World model inspired sarcasm reasoning with large language model agents
Abstract: Sarcasm understanding is a challenging problem in natural language processing, as it requires capturing the discrepancy between the surface meaning of an utterance and the speaker's intentions as well as the surrounding social context. Although recent advances in deep learning and LLMs have substantially improved performance, most existing approaches still rely on black-box predictions of a single model, making it difficult to structurally explain the cognitive factors underlying sarcasm. Moreover, while sarcasm often emerges as a mismatch between semantic evaluation and normative expectations or intentions, frameworks that explicitly decompose and model these components remain limited. In this work, we reformulate sarcasm understanding as a world model inspired reasoning process and propose World Model inspired SArcasm Reasoning (WM-SAR), which decomposes literal meaning, context, normative expectation, and intention into specialized LLM-based agents. The discrepancy between literal evaluation and normative expectation is explicitly quantified as a deterministic inconsistency score, and together with an intention score, these signals are integrated by a lightweight Logistic Regression model to infer the final sarcasm probability. This design leverages the reasoning capability of LLMs while maintaining an interpretable numerical decision structure. Experiments on representative sarcasm detection benchmarks show that WM-SAR consistently outperforms existing deep learning and LLM-based methods. Ablation studies and case analyses further demonstrate that integrating semantic inconsistency and intention reasoning is essential for effective sarcasm detection, achieving both strong performance and high interpretability.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to understand sarcasm in text. Sarcasm is when someone says something that sounds positive or straightforward, but they actually mean the opposite, often to be funny or critical. The authors build a system called WM-SAR that uses several small AI “helpers” working together to spot sarcasm and explain why, instead of relying on one big, mysterious model.
Key Questions and Goals
The paper tries to answer three simple questions:
- How can we break down the “thinking steps” humans use to recognize sarcasm (like reading the words, imagining the situation, and guessing the speaker’s intent) so a computer can follow them too?
- Can we measure the gap between what words say (literal meaning) and what most people would expect in that situation (norms) as a clear number?
- If we combine that gap with a guess about the speaker’s intentions, can we detect sarcasm more accurately and explain our decision?
Methods and Approach (in everyday terms)
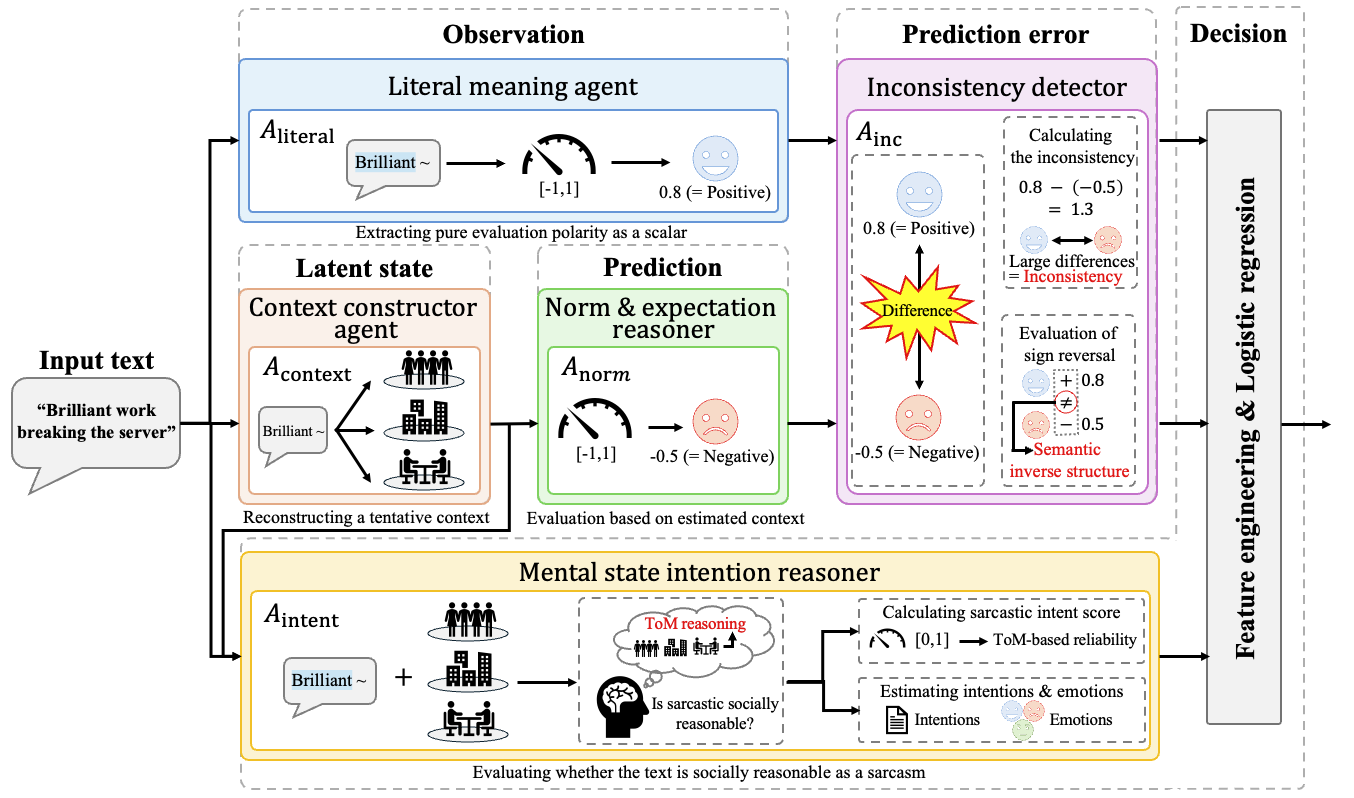
Think of WM-SAR as a small team of specialists, each doing one job, plus a referee that makes the final call. These specialists are LLM agents—smart text AIs—that each focus on one part of the problem. They run in parallel and produce both a simple number and a short explanation. Here’s the team:
- Literal Meaning Agent: Reads the sentence as-is and says if it sounds positive or negative on the surface. Example: “Great job” sounds positive.
- Context Constructor Agent: Imagines a likely situation behind the sentence. Example: Maybe the person said “Great job” right after someone made a mistake.
- Norm and Expectation Reasoner: Decides how most people would feel about that situation according to social norms. Example: If someone just messed up, the “normal” reaction would be negative.
- Inconsistency Detector: Calculates the difference between the literal meaning and the norm-based expectation as a number. Big difference means the words and expectations clash—often a sign of sarcasm. It also checks if the signs disagree (positive words vs negative situation).
- Intention Reasoner (Theory of Mind): Tries to guess the speaker’s intention and emotions, like annoyance or mockery, and outputs a score for “how sarcastic this likely is.”
Finally, a simple mathematical model called Logistic Regression acts like a referee. It takes the key numbers (the size of the inconsistency, whether there is a sign flip, and the sarcasm-intention score) and combines them to produce the final probability that the sentence is sarcastic. Logistic Regression is simple and transparent: it adds up the inputs with learned weights and uses a squashing function so the output is between 0 and 1 (like a confidence score).
This design is inspired by a “world model” idea:
- Observation: read the words (literal agent)
- Latent state: imagine the situation (context agent)
- Prediction: decide what should be expected (norm agent)
- Prediction error: measure the mismatch (inconsistency detector)
- Decision: use intention and numbers to decide sarcasm (intention + referee)
Main Findings and Why They Matter
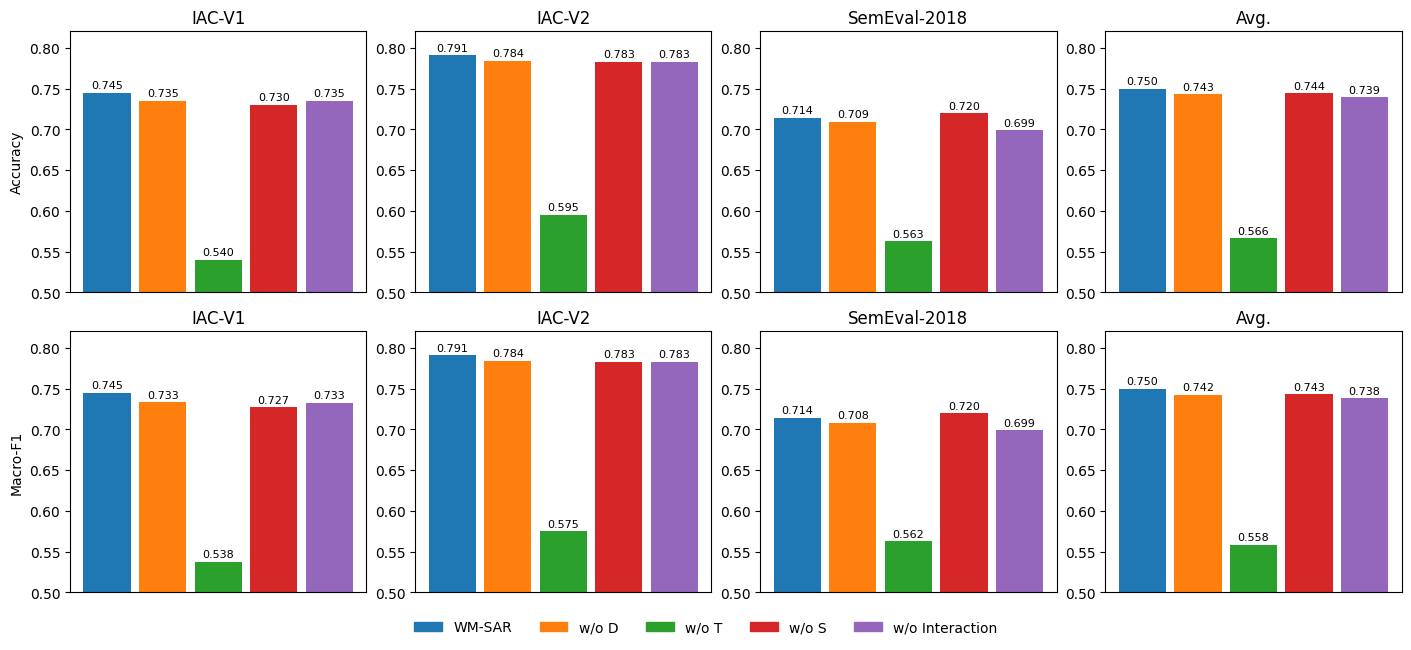
- WM-SAR performed better than several strong baselines on well-known sarcasm datasets (from political forums and Twitter). That includes classic deep learning models and modern LLM-based methods that rely on prompts or single-model reasoning.
- The most important factors were combining:
- The semantic inconsistency (words vs norms mismatch), and
- The speaker’s likely intention (are they trying to mock or criticize?)
- Because each agent outputs numbers and short explanations, the system is more interpretable. That means you can trace why a decision was made: Was it the words? The imagined situation? The expected reaction? The guessed intention?
This matters because sarcasm can confuse sentiment analysis, online moderation, and chatbots. A model that’s both accurate and explainable helps avoid misunderstandings and makes AI behavior easier to trust.
Implications and Impact
- Better sentiment analysis: Systems can avoid labeling “Nice going…” as genuinely positive when it’s clearly sarcastic in context.
- Smarter chatbots and virtual assistants: They can respond appropriately when users are being sarcastic, improving user experience.
- More transparent AI: By breaking decisions into clear steps with numbers and reasons, developers and users can understand and fix errors faster.
- A bridge to human-like reasoning: The multi-agent approach mirrors how people think—considering words, situations, social norms, and intentions—making AI more aligned with human communication.
In short, WM-SAR shows that splitting the job into understandable steps and combining them thoughtfully can make sarcasm detection both more accurate and more explainable, which is a big win for many real-world language applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed concretely so future researchers can act on them.
- Reproducibility of agent outputs: the paper does not provide exact prompts, scoring rubrics, sampling settings (e.g., temperature, top‑p), or seed control for mapping LLM judgments to the bounded scalars M_literal ∈ [−1,1], E_norm ∈ [−1,1], and T_sar ∈ [0,1]; precise prompt templates and parameterization are needed to replicate results and assess variance across runs.
- Stability and calibration of LLM-derived scalars: no analysis of inter-run variability, sensitivity to decoding parameters, or calibration quality of T_sar and the valence scores; quantify stability (e.g., via multiple stochastic runs), apply calibration methods, and report uncertainty intervals.
- Context hypothesis uncertainty: the Context Constructor outputs a single hypothesized context C(u) with no uncertainty quantification; evaluate multi-hypothesis contexts (e.g., n-best sampling), aggregate with weights, and assess how context uncertainty propagates to E_norm, D, and final decisions.
- Use of gold vs. hypothesized context: IAC datasets include thread/interaction context, but the framework relies on reconstructed context; compare performance when using available gold context versus LLM-constructed context to quantify the “cost of hypothesizing.”
- Cultural and demographic variability in “norm-based expectation”: E_norm is framed as a socially shared norm but may be culture-, community-, or demographic-specific; systematically evaluate across regions, cultures, or subcommunities, and consider incorporating annotated normative resources or controlled demographic slices.
- Assumption that valence inversion is a structural necessity: the framework presumes sarcasm hinges on sign disagreement between M_literal and E_norm; analyze datasets to measure how often sarcasm occurs without clear valence inversion (e.g., deadpan, rhetorical sarcasm, understatement), and extend the inconsistency formalism beyond sign-flip (e.g., expectation violation not limited to polarity).
- Disambiguating non-sarcastic incongruity: high |D| may also reflect humor, hyperbole, deception, or irony; introduce additional agents or features to differentiate these phenomena and conduct targeted error analyses on such cases.
- Faithfulness of natural-language rationales: agent rationales are retained but not validated; assess whether rationales faithfully reflect the numeric signals (e.g., via counterfactual tests, human judgments) and whether they improve error diagnosis.
- Validation of ToM reasoning and intention inference: T_sar is an LLM-generated “alignment score” without human-ground truth or reliability checks; collect human annotations for intention strength, compare to T_sar, and measure inter-annotator agreement.
- LR integration vs. alternative interpretable models: only logistic regression is explored; evaluate other interpretable integrators (e.g., generalized additive models, sparse linear models with interaction constraints) and compare coefficient stability, performance, and interpretability.
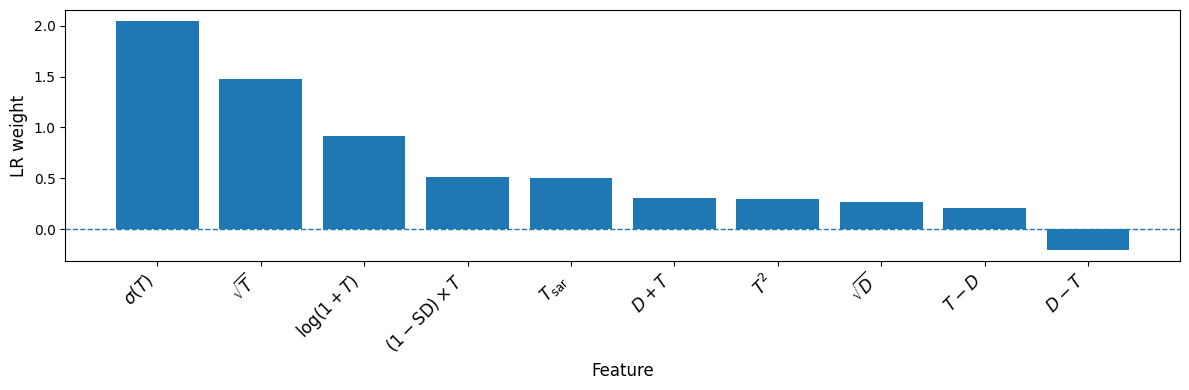
- Feature engineering sensitivity and overfitting risks: many engineered transformations (e.g., D×T, ratios, squares, logs) are introduced without sensitivity analyses; perform feature ablations, regularization sweeps, and report robustness to feature sets and standardization schemes.
- Threshold selection and probability calibration: the final decision threshold τ is tuned to maximize validation accuracy; assess calibration (e.g., ECE, Brier score), report AUROC/AUPRC, and analyze robustness of τ under dataset shift.
- Model scale and backbone dependence: all agents use GPT‑4.1‑mini; evaluate performance and cost across different LLM backbones (open-source and proprietary, varying sizes), and test whether gains persist with smaller models or instruction-tuned variants.
- Latency, cost, and deployment feasibility: no measurements of runtime, parallelization overhead, API costs, or throughput; benchmark inference latency and cost per example across datasets, and explore caching or amortization strategies.
- Robustness to social media phenomena: SemEval tweets often contain emojis, hashtags, sarcasm markers (e.g., “/s”), code‑switching, and creative orthography; test robustness to these phenomena and quantify improvements from explicit preprocessing or dedicated cues.
- Multilingual and cross-cultural generalization: the evaluation is limited to English; extend to multiple languages (including low-resource), analyze transferability of agents and norms, and address culture-specific sarcasm cues.
- Domain shift and out-of-distribution testing: the three datasets differ but remain within argument/tweet domains; conduct OOD evaluations (e.g., product reviews, forums, dialogue systems) to assess generalization and brittleness.
- Comparative use of conversation structure: sarcastic cues often rely on interlocutor dynamics; incorporate speaker/listener roles and dialogue turns where available, and measure whether role-aware context improves E_norm and T_sar.
- Formal psycholinguistic validation: the “world model” mapping is motivated conceptually but not empirically validated; design experiments comparing model signals (e.g., D) with human judgments of expectation violation or with psycholinguistic measures.
- Structured knowledge for norms: E_norm relies on the LLM’s internal knowledge; evaluate integration with external commonsense/normative resources (e.g., ConceptNet, ATOMIC, social science corpora) and test whether explicit knowledge improves consistency.
- Missing quantitative results and statistical significance: the provided text mentions superior performance but lacks complete metrics, variance, and significance tests; report full numbers, confidence intervals, and significance analyses for all baselines.
- Sensitivity to ε in the sign function: ε=0.05 is fixed without justification; perform sensitivity analyses to show how ε affects SD and downstream decisions across datasets.
- Data splits and comparability: the paper re-splits datasets (0.8/0.1/0.1) rather than using official splits/templates; assess how split strategies impact comparability to prior work and repeat experiments with official splits.
- Safety and fairness impacts: misclassification of sarcasm can carry moderation or reputational consequences; evaluate fairness across demographic groups, audit normative biases in E_norm, and consider safeguards for deployment contexts.
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented with today’s LLMs and lightweight model integration, leveraging WM-SAR’s modular signals (literal polarity, inferred context, norm-based expectation, inconsistency, intention score) and interpretable LR arbitration.
- Bold: Sarcasm‑aware social listening and sentiment analytics — sectors: Marketing, Media, Software
- Tools/products/workflows: API that augments existing social listening dashboards (e.g., Sprinklr, Brandwatch) with “semantic inversion” and “sarcasm intention” channels; brand “sarcasm index” KPIs; preflight check for ad copy to flag sarcasm risk before campaign launch.
- Dependencies/assumptions: Small domain calibration for LR threshold; cultural variation in norms; access to LLM inference; acceptable latency for batch/near‑real‑time pipelines.
- Bold: Customer support triage and chatbot escalation — sectors: Customer Experience, Contact Centers, Enterprise Software
- Tools/products/workflows: Middleware that flags tickets/chats with high inconsistency and high intention scores for escalation; Zendesk/Intercom plugin that routes sarcastic complaints to senior agents; bot guardrail that switches to empathetic/clarifying responses on sarcasm detection.
- Dependencies/assumptions: Data privacy and PII handling; domain adaptation (product jargon, slang); response latency constraints in live chat.
- Bold: Sarcasm‑aware content moderation and safety — sectors: Online Platforms, Trust & Safety, Policy
- Tools/products/workflows: Moderation pipeline that reduces false positives/negatives when toxicity is expressed sarcastically; review queues prioritized by inconsistency/intention scores; audit logs with LR coefficients and agent rationales to justify decisions.
- Dependencies/assumptions: Human‑in‑the‑loop review remains necessary; policy definitions of sarcasm in harmful contexts; threshold setting to meet precision/recall targets.
- Bold: Review analytics and NPS correction — sectors: Retail/e‑Commerce, App Stores, SaaS
- Tools/products/workflows: Batch analysis that re‑scores sentiment of sarcastically “positive” reviews; alerts for product teams when sarcasm spikes post‑release; integration into Voice‑of‑Customer (VoC) platforms.
- Dependencies/assumptions: Often minimal external context in reviews—relies on Context Agent hypotheses; light supervised calibration per product category.
- Bold: Workplace communication assistants — sectors: Enterprise Productivity, HR Tech
- Tools/products/workflows: Slack/Teams add‑on that warns “message likely sarcastic” or “reply may misread sarcasm”; tone coaching in email/comms editors; configurable to organization norms.
- Dependencies/assumptions: User consent and org policy; risk of over‑flagging; differing team cultures and in‑group humor.
- Bold: Market and compliance analytics on public forums — sectors: Finance (Research, Compliance), Media Intelligence
- Tools/products/workflows: Sentiment filters for WSB/FinTwit to avoid taking sarcastic hype at face value; compliance monitoring that flags sarcastic references to misconduct in chat logs.
- Dependencies/assumptions: Legal/ethical constraints on surveillance; slang/domain drift; do not use as sole trading signal.
- Bold: LLM red‑teaming and product QA — sectors: AI/ML, Software
- Tools/products/workflows: Test harness that injects sarcastic prompts/inputs and uses WM‑SAR to detect misinterpretations by assistants; failure triage by agent‑level signals; regression tests on sarcasm‑heavy datasets.
- Dependencies/assumptions: Access to internal eval pipelines; continuous updating as models evolve.
- Bold: Data annotation acceleration and quality control — sectors: Data Labeling, MLOps, Academia
- Tools/products/workflows: Pre‑annotation using inconsistency and intention scores; active learning that prioritizes items with high inconsistency but low intention agreement; annotator UIs showing agent rationales to improve consistency.
- Dependencies/assumptions: Clear guidelines for sarcasm vs irony/humor; annotator training; bias checks across cultures.
- Bold: Political and social discourse analytics — sectors: Think Tanks, Journalism, Civic Tech
- Tools/products/workflows: Tracking sarcastic rhetoric in debates or social campaigns; topic‑level dashboards showing norm/meaning inversions; narrative analysis of sarcasm targeting public policies.
- Dependencies/assumptions: Nonpartisan interpretation of norms; domain shift across events; careful presentation to avoid mischaracterization.
- Bold: Classroom and research demonstrators for pragmatics — sectors: Academia, EdTech
- Tools/products/workflows: Teaching modules showing world‑model‑inspired reasoning; ablation labs examining roles of inconsistency and intention; reproducible notebooks for sarcasm experiments.
- Dependencies/assumptions: LLM access; primarily English coverage; IRB considerations for student data if used.
Long‑Term Applications
These use cases are feasible but need further research, scaling, richer data, or productization—especially around multimodality, personalization, cross‑cultural norms, and strict reliability constraints.
- Bold: Multimodal sarcasm understanding (text + prosody + facial cues) — sectors: Media, HRI, Meetings/Collab
- Tools/products/workflows: Real‑time meeting assistants and call analytics combining WM‑SAR text signals with audio/video cues; creator tools that check sarcasm comprehension in video scripts.
- Dependencies/assumptions: High‑quality multimodal datasets; privacy/consent for AV data; efficient on‑device inference.
- Bold: Cross‑lingual and culturally adaptive norm modeling — sectors: Global Platforms, Localization
- Tools/products/workflows: “Culture packs” for the Norm Agent; region‑aware LR calibration; dashboards comparing sarcasm across locales.
- Dependencies/assumptions: Diverse labeled datasets per language/dialect; fairness and bias audits; continual updates as norms shift.
- Bold: Personalized norm and intention modeling — sectors: Enterprise, Social Apps, Collaboration
- Tools/products/workflows: Org/team/user‑level norm profiles that reduce false flags for in‑group banter; adaptive thresholds learned from feedback.
- Dependencies/assumptions: Strong privacy controls, opt‑in mechanisms; concept drift handling; safeguards against profiling/misuse.
- Bold: Sarcasm‑aware conversational AI and response planning — sectors: Customer Support, Assistant Platforms
- Tools/products/workflows: Dialogue managers that detect sarcasm and choose clarification, empathy, or escalation strategies; simulation frameworks to train bots against sarcastic users.
- Dependencies/assumptions: Safety policies for response generation; evaluation beyond accuracy (user satisfaction, harm reduction).
- Bold: Generalized world‑model pragmatics (irony, humor, deception, euphemism) — sectors: Security, Marketing, Education
- Tools/products/workflows: “Pragmatics Reasoning SDK” extending agent roles (e.g., truthfulness, intent to mislead); forensic tools for deceptive rhetoric analysis.
- Dependencies/assumptions: New ontologies and labels; careful ethical review; adversarial robustness.
- Bold: Real‑time, at‑scale moderation and routing — sectors: Social Platforms, Messaging
- Tools/products/workflows: Streaming inference with micro‑batching and distillation of agent prompts; edge deployment for low latency.
- Dependencies/assumptions: Cost controls; load shedding strategies; monitoring for performance regressions.
- Bold: Clinical and mental‑health communication support — sectors: Healthcare, Digital Health
- Tools/products/workflows: Detection of sarcastic cyberbullying for adolescent safety tools; clinician dashboards that flag sarcastic non‑adherence cues in patient messages.
- Dependencies/assumptions: Medical‑grade precision/recall; regulatory approvals; PHI security; rigorous bias and harm analysis.
- Bold: Regulatory auditing and AI transparency compliance — sectors: RegTech, Public Policy
- Tools/products/workflows: Standardized reporting of agent scores, LR coefficients, and rationale traces to meet transparency requirements (e.g., EU AI Act); third‑party audit toolkits.
- Dependencies/assumptions: Accepted standards for explainability; certification frameworks; governance for model updates.
- Bold: Education technology and digital citizenship — sectors: EdTech, K‑12/Higher Ed
- Tools/products/workflows: Writing assistants that coach tone and highlight unintended sarcasm; moderation of student forums with pedagogical feedback rather than punitive actions.
- Dependencies/assumptions: Age‑appropriate design; teacher oversight; cultural sensitivity.
- Bold: Sarcasm‑aware HRI and home robotics — sectors: Robotics, Smart Home
- Tools/products/workflows: Voice interfaces that avoid literal misinterpretation of sarcastic commands; fallback behaviors (ask‑to‑clarify) when inconsistency is high.
- Dependencies/assumptions: Robust speech sarcasm detection; on‑device models; safety validation in the loop.
- Bold: Retrieval‑augmented context grounding — sectors: Software Infrastructure, MLOps
- Tools/products/workflows: Replace/augment the Context Agent with RAG over prior messages, tickets, or knowledge bases to reduce hallucinated contexts; lineage tracking.
- Dependencies/assumptions: Secure data access; privacy and retention policies; dynamic retrieval quality.
- Bold: Benchmarking and standardization for interpretable sarcasm reasoning — sectors: Standards Bodies, Research Consortia
- Tools/products/workflows: Shared tasks with agent‑level labels and evaluation of interpretability (not just accuracy); diagnostic suites for cultural and domain robustness.
- Dependencies/assumptions: Community adoption; funding for dataset creation; legal clearance for data sharing.
Notes on overarching assumptions and dependencies across applications:
- WM‑SAR relies on access to capable LLMs for the agent roles; performance and cost depend on the chosen model and prompt engineering.
- Context estimation is hypothetical when external context is missing; adding retrieval or metadata improves reliability.
- Social norms are culturally contingent and evolve; domain/language adaptation and continuous evaluation are essential.
- Interpretability benefits (agent scores + LR) aid governance but do not eliminate the need for human oversight in sensitive settings.
- Many high‑stakes deployments require robust calibration, bias/fairness audits, and privacy/security controls.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- Ablation studies: Controlled experiments that remove or modify components of a model to measure their contribution. "Ablation studies and case analyses further demonstrate that integrating semantic inconsistency and intention reasoning is essential for effective sarcasm detection, achieving both strong performance and high interpretability."
- Auto CoT: An automated approach to generating chain-of-thought reasoning steps for LLMs. "along with extensions such as Auto CoT \cite{23}, Tree of Thought, and Graph of Thought \cite{24}, has shown that exploring multiple reasoning paths can improve contextual understanding."
- AutoGen: A framework for multi-agent LLM collaboration through structured interactions. "frameworks such as CAMEL and AutoGen \cite{28} attempt to imitate human like reasoning processes through role division and interactive communication among agents."
- Bagging of Cues (BoC): An ensemble-style prompting strategy that aggregates multiple cue-based reasoning outputs. "GPT-4.1-mini + BoC \cite{24}: An ensemble-style method that aggregates multiple cue-based reasoning outputs to make the final judgment through Bagging of Cues (BoC)."
- CAMEL: A multi-agent debate-based framework that improves reasoning diversity and robustness. "Studies have reported improved diversity and accuracy through debate based reasoning in CAMEL \cite{25}"
- Chain of Contradiction (CoC): A prompting strategy that guides step-by-step reasoning over contradictions within text. "GPT-4.1-mini + CoC \cite{24}: A method using a prompting strategy based on Chain of Contradiction (CoC) to conduct step-by-step reasoning over semantic contradictions in the utterance."
- Chain of Thought (CoT): A prompting technique that elicits intermediate reasoning steps in LLMs. "the introduction of intermediate reasoning through Chain of Thought (CoT) prompting \cite{22}"
- class imbalance: A distributional issue where one class has significantly fewer examples than another, affecting learning and evaluation. "class weights are balanced to address class imbalance."
- contrastive feature alignment: A training mechanism that encourages consistent representations across different conditions by contrasting positive/negative pairs. "a framework based on multi scale convolution and contrastive feature alignment was proposed to handle feature consistency under imbalanced data settings \cite{20}."
- DC-Net: A dual-channel deep learning architecture that models utterance-context relationships for sarcasm detection. "DC-Net \cite{35}: A deep learning model with a dual-channel architecture that explicitly models the interrelationship between an utterance and its context."
- deterministic inconsistency score: A numerically computed measure (not learned) of discrepancy between literal meaning and normative expectation. "The discrepancy between literal evaluation and normative expectation is explicitly quantified as a deterministic inconsistency score"
- dual branch architecture: A network design with two parallel pathways that process inputs separately before integration. "a dual branch architecture combined with evidential deep learning was introduced, demonstrating that discrepancy structures provide effective cues for sarcasm detection \cite{19}."
- evidential deep learning: A probabilistic learning approach that models prediction uncertainty by treating outputs as evidence. "a dual branch architecture combined with evidential deep learning was introduced"
- Generative Pre trained Transformer: A family of transformer-based generative models (e.g., GPT) pretrained on large corpora. "Generative Pre trained Transformer based models have been reported to achieve strong performance with minimal supervision \cite{21}."
- Graph of Cues (GoC): A prompting framework that structures multiple sarcasm cues into a graph for reasoning. "GPT-4.1-mini + GoC \cite{24}: A method that reasons by structuring multiple sarcasm cues and associating them through Graph of Cues (GoC)."
- Graph of Thought: A reasoning paradigm that explores and integrates multiple reasoning trajectories via graph structures. "Tree of Thought, and Graph of Thought \cite{24}, has shown that exploring multiple reasoning paths can improve contextual understanding."
- Inconsistency Detector: A module that computes the difference and sign disagreement between literal valence and norm-driven expectation. "The Inconsistency Detector computes, as a deterministic formula, the inconsistency between the observation $M_{\mathrm{literal}(u)$ output by the Literal Meaning Agent and the prediction $E_{\mathrm{norm}(C(u))$ output by the Norm and Expectation Reasoner."
- latent state inference: The process of constructing hidden contextual variables that explain an observed utterance. "This corresponds to latent state inference in the world model."
- Logistic Regression (LR): A simple probabilistic classifier that integrates interpretable features via a sigmoid of a linear combination. "these signals are integrated by a lightweight Logistic Regression model to infer the final sarcasm probability."
- macro-F1: An evaluation metric averaging F1 scores over classes, treating each class equally. "macro-F1 is used for tie-breaking when accuracy is identical."
- Mental State and Intention Reasoner: An agent that performs Theory of Mind reasoning to infer sarcastic intent and emotions. "The Mental State and Intention Reasoner performs ToM-based reasoning on the internal mental states of the speaker, including emotion estimation and pragmatic intention inference"
- Norm and Expectation Reasoner: An agent that estimates socially normative evaluations of inferred context. "The Norm and Expectation Reasoner infers how the situation represented by the context estimated by the Context Constructor Agent should normally be evaluated, in light of generally shared social norms."
- norm-driven expected valence: The scalar evaluation of a situation based on social norms, independent of the utterance’s surface sentiment. "This norm-driven expectation is represented as $E_{\mathrm{norm}(C(u)) \in [-1,1]."</li> <li><strong>prediction error</strong>: The discrepancy between observation and prediction; here, between literal valence and normative expectation. "observation $\rightarrow\rightarrow\rightarrow\rightarrow$ decision"</li> <li><strong>Pretrained LLMs (PLMs)</strong>: Large NLP models trained on broad corpora and adapted to specific tasks. "the development of Pretrained LLMs (PLMs) such as BERT and RoBERTa, as well as LLMs"</li> <li><strong>Sarcasm Arbiter</strong>: The final integrator that aggregates agent outputs to produce a sarcasm probability and label. "their outputs are aggregated by the final integrator, referred to as the Sarcasm Arbiter."</li> <li><strong>semantic inversion</strong>: A mismatch where surface (literal) sentiment contradicts the socially expected evaluation. "This study formulates sarcasm understanding as the detection of semantic inversion arising from world model inspired reasoning"</li> <li><strong>sign function</strong>: A function mapping a real value to +1, 0, or -1 based on thresholds (here with a neutral region). "The sign function $\operatorname{sgn}(\cdot)$ is defined to allow a neutral region as"</li> <li><strong>stratified K-fold cross-validation</strong>: A model selection procedure that preserves class proportions across K folds for robust evaluation. "Specifically, stratified $K$-fold cross-validation is conducted on train+val obtained by concatenating train and val"</li> <li><strong>Theory of Mind (ToM)</strong>: The capacity to infer others’ intentions, beliefs, and emotions; used for pragmatic reasoning. "as well as inferring the speaker’s intentions and emotions through Theory of Mind (ToM) \cite{5}."</li> <li><strong>Tree of Thought</strong>: A reasoning method that explores branching chains of thought rather than a single linear path. "Tree of Thought, and Graph of Thought \cite{24}, has shown that exploring multiple reasoning paths can improve contextual understanding."</li> <li><strong>valence</strong>: The polarity (positive/negative/neutral) of meaning or evaluation. "In psycholinguistics and pragmatics, sarcasm is characterized as an inversion between literal meaning and norm-based expectation. This notion is formalized in this study as ... denotes the semantic valence of the literal meaning of text $u$"</li> <li><strong>world model</strong>: A structured internal process that mirrors human perception: observation, latent inference, prediction, error, decision. "A world model reproduces the typical human perceptual process—observation $\rightarrow\rightarrow\rightarrow\rightarrow$ decision"
- world model inspired reasoning: Adapting the world-model computational structure to guide modular sarcasm understanding. "we reformulate sarcasm understanding as a world model inspired reasoning process"
- Zero shot: Performing a task without task-specific training examples, relying on pretrained knowledge and prompting. "More recently, zero shot sarcasm detection using LLMs has attracted attention"
Collections
Sign up for free to add this paper to one or more collections.