- The paper introduces an innovative dynamic truncation method that uses LLM-generated reference pivot documents to adaptively select candidate documents for reranking.
- It leverages PSI-Rank variants and listwise reranker innovations to reduce inference cost by up to 66% while maintaining state-of-the-art MAP and nDCG performance.
- The approach is model-agnostic, scalable, and demonstrates robust performance across diverse datasets and retrieval systems.
Dynamic Ranked List Truncation for LLM-based Reranking Using Reference-Document Pivots
Introduction
This paper introduces a framework for dynamic ranked list truncation (RLT) and efficient LLM-based reranking pipelines via synthetic, LLM-generated reference documents acting as semantic pivots. The work addresses major bottlenecks in modern multi-stage retrieval systems, particularly the efficiency constraints and context window limitations imposed by LLM-based rerankers. Conventional truncation methods rely on fixed cut-offs or global heuristics, which disregard query-specific relevance distributions and often result in suboptimal reranking effectiveness and efficiency. The authors propose leveraging LLMs to generate reference documents with controlled relevance levels, then exploiting these pivots for query-adaptive RLT and semantically informed listwise reranking strategies.
LLM-generated Reference-Document Pivots
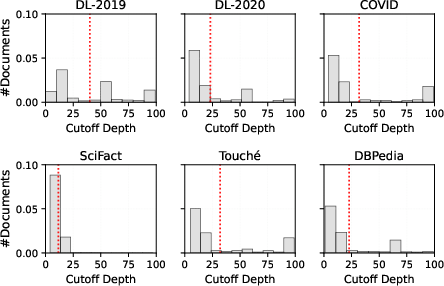
Central to the approach is the generation of a moderately relevant reference document, D∗, for each query Q (Figure 1). An LLM, prompted with an explicit relevance grade (e.g., "marginally relevant" on a 0–3 scale), generates a pivot document positioned at the relevance threshold separating positive and negative examples according to TREC scales. This reference serves as a semantic anchor in the ranked list: documents ranked above D∗ are prioritized for reranking, whereas those below are deprioritized or omitted, operationalizing a dynamic, content-sensitive cutoff.
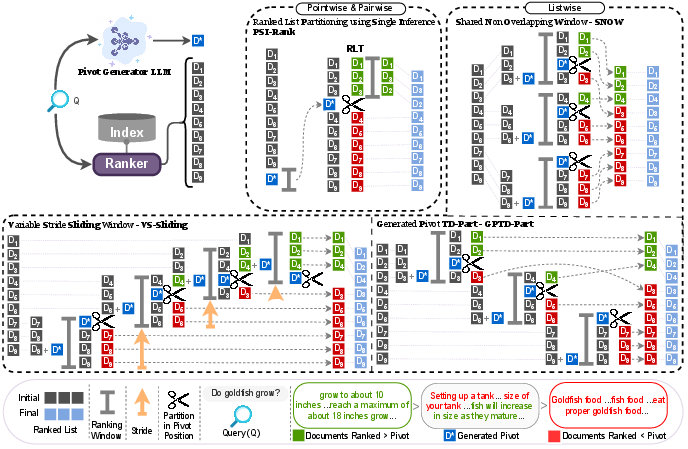
Figure 1: Workflow for generating a reference-document pivot D∗ for a query, used as a semantic anchor for reranking pipelines.
The generative prompt is carefully engineered to specify the information need and the required degree of relevance. The resulting D∗ is automatically validated using a strong LLM-based relevance estimator (UMBRELA), ensuring calibration at the targeted relevance threshold.
Dynamic RLT via PSI-Rank
The proposed PSI-Rank framework employs D∗ for efficient, query-adaptive truncation in reranking pipelines. Two variants are considered:
- Dynamic Cutoff (PSI-RankDyn): For each query, the first-stage retriever scores all candidates and D∗. All documents with scores exceeding that of D∗ constitute the truncated list for reranking.
- Average Cutoff (PSI-RankAvg): A calibration set is used to estimate the average pivot score, yielding a collection-wide static threshold that is less sensitive to outliers but sacrifices per-query adaptivity.
This approach is retriever- and reranker-agnostic, obviates the need for expensive training or hyperparameter tuning, and, critically, requires only a single additional inference per query for the pivot.
Pivot-guided Listwise Reranking
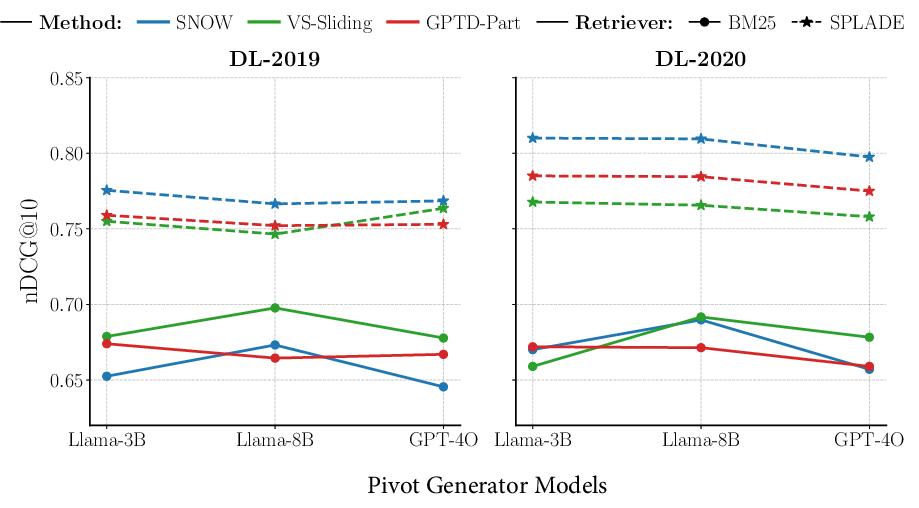
The authors extend the paradigm to listwise rerankers, which process batches/windows of candidate documents to accommodate LLM context restrictions. Three architectural innovations are introduced:
Experimental Evaluation
Comprehensive experiments are conducted on MS MARCO, TREC DL, and BEIR benchmarks, evaluating both in-domain and out-of-domain generalization. RLT and reranking pipelines are compared to recent supervised and unsupervised baselines (BiCut, AttnCut, Choppy, TD-Part) under multiple retrievers (BM25, SPLADE) and rerankers (mono-T5, duo-T5, RankZephyr, RankVicuna, RankGPT).
Key findings include:
Theoretical and Practical Implications
Semantically controlled, synthetic pivot documents enable new types of query- and context-sensitive adaptive truncation for both classic and LLM-based retrieval. This approach unifies and simplifies reranking pipeline design by allowing truncation and window partitioning decisions to be directly informed by generative models, rather than error-prone or inflexible heuristics. The minimal dependence on model size for pivot quality highlights the accessibility and scalability of this method in practical deployments.
On the theoretical side, this work empirically demonstrates that LLMs can generate documents which serve as effective, human-equivalent semantic boundaries—enabling downstream models to “anchor” their relevance judgments. This introduces a new controllable dimension to classic retrieval and modern listwise ranking algorithms.
Future Directions
Potential avenues for extension include joint optimization frameworks integrating generative pivot production with retrieval and reranking models, pivot-based hard negative mining for contrastive training, and adaptation to multi-modal or multi-lingual retrieval scenarios. The canonical LLM-based pivot could enable the automation of label smoothing, outlier rejection, and adaptive threshold calibration in a variety of ranking-centric NLP applications.
Conclusion
The methodology presented establishes LLM-generated semantic pivots as reliable, efficient, and model-agnostic anchors for dynamic ranked list truncation and listwise reranking. The approach achieves state-of-the-art effectiveness-efficiency trade-offs in multi-stage retrieval pipelines and demonstrates strong transferability across datasets, domains, retrievers, rerankers, and LLM architectures. This paradigm is immediately beneficial for practitioners seeking to deploy LLM rerankers at scale and opens new research avenues in adaptive retrieval and generative pipelines.