- The paper introduces a fine-grained mixed-precision quantization method that leverages Fisher information to selectively retain critical weights and activations in high precision (FP8), achieving less than 1% perplexity degradation.
- It proposes a sensitivity-weighted clipping approach and a dynamic precision assignment via a specialized post-processing unit to minimize quantization errors.
- The custom hardware design, featuring a VMAC datapath and tailored acceleration architecture, delivers 14% energy savings and 30% reduction in weight memory usage while maintaining near-original performance.
FGMP: Fine-Grained Mixed-Precision Weight and Activation Quantization for Hardware-Accelerated LLM Inference
Introduction
The efficient inference of LLMs is increasingly critical due to their rapid growth in size and computational demands. Quantization offers a promising approach to enhance inference efficiency by leveraging low-precision datapaths, resulting in reduced energy consumption and memory footprint. However, standard low-precision quantization can degrade model accuracy, particularly in scenarios requiring post-training quantization (PTQ) where retraining is impractical. The paper "FGMP: Fine-Grained Mixed-Precision Weight and Activation Quantization for Hardware-Accelerated LLM Inference" (2504.14152) addresses these challenges by introducing fine-grained mixed-precision (FGMP) quantization along with custom hardware support.
FGMP Quantization Methodology
The FGMP approach targets both weight and activation quantization at a fine-grained level, optimizing LLM inference without sacrificing model accuracy. Critical to FGMP is its policy for precision assignment, which uses sensitivity information based on Fisher information to identify blocks of weights and activations that should be retained in a higher precision format (FP8), while the remaining blocks are quantized to a lower precision format (NVFP4).
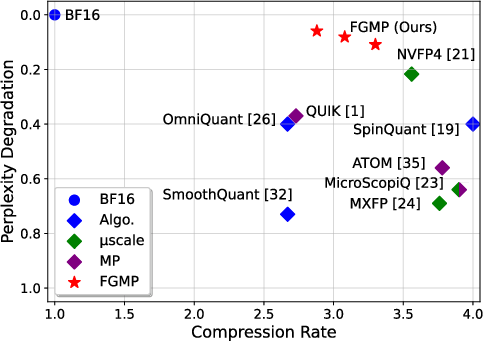
Figure 1: Perplexity degradation versus compression rate for Llama-2-7B with 4-bit quantization, demonstrating FGMP's superior performance over existing methods.
This sensitivity-driven policy prioritizes blocks according to their impact on the model's output loss, ensuring that only essential blocks are kept in high precision. Additionally, FGMP incorporates a sensitivity-weighted clipping approach, further enhancing the representation accuracy of low-precision blocks by adjusting scaling factors to minimize quantization errors.
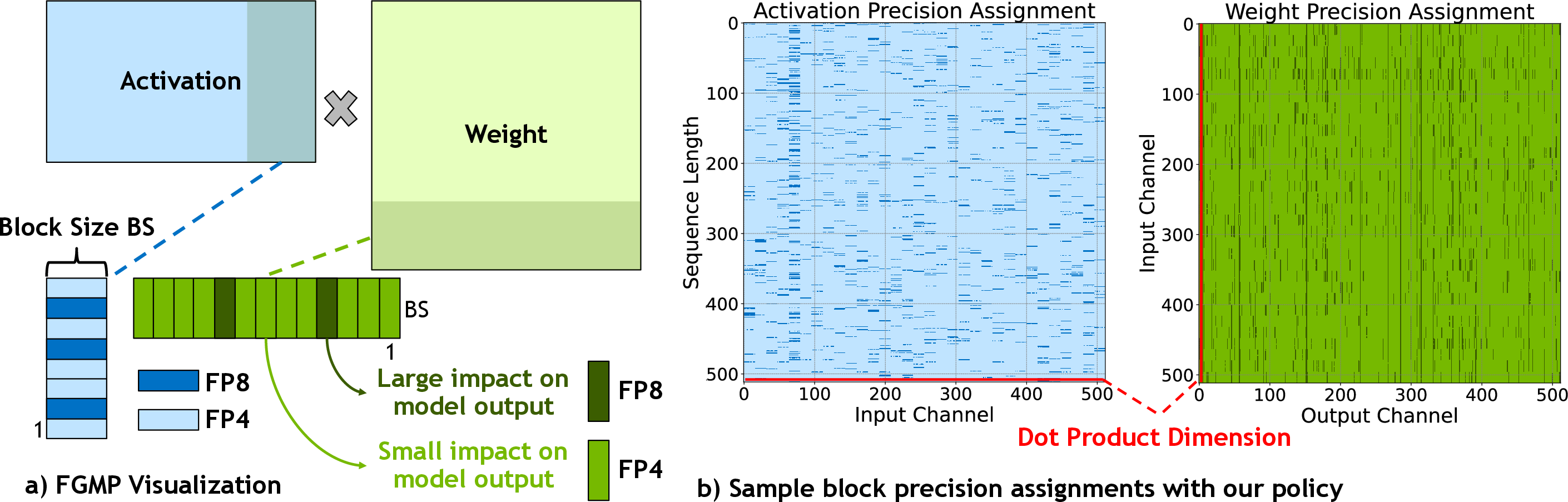
Figure 2: FGMP quantization strategy shown at block granularity, highlighting mixed-precision assignment for Layer 7 FC1 in the Llama-2-7B model.
Hardware Support for FGMP
The realization of FGMP's efficiency gains necessitates complementary hardware enhancements. The proposed hardware design includes a Vector Multiply-Accumulate (VMAC) datapath with support for executing mixed-precision operations at block granularity. This facilitates the use of low-precision computation for the majority of operations, with energy-efficient datapath choices based on the precision distribution (Figure 3).
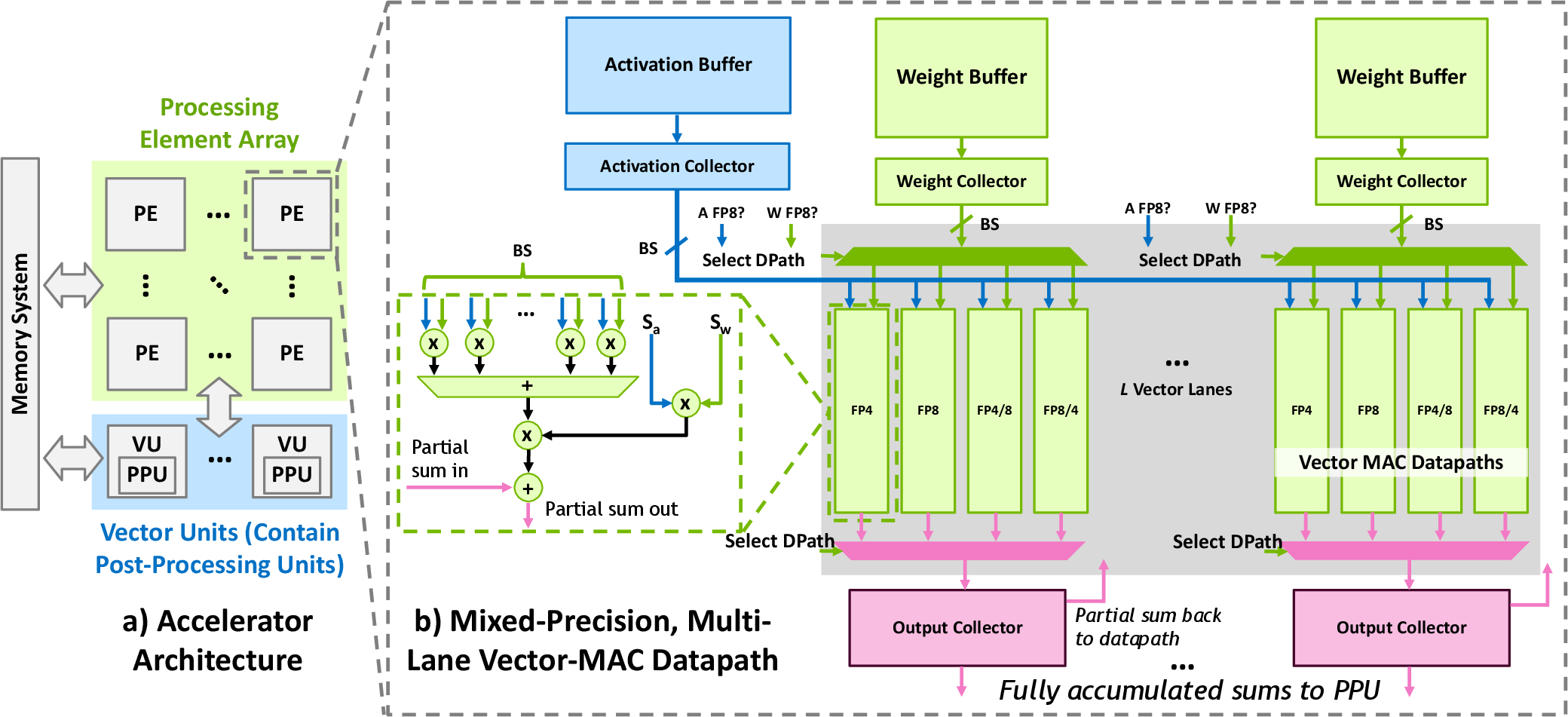
Figure 3: High-level architecture featuring a PE array and a post-processing activation quantization unit for FGMP.
A specialized post-processing unit (PPU) is designed to dynamically allocate precisions to activation blocks, based on real-time sensitivity evaluations, thus enabling optimal precision assignment during inference without substantial runtime overhead.
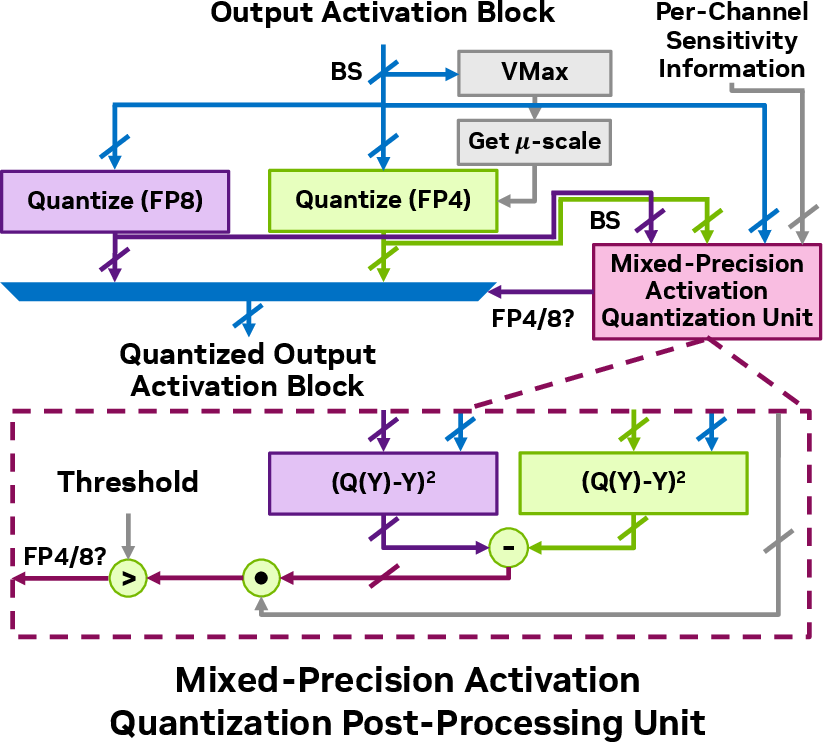
Figure 4: Post-processing unit diagram for dynamic mixed-precision quantization of activations.
Experimental Results
Comprehensive evaluations demonstrate FGMP's effectiveness in maintaining model accuracy (perplexity) across several LLM architectures, such as Llama-2 and GPT3, while significantly reducing energy consumption and memory usage. The FGMP approach, when applied to the Llama-2-7B model, results in less than 1% perplexity degradation compared to FP8 across standard benchmarks like Wikitext-103, while achieving 14% energy savings and 30% weight memory reduction.
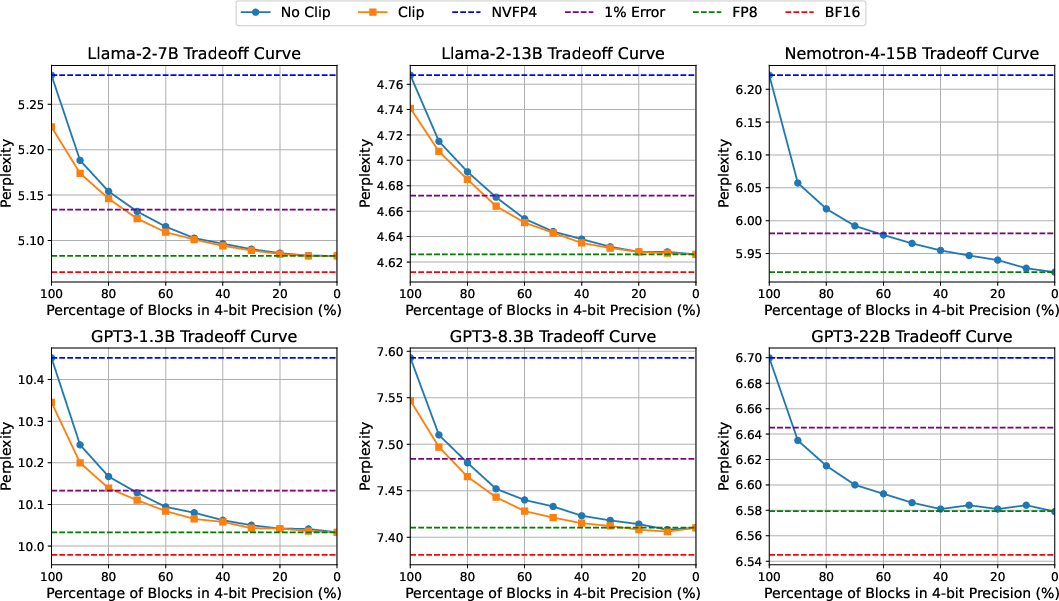
Figure 5: Wikitext-103 perplexity results for various models and precision settings under FGMP quantization.
Conclusion
FGMP represents a significant advancement in LLM quantization, striking a balance between performance and computational efficiency. The synergy of sensitivity-aware quantization and hardware-level innovations empowers LLMs to deliver near-original performance with markedly reduced energy and memory footprints. As LLMs become more pervasive, the implications of such advancements cannot be understated, paving the way for more sustainable and scalable AI deployments. Future work may explore extensions to other model architectures and further optimize hardware designs for even more nuanced precision adjustments.

