- The paper’s main contribution is introducing LHE, which leverages linear maps to recover hierarchical parent-child relations from intermediate LM activations.
- Experiments across five domains and four LM architectures show that low-dimensional subspaces (150–250 dimensions) yield high decodability and significant causal effects.
- The study demonstrates that while global hierarchical geometry is shared, domain-specific subspaces limit cross-domain transfer and enhance targeted interventions.
Linear Representations of Hierarchical Concepts in LLMs
Understanding the internal mechanisms by which LMs encode hierarchical relations (e.g., taxonomies, ontologies) has significant implications for interpretability, transfer learning, and knowledge editing. Previous research primarily focused on the unembedding layer and was restricted to single-token concepts, limiting its applicability. This paper proposes a comprehensive framework to investigate where and how hierarchical structures are represented throughout intermediate layers, accommodating both single-word and multi-token entities across multiple semantic domains.
Methodology: Linear Hierarchical Encoding (LHE)
The core methodological contribution is Linear Hierarchical Encoding (LHE), which operationalizes the search for linear structure underlying hierarchical relations in LMs. LHE extends the Linear Relational Concepts (LRC) paradigm by systematically learning depth- and domain-specific linear transformations. For each relation (is-a, part-of) and hierarchical level, LHE trains a linear map Wr that, when applied to the child concept’s representation in a given layer, approximates the parent concept’s representation at another layer.
Experiments leverage five datasets covering Locations, Research Topics, Persons, Organizations, and Organisms. Evaluation focuses on four prominent decoder-only LMs (Llama 3.2 3B, Llama 3.1 8B, Qwen3 8B, Qwen3 14B), examining intra- and cross-domain generalization and layerwise representation structure.
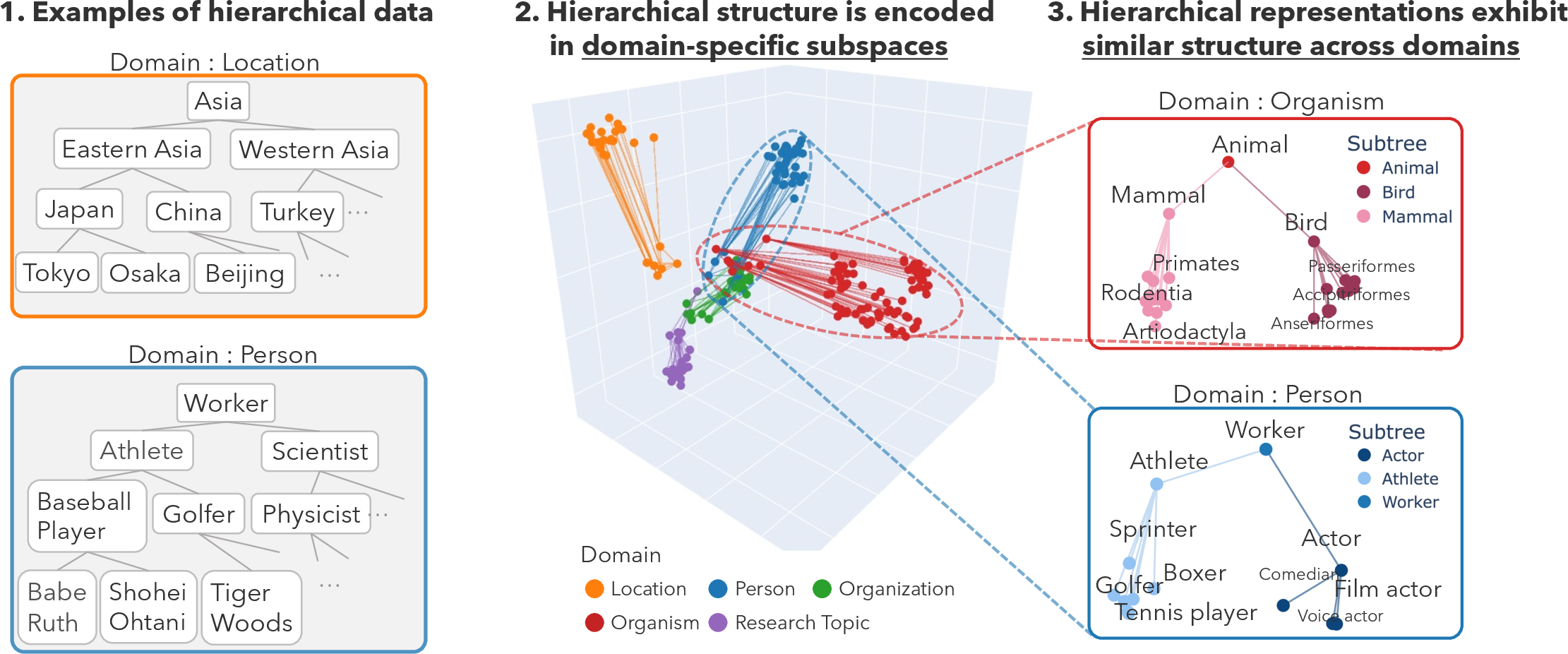
Figure 1: LMs represent hierarchical concepts within domain-specific subspaces in intermediate activations, exhibiting similar structures across domains (PCA visualization after linear transformation).
LHE’s framework enables rigorous decoupling of relation, depth, and domain, facilitating targeted probing of where hierarchical relations are encoded and whether the underlying subspaces are shared or distinct.
Empirical Results
In-Domain Linear Decodability and Causal Effect
Across all domains and models, LHE enables high accuracy for recovering parent-child relations from intermediate layer activations, outperforming both input-averaging and SVM baselines. Causality scores, which assess whether interventions in the learned directions causally alter model predictions, are also substantially elevated for LHE compared to baselines. This demonstrates that hierarchical structure is both decodable and functionally active in LM inference, not merely a spurious correlation.
Strongest performance is observed in Llama 3.2 3B and Llama 3.1 8B, while Qwen3 14B exhibits relatively lower causality—suggesting that direct linear encoding may be diminished in larger Qwen3 variants. This difference implies architectural or pretraining influences on representational geometry, warranting further comparative analysis.
Low-Dimensional and Domain-Specific Subspaces
A critical quantitative finding is that the effective dimensionality of the hierarchy-encoding subspace is remarkably low: peak accuracy and causality are attained with 150–250 dimensions out of hidden sizes in the thousands.
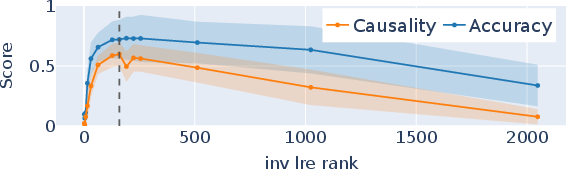
Figure 3: Accuracy and causality as a function of the rank of the pseudo-inverse transformation, showing a peak at low ranks (150–250), indicating a compressed subspace for hierarchical information.
The subspaces are domain-specific; linear maps trained on one domain generalize in accuracy, but causal interventions degrade sharply under domain mismatch.
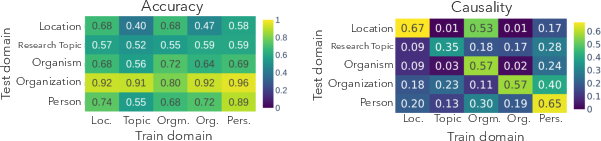
Figure 2: Cross-domain evaluation reveals that while linear decodability (accuracy) is often stable, the causal efficacy of interventions drops drastically under domain shift, highlighting domain-specific subspaces.
Singular value decomposition (SVD) analyses confirm that subject-side subspaces (directions in activation space leveraged for causal interventions) have reduced overlap between domains.
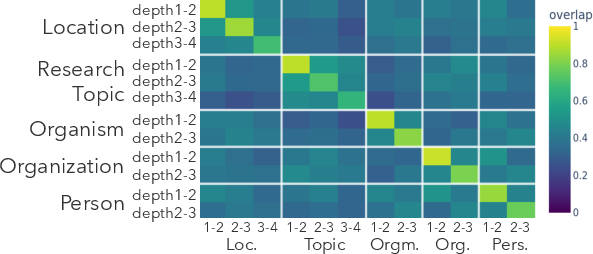
Figure 4: Subspace similarity (based on SVD decomposition) drops outside domain boundaries, confirming that causal structure is localized to domain-specific regions.
Commonality in Representational Geometry
Despite subspace specialization, topological data analysis and PCA visualizations show that the global shape and hierarchical clustering of concept vectors are highly similar across domains. Persistent homology (Wasserstein distances between persistence diagrams) quantifies that the topology of hierarchical representations is more similar between conceptual domains than between these domains and unrelated datasets (random text, business/movie reviews).
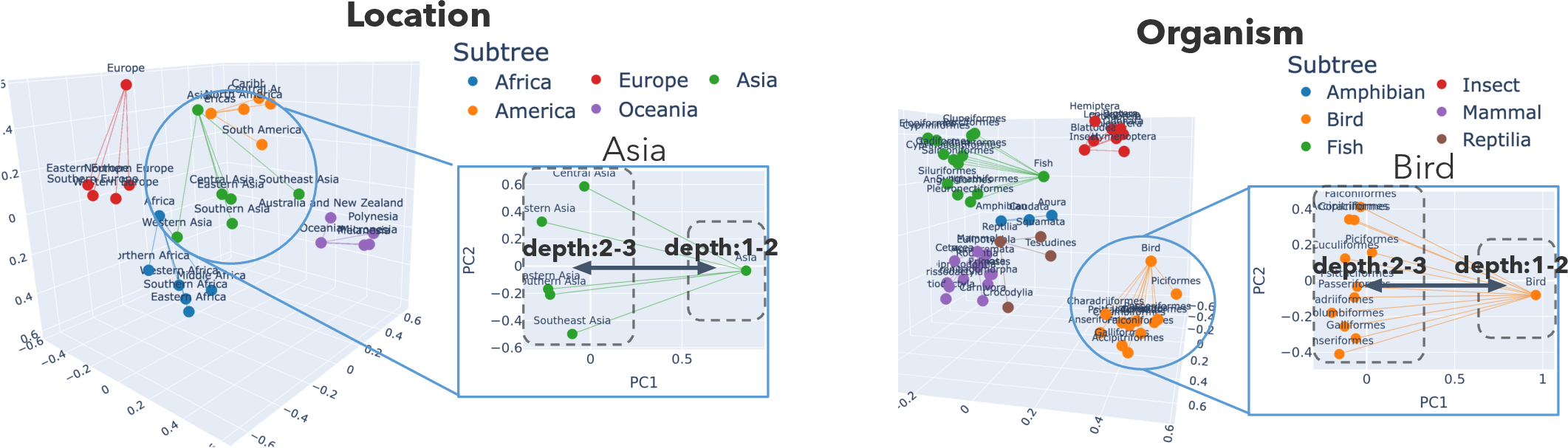
Figure 5: PCA projection of concept vectors (Location and Organism domains) demonstrates depth separation and subtree clustering, revealing shared global structure.
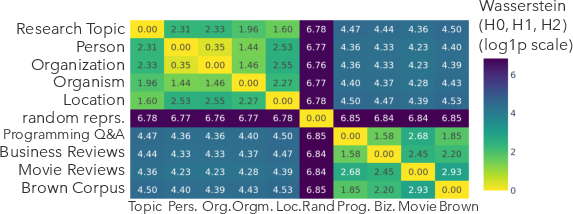
Figure 6: Persistent homology distances (Wasserstein metric) across domains show high similarity among hierarchical domains and clear separation from non-hierarchical baselines.
These findings support a domain-general scheme for encoding hierarchical relations, instantiated in specialized subspaces.
Theoretical and Practical Implications
The results provide direct evidence for the existence of low-dimensional, linearizable representations encoding hierarchical taxonomies within the activations of modern LMs. Such geometric organization aligns with the conceptual spaces framework but also advances interpretability by providing actionable directions for targeted intervention (e.g., knowledge editing, counterfactual manipulation).
The domain-specificity of causal subspaces underscores limits on zero-shot cross-domain transfer of structural knowledge via linear probing/interventions, with ramifications for transfer learning and modularity in LM design.
Of particular note is the observation that even for large, state-of-the-art models, usable hierarchical structure can be extracted with simple linear maps—strongly constraining accounts of the underlying representation manifold and opening avenues for more controllable model behavior.
Future Directions
Open research trajectories include:
- Elucidating the training dynamics by which hierarchical subspaces emerge
- Characterizing how hierarchical representations interface with other relational or attribute-based subspaces
- Investigating hierarchical encoding in multimodal or embodied foundation models
- Exploring interactions with knowledge editing paradigms and symbolic neuro-symbolic hybrid models
- Architecturally regularizing or modularizing models to encourage more robust and generalizable hierarchy encoding
Conclusion
This work demonstrates that LMs implement linearly recoverable representations of hierarchical relations in intermediate activations, with causally effective directions for intervention. These structures occupy low-dimensional, domain-specific subspaces, yet share a globally similar geometry across disparate conceptual domains. These insights meaningfully advance the mechanistic understanding of LM knowledge encoding and have practical import for interpretability, modularity, and editing in neural architectures.
(2604.07886)

