- The paper introduces an RL-driven framework that dynamically assigns specialized model-skill pairs to overcome monolithic reasoning bottlenecks.
- Maestro achieves superior performance with 70.1% average accuracy across benchmarks and demonstrates efficient latency (2.88s) and token usage.
- The hierarchical registry and reward-shaping strategy validate scalable orchestration, facilitating rapid integration of new skills without retraining.
Reinforcement Learning-based Orchestration for Multimodal Model-Skill Ensembles: An Expert Review of "Maestro"
Paradigm Shift: From Monolithic Agents to Strategic Model-Skill Ensembles
The proliferation of LLMs and modular skills has fostered enhanced agentic capabilities, but prevailing paradigms are bottlenecked by the reliance on monolithic reasoning backbones and static skill interfacing. The paper "Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles" (2605.22177) introduces a principled alternative, arguing that domain heterogeneity in multimodal tasks necessitates dynamic assignments of specialized models and skills. Maestro operationalizes this as RL-driven orchestration in a hierarchical model-skill registry, formalizing agentic composition as sequential decision-making with a compositional action space.
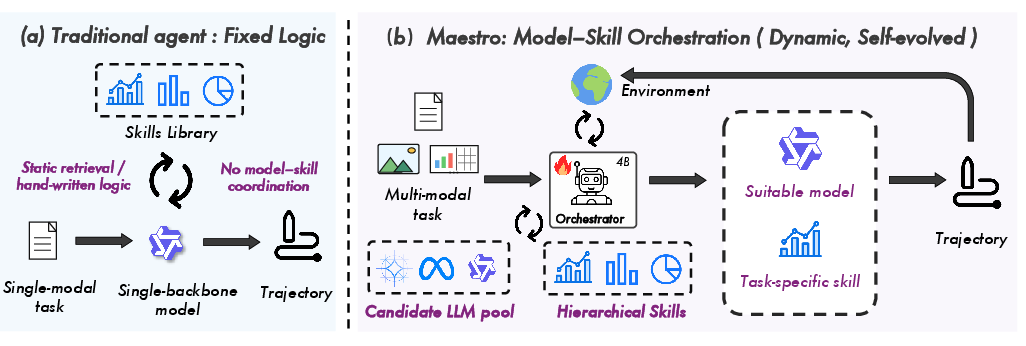
Figure 1: Architectural comparison, showing Maestro's RL-based orchestration for dynamic expert coordination versus traditional fixed-logic dispatch.
Maestro Framework: Hierarchical Registry and RL Policy Structuring
The Maestro orchestrator is instantiated as a lightweight policy model (4B) that interfaces with two-tier skill hierarchies and frozen expert models. The action space is compositional—each action specifies a model-skill pair and query semantic. The orchestration process is cast as a finite-horizon POMDP; at each step, the orchestrator chooses to invoke an external expert, determines the best skill, and decides task termination, optimizing the trajectory via outcome-based RL using Group Relative Policy Optimization (GRPO) rather than step-level supervision.
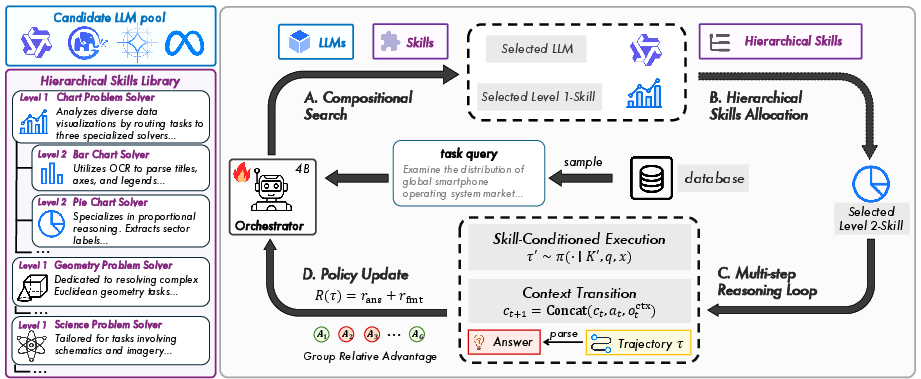
Figure 2: Maestro’s framework, detailing unified compositional action space and iterative evidence-grounded reasoning.
Hierarchical skills (Level-1 coarse, Level-2 fine) and model pools effectively compress the search space, enabling tractable RL optimization. Algorithmic details delineate a masking strategy for token-level policy gradients that ensure the orchestrator only models action token distributions—environment feedback tokens are excluded. Multi-dimensional reward shaping (task correctness, structural protocol adherence) ensures both logical and communication rigor.
Empirical Results: Demonstrated Superiority, Generalization, Efficiency
In-domain and Out-of-domain Benchmarking
Maestro achieves 70.1% average accuracy across 10 multimodal benchmarks, surpassing GPT-5 (69.3%) and Gemini-2.5-Pro (68.7%) with a substantially smaller orchestrator. Notable domain-specific gains are seen in geometric reasoning (Geometry3K: 77.4% vs GPT-4o: 34.1%) and chart understanding (ChartQA: 86.8%). Out-of-domain robustness is evidenced with VStar (88.0%) and HRBench-4K (79.6%), outperforming specialized visual “think with images” methods.
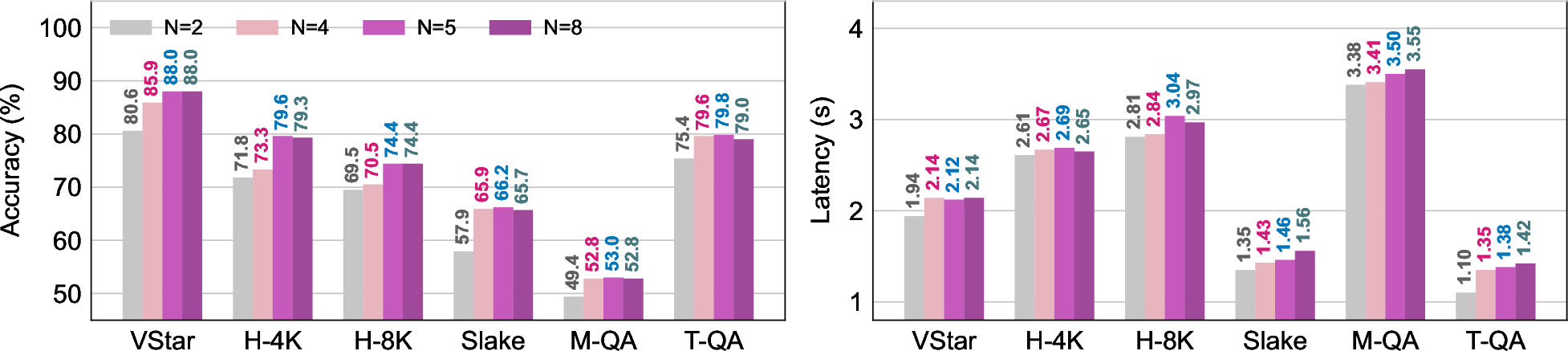
Figure 3: Performance and latency scaling with skill pool size; accuracy grows sub-linearly with added skills, efficiently exploiting richer capabilities.
Plug-and-play generalization is empirically validated: Maestro, without retraining, incorporates new expert models and skills (Maestro*) and yields 59.5% average accuracy on OOD specialized benchmarks (ERQA, OCRBench, VlmsAreBlind, Humaneval_V), outperforming the strongest closed- and open-source baselines.
Efficiency and Scalability
The framework demonstrates lowest average latency (2.88s) and token consumption (648.20 tokens) across all compared methods. The RL-based orchestrator rapidly converges to confident policies, invoking high-level skills only as needed, confirmed by reward and entropy training dynamics.
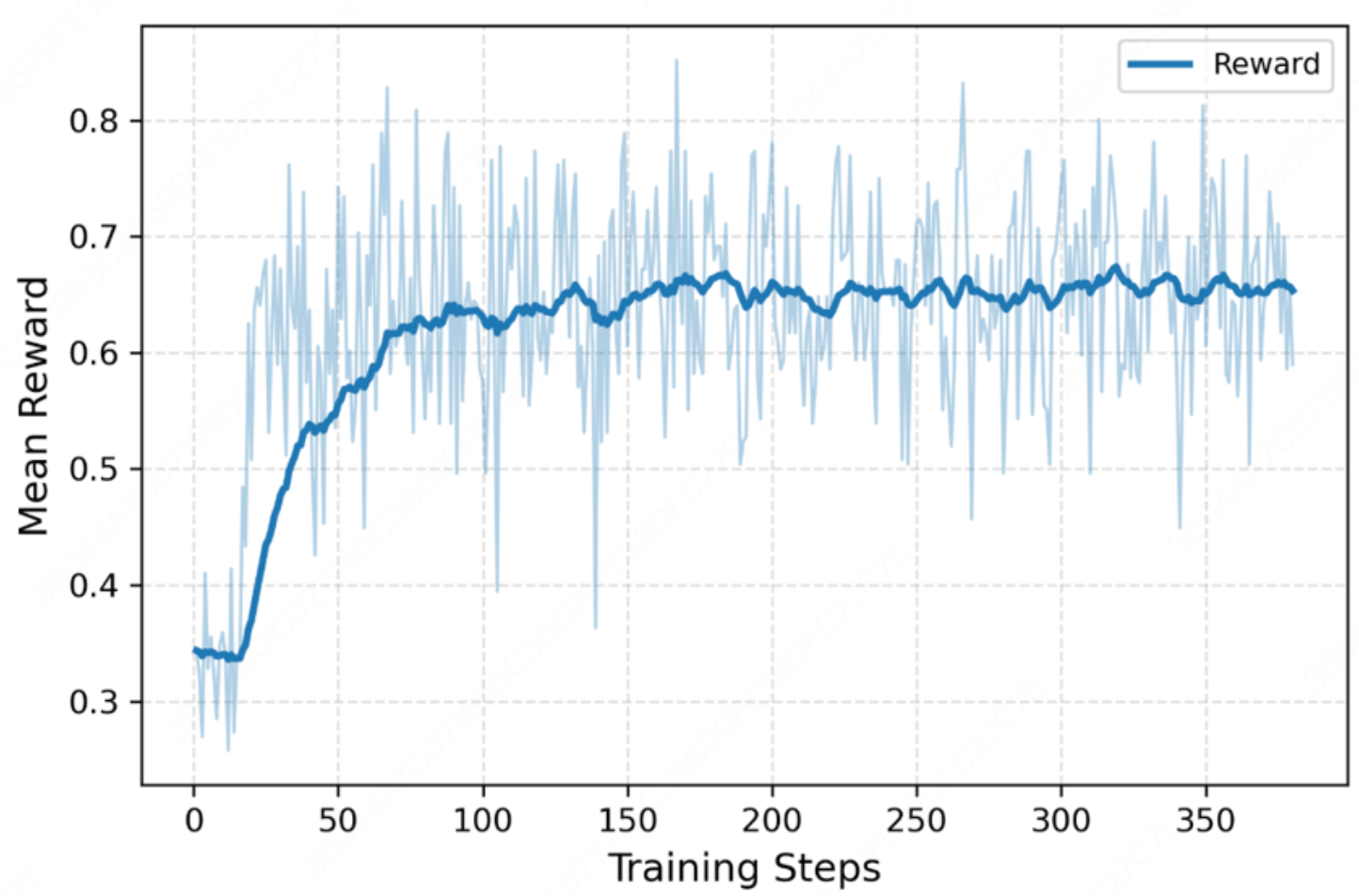
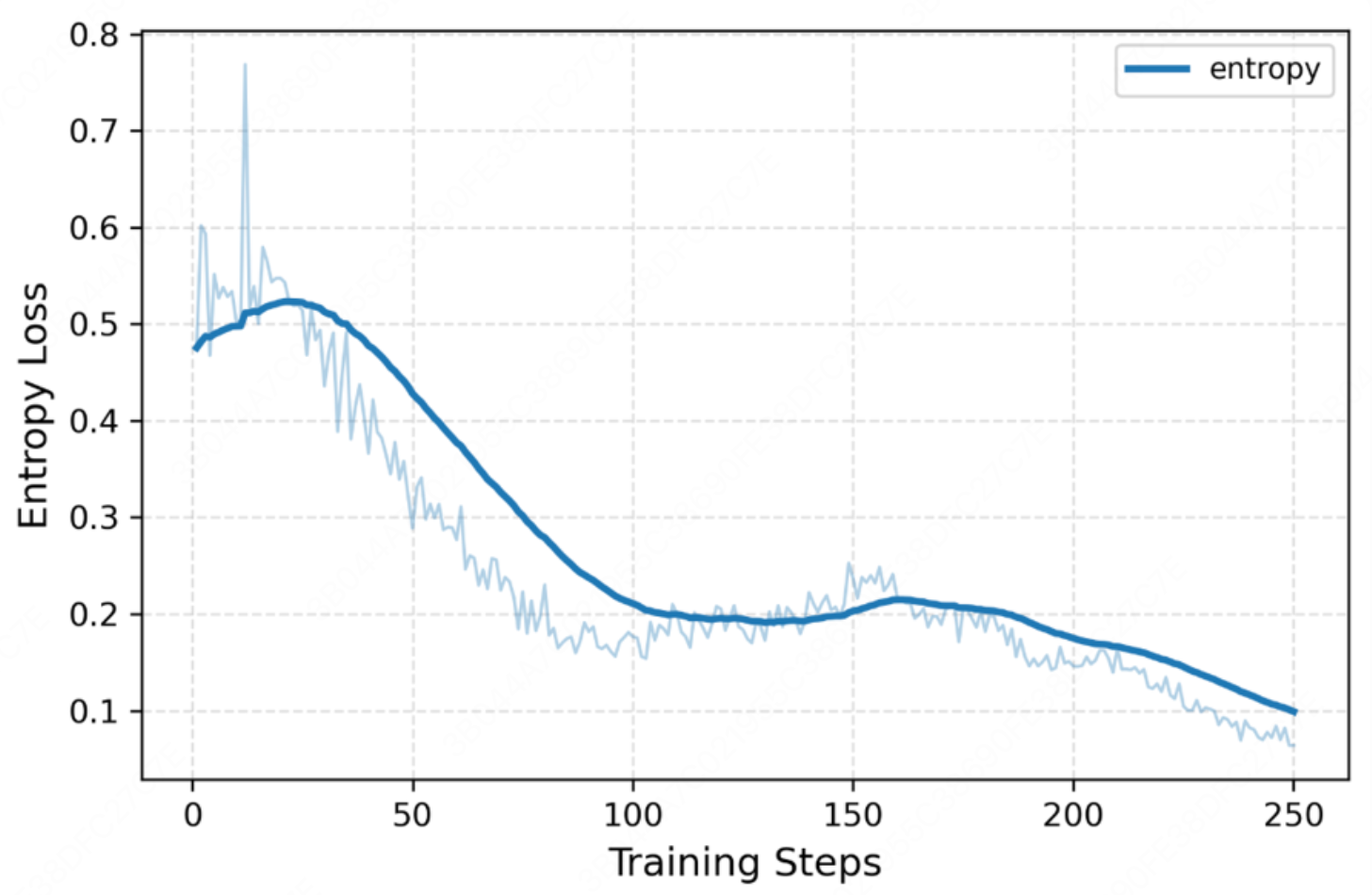
Figure 4: RL training dynamics—reward plateau and declining entropy signal stable and confident orchestration.
Ablation and Upper Bound Analysis
Ablation studies show independent and complementary contributions of the skill library and expert model pool. Removing either reduces performance drastically, especially on reasoning-intensive domains. The format reward is essential for protocol-valid outputs; removing it leads to a -13.1% drop. Importantly, RL-based orchestration confers a +17.4% accuracy gain over retrieval-based workflows.
Qualitative Orchestration: Task-adaptive Expert Composition
Maestro demonstrates task-aware dispatching: for example, on ChartQA, it first invokes GLM-4.6V-Flash with Perception Problem Solver to localize chart elements, and then Chart-R1 with Chart Problem Solver for final reasoning.
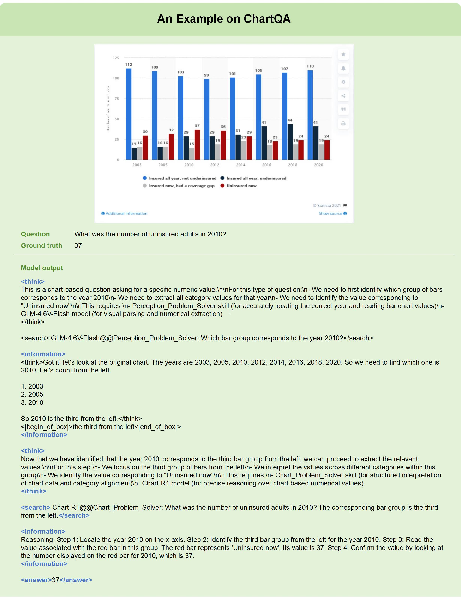
Figure 5: Orchestration on ChartQA—sequential skill invocation for robust chart element extraction and reasoning.
The orchestrator’s adaptive composition is further illustrated across datasets—medical imaging (Slake), high-resolution perception (VStar), object counting (TallyQA), and embodied scene QA (ERQA extension).

Figure 6: Orchestration in medical imaging—selecting MedGemma for perceptual judgment of a chest X-ray.
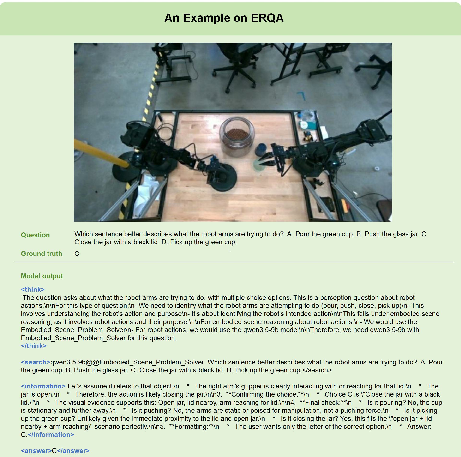
Figure 7: OOD generalization—Maestro selects Qwen3.5-9B and Embodied Scene Problem Solver for robot manipulation QA.
Skill Library Engineering and Scalability
Skill prompts are derived systematically from prior domain-specific methodologies (e.g., InterGPS for geometry, ChartQA for chart parsing), ensuring extensibility and minimizing overfit. Marginal engineering cost per skill is modest (3–5 person-hours); domain coverage is broad, with five default skills generalizing to extensive unseen tasks. Extended benchmarks validate registry expansion as beneficial, with new skills improving oracle and practical upper bounds.
Theoretical and Practical Implications
Maestro’s orchestration forms a scalable blueprint for agentic ecosystems, suggesting that performance and robustness gains can be achieved via intelligent strategic routing, not brute parameter scaling. Theoretical analysis underscores action-space compression, model-skill compatibility gains, and registry expansion guarantees for oracle upper bounds.
The architectural decoupling enables rapid integration of novel models and modular skills, allowing domain experts to enhance agents without retraining or architectural modifications. Practical deployment is supported by high efficiency—latency and inference cost remain minimal despite dynamic multi-model composition.
Future Directions
Automated skill discovery, online policy adaptation, multi-turn self-correction, extension to video/audio modalities, and formal analysis of orchestration sample complexity represent next steps. Integrating self-evolving skill registries with Maestro’s orchestration layer is a particularly promising avenue for robust, adaptive agent development.
Conclusion
Maestro establishes RL-driven orchestration as a high-leverage mechanism for coordinating model-skill ensembles in multimodal agentic systems. Comprehensive empirical and theoretical analysis confirms that outcome-based policy learning enables superior task success, domain generalization, and efficiency, outperforming both static mono-agent baselines and frontier proprietary models. The framework invites further research in scalable, modular, adaptive orchestrators as the agentic ecosystem evolves.

