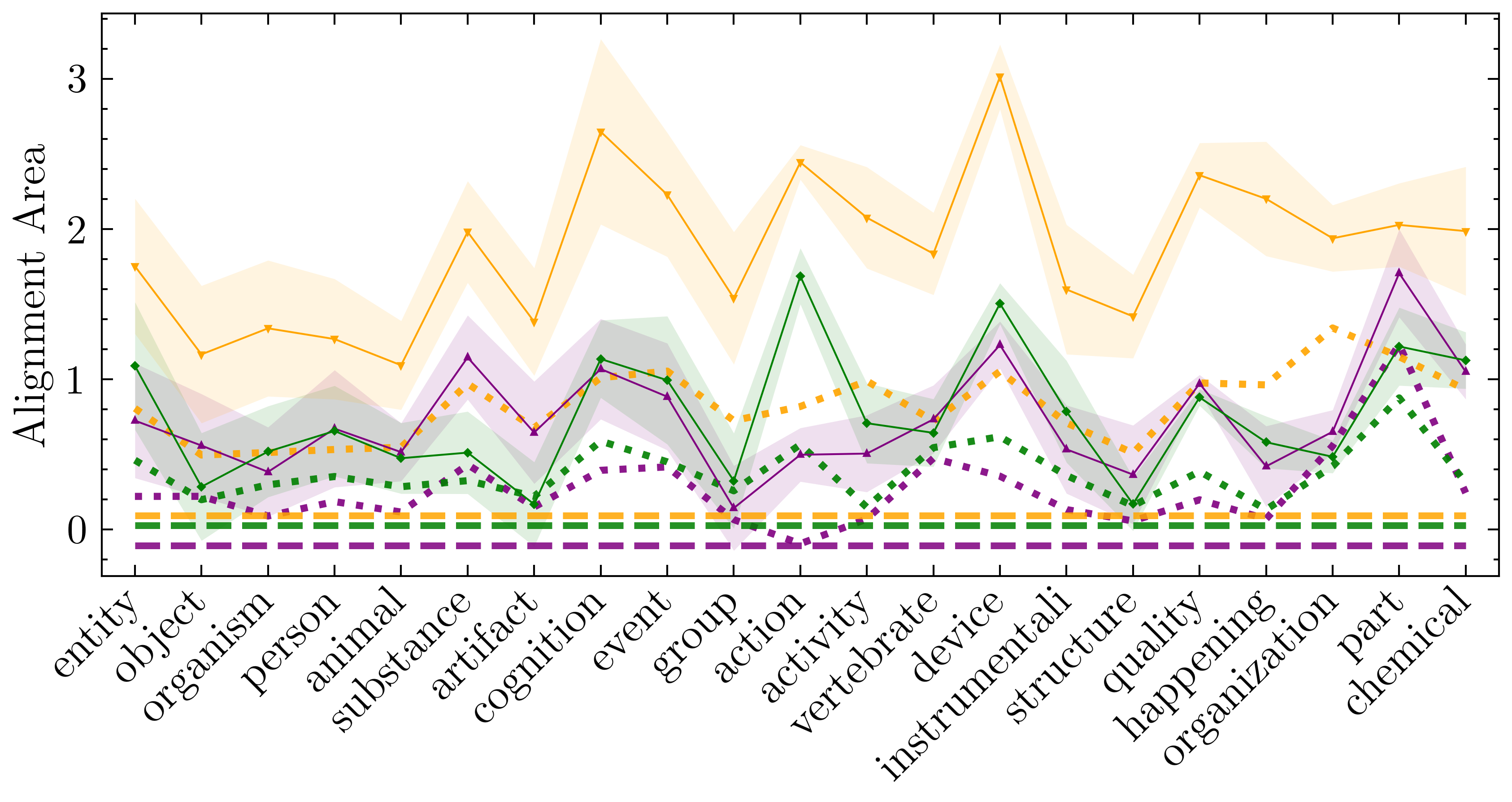
They also sample many small “balanced” trees from WordNet (for example, perfect binary trees of depth 3) and compare the predicted geometry to what the embeddings actually show, using a simple alignment score that checks how well the top directions match.
Main Findings: What did they discover?
The results strongly support their idea.
- Co-occurrence decays with WordNet distance: Words closer in the concept tree co-occur more often.
- Hierarchical splitting appears naturally:
- In word2vec, the top principal components split the tree from coarse to fine. For example, one direction separates animals from plants; another separates birds from fish; another separates flowers from trees.
- The same pattern shows up in Gemma 2B. Even though it’s a big, modern model, its word representations show the same “coarse-to-fine” structure.
- The structure is robust across many concept trees: When they sample many WordNet subtrees (like ones rooted at “organism” or “cognition”), the predicted and actual directions line up much better than random chance.
- A known “orthogonality” signature appears without special rules: Earlier work noticed that when you refine a concept (like going from “animal” to “bird”), the “new part” you add is almost at a right angle to the “old part.” This paper shows that pattern can be explained just by co-occurrence geometry—no special hierarchy mechanism is needed.
Why is this important? It shows that the elegant geometry of meaning—how models place concepts in space—is a natural outcome of simple statistics: which words tend to appear together. That’s a powerful and general explanation.
Implications: Why does this matter?
This work gives a clear, testable story for how LLMs build a hierarchy of concepts:
- Simpler theory, broad reach: You don’t need to assume the model has special parts designed for hierarchies. Just the way words co-occur can generate the structure.
- Better interpretation and control: If we understand that big “concept splits” come from co-occurrence, we can predict them, measure them, and possibly steer models more safely and effectively.
- Design and diagnostics: It suggests that tweaking training data (which changes co-occurrence patterns) could shape the hierarchy of concepts the model learns.
- Connection to other structures: Past work showed analogies (like king − man + woman ≈ queen) and maps (like city coordinates) also come from word statistics. This paper adds hierarchical “is-a” relations to that list.
The authors note limits: they focused on word2vec and on one slice of a modern LLM (unembeddings). Extending the full theory to transformer training dynamics and handling ambiguous words (words with multiple meanings) are promising next steps.
Takeaway
LLMs and word embeddings naturally learn layered, tree-like concept structures because words that are semantically close tend to appear together in text. This simple fact creates the “coarse-to-fine” geometry seen across many systems—no special hierarchy machinery required.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized to guide follow-up research.
- Theoretical robustness to noise: The theory assumes small fluctuations but does not quantify how large or structured noise can be before coarse-to-fine spectral organization breaks down; provide perturbation bounds or phase-transition thresholds for eigenspace stability.
- Indefiniteness of : The analysis largely assumes PSD or truncates negative eigenvalues ad hoc; characterize when is indefinite in practice, how negative modes affect geometry, and whether zeroing negative eigenvalues is theoretically justified.
- Kernel identifiability and estimation: The exponential decay is fit empirically but alternatives are not tested; develop principled kernel estimation procedures (e.g., model selection, confidence intervals) and compare against non-exponential decays or mixtures.
- Dependence on corpus and context window: The corpus used to compute and the context-window size are not specified or varied; assess how different corpora (domain, size, temporal slice) and window choices affect and the resulting spectra.
- DAG-to-tree conversion bias: WordNet is a DAG; the method contracts it into an arborescence by maximizing depth, which may discard important multiple-parent links; compare against using the full DAG (e.g., LCS-based distances, multi-parent kernels) and quantify sensitivity to parent-selection heuristics.
- Hierarchy distance metrics: Only simple tree distance is used; test alternative semantic distances (e.g., Wu–Palmer, Lin, Resnik) or edge-weighted distances and evaluate their impact on the co-occurrence kernel and spectral predictions.
- Generality beyond perfect binary subtrees: Experiments focus on depth- perfect binaries; extend theory and tests to irregular, deeper, and higher-branching trees, and quantify how non-regularity perturbs eigenvalue ordering and degeneracies.
- Depth limitations and sample size: The largest tested depth is due to data constraints; investigate data augmentation or larger corpora to test deeper hierarchies and whether spectral ordering persists.
- Polysemy and sense disambiguation: The study excludes polysemous words; develop context-conditional analyses (e.g., sense-annotated corpora, contextual embeddings) to test whether hierarchical geometry holds per-sense and how LLMs allocate senses across contexts.
- Tokenization and mapping to WordNet: Only words with clean noun synsets and token matches are used; analyze the impact of subword tokenization, multiword expressions, and synset granularity on geometry and alignment.
- Cross-model generality in LLMs: Validation is only on Gemma 2B unembeddings; test across architectures (e.g., Llama, GPT, Mistral), sizes, and layers, including contextual hidden states, to map where/when hierarchical spectra emerge.
- Whitening dependence: Unembedding vectors are whitened; systematically evaluate sensitivity to preprocessing choices (whitening, centering, anisotropy removal) and identify model-intrinsic vs preprocessing-induced geometry.
- Training dynamics link: The account explains word2vec-like embeddings via statistics but leaves open a rigorous link from transformer objectives and optimization dynamics to spectral decomposition and hierarchical modes.
- Confounding relations and topicality: Co-occurrence reflects many relations (topical, syntagmatic, meronymy); quantify how much hypernym distance uniquely explains after controlling for confounds and whether residuals distort hierarchical modes.
- Mixture of attributes: Words bear discrete, continuous, and hierarchical attributes; provide a multi-attribute model predicting how modes compete or mix and how to disentangle overlapping structures spectrally.
- Stability of degenerate eigenspaces: Degenerate wavelet subspaces are reported, but their resolution in real data is not characterized; analyze how corpus asymmetries or noise choose bases within degenerate spaces and the implications for interpretability.
- Statistical testing and baselines: Alignment is assessed via top- subspace overlap and a shuffled baseline; add stronger baselines (e.g., matched-degree random trees, topic-matched permutations) and formal statistical tests (CIs, p-values, multiple-comparison controls).
- Parameter sensitivity in alignment metrics: The choice of (up to 15) and “alignment area” summary is fixed; perform sensitivity analyses over , dimensionality , and alternative subspace metrics (e.g., principal angles, Procrustes error).
- PMI approximation validity: is linked to PMI only near ; quantify approximation error across the frequency spectrum and explore alternatives (e.g., shifted PMI, smoothed estimators) for rare/common word pairs.
- Frequency and Zipf effects: While normalization removes some frequency bias, residual effects may remain; explicitly control for unigram frequency (e.g., stratification) to isolate hierarchy-driven structure.
- Context granularity: Co-occurrence is measured with a fixed window; test sensitivity to sentence- vs document-level co-occurrence and directional/asymmetric windows on the inferred kernel and spectral modes.
- Non-English and cross-lingual generalization: Only English WordNet is used; evaluate cross-lingual WordNets or BabelNet and multilingual LMs to test universality of hierarchical splitting geometry.
- Other hierarchies and ontologies: Validate on non-WordNet hierarchies (e.g., MeSH, UMLS, Wikipedia categories, product taxonomies) to probe domain dependence and the role of ontology design.
- Downstream functional impact: The work argues geometry can be mechanistic rather than functional; empirically test whether stronger hierarchical spectra correlate with improved hierarchical reasoning or taxonomy-aware tasks.
- Concept-vector estimation details: The Park-style diagnostic uses a 70% descendant sampling; assess robustness to sampling strategy, alternative concept estimators, and selection bias in parent-child pairs.
- Ambiguity in “scaling” mode interpretation: The leading scaling mode varies with depth but its semantic content is unclear; determine whether it reflects hierarchy depth, frequency artifacts, or corpus structure, and how to factor it out when probing specific splits.
- Negative association and anti-co-occurrence: Assumption of positive decaying ignores negative associations (e.g., mutually exclusive concepts); extend the theory to signed kernels and evaluate whether anti-co-occurrence produces distinct geometric signatures.
- Interaction with subword morphology: Morphological families may induce co-occurrence patterns unrelated to hypernymy; quantify their influence and propose controls (e.g., lemmatization, morpheme-aware token aggregation).
- Reproducibility and code release: Code is “to be released,” limiting reproducibility; provide full data specifications (corpus, vocabulary filtering, hyperparameters) and seeds for subtree sampling.
- Formal extension beyond binary trees: Proofs hinge on binary-tree symmetry; generalize the hierarchical Haar basis and interlacing results to -ary and heterogeneous trees, and characterize resulting eigenvalue multiplicities.
- Practical identifiability of directions: Subspace-level alignment is shown, but mapping individual eigenvectors to named hierarchical splits in real, irregular taxonomies remains under-specified; develop procedures to label and track split directions across datasets.
- Causal tests via data interventions: The claim that hierarchy emerges from pairwise statistics could be tested by training on corpora with ablated hierarchical co-occurrence; design controlled datasets to causally validate the mechanism.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by leveraging the paper’s findings that hierarchical concept geometry emerges from co-occurrence statistics and is reflected in word2vec and LLM unembedding spaces.
- Hierarchy-aware model interpretability and auditing
- Sectors: Software, AI Safety, Compliance
- Use: Extract coarse-to-fine concept splits via eigenvectors of Gram matrices to visualize how a model organizes categories (e.g., animal → bird vs fish). Audit whether sensitive categories are entangled across levels.
- Tools/Workflows: “Hierarchy Spectral Explorer” (a small library/plug‑in) that computes and visualizes top‑k eigenspaces and split directions; reports alignment with domain taxonomies.
- Assumptions/Dependencies: Access to model unembeddings or activation features; sufficient corpus statistics; stable vocabulary mapping; compute for eigendecomposition.
- QA for datasets and fine-tunes via top‑k eigenspace alignment
- Sectors: MLOps, NLP research
- Use: Treat the paper’s alignment metric g(k) as a regression test for semantic hierarchy fidelity before/after fine‑tunes or data updates; detect drift or collapse of hierarchical structure.
- Tools/Workflows: CI checks that compute alignment area against a reference (e.g., fitted exponential kernel or a gold taxonomy).
- Assumptions/Dependencies: Reference taxonomy or fitted co-occurrence kernel; reproducible data curation; consistent tokenization.
- Hierarchical semantic search and query expansion
- Sectors: Search, E‑commerce, Enterprise Knowledge Management
- Use: Expand queries upward (general) or downward (specific) by moving along coarse-to-fine principal directions; support faceted navigation that respects taxonomic granularity (e.g., organism → animal → bird).
- Tools/Workflows: “Hierarchical Search API” that projects queries onto split modes for breadth/depth control; hybrid retrieval that toggles specificity with a single parameter (k or eigenmode weights).
- Assumptions/Dependencies: Index of document embeddings; adequate co-occurrence data; optional mapping to WordNet or domain ontology.
- Product taxonomy mapping and catalog hygiene
- Sectors: Retail/E‑commerce
- Use: Auto-assign new products to catalog hierarchies and detect misclassifications by comparing their projections on split modes of the product domain.
- Tools/Workflows: Batch classifier that uses split-space scores; moderation queue for low-confidence placements.
- Assumptions/Dependencies: Product text data; existing taxonomy or fitted kernel; handling polysemy and abbreviations.
- Ontology curation and refinement
- Sectors: Libraries/Archives, Enterprise Knowledge Graphs
- Use: Identify where merges/splits are warranted by inspecting degeneracies and coarse-to-fine eigenstructure; diagnose over-broad or redundant nodes.
- Tools/Workflows: “OntologyAligner” that compares eigenspace structure across versions or sources; suggests candidates for restructure.
- Assumptions/Dependencies: Access to ontologies and relevant corpora; human-in-the-loop validation.
- Prompt steering for specificity control
- Sectors: Content Generation, Customer Support
- Use: Move generated text towards broader or more specific categories by nudging representations along predicted split directions; keep general category constant while toggling subtypes.
- Tools/Workflows: Prompt middleware that computes steering vectors from unembeddings; guardrails preserving higher-level membership.
- Assumptions/Dependencies: Access to representation hooks or logit bias; careful safety testing to avoid unintended shifts.
- Educational visualization of semantic hierarchies
- Sectors: Education, EdTech
- Use: Interactive maps that show coarse-to-fine splits in real text corpora (e.g., biology taxonomy), helping students grasp hierarchical structures.
- Tools/Workflows: Web app that projects curriculum vocab onto leading eigenmodes; lesson plans linking text examples to hierarchy geometry.
- Assumptions/Dependencies: Age-appropriate corpora; licensing for model/vector use.
- Content moderation with controlled generalization
- Sectors: Trust & Safety, Social Platforms
- Use: Differentiate “general category” mentions from “specific subcategory” mentions in detection pipelines; reduce overbroad takedowns.
- Tools/Workflows: Classifiers that include split-mode features; thresholds tuned to maintain parent-class detection while varying child specificity.
- Assumptions/Dependencies: Clear policy taxonomies; evaluation on edge cases; robust handling of polysemous terms.
- Biomedical and legal term navigation
- Sectors: Healthcare (ICD/SNOMED), LegalTech
- Use: Assist coding and legal research by letting users zoom from general codes/precedents to finer ones using split geometry instead of ad‑hoc rules.
- Tools/Workflows: Sidebar “Hierarchy Navigator” in coding or case-law search tools; automatic broader/narrower term suggestions.
- Assumptions/Dependencies: Domain-specific corpora; alignment with regulated ontologies; expert review.
- Benchmarking and reproducibility for hierarchy alignment
- Sectors: Academia, Open-Source Communities
- Use: Standardize evaluation with the paper’s alignment metrics and fitted exponential kernels for public models and datasets.
- Tools/Workflows: Leaderboards reporting alignment areas by domain; reproducible scripts from the authors’ code release.
- Assumptions/Dependencies: Open access to embeddings/unembeddings; community-agreed taxonomy subsets.
Long-Term Applications
These applications are promising but need further research, scaling, or engineering (e.g., handling polysemy, extending beyond unembeddings, domain validation, or policy adoption).
- Training-time objectives to shape hierarchical geometry
- Sectors: Foundation Models, Applied NLP
- Use: Curriculum design and sampling strategies that modulate co-occurrence patterns to encourage desired coarse-to-fine structure in-domain.
- Potential Products: “Hierarchy‑aware pretraining” recipes that improve controllability and interpretability.
- Dependencies: Understanding of transformer dynamics; risk of unintended biases; compute cost.
- Taxonomy induction from scratch via spectral co-occurrence
- Sectors: Knowledge Graphs, Information Science
- Use: Infer hierarchical ontologies directly from text without relying on WordNet; bootstrap domain taxonomies (e.g., cybersecurity, materials science).
- Potential Products: “TaxonomyBuilder” that outputs a draft hierarchy with confidence scores.
- Dependencies: Large, representative corpora; polysemy resolution; human curation loop.
- Representation distillation and compression using coarse-to-fine subspaces
- Sectors: Edge AI, Enterprise Deployment
- Use: Distill models into task-relevant hierarchical subspaces for smaller memory/latency while preserving category structure.
- Potential Products: Subspace-aware quantization/pruning toolchains.
- Dependencies: Proven task transfer; stability of split modes across domains.
- Cross-lingual and cross-domain ontology alignment via spectral signatures
- Sectors: Localization, Multinational Enterprises
- Use: Align hierarchies across languages or business units using structure of eigenspaces rather than direct term mapping.
- Potential Products: Cross-lingual “OntologyAligner” with co-occurrence bridges.
- Dependencies: Multilingual corpora; careful handling of cultural/market differences.
- Bias and fairness diagnostics centered on hierarchical disentanglement
- Sectors: AI Safety, Governance
- Use: Detect overgeneralization (e.g., from subgroup to group) by measuring leakage across split levels; prioritize mitigations at offending levels.
- Potential Products: Fairness audit kits that score level-wise entanglement.
- Dependencies: Sensitive-category taxonomies; policy-defined thresholds; robust statistical testing.
- Multimodal hierarchical concept geometry
- Sectors: Vision-Language, Robotics
- Use: Extend coarse-to-fine spectral structure to image/audio/video co-occurrence (captions, ALT-text) for category control in generation or perception stacks.
- Potential Products: Hierarchy-consistent VLMs enabling precise category control (e.g., “vehicle → car → hatchback”).
- Dependencies: Multimodal datasets; unified embedding spaces; safety validation.
- Policy and standards for transparency reporting
- Sectors: Public Policy, Standards Bodies
- Use: Require disclosure of hierarchy alignment metrics for released foundation models; standard tests demonstrating separation of broad vs specific categories.
- Potential Products: Compliance toolkits that generate standardized reports with alignment curves and areas.
- Dependencies: Consensus on benchmarks; regulator adoption.
- Continual and federated learning with hierarchy-preserving updates
- Sectors: Healthcare, Finance, On-device AI
- Use: Add new subcategories without disrupting parent-level behavior by constraining updates in wavelet subspaces.
- Potential Products: Update protocols that localize changes to specific split levels.
- Dependencies: Robust optimization under constraints; verification methods.
- Knowledge graph integration and retrieval augmentation
- Sectors: Enterprise AI, Search
- Use: Fuse spectral hierarchies with KGs to guide retrieval depth and answer specificity; reduce hallucinations by enforcing parent-child consistency.
- Potential Products: RAG systems with “specificity knobs” driven by split-mode projections.
- Dependencies: KG coverage; latency budgets; evaluation frameworks.
- Clinical decision support and regulated-domain explanations
- Sectors: Healthcare, Legal, Finance
- Use: Provide stepwise, coarse-to-fine explanations that map model reasoning to recognized hierarchies (e.g., symptom → syndrome → diagnosis).
- Potential Products: Explanation layers that trace contributions across split levels.
- Dependencies: Rigorous clinical/legal validation; robust handling of ambiguity; liability considerations.
Glossary
- Anisotropy: Directional imbalance in a representation space where variance is not uniform across directions. "global anisotropy"
- Arborescence: A directed, rooted tree where each node has a unique parent (except the root). "rooted arborescence"
- Cauchy interlacing: A theorem relating eigenvalues of a matrix and those of its principal submatrices, ensuring interleaving order. "Cauchy interlacing:"
- Co-occurrence kernel: A function that maps distances between words (e.g., on a taxonomy) to expected co-occurrence strength. "co-occurrence kernel"
- Co-occurrence statistics: Empirical counts or probabilities describing how often words appear near each other in text. "co-occurrence statistics"
- Concept vector: A direction in representation space intended to encode the presence of a semantic concept. "a concept vector is meaningful"
- DAG (Directed Acyclic Graph): A directed graph with no cycles; used here to describe WordNet’s noun hypernym structure before tree conversion. "hypernym DAG"
- Degenerate eigenspaces: Eigenspaces corresponding to repeated eigenvalues where eigenvectors are defined only up to rotation. "Degenerate eigenspaces."
- Eigenspace alignment: The similarity between the subspaces spanned by leading eigenvectors of two matrices. "Top- eigenspace alignment"
- Exponential kernel: A decay function of the form f(d)=αe{-βd} used to model distance-dependent co-occurrence. "fitted exponential kernels "
- GloVe: A word embedding method that learns vectors from global co-occurrence statistics. "GloVe"
- Gram matrix: A matrix of inner products between vectors that captures the geometry of an embedding set. "Gram matrices"
- Haar wavelets: Orthogonal, localized basis functions used for multi-resolution analysis; here, adapted to tree structures. "analogous to Haar wavelets"
- Hierarchical splitting geometry: A spectral pattern where leading modes separate a taxonomy from coarse to fine branches. "hierarchical splitting geometry"
- Hypernym: A more general concept in a taxonomy that subsumes more specific instances. "hypernyms"
- Hypernymy: The “is-a” semantic relation linking a specific concept to a more general one. "hypernymy---the ``is-a'' relation between more specific and more general concepts"
- Hyponym: A more specific concept in a taxonomy that falls under a broader hypernym. "hyponyms"
- Indefinite (matrix): A matrix that has both positive and negative eigenvalues (neither PSD nor NSD). "indefinite"
- Invariant subspaces: Subspaces that are preserved under a linear transformation (here, multiplication by the kernel matrix). "invariant subspaces"
- Linear representation hypothesis: The idea that high-level concepts are encoded as linear directions in model representations. "linear representation hypothesis"
- Parametric decay model: A fitted functional form (e.g., exponential) describing how co-occurrence strength decreases with distance. "Parametric decay model"
- Pointwise Mutual Information (PMI): A measure of association between two events, often used to quantify word co-occurrence strength. "Pointwise Mutual Information (PMI) matrix"
- Positive semidefinite (PSD): A matrix with all nonnegative eigenvalues, ensuring nonnegative quadratic forms. "positive semidefinite (PSD)"
- Principal components (PCs): Orthogonal directions capturing maximal variance in data; eigenvectors of the covariance or Gram matrix. "principal components (PCs)"
- Principal submatrix: A submatrix formed by selecting the same index set of rows and columns from a matrix. "principal submatrix"
- Regular perturbation theory: Analytical treatment of how small perturbations affect eigenvalues and eigenvectors of a matrix. "regular perturbation theory"
- Scaling basis modes: Level-wise basis functions on a tree that are constant on a given depth and zero elsewhere. "Scaling basis modes."
- Skip-gram embeddings: Word vectors learned by predicting context words from a target word (e.g., word2vec’s SGNS). "skip-gram embeddings"
- Spectral decomposition: Factorization of a symmetric matrix into eigenvalues and eigenvectors, revealing its principal modes. "spectral decomposition of the Pointwise Mutual Information (PMI) matrix"
- Spectral ordering: The ranking of modes by eigenvalue magnitude, here showing coarse-to-fine hierarchical structure. "Coarse-to-fine spectral ordering"
- Split space: The subspace spanned by wavelet modes that contrast sibling subtrees at various relative depths. "split space"
- Unembedding vectors: Output-space vectors mapping hidden states to vocabulary logits in LLMs. "unembedding vectors"
- Unigram probability: The marginal probability of a single word occurring, independent of context. "unigram probability"
- Wavelet basis modes: Tree-structured, sign-flipping basis functions that capture contrasts within subtrees. "Wavelet basis modes."
- Whitening: A linear transformation that removes correlations and scales features to isotropic variance. "whitening"
- WordNet hypernym graph: The semantic network in WordNet linking nouns via hypernym relations, used here to measure hierarchy. "WordNet hypernym graph"
Collections
Sign up for free to add this paper to one or more collections.