- The paper presents an innovative framework using self-elicited multi-perspective reasoning with critic-guided revision for improved sarcasm detection.
- It employs dynamic role instantiation and trajectory flattening to integrate textual and visual cues into coherent analytical chains.
- Empirical results on multiple benchmark datasets demonstrate significant improvements in accuracy, recall, and interpretability compared to traditional methods.
ProCrit: Self-Elicited Multi-Perspective Reasoning with Critic-Guided Revision for Multimodal Sarcasm Detection
Introduction and Motivation
Multimodal sarcasm detection constitutes a complex cross-modal reasoning challenge, requiring the identification of nuanced incongruities between textual and visual cues that signal ironic intent. The inherent diversity of sarcasm mechanisms—verbal irony, hyperbole, pragmatic implicature, cultural references—necessitates flexible analytical strategies. Prevailing approaches deploy fixed, manually prescribed reasoning perspectives, often failing to accommodate sample-specific mechanisms and dynamic context dependencies. ProCrit reframes sarcasm detection as a self-elicited, multi-perspective reasoning process, leveraging dynamic role instantiation and external critique for adaptive, progressive analysis.
Process-Level Reasoning Annotation Synthesis
The lack of process-level supervision is addressed in ProCrit via a dynamic-role agentic rollout protocol. A robust vision-LLM sequentially spawns analytical roles, each conditioned on the aggregated history of prior analyses. These roles autonomously determine analytical perspectives required for each instance, yielding sample-adaptive, progressive reasoning trajectories. The full context of prior steps is visible at each analytic turn, ensuring logical dependencies among perspectives.
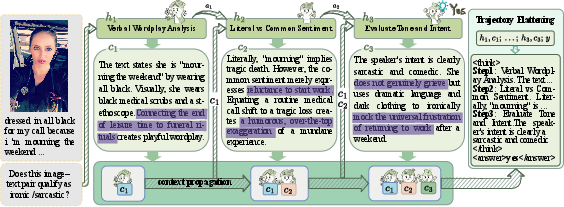
Figure 1: Illustration of the reasoning annotation synthesis process demonstrating sequential role spawn and reasoning trajectory flattening.
Trajectory flattening concatenates these multi-turn analytical steps into a single autoregressive sequence, allowing efficient training and inference while preserving implicit cross-perspective dependencies. Comparative analysis shows substantial improvements in reasoning expressivity relative to existing dataset annotations.

Figure 2: Comparison between existing dataset annotations and the process-level reasoning annotations synthesized by ProCrit.

Figure 3: Examples of reasoning trajectory synthesized through dynamic-role agentic rollout. Each analytical perspective is spawned sequentially within a shared context, progressively building a coherent multi-perspective analysis.
Proposal--Critic Framework and Draft–Critique–Revise Paradigm
ProCrit integrates two agents: a proposal agent and a critic agent. The proposal agent generates initial multi-perspective reasoning chains, leveraging process-level annotation supervision. Recognizing the limitations of intrinsic self-correction in large models, ProCrit introduces an independent critic agent that evaluates draft outputs, assigning calibrated quality scores and providing actionable, targeted natural-language feedback.
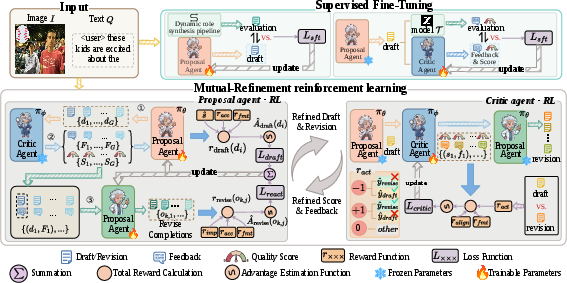
Figure 4: Overview of mutual-refinement training with alternating optimization of proposal and critic agents using revision outcomes and feedback as rewards.

Figure 5: Successful answer correction via critic-guided revision. The draft produces an incorrect sarcasm judgment due to flawed cross-modal reasoning. The critic pinpoints the reasoning deficiency and provides targeted feedback, enabling the proposal agent to generate a corrected reasoning from scratch.
The draft–critique–revise paradigm enables externally guided iterative refinement. The proposal agent, prompted with critic feedback, generates revised reasoning from scratch, thus allowing directed correction of analytical deficiencies and deeper exploration of cross-modal incongruity.

Figure 6: Reasoning quality improvement via critic feedback. The draft predicts the correct label but provides shallow, surface-level reasoning. After receiving the critic's feedback identifying analytical gaps, the revision produces a substantially deeper analysis that explicitly captures the cross-modal sarcastic mechanism.
Mutual-Refinement Training and Optimization
ProCrit deploys a dual-stage Group Relative Policy Optimization (GRPO) mechanism for joint training of proposal drafting and feedback-guided revision. During optimization, the critic agent is frozen, supplying scalar rewards (quality scores) and textual guidance. Proposal agent revision outcomes reciprocally inform the critic agent's reward calibration, grounding critic feedback in observed effectiveness.
Key reward functions include:
- Critic evaluation (normalized scores)
- Feedback actionability (successful correction of prior errors)
- Revision improvement (credit only for genuine answer fixes, penalization for harmful rewrites)
Alternating optimization ensures both agents are subject to outcome-driven refinement, avoiding co-adaptation instability.
Empirical Evaluation and Results
Evaluation on MMSD2.0, MMSD, and redEval benchmarks validates ProCrit's superiority in F1, accuracy, precision, and recall. Adaptive, self-elicited perspective generation consistently outperforms both plain chain-of-thought and fixed-perspective approaches. Critic-guided revision yields substantial gains in recall, indicating enhanced capability to capture subtle sarcastic signals missed in draft-only analysis.
The ablation studies rigorously isolate component contributions. Mutual-refinement RL stages, critic reward calibration, and revision reward weighting are all shown to be essential for optimal performance. The efficiency analysis demonstrates that even in draft-only mode, ProCrit achieves competitive results, making it practical for scenarios with inference cost constraints.
Implications and Future Directions
The formalization of self-elicited multi-perspective reasoning with external critique constitutes a compelling methodological advancement for complex multimodal tasks. ProCrit's agentic architecture decouples reasoning generation from evaluation, directly addressing reliability issues inherent in self-correction paradigms. The process-level annotation synthesis offers a scalable approach to supervision for tasks lacking structured datasets.
Practically, ProCrit's reasoning chains enhance transparency, facilitating interpretability and human oversight in sentiment analysis systems. Theoretically, mutual-refinement training introduces a framework for joint agent evolution grounded in outcome-based feedback, potentially generalizable to broader multi-agent reasoning domains.
Future work may explore expansion to multilingual settings, adaptation to other figurative language phenomena (e.g., metaphor, humor), and integration of richer context such as conversational history or interlocutor profiles for enhanced subjectivity modeling.
Conclusion
ProCrit presents a self-elicited, critic-guided multi-perspective reasoning framework for multimodal sarcasm detection, realizing dynamic perspective integration and outcome-grounded iterative refinement. Empirical results on standard benchmarks demonstrate its efficacy, with ablation analyses highlighting the criticality of mutual-refinement and external critique. The architecture advances both methodological rigor and practical interpretability, offering meaningful prospects for deployment and cross-modal reasoning research.

