- The paper introduces GRASP, which integrates explicit chain-of-thought reasoning to localize sarcastic triggers in both text and visual data.
- It leverages a balanced MSTI-MAX dataset and employs dual-stage supervised and RL-based optimization to enhance visual grounding and detection accuracy.
- Empirical results show significant improvements in AP metrics and F1-score over baselines, confirming the model's robust interpretability and generalizability.
GRASP: Grounded Chain-of-Thought Reasoning with Dual-Stage Optimization for Multimodal Sarcasm Target Identification
Multimodal Sarcasm Target Identification (MSTI) presents unique challenges in computational understanding of language and vision, advancing beyond coarse-grained binary sarcasm detection (MSD) towards the requirement for fine-grained localization of sarcastic triggers within multimodal data. This includes identifying precise textual spans and corresponding visual regions that ground sarcastic intent, as illustrated in Figure 1.
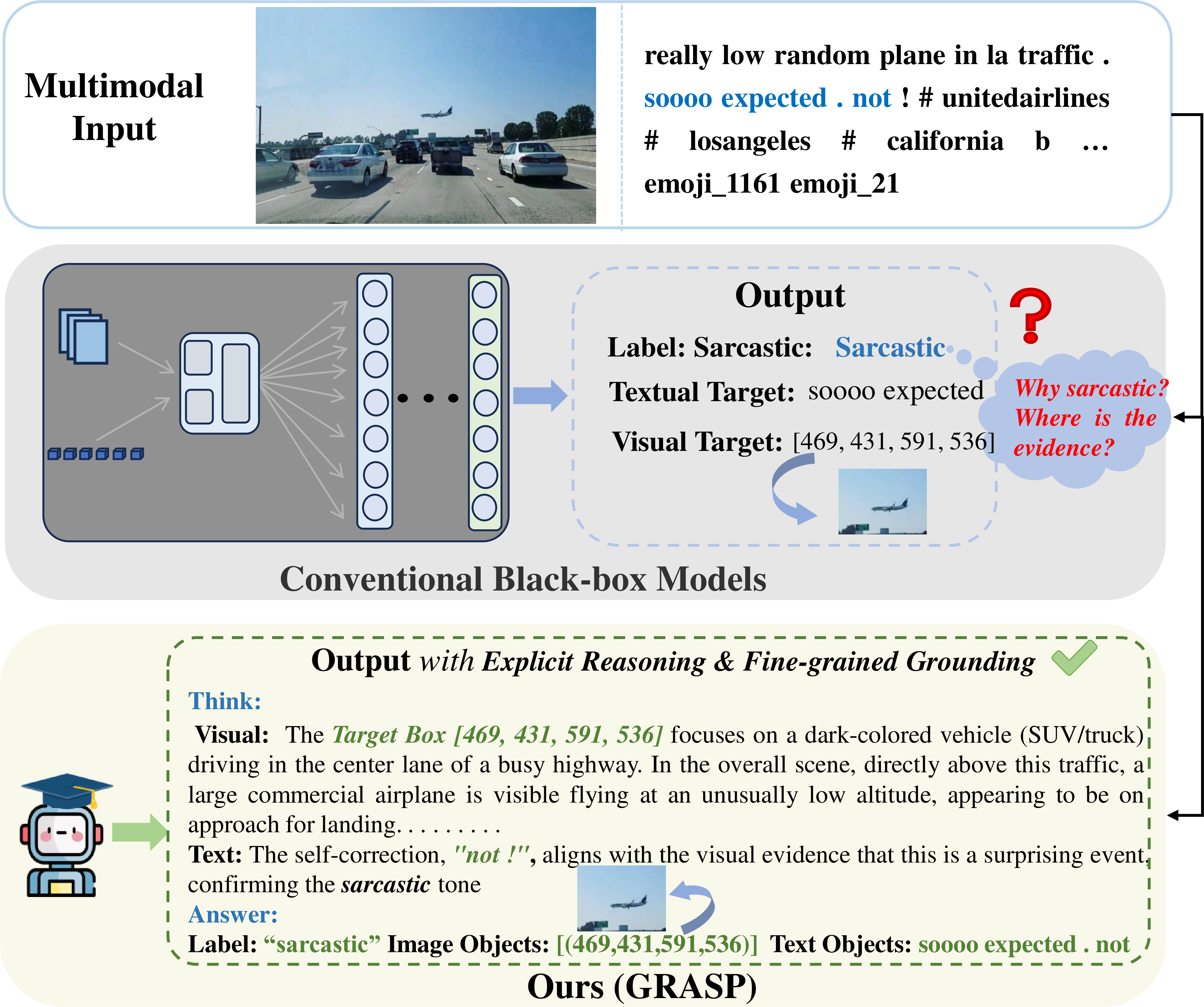
Figure 1: An illustrative example of MSTI, highlighting the grounding of sarcasm at specific textual and visual loci using the GRASP framework's explicit chain-of-thought reasoning.
Prior approaches either rely on task-specific architectures with implicit cross-modal alignment or employ large MLLMs as generic engines that compress visual information into textual proxies. Both fail to deliver interpretable reasoning paths or achieve optimal fine-grained localization. These limitations reflect the lack of explicit, human-readable rationales and poor robustness to data imbalance across sarcasm classes, as well as an inability to integrate visual specificity with abstract cognitive logic in a unified generative framework.
GRASP ("Grounded Chain-of-Thought ReAsoning with Dual-Stage Optimization for Multimodal Sarcasm Prediction and Target Identification") addresses these deficiencies with three central advances:
- Creation of the balanced, fine-grained, and explicitly annotated MSTI-MAX dataset;
- A multimodal chain-of-thought reasoning paradigm that grounds explicit visual targets within reasoning steps;
- A dual-stage supervised and policy-optimized training strategy that enforces both outcome correctness and robust reasoning structure.
The MSTI-MAX Dataset: Addressing Imbalance and Annotation Quality
MSTI-MAX reconstructs the foundational MSTI~2.0 dataset to resolve two critical issues: severe class imbalance (a realistic prevalence of non-sarcastic expression in the wild) and incomplete annotation of visual sarcasm targets. By augmenting non-sarcastic instances from large-scale MSD corpora and standardizing visual target annotation (bounding boxes in normalized coordinates), MSTI-MAX supports stable training and robust generalization.
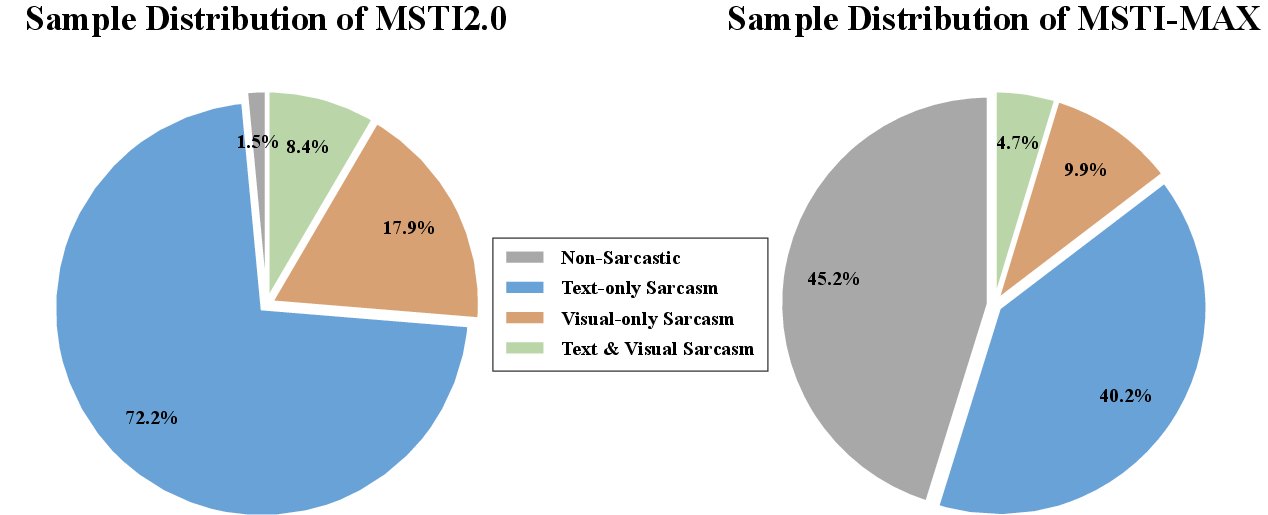
Figure 2: Modality distribution of sarcasm targets in MSTI-MAX and MSTI~2.0, demonstrating a richer distribution in MSTI-MAX across Text-only, Visual-only, and joint Text ↔ Visual targets.
MSTI-MAX provides a high-resolution mapping between sarcastic intent and its multimodal anchoring, critically enabling the development and benchmarking of interpretable MSTI models.
GRASP Framework: Grounded CoT Reasoning and Dual-Stage Optimization
Grounded Chain-of-Thought Reasoning
GRASP mandates a structured, two-stage reasoning output. The <Think> module guides the model through:
- Visual Description: localizing relevant objects via explicit bounding box coordinates,
- Textual Analysis: parsing semantic intent and emotional tone,
- Consistency Check: evaluating contradiction or reinforcement between modalities.
This is followed by an <Answer> module with explicit output: sarcasm label, localized keyword(s), and spatial coordinates of sarcasm triggers. By requiring explicit reference to image regions in the reasoning chain, GRASP directly operationalizes the "Thinking with Images" paradigm and preserves fine-grained spatial detail throughout the generative process.
Dual-Stage Outcome-supervised Joint Optimization
- Supervised Fine-Tuning (SFT): Utilizes high-quality instructor-generated chain-of-thought samples, optimizing all output tokens but assigning elevated loss weight to bounding box tokens. This prioritization enhances visual grounding over superficial textual pattern-matching, as confirmed by empirical hyperparameter sweeps.
- Fine-Grained Target Policy Optimization (FTPO): Builds on SFT initialization using outcome-supervised RL. Multidimensional rewards (output formatting, label correctness, visual grounding IoU, textual match, anti-redundancy penalty) are employed, facilitating learning of both structured reasoning and fine-grained localization. The approach is model-agnostic and does not require an external critic, instead leveraging group-based reward normalization for robust policy gradient estimation.
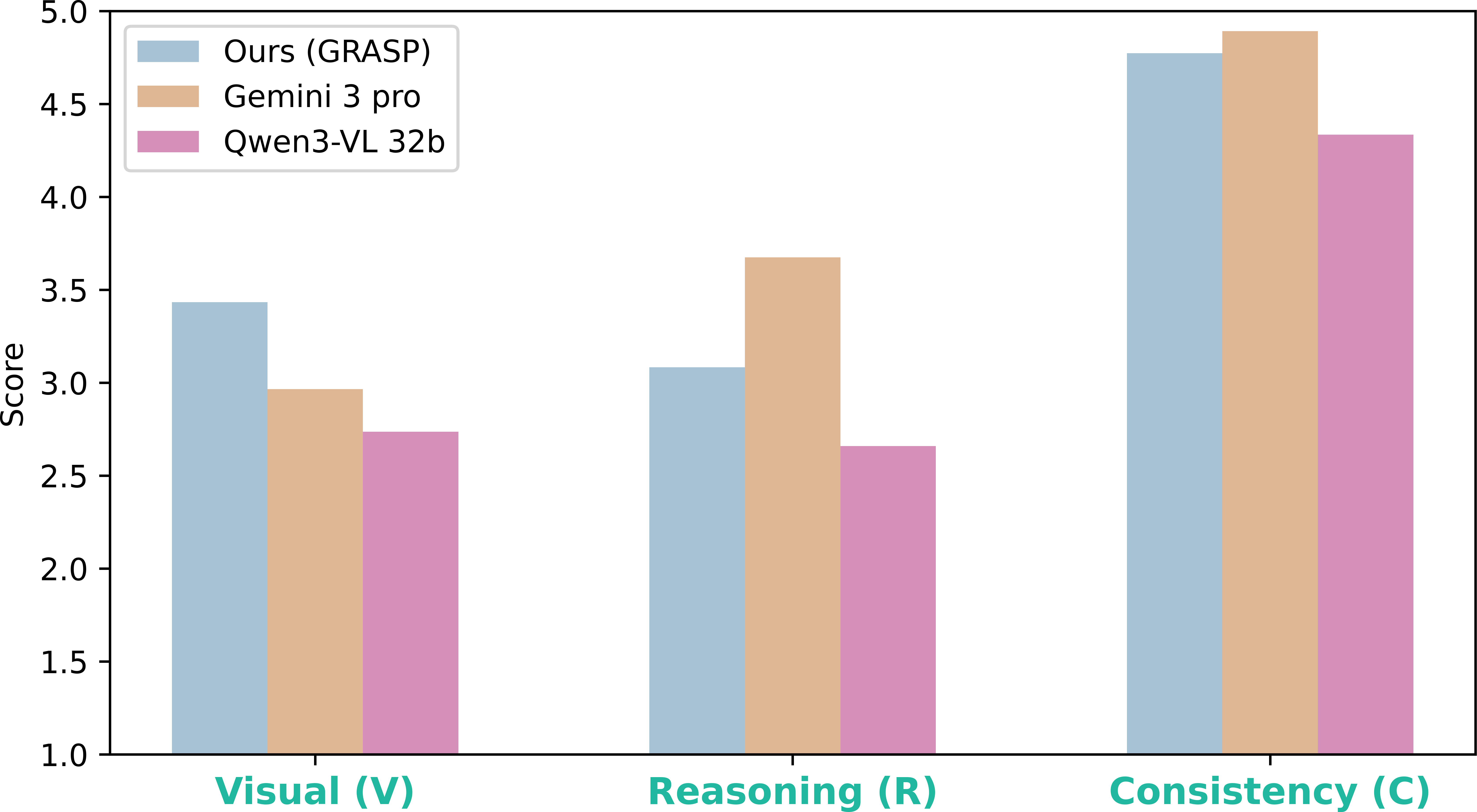
Figure 3: LLM-as-a-Judge evaluation results for reasoning quality, with higher values indicating superior visual grounding, reasoning, and logical consistency.
Experimental Results
GRASP is evaluated on MSTI-MAX and ablated/comparative settings. Strong numerical results are observed:
- Substantial improvement in visual target AP metrics, notably with Qwen3-VL-8B achieving AP of 46.71, AP50 of 51.30, and AP75 of 46.08, outperforming both zero-shot MLLMs (e.g., Gemini-3-Pro, Qwen3.5 series) and prior task-specific baselines.
- Sarcasm detection F1 also reaches or approaches the best observed values, indicating that the fine-grained optimization does not trade off coarse-grained decision accuracy.
- Ablation indicates that both SFT and FTPO are critical, and omitting either severely degrades performance, especially on fine-grained localization.
The importance of explicit chain-of-thought reasoning is further highlighted via LLM-as-a-Judge evaluation, which assesses reasoning outputs for visual-perceptual accuracy, logical consistency, and multimodal incongruity assessment. GRASP's outputs consistently achieve higher human-aligned reasoning scores than both generalist MLLMs and task-specific models.

Figure 4: Case study of GRASP demonstrating explicit visual-textual reasoning and target localization in a multimodal sarcasm instance.
Architectural Robustness and Generalizability
GRASP consistently demonstrates robust transfer to out-of-domain datasets (e.g., MMSD~2.0), exceeding the performance of baseline and LLM-based models without requiring task-specific retraining. Similarly, substituting different MLLM backbones (e.g., Qwen-VL, InternVL) results in comparable performance, confirming the architectural abstraction and adaptability of the framework.
Implications and Future Directions
GRASP establishes a technically and empirically validated paradigm for interpretable multimodal reasoning in fine-grained language-vision tasks. Its success in MSTI underscores three broader implications:
- Explicitly grounded, structured chain-of-thought reasoning enhances both interpretability and localization performance, breaking open the black-box nature of prevailing multimodal models.
- Dual-stage optimization incorporating per-component loss weighting and outcome-based RL methods is highly effective for tasks that conjoin structured output and grounded target prediction.
- Model-agnostic architectural principles allow GRASP to be extended to diverse MLLMs and new multimodal reasoning domains, potentially encompassing sarcasm explanation, irony detection in video, or counterfactual visual question answering.
Conclusion
GRASP demonstrates that the joint modeling of explicit visual-and-textual grounding within chain-of-thought reasoning, optimized via carefully staged supervision and reinforcement, yields superior and interpretable performance in multimodal sarcasm target identification. Future work may explore expanding context windows, compositional prompt engineering, and further refinements of reward design for broader multimodal reasoning applications.
References:
See (2604.08879) for the full technical report and supplementary materials.