- The paper introduces a length-weighted vocabulary objective that favors longer tokens to mitigate fragmentation and improve token compression.
- It employs a greedy approximation with Rabin-Karp rolling hashing to achieve near-linear scaling and a 14–18% token reduction relative to BPE.
- Empirical results demonstrate reduced training steps by 18%, lower inference latency by 13–14%, and improved downstream task accuracy.
Length-MAX Tokenizer: Length-Weighted Tokenization for Efficient Language Modeling
Motivation and Methodology
The Length-MAX tokenizer addresses the inefficiency intrinsic to frequency-focused subword tokenization strategies such as BPE, WordPiece, and SentencePiece. Conventional frequency-based merging prioritizes short high-frequency substrings, resulting in fragmented token sequences, increased memory and compute requirements, and degraded performance on tasks requiring long-range sequence modeling. Length-MAX mitigates these through a length-weighted vocabulary objective, maximizing freq(t)×∣t∣, thereby favoring longer tokens that maintain high corpus frequency.
The vocabulary selection is NP-hard, equated to a graph partitioning problem where the corpus is segmented by maximizing average token length over all sequences. A greedy approximation using scoreboard-based candidate selection and Rabin-Karp rolling hashing delivers O(N) complexity and near-linear scaling across up to 256 CPU cores. Token matching during inference is executed via efficient DFA decoding, yielding a 3–4× runtime gain over naïve approaches.
Tokenization Efficiency and Compression
Empirical evaluation on the FineWeb10B corpus demonstrates robust improvements in token compression ratio (tokens per character, TPC) across the entire 10k–50k vocabulary range. Length-MAX consistently achieves 14–18% fewer tokens than BPE and other baselines.
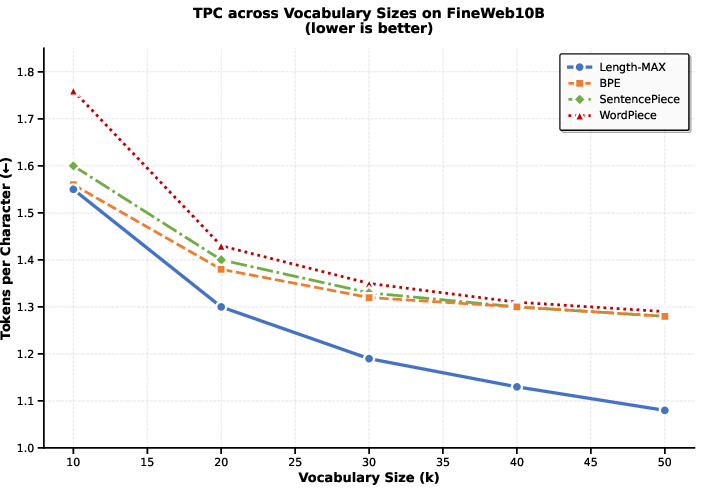
Figure 1: Length-MAX demonstrates lower TPC than BPE, WordPiece, and SentencePiece across vocabularies, confirming enhanced text compression.
Cross-domain experiments spanning news, technical, literary, conversational, and mixed corpora confirm the compression gains are domain-agnostic. Even at 64k and 100k vocabularies, where all methods approach word-level token units, Length-MAX maintains 13.0% and 9.8% lower TPC, respectively.
Scaling Behavior and Training/Inference Cost
Compression efficiency directly translates to improved LLM throughput, reduced training steps, and lower latency. Length-MAX consistently reduces training steps to convergence by approximately 18% and inference latency by 13–14% for GPT-2 architectures at 124M, 355M, and 1.3B parameters. Throughput gain is measured at 16% for 124M. Analytical FLOPs-based extrapolation predicts similar proportional efficiency at the 7B model scale.
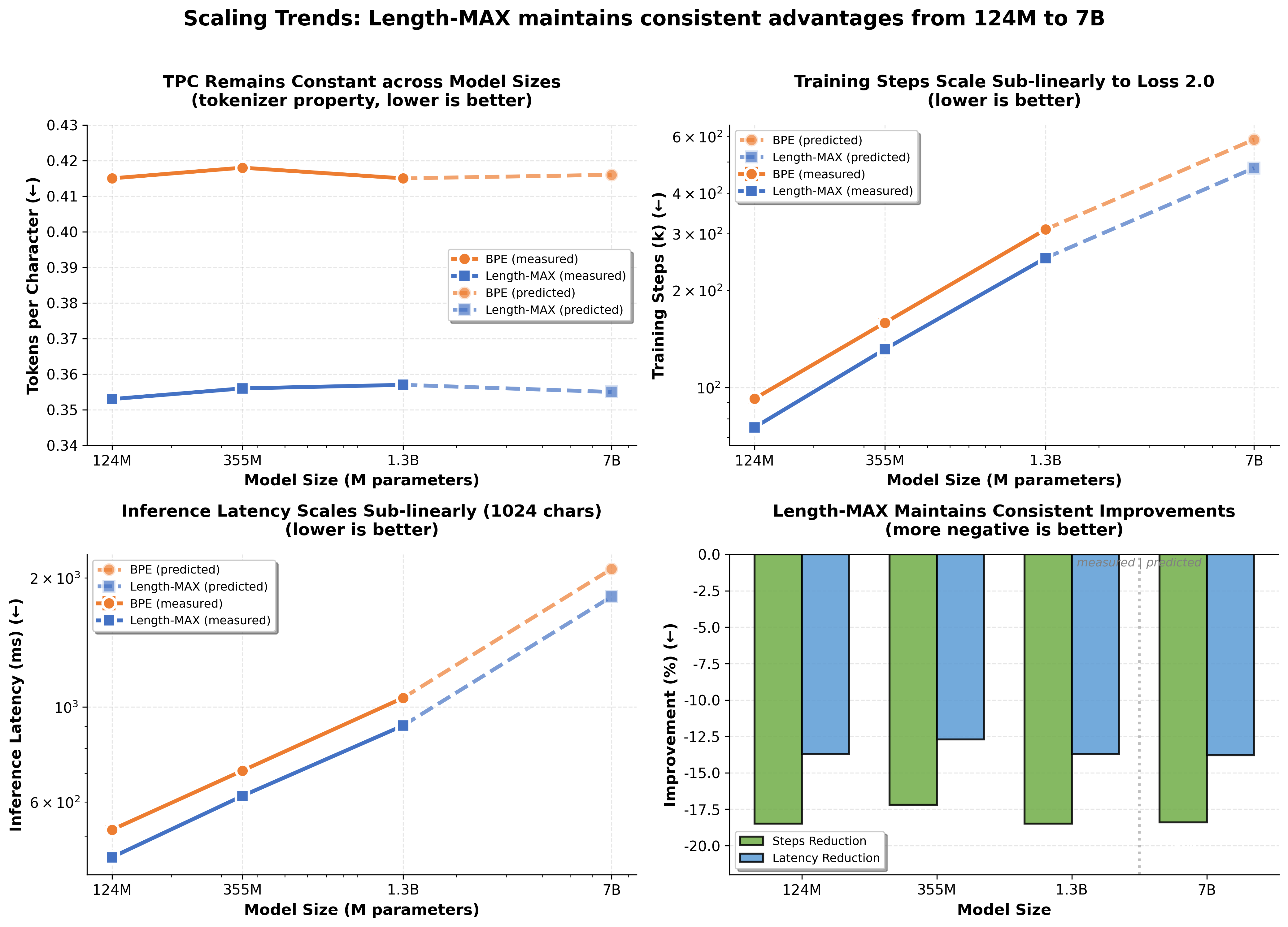
Figure 2: Relative gains in training convergence and inference latency remain stable across scale, with analytical predictions indicating persistence for larger models.
Latency and throughput improvements are statistically robust (p<0.001, paired bootstrap), and memory consumption reductions for embedding and KV-cache consistently reach ≈18%.
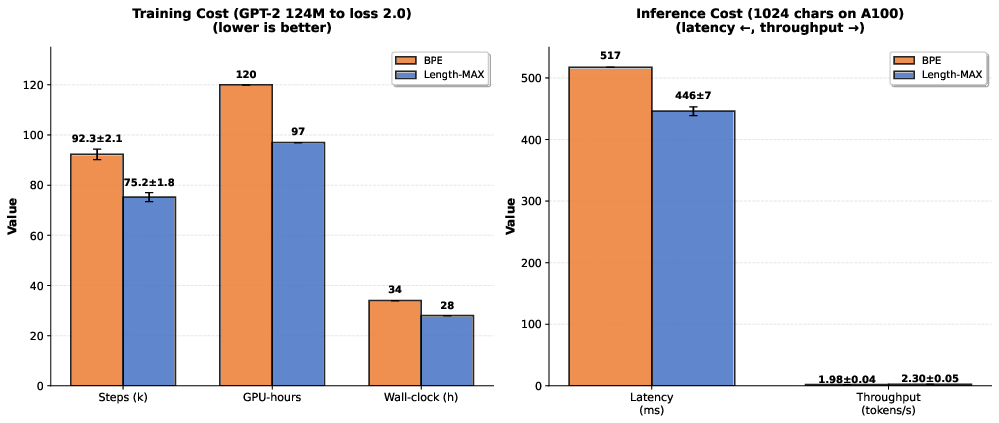
Figure 3: Steps to convergence, inference latency, and throughput all show improved efficiency metrics for Length-MAX.
Contrary to potential trade-off concerns, Length-MAX delivers both compression and downstream performance gains. GLUE macro-average accuracy improves by 12.8%, with strong effects on NLI tasks (QNLI +49%, RTE +58%). Extended suite evaluation (BLiMP, LAMBADA, StoryCloze, SQuAD, HellaSwag, PIQA, Winograd) shows a macro-average gain of +2.9 points. LAMBADA perplexity reduction of 11.7% and HellaSwag accuracy increase of 4.3 points highlight robust contextual modeling.
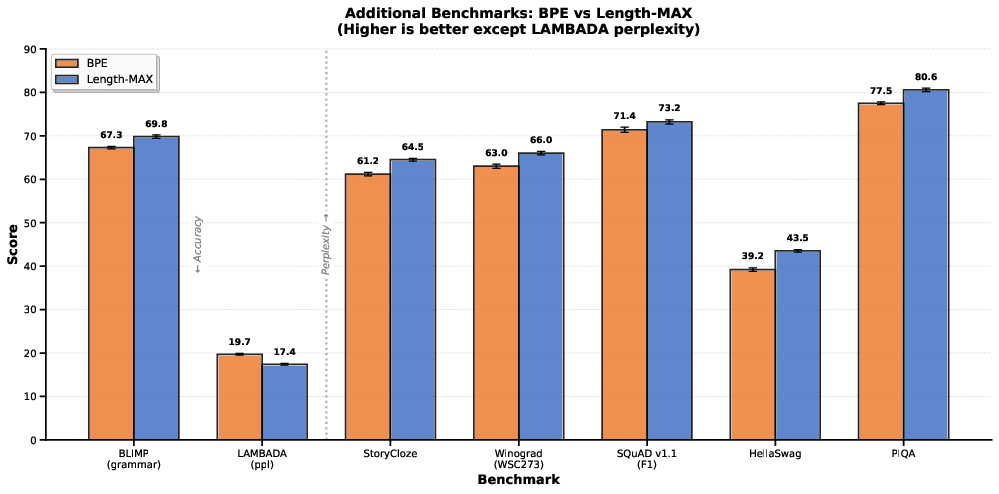
Figure 4: Macro-average improvements across diverse downstream tasks confirm the practical advantages of Length-MAX tokenization.
Human and automated GPT-4 evaluations on TinyStories attribute a 85% model preference for Length-MAX outputs on test prompts, with marked consistency (+60%) and grammar (+16.7%) improvement.
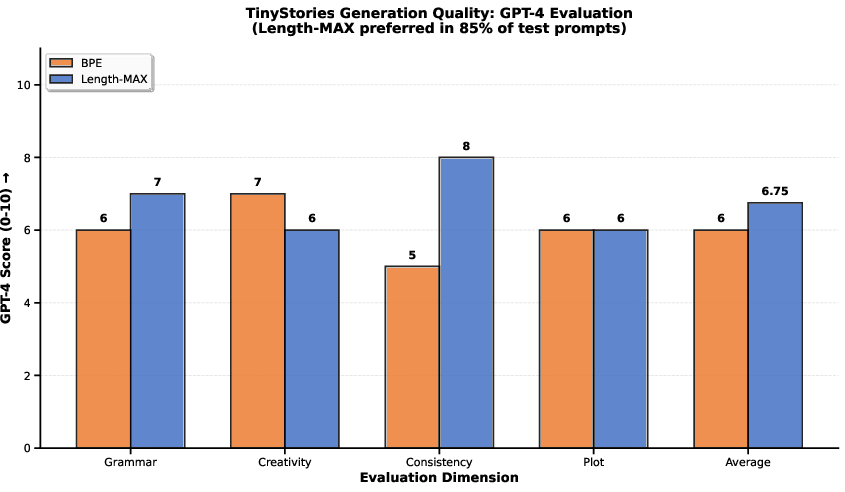
Figure 5: GPT-4 prefers generations from models trained with Length-MAX, especially for consistency and grammaticality.
Token Distribution, Zipf Alignment, and Vocabulary Utilization
Length-MAX redistributes probability mass from redundant short tokens to multi-word semantic units, flattening vocabulary head variance while preserving Zipf-like tail behavior. Quantitative alignment to Zipf’s law improves (R2=0.941, α=0.95) relative to BPE (R2=0.909, α=1.08).
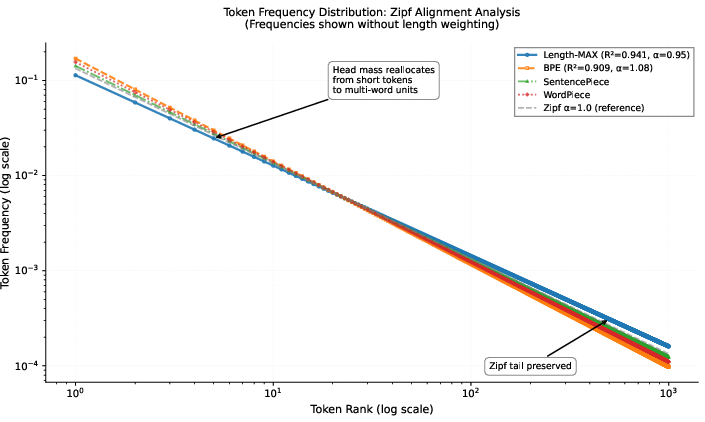
Figure 6: Head variance reduction and increased prevalence of multi-word tokens relative to BPE; Zipf-like distribution is preserved.
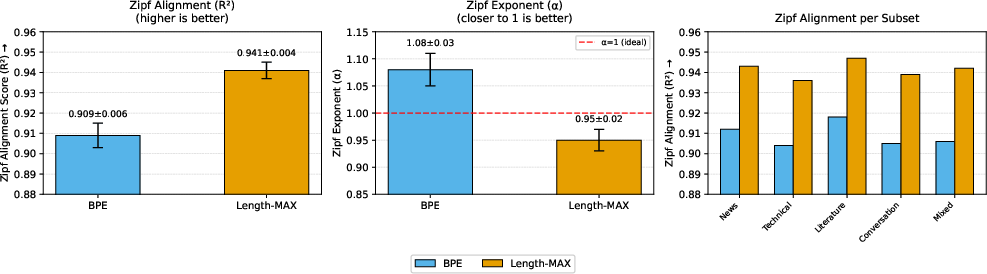
Figure 7: Zipf alignment for mean R2, exponent α, and subset scores confirms desirable distributional shift.
Vocabulary coverage is nearly complete (99.62%), and OOV rate remains low (0.12% vs. 0.15% for BPE). DFA-based inference preserves robustness under character-level noise, with negligible perplexity degradation.
Throughput, System Engineering, and Implementation
Length-MAX’s algorithmic design eliminates merge-based sequential dependencies, achieving near-linear multi-core scaling (87% at 256 cores) and outperforming HuggingFace tokenizers in both vocabulary construction and encoding throughput.
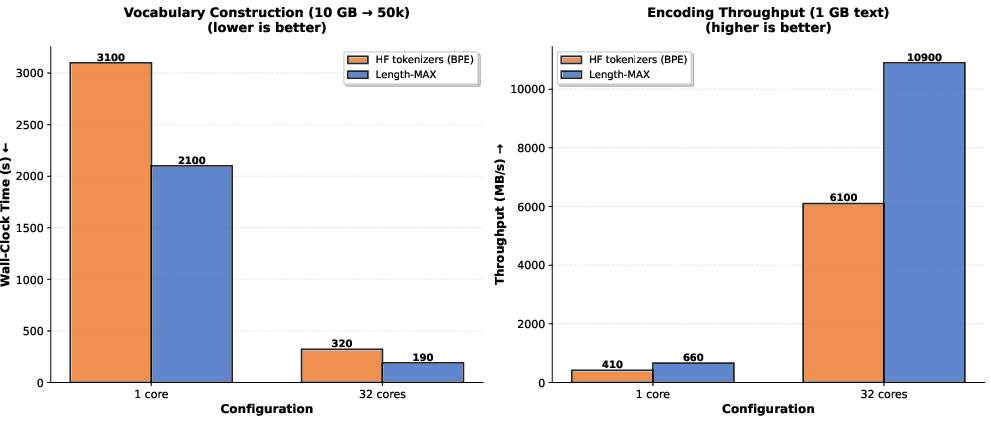
Figure 8: Length-MAX outpaces HuggingFace BPE in construction time and encoding throughput, confirming system scalability.
Cache-efficient scoreboard structures and SIMD vectorization contribute to single-node performance gains. Map-Reduce vocab merging and shard-based corpus parallelism provide practical distributed scalability on TB-scale data.
Limitations and Future Directions
Current experiments focus on English and models up to 1.3B parameters. Extension to morphologically rich or logographic languages, as well as empirical validation on even larger LLMs, remains for follow-up research. Length-MAX cannot be directly applied to frozen pretrained checkpoints due to token embedding dependency. Integration strategies with token-free architectures (e.g., ByT5, CANINE, BLT) and boundary-aware methods (e.g., SuperBPE) present promising avenues for hybridization.
Conclusion
Length-MAX operationalizes length-weighted tokenization, providing consistent gains in compression, compute efficiency, and downstream model performance over frequency-only baselines. Its NP-hard graph partitioning formulation, greedy approximation, and production-scale implementation generalize across model sizes and domains without architectural modification. The approach yields substantial numerical improvements verified across training, inference, downstream tasks, and systemic throughput, while preserving corpus semantics and power-law token distribution alignment. Future work should address broader linguistic coverage and hybridization with complementary tokenization paradigms.

