- The paper demonstrates that slight misranking in the high-reward tail dramatically undermines win rate and expected reward in LLM post-training.
- The methodology involves iterative, LLM-driven rubric refinement using off-policy exemplars to effectively differentiate among high-quality responses.
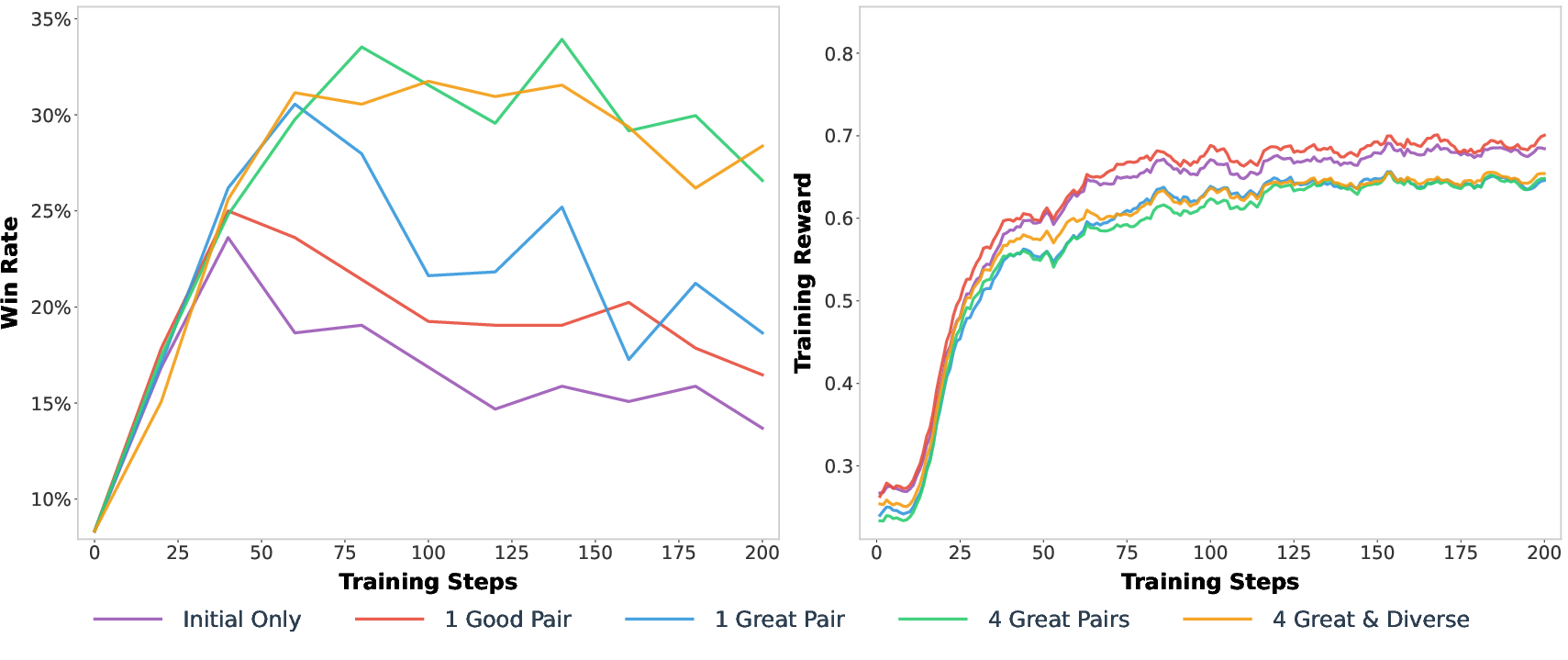
- Empirical results show that rubrics based on great and diverse responses significantly delay reward over-optimization, yielding robust performance improvements.
Rubric-Based Reward Modeling for LLM Post-Training: Theory and Practice
Overview
This paper addresses the persistent challenge of reward over-optimization in reinforcement fine-tuning (RFT) of LLMs. The authors provide a theoretical and empirical analysis demonstrating that the primary driver of over-optimization is reward misspecification in the high-reward (tail) region, i.e., the inability of reward models to reliably distinguish between excellent and merely great responses. To mitigate this, the paper proposes a rubric-based reward modeling framework that leverages off-policy exemplars and iterative rubric refinement, focusing on discriminating among high-quality, diverse responses. The approach is shown to substantially delay and reduce reward over-optimization, yielding more robust post-training improvements.

Figure 1: Chasing the Tail with Rubric-Based Rewards. The schematic illustrates the focus on the high-reward tail and the iterative refinement process.
Theoretical Analysis: High-Reward Tail Dominance
The authors formalize the RFT objective as maximizing expected reward under a KL constraint from the base model, with the reward model r serving as a proxy for the inaccessible ground-truth r∗. They introduce a misspecification mapping f from r∗ to r and derive closed-form expressions for expected reward, win rate, and KL divergence under this mapping. The key theoretical result is that, for Pareto-optimal post-training procedures, the impact of reward misspecification on downstream performance is exponentially concentrated in the high-reward region. Specifically, errors in ranking or scoring the top responses dominate the degradation in win rate and expected reward, while the KL divergence remains invariant to f.
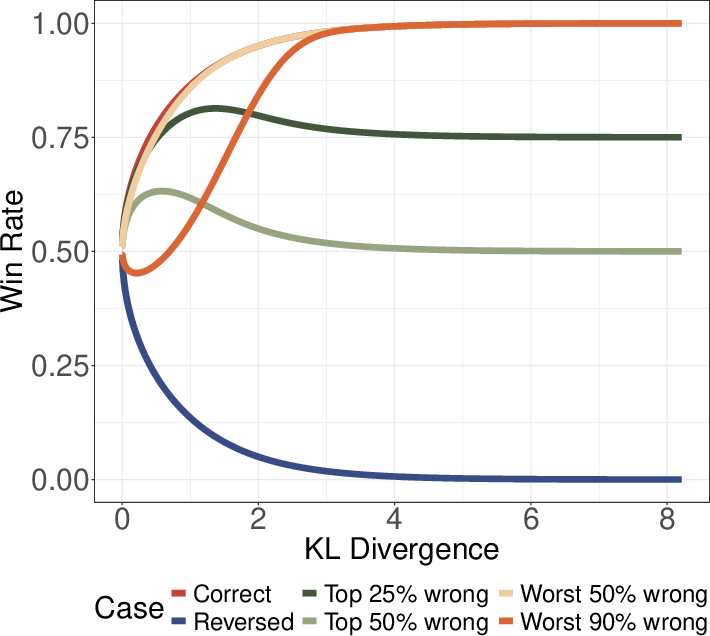
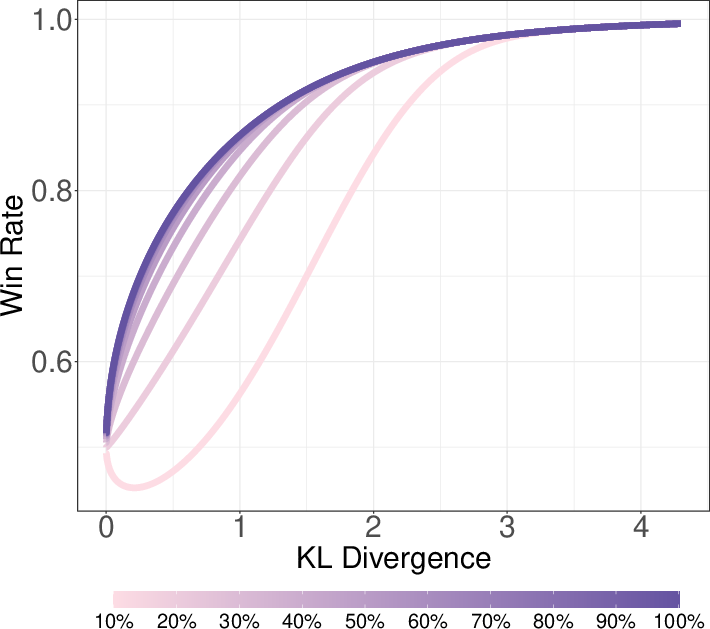
Figure 2: Win rate with reward misspecification. Performance collapses when the proxy reward is inaccurate in the high-value region, but is robust if the top responses are correctly ranked.
The analysis further shows that if the reward model correctly ranks only a small fraction (e.g., top 10%) of responses, near-optimal performance is achievable. Conversely, misranking the high-reward tail leads to rapid collapse in win rate as optimization pressure increases.
Rubric-Based Reward Modeling: Principles and Workflow
Rubric-based reward modeling (RLRR) is proposed as a solution to the scarcity of high-reward training examples and the brittleness of standard reward models to off-policy data. In RLRR, each prompt is associated with a set of explicit, weighted binary criteria (the rubric), and a verifier LLM scores each response against these criteria. The total reward is the weighted average of satisfied criteria.
The paper introduces two principles for effective rubric construction:
- Distinguish excellent from great responses: Rubrics must be refined to separate the very best responses from those that are merely good.
- Distinguish among diverse off-policy responses: Rubrics should be iteratively refined using a diverse pool of high-quality responses from multiple strong models.
The authors operationalize these principles via an iterative refinement workflow. At each step, the current rubric is used to score a pool of candidate responses; the top responses are compared, and a proposer LLM is prompted to identify distinguishing features, which are encoded as new or refined rubric criteria. This process is repeated, progressively sharpening the rubric's discriminative power in the high-reward tail.
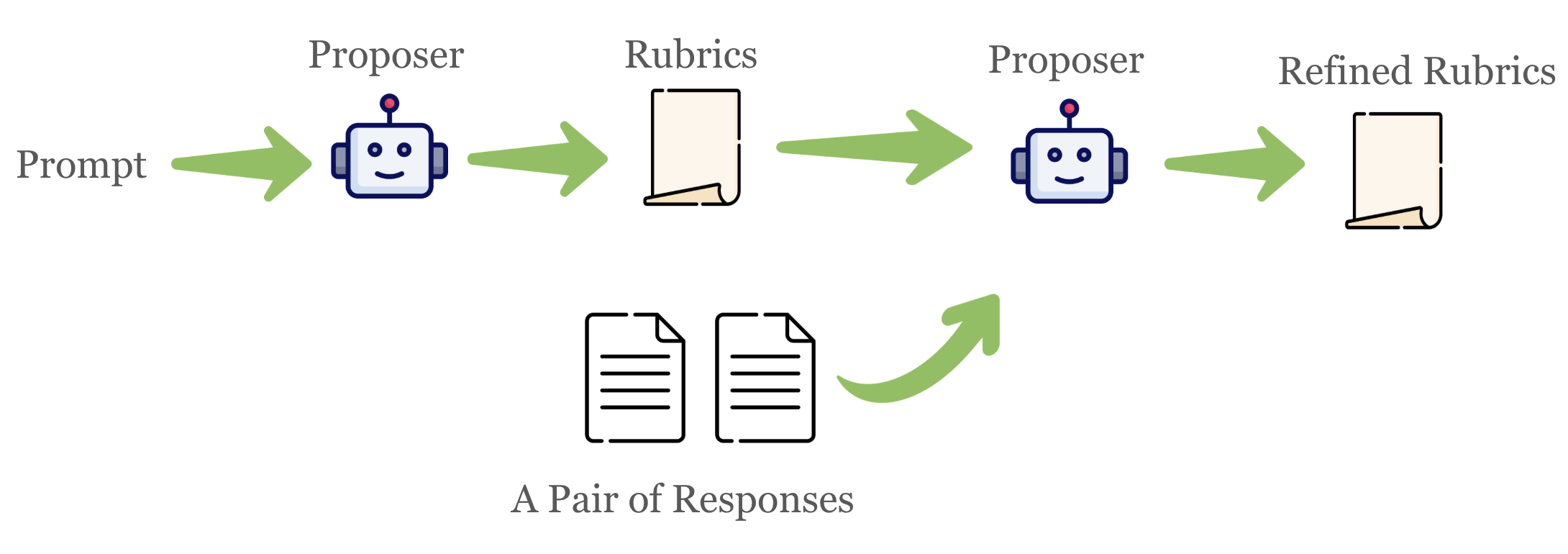
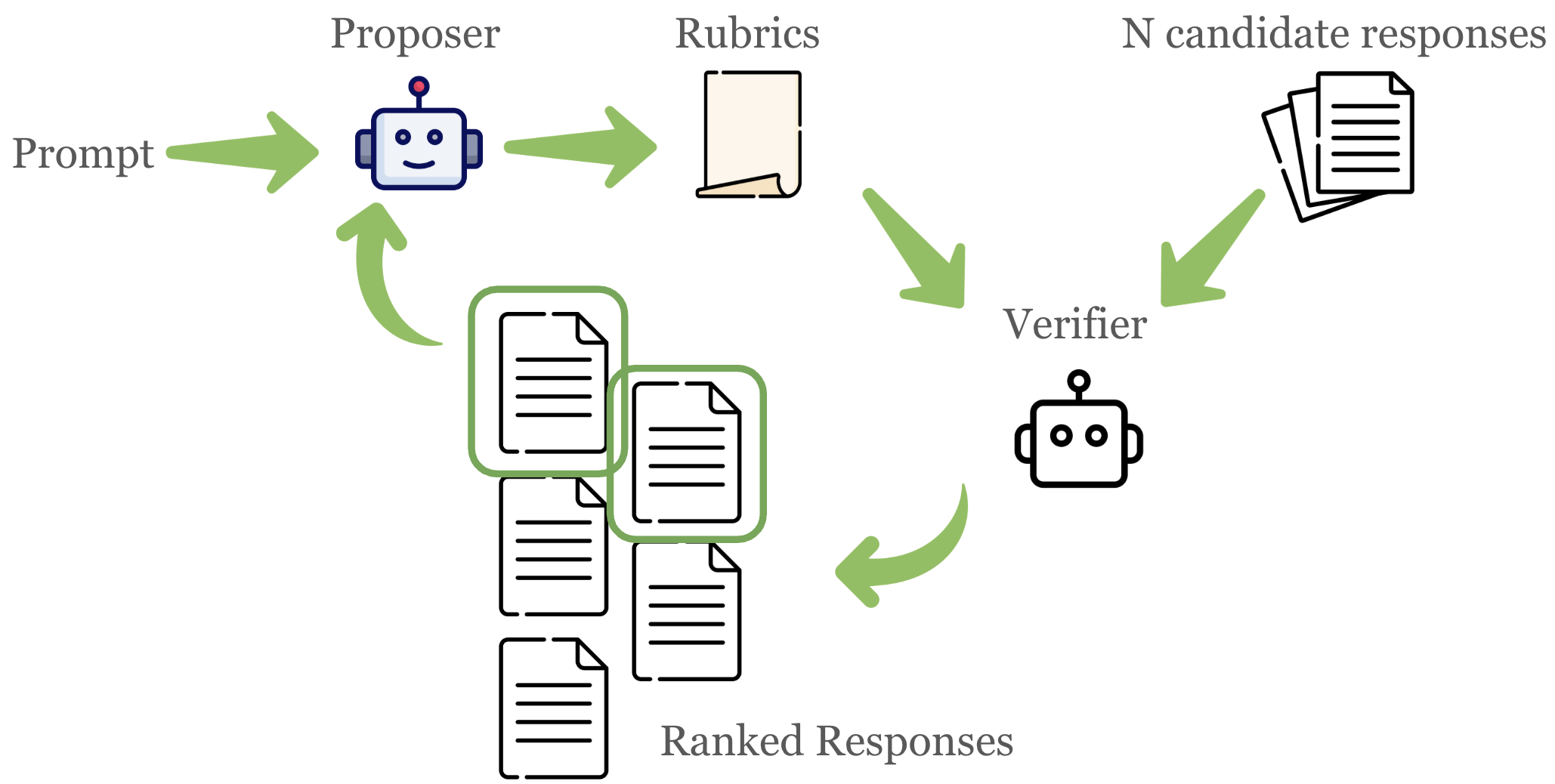
Figure 3: Single-round Improvement. A proposer LLM analyzes a pair of responses to identify distinguishing features and encodes them as new rubric criteria.
Empirical Evaluation
Experiments are conducted in both generalist and health domains, using Qwen3-8B-Base as the base model and GRPO as the RFT algorithm. Rubrics are constructed and refined using GPT-4.1 as the proposer and verifier. Candidate responses are drawn from a diverse set of strong LLMs, including Gemini 2.5 Pro and others.
Key findings include:
Quantitatively, win rates and domain-specific metrics (e.g., HealthBench) improve monotonically with the quality and diversity of rubric refinement. Rubric-based rewards also show higher agreement with ground-truth judges in the high-reward region, directly linking rubric accuracy in the tail to downstream RL performance.
Qualitative Analysis of Rubric Refinements
Analysis of rubric refinement patterns reveals that great candidate responses drive more sophisticated rubric improvements, such as breaking down complex criteria, enhancing verification standards, and defining explicit scope or constraints. In contrast, good responses tend to drive basic corrections or broaden criteria. This supports the claim that high-quality, diverse exemplars are essential for eliciting rubrics that can reliably distinguish the best outputs.
Implications and Future Directions
The findings have several important implications:
- Reward model design for LLM alignment should prioritize accuracy in the high-reward tail. Global reward model metrics are insufficient; targeted evaluation and refinement in the tail are critical.
- Rubric-based rewards offer a scalable, interpretable, and sample-efficient alternative to preference-based reward models, especially in domains where large-scale high-quality preference data is unavailable.
- Iterative, LLM-driven rubric refinement is effective for leveraging off-policy data without overfitting to superficial artifacts.
Potential future directions include optimizing the aggregation of rubric scores (beyond simple weighted averages), automating the selection of candidate pools for refinement, and extending the approach to more open-ended or creative tasks.
Conclusion
This work provides a rigorous theoretical and empirical foundation for rubric-based reward modeling in LLM post-training. By focusing on the high-reward tail and leveraging iterative, LLM-driven rubric refinement with diverse, high-quality responses, the approach effectively mitigates reward over-optimization and yields robust alignment improvements. The results suggest that careful reward model design—centered on discriminating among the best outputs—is essential for scalable and reliable LLM alignment.