- The paper introduces LTC, which compresses tokens in intermediate layers to retain early query–document interactions while boosting efficiency.
- It demonstrates that applying compression at middle layers achieves significant throughput gains (up to 116% increase in QPS) with minimal nDCG@10 loss.
- The approach acts as a regularizer, ensuring robust generalization across different document lengths and out-of-domain datasets.
Introduction
Transformer-based cross-encoder rerankers deliver state-of-the-art performance in document and passage retrieval but remain computationally prohibitive for production environments due to quadratic self-attention complexity with respect to input sequence length. While input-level token compression has proven effective for bi-encoder architectures, transfer of these strategies to cross-encoder rerankers yields major effectiveness degradation, attributable to disruption of early query–document token interactions crucial for relevance modeling. The present work introduces Layer-wise Token Compression (LTC), in which adaptive token pooling is performed in intermediate transformer layers, maintaining fine-grained interaction in the lower stack while enabling significant acceleration in later layers.
Methodology: Layer-wise Token Compression
LTC operates by compressing token representations at a designated transformer layer ℓ∗, after early layers process the full input to capture fine-grained matching signals. The compression module C employs 1D adaptive average pooling, reducing the sequence length by a user-selectable rate r (i.e., retaining n′=⌊n⋅r⌋ tokens). Attention masks and position indices are subsequently adjusted to reflect the compressed sequence.
For listwise LLM rerankers, LTC distinguishes query and instruction tokens from the documents and applies compression selectively to document-token positions using a document mask, ensuring that cross-document token entanglement is avoided. The result is a framework compatible with both pointwise and listwise transform er-based reranking architectures.
Empirical Results: Pointwise Reranking
Comprehensive evaluation was performed using Qwen3-0.6B (28 layers) as a pointwise reranker trained on MS MARCO passage datasets. Effectiveness (nDCG@10) and inference throughput (queries per second, QPS) were monitored on the TREC Deep Learning 2019/2020 test sets.
Early-stage compression, particularly at the embedding or initial transformer layers, was found to dramatically degrade ranking performance. Aggressively compressing at layer 2 with r=0.2 resulted in nDCG@10 dropping from 0.727 to 0.638 on DL19—a statistically significant 12.2% decrease. In contrast, compression applied at intermediate layers (ℓ∗=8–$14$) with moderate rates (r=0.4–$0.8$) preserved effectiveness nearly indistinguishable from baseline while delivering significant speedups, e.g., 25% increase in QPS without measurable effectiveness loss.
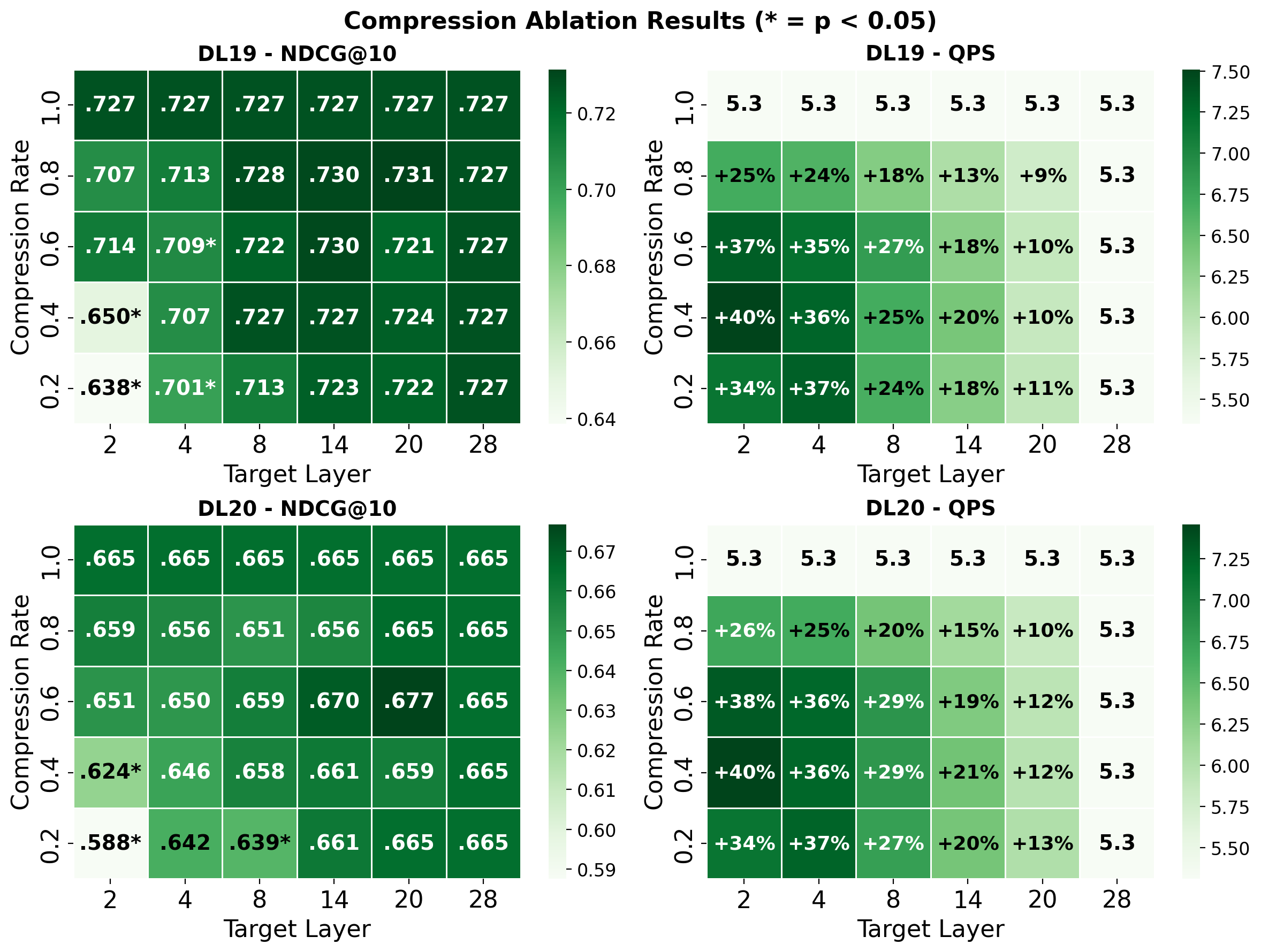
Figure 1: Passage ranking with LTC—nDCG@10 (left) and QPS (right) as a function of compression rate and target layer.
The embedding-layer Jasper approach (Zhang et al., 18 Nov 2025) achieves comparable QPS to LTC, but nDCG@10 loss is substantially higher (0.5832 vs. 0.727), supporting the hypothesis that token interactions captured in early layers are indispensable in cross-encoder architectures.
Application of LTC-trained Qwen3 models to document ranking (longer inputs, unseen during training) showed that compression not only improved QPS (by up to 116%) but also improved or maintained effectiveness compared to baseline, indicating strong robustness to input length and supporting the interpretation that LTC acts as a regularizer promoting length-invariant representations.
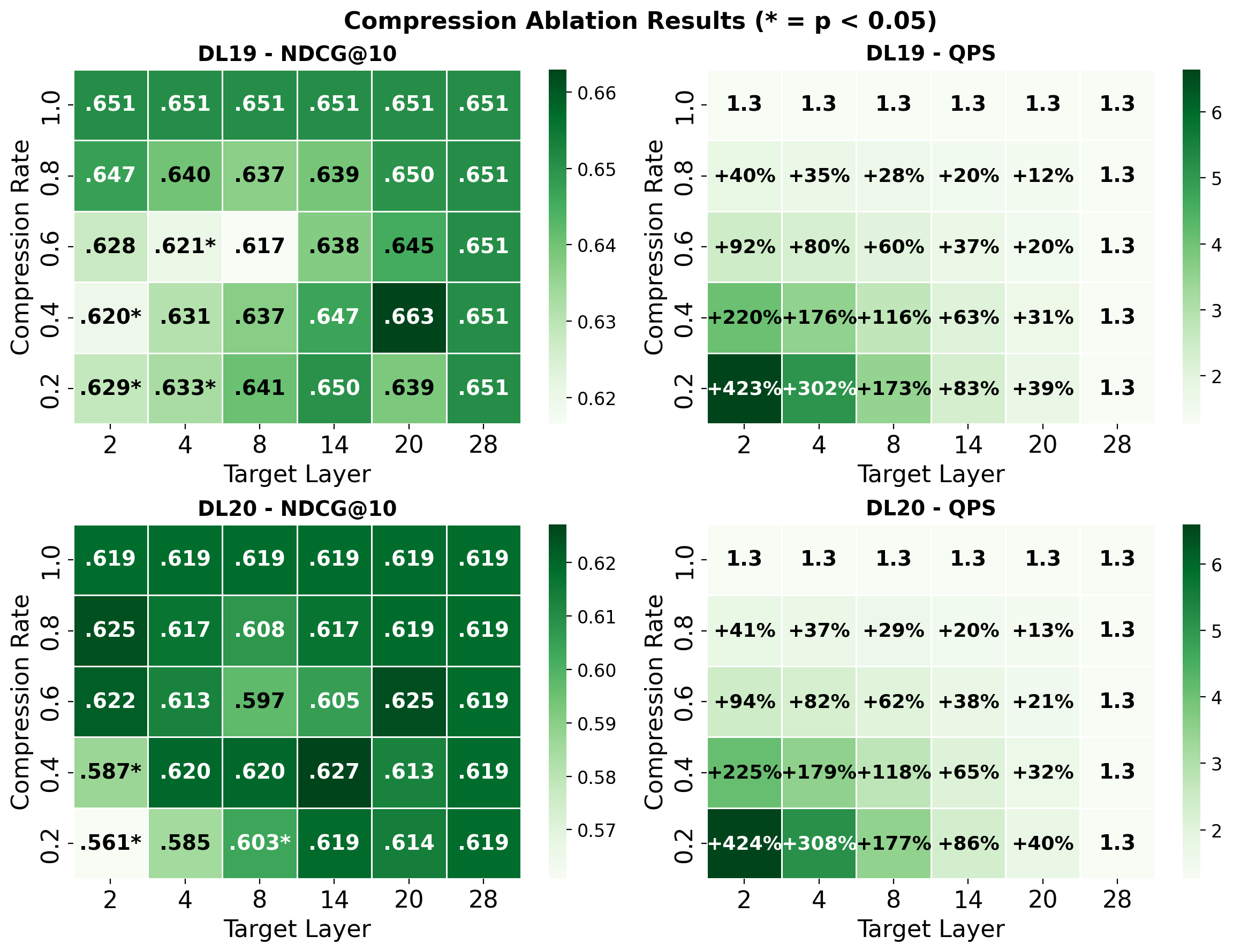
Figure 2: Document ranking performance and QPS for LTC-trained rerankers; middle-layer compression outperforms baseline for long-sequence inputs.
Ablation demonstrated that applying LTC compression only at inference, without compression-aware training, resulted in catastrophic performance degradation under aggressive configurations. Effective LTC therefore requires compression-aware finetuning to adapt model representations to token loss.
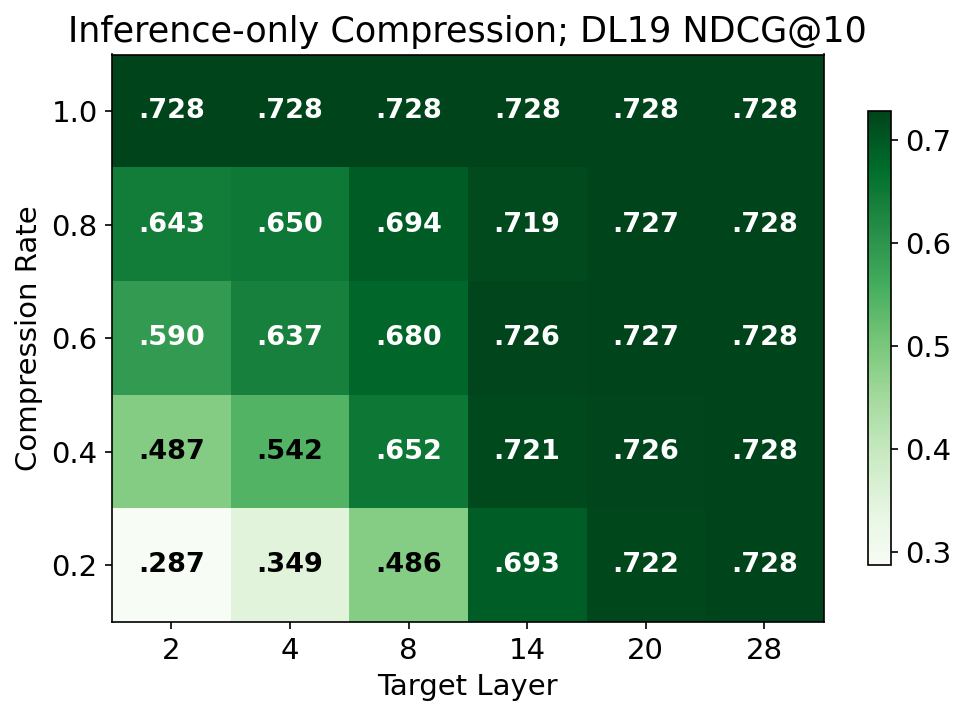
Figure 3: Zero-shot inference-only LTC yields severe breakdown in nDCG@10 versus LTC-aware trained models, especially for aggressive early-layer compression.
Zero-shot BEIR evaluation further indicated that LTC does not hinder out-of-domain generalization; in fact, mild compression slightly improved mean nDCG@10 across datasets such as NFCorpus, FiQA, and TREC-COVID, likely because regularization from compression counteracts overfitting.
Listwise Reranking with Large LMs
LTC was extended to listwise reranking with Mistral-7B-Instruct models. In this configuration, only document tokens are compressed, while instruction and query tokens remain unaltered. On MS MARCO passage and document ranking tasks, most LTC settings improved or preserved effectiveness with substantial throughput increases (+27% to +73% QPS), with several configurations delivering statistically significant nDCG@10 gains versus the baseline.
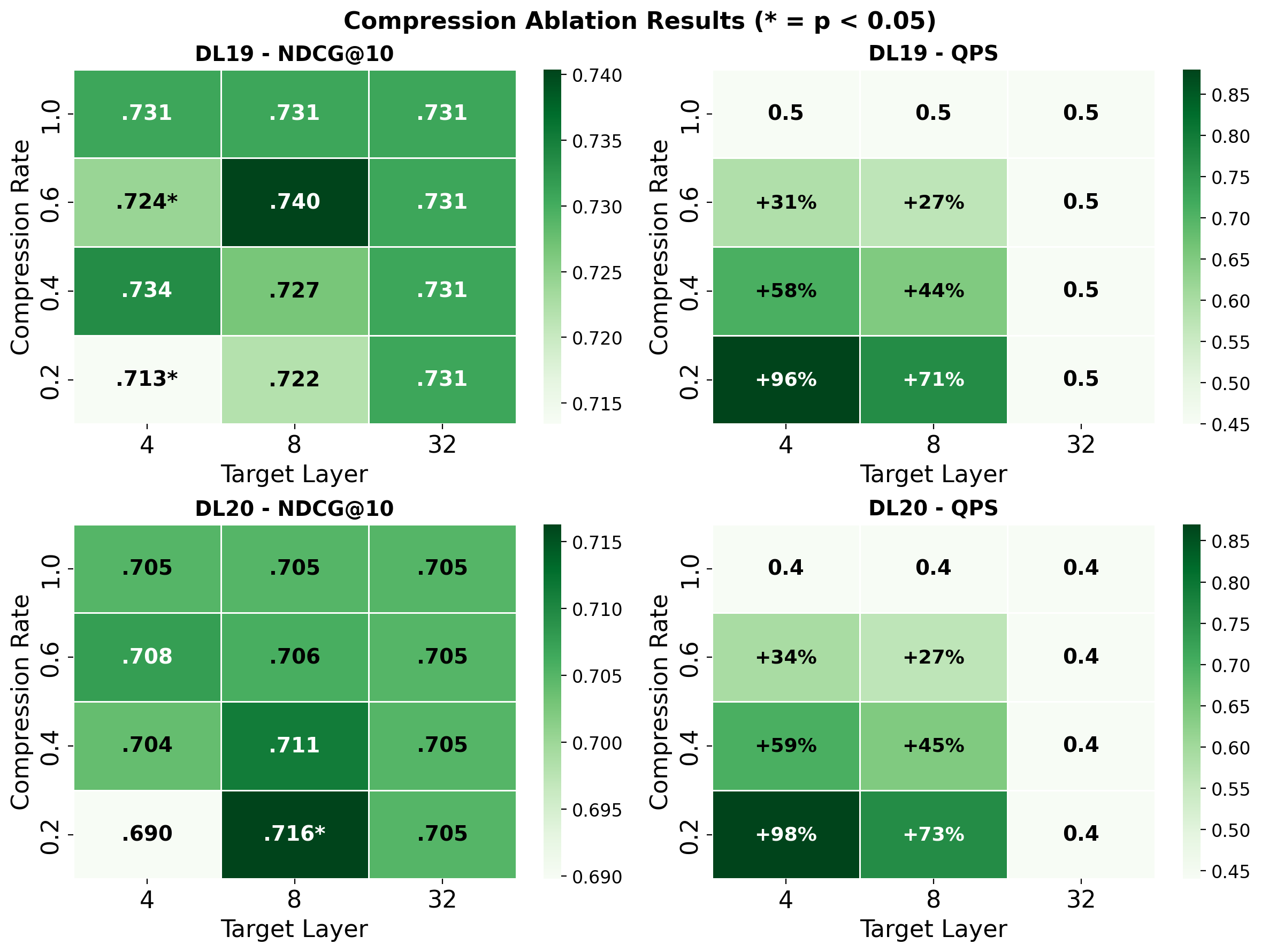
Figure 4: Listwise passage ranking: nDCG@10 (left) and QPS (right) as a function of LTC configuration; several compressed settings provide significant effectiveness and efficiency improvements.
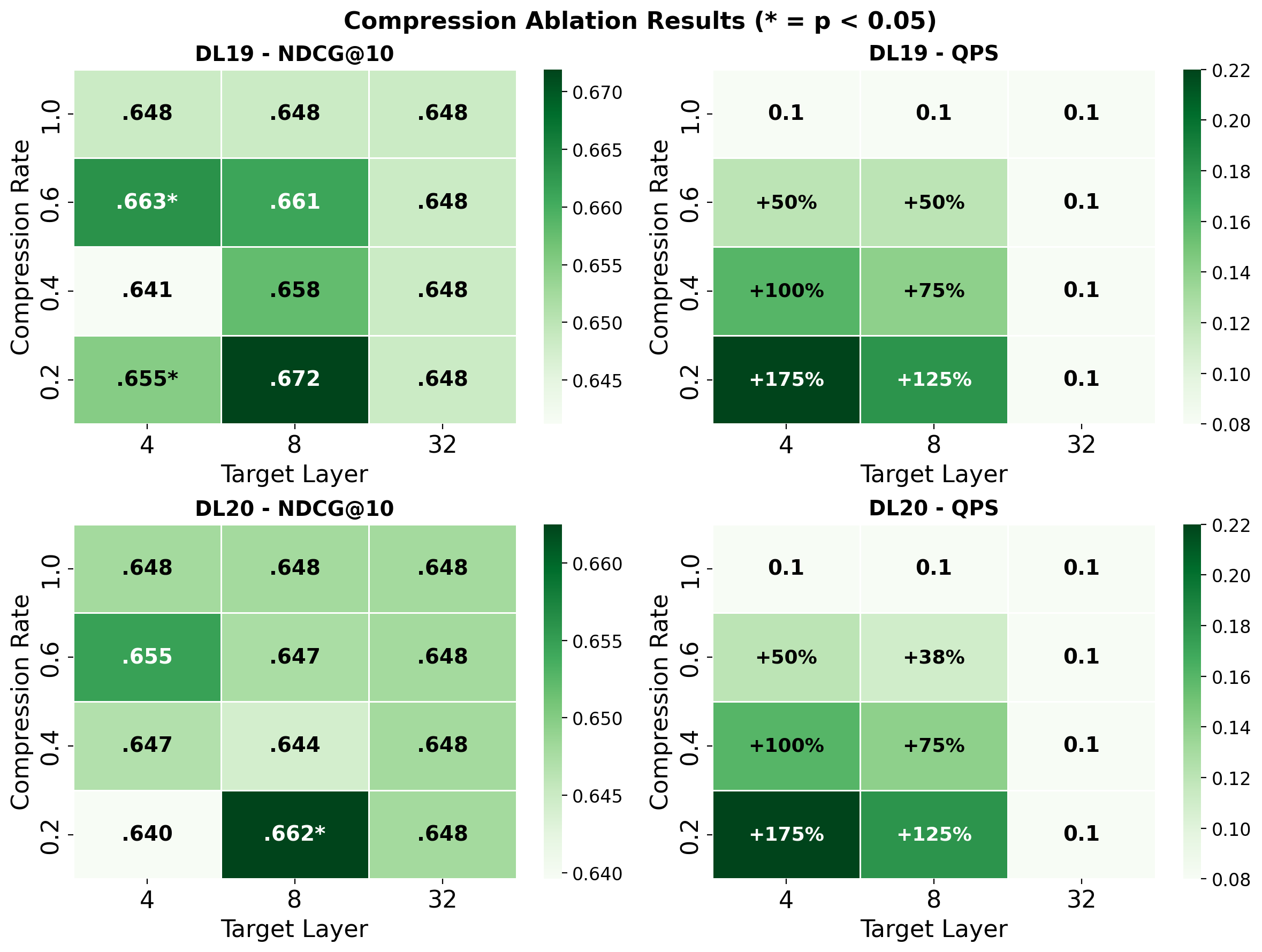
Figure 5: Listwise document ranking: effectiveness and QPS; selective LTC delivers throughput improvements up to nearly 2x with minimal or no effectiveness loss.
Implications and Future Directions
The LTC strategy demonstrates that efficiency/effectiveness trade-offs in transformer reranking can be reliably controlled by selecting appropriate compression rates and target layers. In production IR deployments—where model throughput remains critical—LTC provides a principled pathway to substantial cost reduction while preserving SOTA effectiveness, and supports robust generalization to longer documents and out-of-distribution datasets.
Theoretically, the result that LTC acts as a regularizer for robustness warrants deeper analysis. Future research directions include: (1) automating layer and rate selection (e.g., gradient-based or neural architecture search), (2) integrating LTC with orthogonal compression strategies such as quantization, KV cache compression, or prompt reduction, and (3) probing the representational invariances induced by LTC via attention and hidden norm analyses.
Conclusion
Layer-wise Token Compression (LTC) offers a robust and empirically validated approach for accelerating transformer-based reranking systems. By situating token pooling at intermediate transformer layers, LTC preserves necessary early token interactions and enables aggressive sequence length reduction for downstream blocks, producing up to 116% improvement in computational throughput without sacrificing retrieval effectiveness. LTC’s architectural generality allows immediate application to listwise reranking with large LMs, and the observed regularization effects support robustness under length variation and domain shift. Broad adoption of LTC across industrial and research retrieval stacks appears both practical and advantageous.
(2605.20683)