HRM-Text: Efficient Pretraining Beyond Scaling
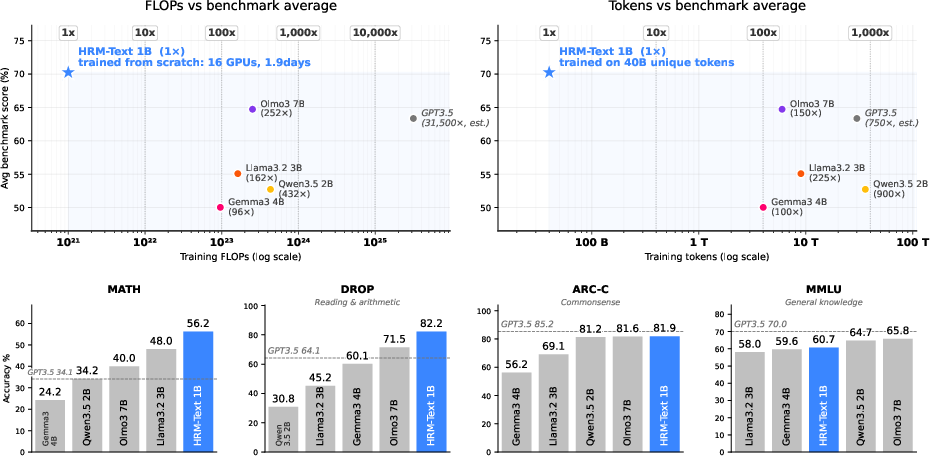
Abstract: The current pretraining paradigm for LLMs relies on massive compute and internet-scale raw text, creating a significant barrier to foundational research. In contrast, biological systems demonstrate highly sample-efficient learning through multi-timescale processing, such as the functional organization of the frontoparietal loop. Taking this as inspiration, we introduce HRM-Text, which replaces standard Transformers with a Hierarchical Recurrent Model (HRM) that decouples computation into slow-evolving strategic and fast-evolving execution layers. To stabilize this deep recurrence for language modeling, we introduce MagicNorm and warmup deep credit assignment. Furthermore, instead of standard raw-text pretraining, we train exclusively on instruction-response pairs using a task-completion objective and PrefixLM masking. Serving as an empirical existence proof of efficient pretraining, a 1B-parameter HRM-Text model trained from scratch on only 40 billion unique tokens and $1,500 budget achieves 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH. Despite utilizing roughly 100-900x fewer training tokens and 96-432x less estimated compute than standard baselines, HRM-Text performs competitively with 2-7B parameter open models. These results demonstrate that co-designing architectures and objectives can radically reduce the compute-to-performance ratio, making pretraining from scratch accessible to the broader research community.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces HRM-Text, a new way to train LLMs so they learn well from much less data and compute. Instead of copying today’s “just make it bigger and train on the whole internet” approach, the authors design an architecture and training setup that help the model “think” more efficiently—more like how people learn from fewer examples.
They show a 1-billion-parameter model (that’s small compared to many modern models) trained for about $1,500 on 40 billion tokens can perform similarly to larger models that usually need 100–900 times more data and 96–432 times more compute. The main message: smart design can beat brute force.
What questions the paper asks
Here’s what the researchers wanted to find out:
- Can a different model design help it “reason” more deeply without needing tons of data?
- If the model will answer questions at the end, can we train it directly on question→answer pairs (instead of predicting every single word in a giant text), and will that be more efficient?
- Can simple stabilizing tricks make a recurrent (looping) model practical for language tasks, where training can easily become unstable?
How they did it (in everyday terms)
The authors combine two big ideas: a new architecture and a new training goal.
Architecture: two-speed “thinking” (like coach and player)
- The model is built to think at two speeds:
- A slow “strategic” part (think: coach) that keeps the big picture in mind.
- A fast “execution” part (think: player) that works out the details step by step.
- These two parts talk to each other over several internal “cycles,” so the model can refine its thoughts before writing the next word. This is called a hierarchical recurrent model (HRM). “Recurrent” means it loops through its internal steps multiple times, gaining “depth” without growing huge.
Training objective: practice what you actually do
- In real use, we give models an instruction and want a response. So, instead of training on all raw text and predicting every token, they train only on instruction→response pairs and score the model only on the response part.
- They also use a masking trick called PrefixLM:
- The model can fully read and cross-reference the entire instruction (like reading the whole question carefully).
- It then writes the answer one token at a time (so it still learns to generate text properly).
- This is more efficient because the model focuses its learning where it matters: producing good answers, not reconstructing the prompt.
Keeping the model stable while it “thinks” deeply
Recurrent models can be hard to train: signals can blow up or fade away. The authors add two simple, helpful ideas:
- MagicNorm: Think of it as keeping the volume of signals “just right” at key points so the model stays stable through many internal steps. It balances being stable going forward and still letting learning signals flow backward.
- Warmup deep credit assignment: Early in training, they only “grade” the last few internal steps, then gradually grade more steps later. It’s like coaching: first give feedback on the final moves, then expand to earlier decisions once the player is steadier.
What they found (and why it matters)
The authors trained a 1B-parameter HRM-Text model from scratch on only 40B unique tokens, for about $1,500, and got competitive scores:
- MMLU: 60.7%
- ARC-Challenge: 81.9%
- DROP: 82.2%
- GSM8K (math word problems): 84.5%
- MATH (hard math): 56.2%
Why this is impressive:
- It matches or comes close to the performance of 2–7B parameter open models, despite using about 100–900× fewer training tokens and 96–432× less compute.
- It shows that co-designing the architecture (two-speed thinking) and the training goal (answer-only learning with PrefixLM) can massively improve efficiency.
- The model appears especially strong in reasoning tasks (like math and logic), which fits the design: it “thinks” internally before answering.
The authors also check that the model isn’t just memorizing benchmark answers by testing for “contamination” (overlap with training data). Results suggest the model’s scores aren’t mainly from memorization.
What this could change (implications)
- Lower barrier to entry: If you don’t need huge compute or the entire internet to get strong results, more researchers, students, and small labs can train capable models from scratch. That’s good for openness and innovation.
- Reasoning vs. knowledge: The model’s design favors careful thinking over massive fact memorization. In the future, we could pair a small “reasoning core” like HRM-Text with external knowledge tools (like retrieval or memory systems) to get the best of both worlds.
- Smarter compute use: Because the model does internal steps before answering, it might later use “adaptive computation” (stop early on easy questions, think more on hard ones) to save time during inference.
- Practical serving: The PrefixLM setup fits into common inference systems with small engineering tweaks, so this isn’t just a lab demo.
In short: This paper is a proof that “efficient pretraining beyond scaling” is possible. With a two-speed thinking model and an answer-focused training plan, you can get strong performance at a fraction of the usual cost.
Knowledge Gaps
Below is a consolidated list of the paper’s open questions, limitations, and knowledge gaps that warrant further investigation.
- Scaling beyond 1B parameters: establish whether HRM-Text’s data/compute efficiency and stability persist at larger scales (e.g., 3B–70B), with controlled token and FLOP budgets and explicit scaling laws.
- Inference-time efficiency: quantify latency, throughput (tokens/sec), and memory vs comparable Transformers; measure real-world serving costs (prefill/decoding) with and without recurrence.
- Adaptive computation time (ACT): implement token- and sequence-level halting for HRM-Text; study training procedures, stability, and compute–accuracy trade-offs under ACT.
- Long-context capability: evaluate and scale beyond 4k tokens; test long-range tasks (e.g., NarrativeQA, long-context QA/retrieval) to verify whether dual-timescale recurrence helps capture distant dependencies.
- Knowledge breadth vs reasoning: systematically map how knowledge-heavy benchmark performance (e.g., MMLU subsets) changes with more/less raw-text exposure; test mixed curricula (raw text + instruction) for HRM-Text.
- Retrieval/learned memory integration: add external retrieval (RAG/kNN-LM) or learned memory modules; compare end-to-end vs modular training; measure knowledge coverage, latency, and failure modes.
- Objective sensitivity: explore mixtures of P(x) and P(x_a|x_q), curriculum schedules, and response-only training without PrefixLM; identify objective schedules that maximize data efficiency and final quality.
- PrefixLM in multi-turn chat: formalize caching policies and attention masks for alternating user/assistant turns; evaluate correctness, memory growth, and performance under streaming and tool-augmented conversations.
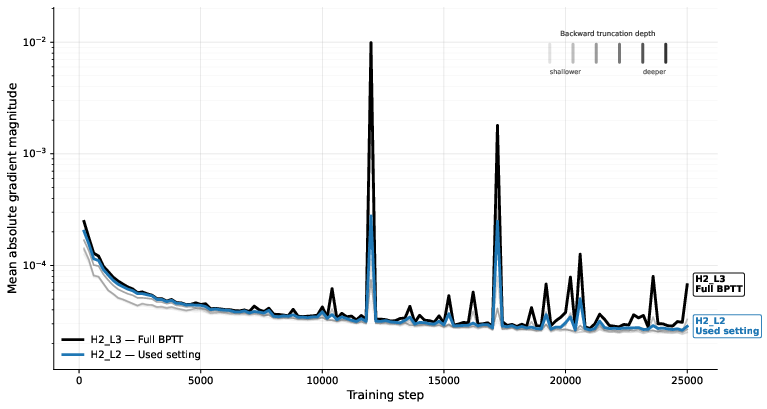
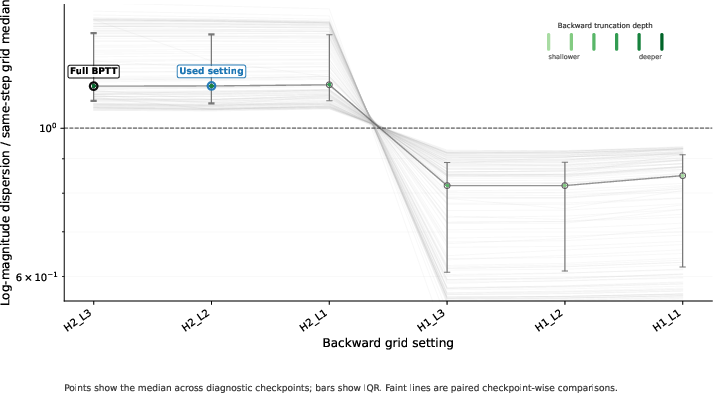
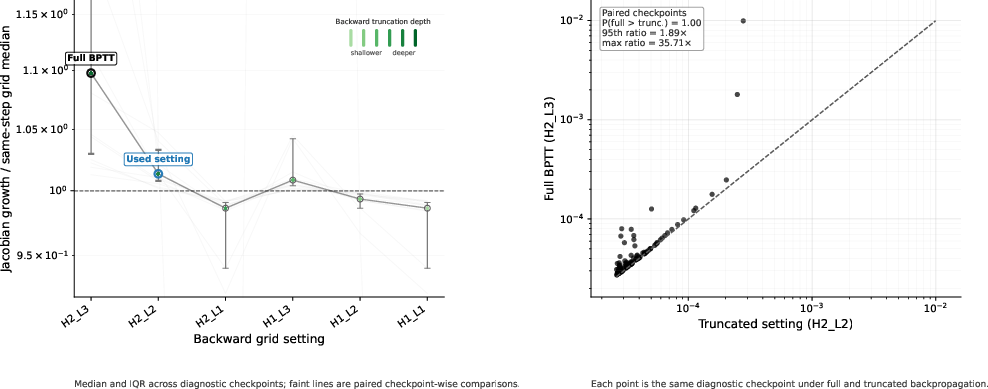
- Theoretical underpinnings of MagicNorm: provide formal stability analysis under TBPTT; characterize gradient dynamics vs PreNorm/PostNorm; establish sensitivity to recurrence depth N, backward horizon K, and internal block depth L.
- Warmup deep credit assignment design: study alternative schedules (nonlinear, adaptive per-layer/token, curriculum by sequence length); assess effects on convergence speed, stability, and final metrics.
- Component ablations: quantify the independent contributions of sigmoid-gated attention, parameterless RMSNorm, SwiGLU, and RoPE; compare against standard attention and normalization to isolate what’s essential.
- Recurrence configuration search: vary H/L state sizes, number of cycles, step ratios, and parameter sharing (TRM-style); map compute–accuracy frontiers and identify robust configurations across tasks.
- Robustness and OOD generalization: test on distribution shifts, adversarial prompts, calibration, and uncertainty estimation; evaluate sensitivity to prompt formats and instruction perturbations.
- Safety and bias: assess toxicity, harmfulness, demographic bias, and jailbreak resistance; determine compatibility of HRM-Text with alignment post-training (SFT/RLHF/RLAIF) and its stability impacts.
- Data mixture transparency and sensitivity: release full sampling manifests; study performance sensitivity to dataset caps/upsampling; evaluate stronger contamination detection (semantic/fuzzy matching) and its effect on reported gains.
- Chain-of-thought (CoT) handling: rigorously compare training with vs without CoT traces (beyond removing > spans); probe whether HRM develops latent internal reasoning without explicit CoT and how that interacts with the cot condition tag.
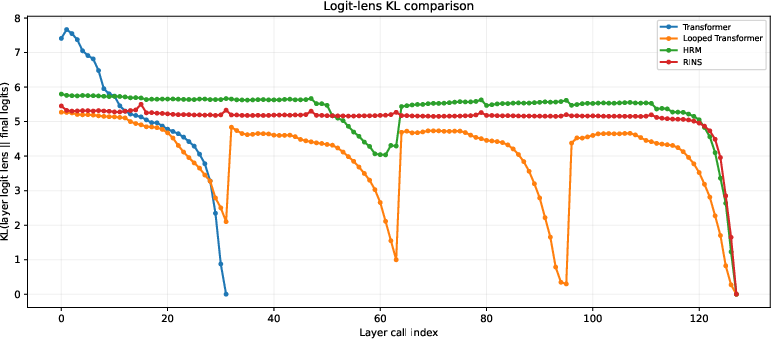
Effective depth causality: link representation-change and logit-lens metrics to task improvements with controlled comparisons (e.g., equally deep Transformers); rule out confounds from recurrence unrolling.
- Reproducibility and variance: report multi-seed results and confidence intervals; characterize training instabilities/failures (no gradient clipping), and sensitivity to optimizer settings and EMA.
- Compute and energy accounting: standardize FLOP/token and energy reporting; reconcile “unique tokens” vs total seen tokens; ensure fair comparisons with baselines differing in data quality and post-training.
- Coverage of domains/languages: evaluate code (HumanEval/MBPP), multilingual tasks, tool use, planning/agentic benchmarks; adapt tokenizer/vocab if needed and quantify domain transfer.
- Continual/online learning: test whether recurrent states or hierarchical design aid streaming learning and reduce catastrophic forgetting during further training or domain adaptation.
- Deployment constraints: profile VRAM usage, quantization tolerance, and compatibility with inference stacks (vLLM/TensorRT/TPU); evaluate accuracy–compression trade-offs for edge scenarios.
- Data-efficiency curves: produce performance vs tokens plots at 5B/10B/20B/40B unique tokens; locate diminishing returns and compute-optimal regimes for HRM under varying objectives.
- Generality of MagicNorm: test MagicNorm in non-recurrent Transformers and other modalities (vision/audio) to assess broader applicability and limits.
- Baseline comparability: replicate comparisons with baselines trained under matched instruction-only regimes and without mid-/post-training; control for data curation to isolate architectural vs data effects.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s tools and the open-source HRM-Text codebase, emphasizing reduced compute, lower cost, and practical integration paths.
- Sector: Software/AI Infrastructure — “Budget Pretraining” for SMEs and labs
- Use case: Train 0.5–1B parameter domain-specialized LLMs from scratch on 10–60B tokens for internal assistants (e.g., customer support, policy/QMS assistants) at sub-$2k budgets.
- Tools/workflows: HRM-Text repo; response-only (task-completion) objective + PrefixLM masking; stratified sampling pipeline; MagicNorm + warmup deep credit assignment schedule.
- Assumptions/dependencies: Access to a few high-end GPUs via cloud rental (or longer training on mid-tier GPUs); availability of instruction-response data; MLOps for monitoring and evaluation.
- Sector: Education — Low-cost math and reasoning tutors on modest hardware
- Use case: Deploy on-prem/offline tutoring services focused on GSM8K/MATH-like reasoning for schools or nonprofits without relying on cloud LLMs.
- Tools/workflows: Fine-tune HRM-Text on math/textbook exercises; use condition tags to control response style (direct vs. CoT) at generation.
- Assumptions/dependencies: Classroom-appropriate datasets; safety filters; local IT support for serving (e.g., vLLM) with PrefixLM-aware attention masks.
- Sector: Healthcare (non-clinical) — Privacy-preserving internal knowledge assistants
- Use case: On-prem assistants for policy navigation, documentation, scheduling, and administrative workflows in hospitals/clinics where PHI must not leave the premises.
- Tools/workflows: Fine-tune HRM-Text on internal SOPs and admin FAQs; serve with PrefixLM in standard inference frameworks (e.g., vLLM) with bidirectional instruction attention.
- Assumptions/dependencies: Strict data governance; not for diagnostic or clinical decision-making without validation; institution-specific evaluation and red-teaming.
- Sector: Finance (operations & compliance) — Cost-effective internal QA and summarization
- Use case: Internal policy/compliance Q&A, meeting minutes summarization, and audit trail generation using compact models that can run on on-prem GPUs.
- Tools/workflows: Fine-tune HRM-Text on policy documents and compliance checklists; response-only objective to focus learning on answer quality.
- Assumptions/dependencies: Human-in-the-loop review; audit logs; domain data; clear separation from regulated decision-making.
- Sector: Public Sector/NGOs — Localized assistants under limited compute budgets
- Use case: Build multilingual, domain-focused assistants for agencies, municipalities, or NGOs that lack access to massive compute.
- Tools/workflows: HRM-Text with stratified sampling to balance small multilingual instruction corpora; PrefixLM-based serving for interactive tasks.
- Assumptions/dependencies: Curated, de-biased multilingual instruction data; procurement policies permitting open-source stacks.
- Sector: Sustainability/ESG — “Green AI” procurement and reporting
- Use case: Prefer pretraining/fine-tuning methods with materially lower FLOPs and tokens; report energy savings and carbon footprints for AI initiatives.
- Tools/workflows: Track FLOPs/token budgets; adopt HRM-Text-style objective and architecture for reduced compute-to-performance ratio.
- Assumptions/dependencies: Agreement on measurement methodology; acceptance of smaller models for targeted tasks.
- Sector: AI Research & Academia — Democratized foundational model research
- Use case: Run from-scratch pretraining experiments in classrooms and small labs to explore new architectures/objectives without billion-dollar budgets.
- Tools/workflows: HRM-Text code; MagicNorm layers; warmup deep credit assignment; effective depth and logit-lens analyses; dataset contamination tests; SeqIO-style stratified sampling.
- Assumptions/dependencies: Modest compute grants or cloud credits; curriculum materials; reproducibility practices.
- Sector: AI Platforms — PrefixLM as a first-class training/serving mode
- Use case: Integrate PrefixLM response-only training into existing pipelines to improve efficiency for instruction-following models (even non-HRM).
- Tools/workflows: Modify attention masks for bidirectional instruction and causal response; add KV-cache logic for multi-turn chat.
- Assumptions/dependencies: Engineering changes to training and inference stacks; mask correctness and cache handling.
- Sector: Customer Support/Enterprise IT — Lean instruction-following chatbots
- Use case: Deploy compact chatbots for ticket triage, FAQ answering, and SOP guidance with lower hardware requirements.
- Tools/workflows: Fine-tune on support logs formatted as instruction-response; response-only objective to focus on solution generation.
- Assumptions/dependencies: Sufficiently representative internal data; escalation policies; security controls.
- Sector: Tooling for Model Training — Stabilized recurrent/looped training
- Use case: Adopt MagicNorm and warmup deep credit assignment to stabilize training of recurrent/looped architectures that otherwise suffer from gradient pathologies.
- Tools/workflows: Implement MagicNorm block (PreNorm blocks + final norm) and dynamic TBPTT horizon warmup (e.g., K=2→5).
- Assumptions/dependencies: Engineering comfort with custom layers/schedules; ablations to tune horizons for task/domain.
- Sector: Knowledge Management — Response-focused document assistants
- Use case: Build agents that emphasize answer quality over prompt reconstruction for SOPs, handbooks, and wikis.
- Tools/workflows: HRM-Text or existing models trained/fine-tuned with response-only loss and PrefixLM to better utilize the prompt context.
- Assumptions/dependencies: Clear instruction formatting; evaluation on answer accuracy/faithfulness; retrieval optional but helpful.
- Sector: Maker/Community Projects — Offline personal assistants
- Use case: Create DIY assistants for home/lab use (e.g., STEM helper, household how-to) running on a single GPU or powerful workstation.
- Tools/workflows: Prebuilt 1B checkpoint; quantization for inference; curated instruction sets; togglable output styles via condition tags.
- Assumptions/dependencies: Hardware availability; basic MLOps for serving; awareness of model limitations.
Long-Term Applications
The following opportunities require further research, engineering, scaling, or validation before broad deployment.
- Sector: AI Systems — Decoupling reasoning from knowledge via retrieval/memory
- Opportunity: Pair a compact recurrent reasoning core (HRM-Text) with retrieval-augmented stores or learned conditional memory (e.g., Engram-style) to cover broad factual knowledge without massive pretraining.
- Potential products: “Reasoning Core + Memory” architecture for enterprise QA; plug-in retrievers/memory modules.
- Assumptions/dependencies: Robust retrieval quality; memory training and eviction policies; latency management; alignment of reasoning with retrieved evidence.
- Sector: AI Infrastructure — Adaptive Computation Time (ACT) at inference
- Opportunity: Reduce inference cost by halting early on easy tokens/prompts while reserving full recurrence for hard cases.
- Potential products: ACT-enabled HRM serving engines; per-token compute budgeting.
- Assumptions/dependencies: Reliable confidence/halting signals; hardware scheduling support; stability under varying compute budgets.
- Sector: Robotics/Autonomy — Hierarchical planning and execution
- Opportunity: Adapt dual-timescale recurrence to map high-level planning (H) and low-level execution (L) in language-conditioned control and task planning.
- Potential products: Language-to-plan modules for household/warehouse robots; multi-timescale policy controllers.
- Assumptions/dependencies: Multimodal training (vision, proprioception); safety constraints; sim-to-real transfer.
- Sector: Healthcare — Validated clinical decision support
- Opportunity: Use compact reasoning models with medical retrieval/knowledge bases to support clinicians with explainable suggestions.
- Potential products: On-prem CDS copilots with rigorous audit trails, selective reasoning depth via ACT.
- Assumptions/dependencies: Regulatory approval (e.g., FDA), clinical trials, bias/safety mitigation, liability frameworks.
- Sector: Finance — Risk analysis and compliance automation with auditability
- Opportunity: Combine HRM-style reasoning with document retrieval to produce auditable, step-by-step analyses for risk/compliance tasks.
- Potential products: Explainable risk reviewers; automated policy conformance checkers with rationale.
- Assumptions/dependencies: Strong guardrails; adversarial testing; model governance and record-keeping; integration with GRC systems.
- Sector: Education — On-device, low-resource global tutoring
- Opportunity: Deliver multilingual, offline tutors on phones/tablets with adaptive compute and targeted curricula (math/science reasoning).
- Potential products: ACT-enabled mobile tutors with dynamic depth; teacher dashboards for oversight.
- Assumptions/dependencies: Efficient quantization; pedagogical validation; localization and accessibility; safety content filters.
- Sector: Software Engineering — Iterative planning/execution for code tasks
- Opportunity: Apply two-timescale reasoning to plan-then-execute code generation, debugging, and test synthesis with focused compute.
- Potential products: IDE copilots that allocate more recurrence to complex functions/tests.
- Assumptions/dependencies: Code/data availability; integration with build/test pipelines; security of generated code.
- Sector: Public Policy — Standards for efficient, equitable AI development
- Opportunity: Incentivize low-compute methods (like HRM-Text) in grants/procurement; establish “green AI” reporting and benchmarks.
- Potential products: Policy frameworks for energy-aware AI; public-sector mandates for efficient model selection when appropriate.
- Assumptions/dependencies: Consensus metrics for energy/FLOPs; alignment with performance and safety requirements.
- Sector: AI Platform Vendors — Native PrefixLM/response-only support
- Opportunity: Standardize PrefixLM objectives and KV-cache logic across training and inference engines for instruction-heavy workloads.
- Potential products: “PrefixLM mode” in vLLM/Transformers/TensorRT-LLM; turnkey response-only fine-tuning APIs.
- Assumptions/dependencies: Updates to libraries and serving stacks; interoperability testing; community adoption.
- Sector: Security & Privacy — Federated or on-prem from-scratch pretraining
- Opportunity: Train compact models on sensitive, siloed data across sites without aggregating raw text.
- Potential products: Federated HRM-Text training kits; secure aggregation pipelines.
- Assumptions/dependencies: Federated orchestration; privacy-preserving optimization; legal agreements.
- Sector: Benchmarking & Research — Scaling recurrent LMs beyond 1B
- Opportunity: Explore whether HRM gains persist at 3–7B+ scales and across diverse modalities.
- Potential products: Open checkpoints, benchmark suites for effective depth and stability; best-practice guides for MagicNorm/TBPTT warmup.
- Assumptions/dependencies: Larger compute budgets; architecture refinements; broader datasets and safety evaluations.
- Sector: Sustainability — Carbon-aware training schedulers
- Opportunity: Combine low-compute recipes with carbon-aware scheduling (train when grid is greener) for further emissions reduction.
- Potential products: MLOps tools that schedule HRM-style training based on real-time carbon intensity.
- Assumptions/dependencies: Access to carbon data feeds; flexible compute scheduling; organizational policy alignment.
Each application’s feasibility depends on the availability of high-quality instruction-response datasets, engineering support for PrefixLM masks and KV-cache logic, organizational tolerance for smaller models, domain-specific validation (especially in regulated sectors), and access to at least modest GPU resources or cloud credits.
Glossary
- Adaptive computation time (ACT): A mechanism that lets a model dynamically stop computation early on easy inputs and spend more steps on harder ones. "ACT would allow easy prompts or tokens to halt after fewer recurrent cycles while reserving the full recurrent budget for harder cases"
- Adam-atan2 optimizer: An Adam-style optimization algorithm variant that uses an atan2-based update rule (as cited), used to train the model. "We use the Adam-atan2 optimizer~#1{EXWANLGSKLP-2024} with , , and a weight decay of 0.1."
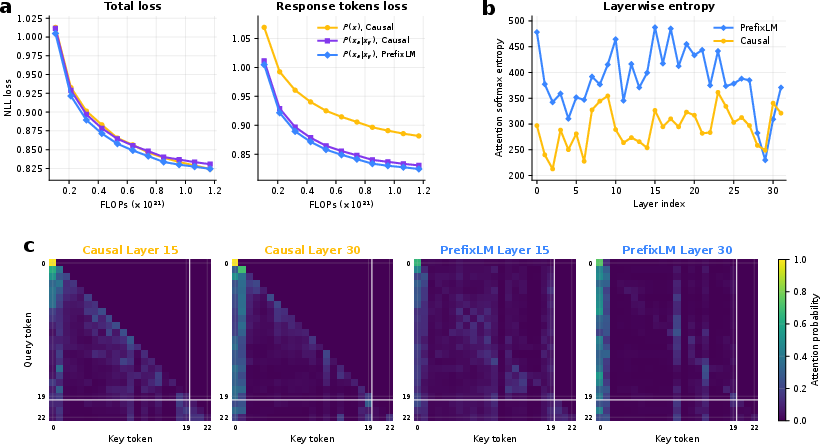
- Attention entropy: A measure of how spread out the attention distribution is; higher entropy suggests the model attends to a broader set of tokens. "PrefixLM increases layerwise attention entropy relative to causal masking, suggesting broader use of the prompt."
- bfloat16 precision: A 16-bit floating-point format with a wider exponent than FP16, often used to speed up training while preserving stability. "All models are trained in bfloat16 precision"
- Byte-Pair Encoding (BPE): A tokenization algorithm that builds a vocabulary by iteratively merging common symbol pairs. "We employ a Byte-Pair Encoding (BPE) tokenizer with a vocabulary size of 65,536"
- Causal masking: An attention mask that prevents a token from attending to future tokens, enforcing autoregressive generation. "while standard causal masking is maintained over the response sequence."
- Chain-of-thought (CoT): A prompting/training style where intermediate reasoning steps are generated alongside the final answer. "cot (chain-of-thought)"
- Compute-to-performance ratio: A metric describing how much performance is achieved per unit of compute; improving it means getting more capability for less compute. "co-designing architectures and objectives can radically reduce the compute-to-performance ratio"
- Conditional-memory: An approach where memory retrieval is conditionally triggered to supplement the model’s knowledge during inference. "Recent conditional-memory approaches such as Engram point in a related direction"
- Credit assignment: The process of determining which past computations or parameters were responsible for observed outcomes during learning, especially across time in recurrent setups. "where local traces can support delayed credit assignment"
- Dual-timescale recurrence: A recurrent architecture that separates fast, fine-grained updates from slower, more stable updates across steps. "featuring a dual-timescale recurrence"
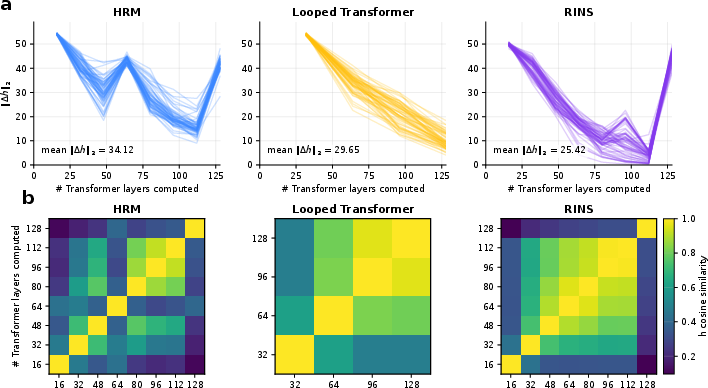
- Effective depth: The extent to which deeper layers or recurrent steps continue to make meaningful changes to representations and outputs. "whether HRM exhibits greater effective depth than standard and looped Transformer baselines."
- Engram: A referenced conditional-memory system that augments models with scalable memory lookup to complement neural computation. "Recent conditional-memory approaches such as Engram point in a related direction"
- Exponential Moving Average (EMA): A running average of model parameters that gives more weight to recent updates, often improving evaluation stability. "we maintain an Exponential Moving Average (EMA) of the model weights with a decay rate of 0.9999."
- Frontoparietal loop: A brain network implicated in planning and control; here it inspires a hierarchical, multi-timescale model design. "functional organization of the biological frontoparietal loop"
- Fully Sharded Data Parallel (FSDP2): A distributed training technique that shards model states across devices to scale large models efficiently. "The parallelization framework is based on PyTorch FSDP2"
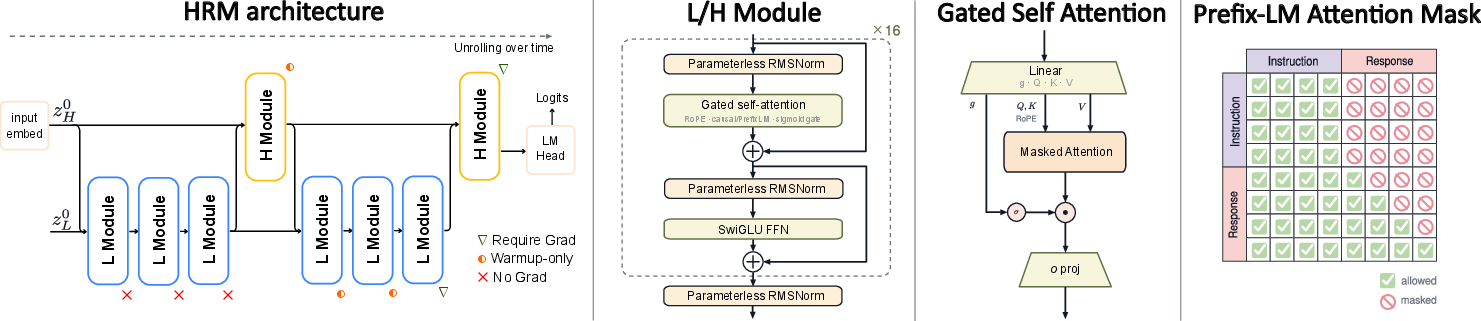
- Hierarchical Recurrent Model (HRM): The paper’s core architecture that separates slow “strategic” and fast “execution” recurrent modules. "we introduced the Hierarchical Recurrent Model (HRM), a dual-timescale architecture"
- Instruction–response pairs: A training format where each example is an instruction (prompt) and its corresponding response (answer). "we train exclusively on instruction-response pairs"
- Kullback–Leibler (KL) divergence: A measure of difference between probability distributions, used here to compare per-layer predictions to the final output distribution. "then compute the KL divergence between each probed prediction and the final model distribution."
- KV-cache: Cached key/value tensors used to speed up autoregressive decoding across tokens and turns. "Using a PrefixLM-style attention pattern in multi-turn chat also requires careful KV-cache logic"
- LeCun normal: A parameter initialization scheme designed to stabilize signal variance through layers. "All model weights are initialized using LeCun normal."
- Logit lens: An analysis technique that decodes intermediate hidden states with the output head to inspect how predictions evolve with depth. "we also use logit lens analysis"
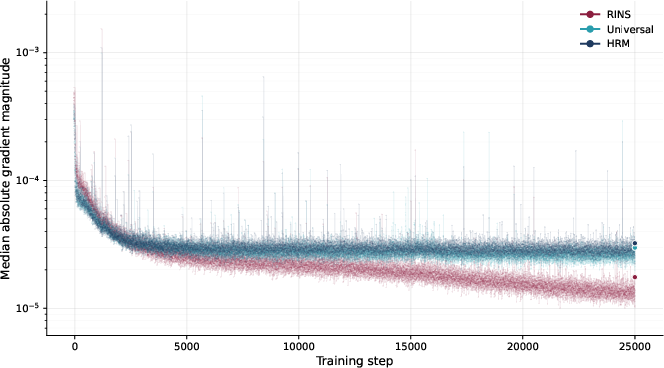
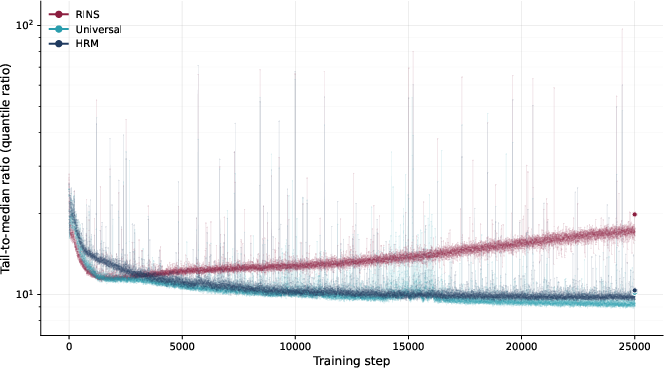
- Looped Transformers: Transformer variants that reuse (loop) layers or steps to increase computation without proportionally increasing parameters. "Looped Transformers and RINS generally outperform Transformer models of the same size"
- MagicNorm: A normalization scheme combining PreNorm blocks with an output norm per recurrent module to stabilize forward activations while keeping backward gradients healthy under truncated BPTT. "To stabilize this deep recurrence for language modeling, we introduce MagicNorm"
- Negative log-likelihood (NLL): A standard loss for probabilistic models; here computed only over response tokens conditioned on the instruction. "using a negative log-likelihood (NLL) loss computed exclusively over the response"
- PostNorm: A Transformer normalization placement where layer normalization is applied after the residual addition. "PostNorm \citep{vaswani2017attention} places the normalization outside the residual branch:"
- PrefixLM: A training/attention scheme where prefix (instruction) tokens attend bidirectionally, while the suffix (response) remains autoregressive. "We pair this with a PrefixLM attention mask"
- PreNorm: A Transformer normalization placement where layer normalization is applied before the sublayer transformation within the residual path. "PreNorm places the normalization inside the residual branch:"
- Recursive Inference Networks (RINS): A referenced recurrent/looped architecture baseline used for comparison in the paper. "Looped Transformers and RINS generally outperform Transformer models of the same size"
- Reinforcement learning with verifiable rewards (RLVR): A training paradigm that leverages verifiable signals to guide long chain-of-thought generation. "explicit long-CoT traces mostly produced by reinforcement learning with verifiable rewards (RLVR) training"
- RMSNorm: Root Mean Square Layer Normalization, a normalization layer that normalizes by RMS rather than variance; used here without a learnable scale. "parameterless RMSNorm (omitting the learnable parameter)"
- Rotary Position Embeddings (RoPE): A positional encoding technique that injects relative position information into attention via rotations. "Rotary Position Embeddings (RoPE)"
- Sigmoid-gated self-attention: An attention mechanism augmented with a sigmoid gate to modulate attention outputs. "a sigmoid-gated self-attention mechanism"
- Stratified sampling (SeqIO-style): A mixture-construction approach that samples examples stratified by dataset/task rather than uniformly from a pooled corpus. "We employ SeqIO-style stratified sampling"
- SwiGLU: A gated activation function variant that often improves transformer performance and stability. "SwiGLU activation functions"
- Temporal curriculum: A training strategy that increases the temporal span of backpropagation or dependencies over time to stabilize learning. "The schedule is motivated by temporal-curriculum principles"
- Truncated backpropagation through time (TBPTT): A training method for RNNs/recurrent models that limits the backward gradient horizon to a fixed number of steps. "induced by truncated backpropagation through time (TBPTT)."
- TRM: A variant of HRM that shares parameters between the slow and fast modules, used as a comparative baseline. "TRM is a HRM-variant that shares the H and L module parameters"
- Universal Transformers: A model that adds recurrence over layers to increase depth of computation with shared parameters. "Universal Transformers introduced recurrent depth to self-attention"
- vLLM: A high-throughput LLM inference engine/library for efficient serving with features like paged attention. "PrefixLM can run inside standard text-generation inference frameworks such as vLLM"
- Warmup deep credit assignment: A training schedule that gradually increases the number of recurrent steps included in backpropagation to stabilize optimization. "We employ a warmup deep credit assignment strategy: gradients are initially backpropagated through only the final two recurrent steps, expanding to the final five steps as training progresses."
Collections
Sign up for free to add this paper to one or more collections.

