- The paper demonstrates that task-specific quantization yields optimal trade-offs in cost, latency, and performance.
- It introduces a dynamic precision routing mechanism that allocates optimal precision levels based on extensive empirical sensitivity analyses.
- Benchmark results show up to 21.7% cost reduction and significant latency improvements compared to static precision assignments.
Task-Adaptive Precision Routing for Autonomous Agents with QuantClaw
Introduction
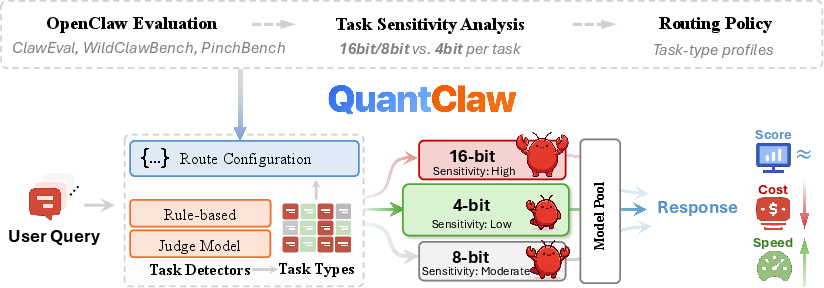
The proliferation of autonomous agent systems, typified by platforms such as OpenClaw, has intensified computational challenges due to long-context handling, multi-turn reasoning, and the widespread adoption of large-scale LLMs. Uniform high-precision inference—standard in conventional deployments—results in substantial inefficiency, particularly as agentic workflows diversify and task complexity becomes highly heterogeneous. Quantization is a well-explored approach for optimizing latency and cost, but its nuanced effects on diverse agentic tasks remain insufficiently understood. The paper "QuantClaw: Precision Where It Matters for OpenClaw" (2604.22577) addresses this gap by characterizing quantization sensitivity at both model and task levels and introduces QuantClaw, a dynamic, plug-and-play precision routing layer for OpenClaw, performing task-aware allocation of model precision to optimize cost and latency with no observable decline—often improvement—in task performance.
Quantization Sensitivity: Model-Level and Task-Level Analysis
A central contribution is the comprehensive empirical analysis across 24 agentic task types, 104 tasks, and 6 LLMs ranging from 9B to 744B parameters. Quantization from native precision (BF16/FP8) to NVFP4 (a 4-bit microscale floating-point format) introduces minimal aggregate performance degradation, but this impact exhibits systematized dependence on both model scale and task semantics. Notably, large models (>200B) demonstrate pronounced robustness to precision reduction, attributable to increased representational redundancy and implicit regularization effects under quantization.
Figure 1: Scaling behavior of quantization degradation under NVFP4 demonstrates a systematic power-law relationship, with degradation diminishing as model size increases.
Task-level analysis further reveals sharp inter-task heterogeneity in quantization sensitivity (Figure 2). "High-sensitivity" categories—such as code generation, compliance, and safety-critical inference—suffer significant drops in performance under aggressive quantization, while "low-sensitivity" tasks (e.g., retrieval, research, and text comprehension) are largely unaffected, and occasionally exhibit improved generalization. Moderate-sensitivity tasks, including standard NLG or rewriting, inhabit an intermediate zone, amenable to mixed-precision routing.
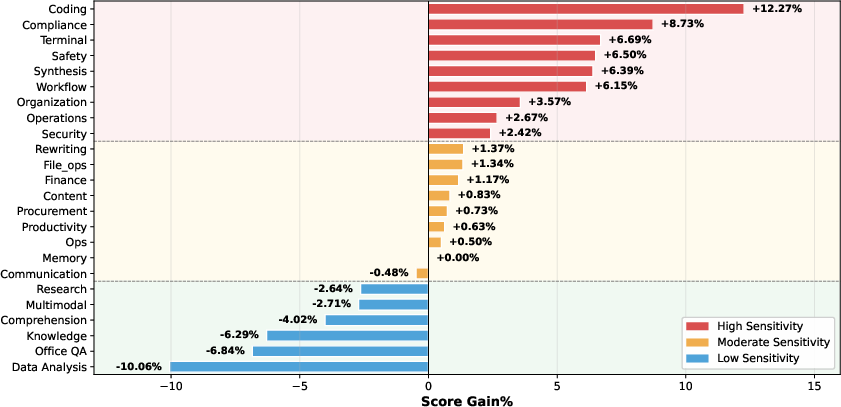
Figure 2: Distribution of task-level quantization sensitivity, categorizing OpenClaw tasks by empirical robustness to reduced precision.
The observed task-dependent sensitivity motivates the QuantClaw paradigm: a runtime-allocated, policy-driven precision controller. The system supports both "latency-oriented" and "cost-oriented" operating modes. Tasks are automatically classified by a hybrid rule/model-based detection pipeline and routed to an appropriate model instance at one of several hardware-friendly precision levels, optimizing for either minimum overall latency or minimal cost without task-level quality compromise.
QuantClaw maintains a pool of model variants pre-quantized to different precisions. The routing policy is derived from offline sensitivity profiling (Section 2 of the paper), mapping each task type to its empirically optimal precision. This approach achieves strict Pareto improvements over any static assignment scheme.
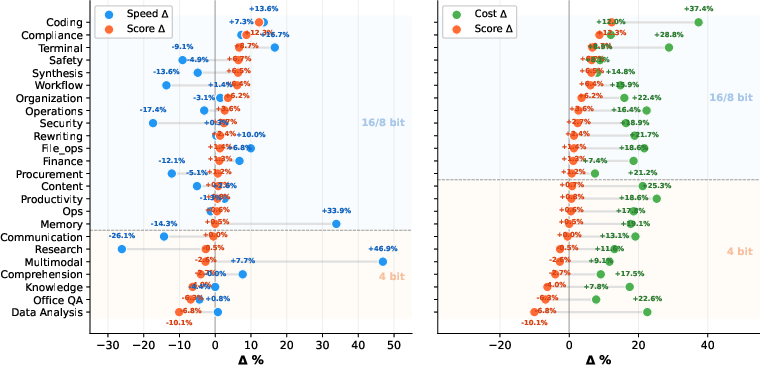
Figure 3: Task-level trade-off between high precision (16/8-bit) and low precision (4-bit). Critical tasks are routed to higher-precision execution; tolerant tasks are handled by lower-precision models for efficiency.
System Design and Implementation
QuantClaw formalizes precision as a dynamic resource, governed by a modular, extensible routing pipeline. The workflow comprises:
Automatic adaptation, dashboard customizability, and real-time observability are supported features for production environments.
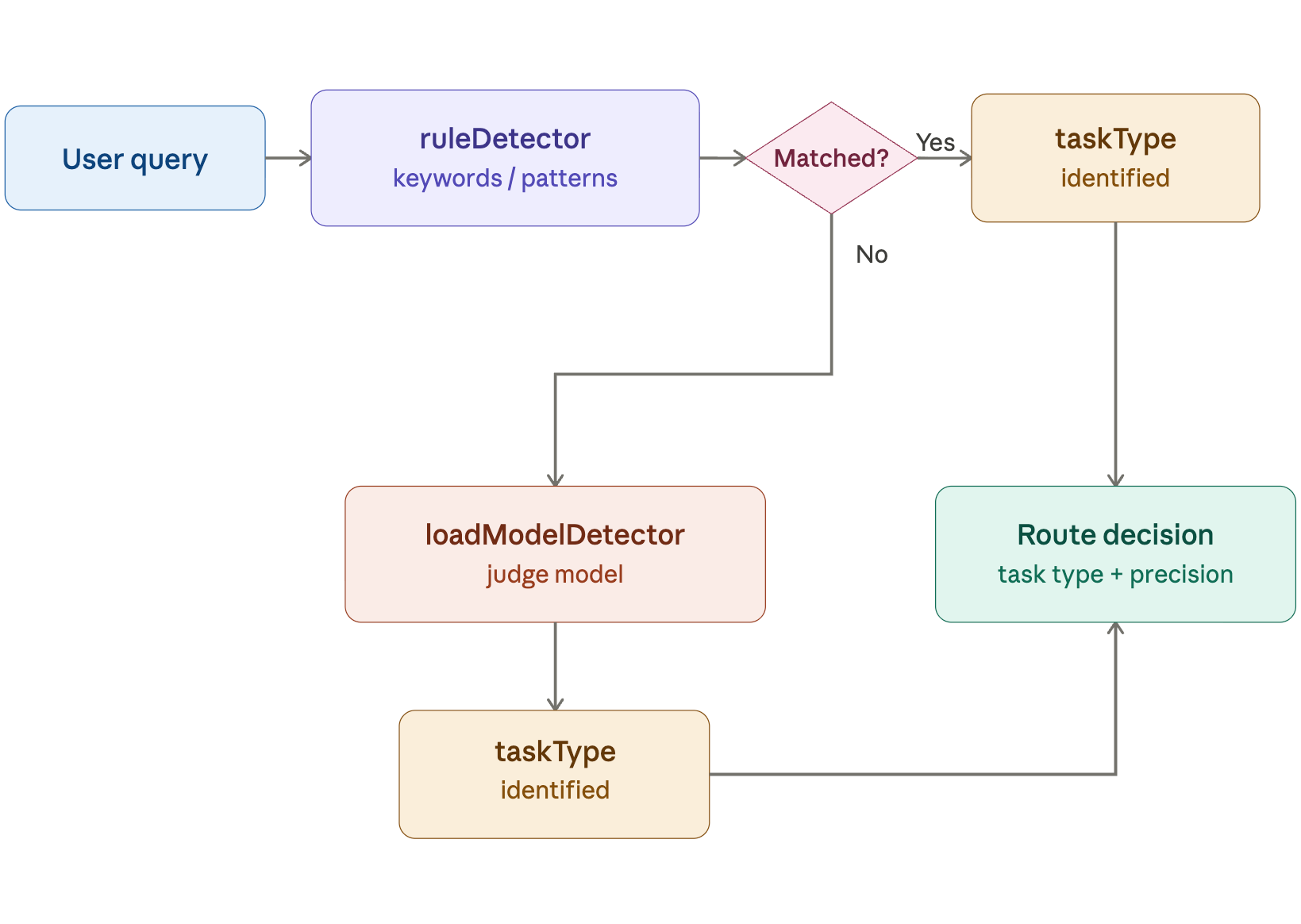
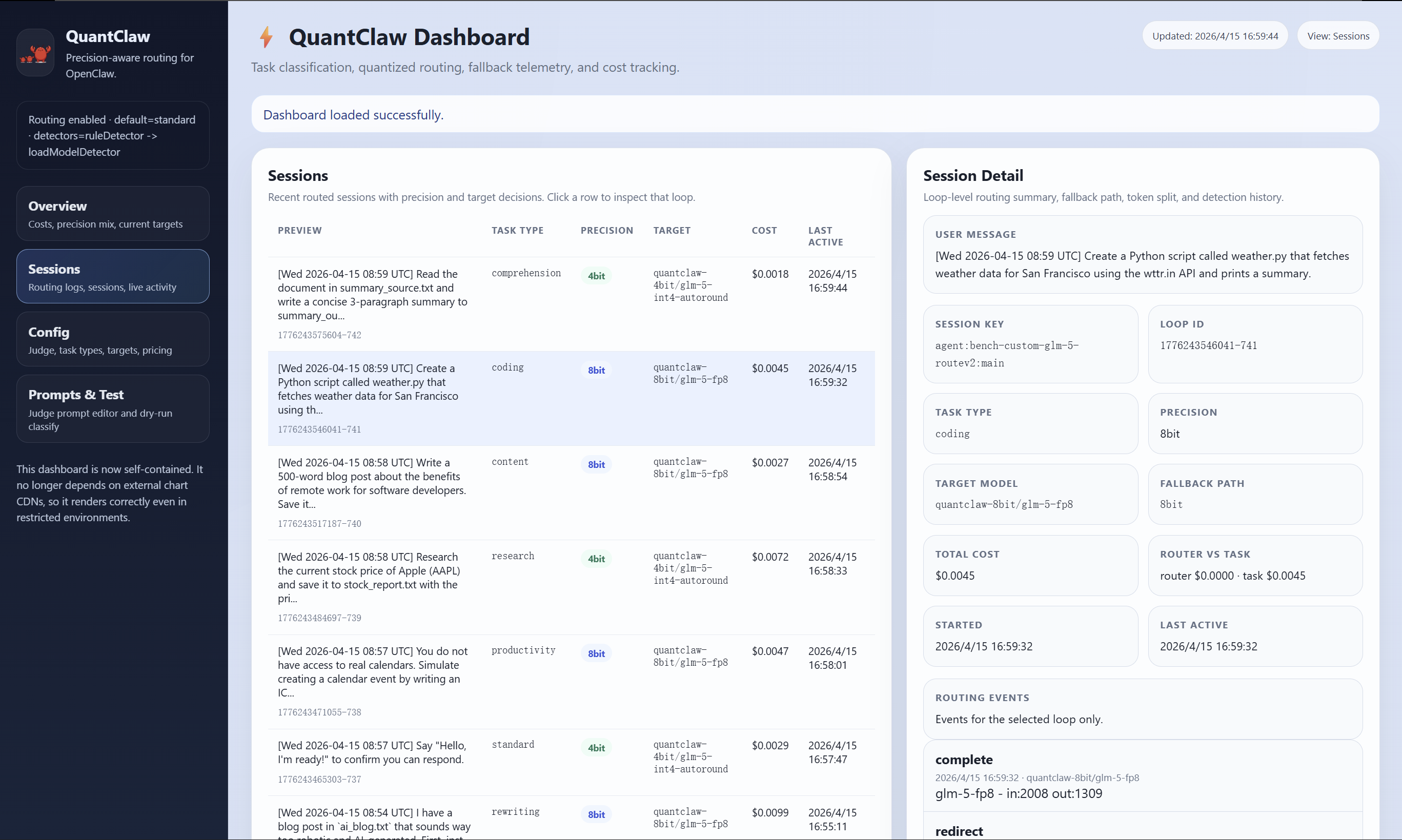
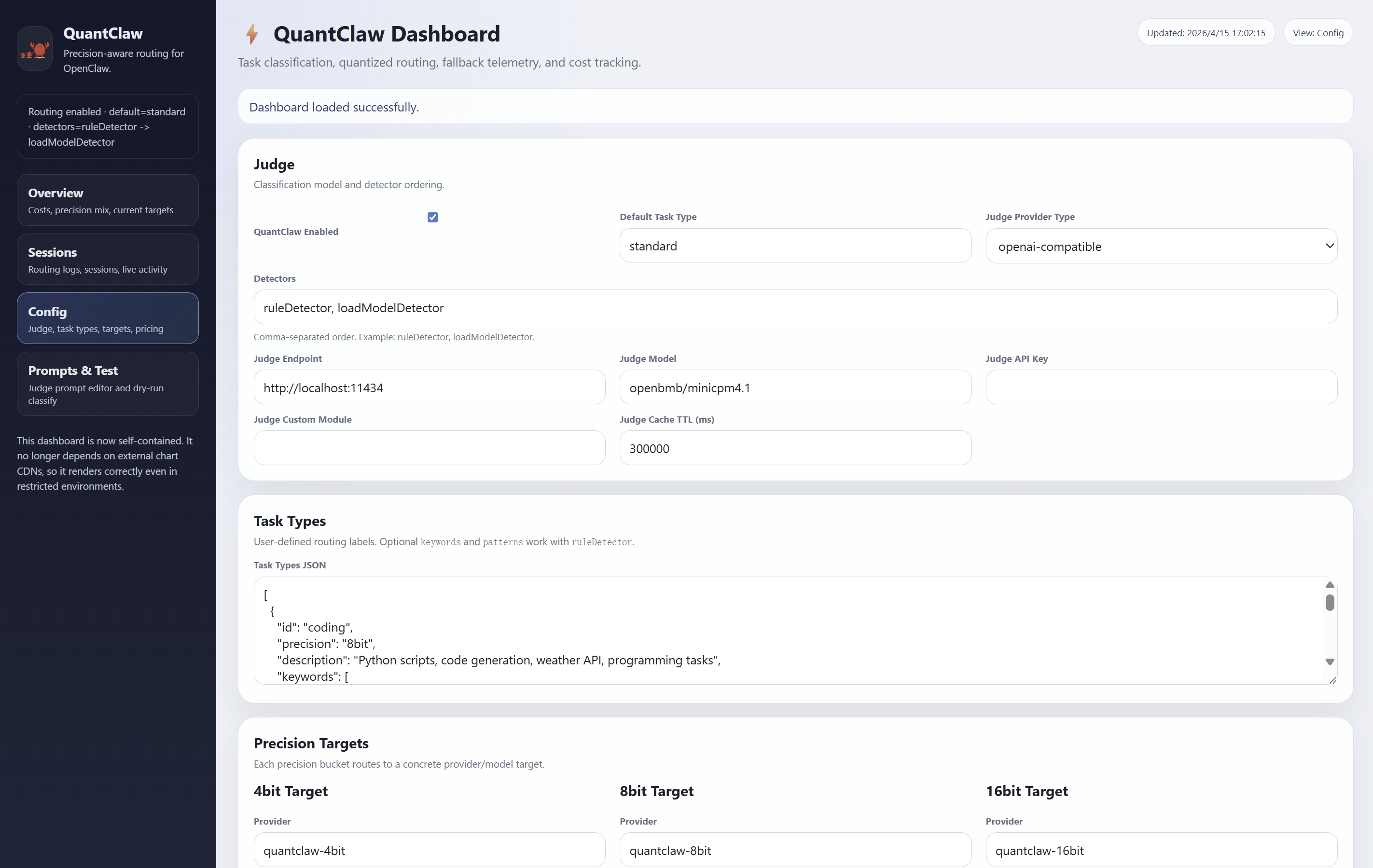
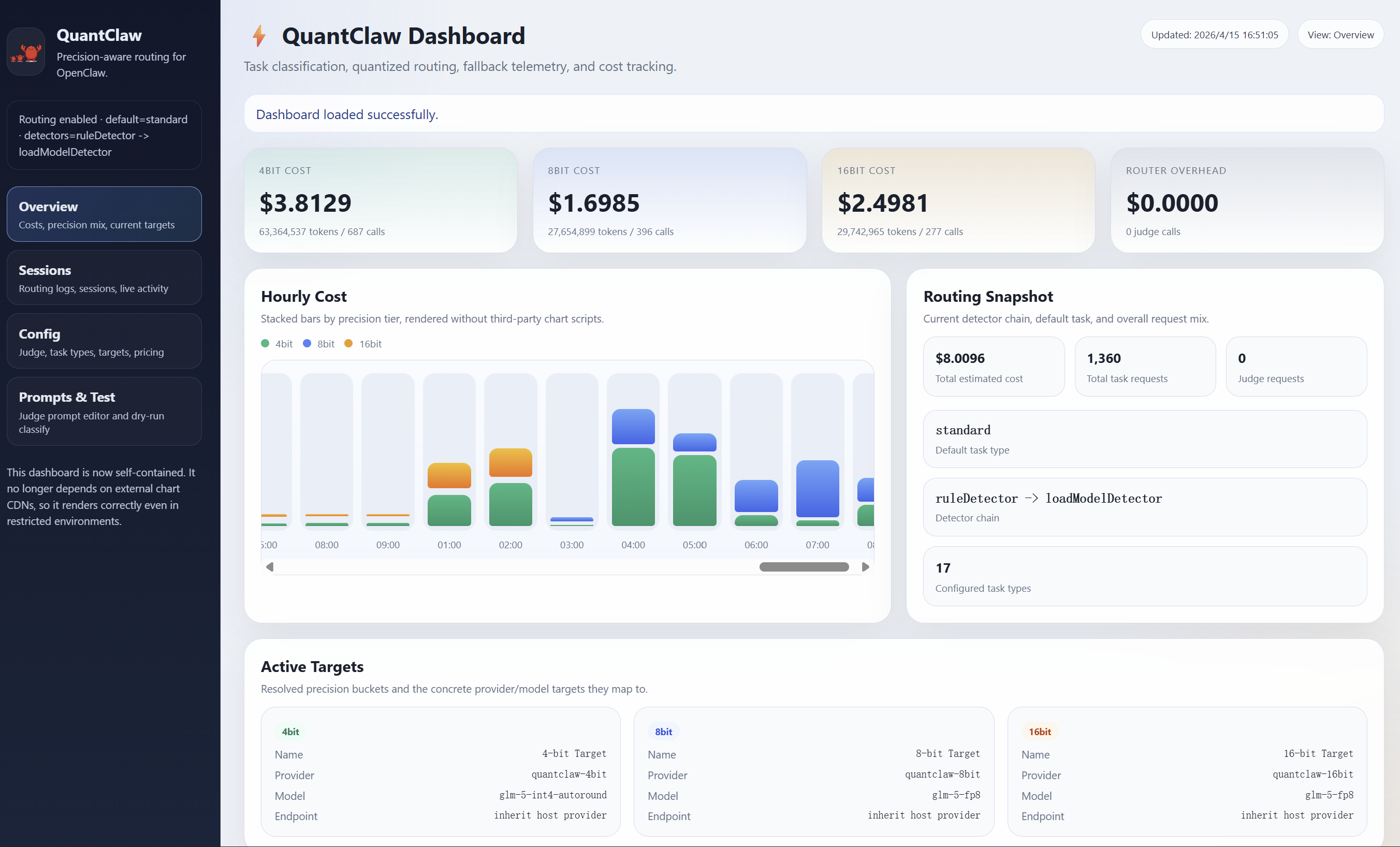
Figure 5: Illustration of automatic adaptation consolidating both task detectors in the decision flow.
Extensive benchmarking on PinchBench (v1.2.0 and v2.0.0) demonstrates that QuantClaw surpasses both the uniform high-precision and static low-precision baselines. On GLM-4.7-Flash, QuantClaw reduces cost by 21.7% and end-to-end latency by 8.4%, while simultaneously improving average task score. On GLM-5, cost and latency savings reach 21.4% and 15.7%, respectively, with performance matching or exceeding the FP8 baseline. These improvements are not attainable via naïve uniform precision downgrading, as the selectively routed execution preserves high-precision operation for the subset of tasks where quantization would otherwise be destabilizing.
Theoretical and Practical Implications
The results underscore that static precision assignment is suboptimal for agentic LLM deployments. QuantClaw demonstrates the efficacy of treating precision as a first-class, schedulable resource, closely analogous to dynamic resource management in distributed systems. In practical terms, such adaptive policies will be critical for economically viable deployment of large LLM agent systems, particularly at scale and in latency-constrained interactive environments.
The methodology also complements developments in quantization-aware training (Liu et al., 2 Mar 2026, Breugel et al., 5 Jun 2025), highlighting that system-level adaptivity (task-aware precision routing) and algorithmic advances (quantization algorithms) are complementary for maximizing efficiency. The paradigm generalizes beyond OpenClaw, inviting further research on adaptive execution in heterogeneous agent systems and multi-model orchestration frameworks.
Conclusion
QuantClaw establishes that uniform-precision deployment is economically suboptimal and often technically inadequate for complex agentic workflows. Task-dependent quantization sensitivity mandates dynamic precision allocation, and QuantClaw achieves this through a lightweight, automated routing architecture that consistently reduces latency and cost, while preserving or enhancing system-level task performance. Future agent stacks should adopt similar resource management approaches, treating precision, memory, and model selection as schedulable dimensions to optimize for both user experience and operational cost.