- The paper introduces phase-aware quantization, decoupling aggressive NVFP4 prefilling from precise BF16 decoding to minimize error propagation.
- It achieves up to 3× speedup in the prefill stage while nearly preserving BF16-level accuracy in complex agentic workflows.
- The methodology underscores the benefits of tailored quantization strategies for efficient multi-turn LLM inference and encourages further hybrid precision research.
Mix-Quant: Phase-Aware Quantization for Efficient Agentic LLM Inference
The recent proliferation of agentic workflows leveraging LLMs for multi-turn planning, tool use, retrieval augmentation, and code execution has exposed critical bottlenecks in inference efficiency. In agentic frameworks, repeated prompt augmentation with tool outputs, retrieved documents, and internal memory causes the input context to balloon, making the prefilling, or context encoding, stage the dominant contributor to total computational workload. Figure 1 illustrates the profile of agentic workflows: while NVFP4 quantization offers high throughput, naively applying this format across both prefilling and decoding deteriorates model accuracy by compounding quantization errors throughout generation. The core insight of Mix-Quant is to decouple the quantization strategy between inference stages: exploit aggressive NVFP4 quantization for compute-heavy prefilling, while safeguarding decoding quality via BF16 precision.
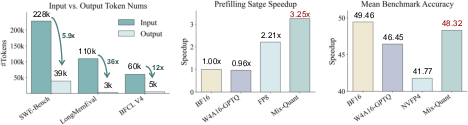
Figure 1: Agentic workflows are highly input-heavy, introducing substantial prefilling overhead. NVFP4 quantization can greatly accelerate computation, but applying it to both prefilling and decoding causes notable accuracy degradation. Mix-Quant instead uses NVFP4 for prefilling and precise BF16 for decoding, achieving substantial speedup while largely preserving agentic performance.
Methodology: Phase-Aware Quantization via Mix-Quant
Mix-Quant introduces a two-path execution model: (1) during prefilling, the model weights and activations are quantized using NVFP4—a 4-bit floating point format with fine-grained block-level scaling optimized for NVIDIA Blackwell architectures—resulting in efficient, parallelizable computation of the key-value cache; (2) during decoding, the model reverts to BF16 precision, ensuring autoregressive generation is resilient to quantization-induced error propagation. This phase-aware separation is directly operationalized in a disaggregated server deployment, with fast prefill workers generating KV caches in NVFP4 and decode workers consuming these caches and generating output in high precision.
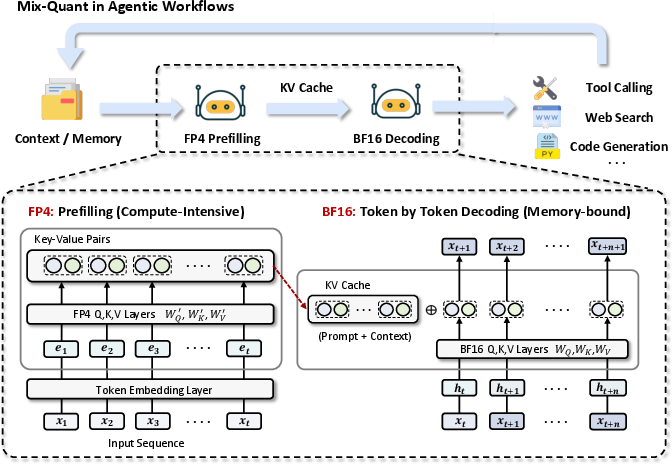
Figure 2: Overview of Mix-Quant for efficient agentic LLM inference: phase-aware quantization enables accelerated context prefilling (NVFP4) while maintaining high-quality decoding (BF16).
The rationale draws from distinct bottleneck analyses: in prefilling context, errors due to quantization do not recursively accumulate and attention mass is concentrated on a small subset of tokens, making the process robust to quantization noise. During decoding, however, errors propagate sequentially, and perturbing logits—even minutely—can irreversibly alter the agent trajectory, especially in tool-using or multi-step code-generation contexts. Extensive ablation confirms that quantizing only prefilling outperforms any uniform or decode-only quantization regime.
Experimental Results
Empirical evaluation spans long-context understanding (LongBench-V2, AA-LCR) and agentic function-calling, interactive memory, and stateful dialogue (BFCL v4, LongMemEval, τ²-bench) benchmarks across strong open-weight models (Qwen3, Qwen3.5, and Gemma-4). Uniform NVFP4 quantization consistently hurts downstream agentic performance, with degradation reaching up to 10–15% on representative models and tasks. In contrast, Mix-Quant delivers nearly full preservation of BF16-level accuracy, sometimes within 0.5% of baseline, even on challenging agentic evaluations. Notably, the efficacy of phase-aware quantization extends to mathematical reasoning and complex long-context synthesis.
Crucially, Mix-Quant achieves up to 3× end-to-end speedup in prefill latency over the BF16 baseline, as shown in Figure 3. This acceleration is robust across prompt lengths and batch sizes. The system maintains performance scalability due to hardware-efficient NVFP4 kernels and minimal overhead in mixed-precision path handoff.
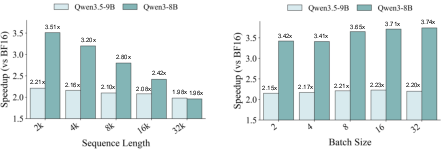
Figure 3: Mix-Quant achieves up to 3× speedup in the prefill stage relative to the BF16 baseline, with strong robustness across both sequence length and batch size.
Theoretical and Practical Implications
The decoupled quantization strategy in Mix-Quant demonstrates that input-context redundancy and attention sparsity fundamentally alter the trade-offs available in model acceleration. By targeting the computational bottleneck (prefilling) with aggressive quantization enabled by high-fidelity microscaling FP4, agentic serving stacks can substantially reduce hardware cost with negligible loss in reliability. This design is directly compatible with disaggregated inference deployments and orthogonal to further advances in sparse attention, prompt compression, or cache reuse.
From a theoretical perspective, the strong empirical evidence suggests that the approximation quality required for prefill and decode are not symmetric and should not be treated uniformly in future quantization research. The results call for further investigation of phase-aware model transformations, especially for workloads displaying high context redundancy and attention mass concentration. Potential future research avenues include automated dynamic quantization selection based on real-time context statistics, fusion with prompt compression frameworks, and hardware-software co-design for mixed-precision inference.
Conclusion
Mix-Quant establishes phase-aware quantization as a principled strategy for breaking the efficiency barrier in agentic LLM serving. By leveraging NVFP4 quantization for prefilling and maintaining BF16 decoding, it delivers a favorable trade-off: substantial acceleration with marginal loss in agentic accuracy. These results have strong implications for the design of next-generation LLM inference systems focused on agentic workflows, where long-context processing is a first-order concern. The framework offers a template for further hybrid acceleration schemes and demonstrates the value of aligning quantization strategy with the computational and error-sensitivity profile of each inference phase.
References:
Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs (2605.20315)