- The paper introduces ToaST, a novel tokenization method that formulates subword vocabulary selection as an integer programming problem to optimize compression.
- It develops a recursive split tree structure that deterministically segments pretokens based on frequency counts, reducing the reliance on greedy methods.
- Empirical results demonstrate over 11% token count reduction and significant improvements in LLM performance, outperforming BPE, UnigramLM, and WordPiece.
Tokenization with Split Trees: Principled Compression-Driven Subword Tokenization
Introduction
"Tokenization with Split Trees" (2605.22705) introduces ToaST, a novel subword tokenization method that frames vocabulary selection as an explicit combinatorial optimization problem under a recursive split tree inference procedure. ToaST is designed to optimize compression (minimize token count) directly and globally, rather than relying on the greedy, merge-based approach used in Byte Pair Encoding (BPE) and the ablative top-down process in UnigramLM. Given the centrality of data compression and the tokenization bottleneck in LLM production and deployment, ToaST aims to reduce the number of inference tokens, extend effective context, and improve token distribution characteristics compared to standard baselines.
Split Tree Construction
ToaST departs from merge-driven methods by constructing, for each unique pretoken (as defined by regular expression segmentation), a full binary split tree using frequency counts of byte n-grams computed over the tokenizer training data. At each node, the split is chosen to maximize min(cp,cp′), where cp and cp′ are the corpus frequencies of the resulting substrings after the split, promoting balanced splits and enhancing the utility of candidate tokens.
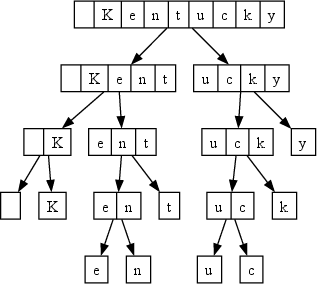
Figure 1: Example split tree for $\textvisiblespace Kentucky$ demonstrates recursive binary splitting based on n-gram counts, with single bytes as leaves.
Each node in the split tree corresponds to a candidate token. This construction is vocabulary-independent: the same deterministic trees are used regardless of the final vocabulary, allowing decoupling between statistical partitioning and subsequent token selection.
Split Tree Inference Algorithm
Tokenization of text is performed by recursively traversing each pretoken's split tree. For a given vocabulary V, the inference process emits a token at the first node encountered on a root-to-leaf path that is present in V; if the node is not in V, its children are considered recursively. All single-byte tokens representing valid UTF-8 code units are always included in V to guarantee tokenizability.
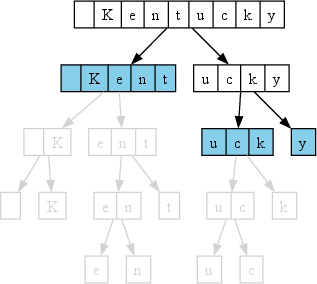
Figure 2: During tokenization, in-vocabulary nodes (blue) are emitted, while out-of-vocabulary nodes (white) are split recursively; unreachable nodes in descent are light gray.
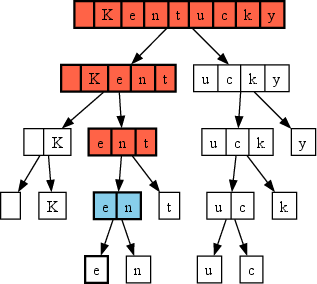
Figure 3: A token appears in the output if and only if the node is in the vocabulary and none of its ancestors are; an example path from leaf to root highlights this property.
This design achieves several properties:
- Changing vocabulary never affects tree structure.
- All valid vocabularies yield correct tokenizations (contrast with BPE merge constraints).
- Removing a token causes local refinements without cascading effects—each tree can be efficiently traversed to update tokenizations incrementally.
Vocabulary Selection as Integer Programming
ToaST formulates the selection of vocabulary tokens as a 0-1 Integer Program (IP): select a subset of candidate tokens of the desired vocabulary size min(cp,cp′)0 to globally minimize the total number of training tokens produced under recursive split inference. The constraints ensure complete coverage of every pretoken with mutually exclusive token assignments along each root-to-leaf path. The model variables represent inclusion of tokens in min(cp,cp′)1 and assignment of tree nodes to the tokenization:
- min(cp,cp′)2: token min(cp,cp′)3 is included in min(cp,cp′)4,
- min(cp,cp′)5: node min(cp,cp′)6 in split tree min(cp,cp′)7 is used in the tokenization.
Due to the tree structure, the LP relaxation of the IP is almost always integral (maximum observed relaxation gap less than min(cp,cp′)8), and rounding heuristics suffice for scalability to hundreds of thousands of split trees and vocabulary sizes exceeding 250k.
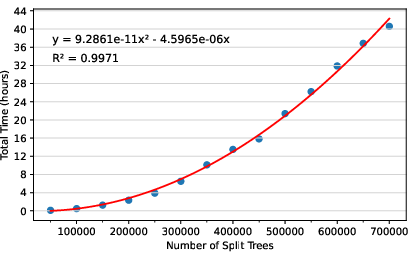
Figure 4: Total training time grows quadratically with the number of split trees; scalability enables coverage of min(cp,cp′)9 of training data.
Intrinsic Compression and Token Distribution Metrics
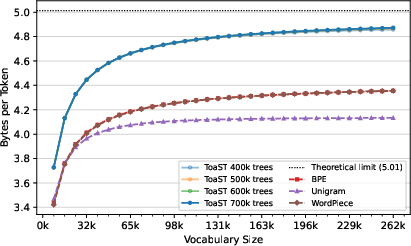
On English data, ToaST achieves superior compression, outperforming BPE, WordPiece, and UnigramLM by over 11% reduction in token count at vocabulary sizes of 40,960 and above. This is a substantial result given that lower token counts:
ToaST yields a dramatically altered distribution of token types: for moderately large vocabularies (e.g., 65,536), use of single-byte fallback tokens (Leaf nodes) is reduced by a factor of 14–19x compared to BPE and similar baselines.
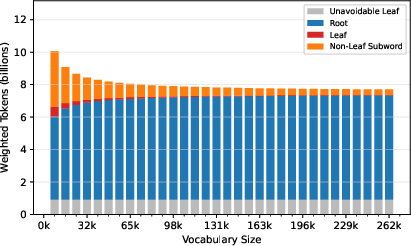
Figure 6: Stack plot of token categories with ToaST; Root tokens (full pretoken coverage) dominate, whereas Leaf usage is suppressed.
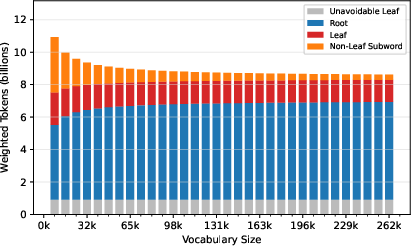
Figure 7: BPE substantially overuses single-byte fallback tokens compared to ToaST.
ToaST also achieves higher R\'enyi efficiency (cp0), reflecting a more uniform token usage distribution and mitigating the issue of excessively frequent tokens that can degrade model capacity and amplify context budget disparities.
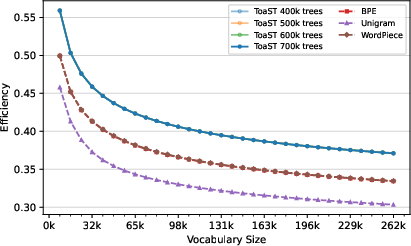
Figure 8: ToaST attains higher R\'enyi efficiency across all vocabulary sizes, indicating superior token utilization uniformity.
In Nanochat LLM training at 1.5B parameters (depth 24), ToaST leads to the best model performance on the CORE metric—a composite average over 22 evaluation benchmarks. The CORE score outperforms BPE by 7.6% and UnigramLM by 5.3% (statistically significant); a 2.6% margin over WordPiece is observed. For individual tasks, ToaST achieves the top score in 13 out of 22 benchmarks.
Pretraining is token-matched, so ToaST's improved compression exposes the network to 11% more text for the same number of tokens—a direct capacity scaling advantage. Notably, the advantages persist in supervised fine-tuning and several reasoning-oriented downstream tasks.
Flexibility and Extensibility
Because split tree construction and vocabulary selection are decoupled, ToaST is highly extensible:
- Split tree partitioning can be guided by morpheme boundaries, character boundaries (multi-byte safety), or superword (phrase) statistics as auxiliary criteria.
- Linear objective coefficients in the optimization may be reweighted by language or domain, directly addressing known tokenization premiums in multilingual settings and supporting fairer LLMs.
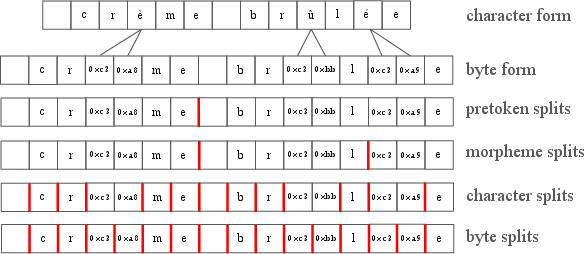
Figure 9: Example hierarchical split preference—superword, morpheme, character, and byte levels can be incorporated into recursive tree construction.
Computational Scalability
Warm-started LP solving and the near-integral relaxation of the ToaST IP make it tractable to solve for a wide range of vocabulary sizes and with very large coverage of highly frequent pretokens, capturing cp199\% of training occurrences with reasonable compute resources.
Conclusion
ToaST implements split tree-based tokenization with global, compression-optimizing vocabulary selection via integer programming. Empirically, ToaST achieves over 11% token count reduction, dramatically fewer fallback tokens, and higher R\'enyi efficiency compared to BPE, WordPiece, and UnigramLM, with strong downstream LLM effects (7.6% higher CORE vs. BPE). Its generality and extensibility make it relevant for future research into multilingual fairness and linguistically-aware tokenization. ToaST provides a compelling framework for principled tokenizer design, with broad practical and theoretical implications for efficient and effective LLM training and deployment.